はてなキーワード: アプリケーションとは
IT業界であればVMwareの周辺で発生している騒動について多少なりとも聞いていると思います。業界外の人でもその名前ぐらいは耳にされているのではないでしょうか。では実際にVMwareに何が起こっているのか、どのような背景があるのか、今後どうなるのかを知っている範囲で書いてみます。
VMwareとは仮想化ソフトウェアです。この説明だけで理解できる人にはこのセクションの説明は不要です。
VMware自体は1998年創業の会社ですが、広く世に知られるようになったのはおそらく2000年前後ぐらいからでしょうか。仮想化とはハードウェアと抽象化して物理的なハードウェアをソフトウェア的に再現する技術の一種です。Windowsの上でさらに別のOSを実行できるようにすることができるようになります。この別のOSのことを仮想マシン(VM)と呼びます。個人レベルではテスト環境などに使えることがメリットですが、企業レベルでは大量のハードウェアを効率的に集約できることが期待されていました。特に2010年以降のマルチコア化の急速な進展の結果、多くの用途でボリュームゾーンのサーバーハードウェアは高速・大容量になり過ぎました。企業内のアプリケーションを動作させるために単体のハードウェアは過剰になって久しいです。そのため、VMwareによって1台の物理ハードウェアを複数のVMで利用する使い方が一般化しました。社内で新しいサーバーが必要になってもわざわざ新規で物理的なハードウェアを購入してセットアップと設置などをしなくてよくなるわけです。個人向けのVMware Workstationは単にPC上にVMを複数起動できるだけでしたが、企業向けの上位版では複数のサーバーやストレージを束ねてプライベートクラウドを構成することも可能でした。
企業としてのVMwareはEMCというストレージメーカーに買収後、2007年に上場します。EMCがDELLに買収されたこともあり、DELLの傘下になったあと2021年にスピンオフされ独立した企業となりました。その後、2022年にBoradcomに買収されます。
現在のBroadcomは源流をたどればHPに繋がります。HPからアジレントという計測機器を作る会社がスピンオフし、その会社から半導体事業をファンドが買収し独立させたAvagoという会社が現在のBoradcomの母体です。BroadcomはAvagoとは別の半導体設計・製造を行っていた会社ですが、Avagoに買収され存続会社の社名をBroadcomとしたことで現在の形になっています。
Broadcomの製品で一番有名なところとしては、ネットワーク関連のチップだと思います。サーバー用のNICなどで名前を見る機会も多いはずです。それ以外にも様々な用途のチップを作っていましたし、買収によりラインナップを拡充してきました。
転機となったのは2017年にQualcommを買収しようとしたことです。これは先方の役員から拒絶され、また規制当局からも懸念を表明されたことで失敗に終わります。これ以降、Broadcomはソフトウェア企業の買収に軸足を移しました。CAテクノロジーズやSymantecのセキュリティ部門を買収しました。Symantecのセキュリティ部門はその後、アクセンチュアに売却します。もちろん、今回のVMwareも買収しています。
Broadcomが買収したCAテクノロジーズはかつてComputer Associatesと呼ばれる会社でした。1976年創業でメインフレームのころからビジネスを行っており一時は業界2位の地位まで上り詰めた会社ですが、今一つ有名なプロダクトがない会社と記憶しています。
List of mergers and acquisitions by CA Technologies - Wikipediaと、CAが買収した会社はWikipediaで専用のページが用意されるほど数多くあります。この会社のビジネスモデルはさほど成長度は望めないがシェアが大きい企業向けシステムなど確実にキャッシュを生み出すソフトウェア(いわゆるcash cow)を作る会社を買収し、新規開発を一切止めることで費用を削減しキャッシュを絞り出すというモデルだったようです。私も以前CAのロゴの入ったソフトウェアを使ったことがありますが、なぜこのような使いにくいソフトを使い続けるのか疑問でした。企業システムの一部として使い始めてしまうと簡単には変更することができず、ランニングコストがかかり続けたとしても変更するためのコストを考えると使い続けざるを得なくなることは非常によくあります。
どこかで聞いた話ですね。これと同じことがVMwareでも起こりました。BoradcomがCAテクノロジーズを買収したのはこのビジネスモデルを吸収するためだったのではないかと思われます。
Broadcomに買収されて以降、VMwareはそのビジネスを大きく転換しました。日本法人では社員が大幅に削減されたようです。ライセンスについても売り切りモデルの新規販売を止めサブスクリプションだけにしたり、ランナップを大幅に整理しました。
このようなビジネスモデルの転換は既存ユーザーから反発を食らいますが、前述の通り企業システムの根幹で使われているソフトであるため簡単に使用を止めることができないのが現状です。日経BPなどでは移行先の候補の比較記事なども掲載していますが、変更するための人的コストを考えると使い続ける企業は少なからずあるのではないでしょうか。
より悲惨なのはクラウドサービスをVMwareを中核に構築してしまったところです。こちらはもっと乗り換えるのが難しいはずで、IaaSから撤退する会社も出てくるのではないでしょうか。
ソフト産業は製造業と違い成功すれば小規模ながら利益率の高いビジネスを生み出せる可能性があります。一方で製造施設などの固定資産や従業員数は多くないため、企業価値が過小評価されている企業もあります。そのような会社を買収してキャッシュを搾り取るビジネスを行ってきたのがCAという会社でした。少なくともこのモデルで数十年間ソフト業界で生き続けていました。そのため、このモデルを根絶することはかなり難しいのではないかと考えています。
エッジコンピューティング市場の収益は、2023年には約841億ドルに達すると予測されている。さらに、エッジコンピューティング市場に関する弊社の洞察によると、予測期間中のCAGRは約35.18%で成長し、2036年には約31兆5,810億ドルの規模に達する見込みです。
5Gネットワークの普及に伴い、エッジコンピューティング市場は急成長している。さまざまな場所にある企業のほとんどが、クラウド・コンピューティング・プラットフォームを通じてサービスに接続している。エッジコンピューティングは5Gと6Gのインフラを活用し、コスト削減、運用の簡素化、サイバーセキュリティ対策の強化を実現する。
モノのインターネット(IoT)の台頭: モノのインターネット(IoT)の急速な普及により、中央集権型のクラウド・コンピューティングやストレージ・システムで処理されるデータは膨大な量に達している。さらに、エッジコンピューティング市場は、低遅延処理やAIの適用を必要とするユースケースの増加により成長している。
医療用センサー、スマートカメラ、産業用PC、その他のモノのインターネット(IIoT)デバイスなどのエッジデバイスの普及が、エッジコンピューティング市場の拡大を促進している。さらに、運用能力の強化や主要企業間の重要なコラボレーションに対する需要の高まりが、IIoT市場の拡大を後押ししている。エッジコンピューティング市場は、業種、コンポーネント、アプリケーションのカテゴリーに基づいて区分される。
以下のリンクからすべての情報を見るには、ここをクリックしてください:https://www.sdki.jp/reports/edge-computing-market/108966
要件満たすため・社内政治的な理由でピンポイントで別のところ使う+併用はあっても、
ゼロトラストセキュリティは、「信頼せず、常に検証する」という原則に基づいています。主な特徴として、常時の認証と承認、最小権限アクセス、アクセスの継続的な監視があります。以下の技術やソリューションを組み合わせることで、包括的なゼロトラストセキュリティモデルを構築できます。
1. Microsoft Entra ID(旧Azure AD):
3. 多要素認証(MFA):
1. 暗号化:
これでなんとなく長文書いたらビビるくらいブクマついたので弊社の例も書いてみる
3年前に買収されて今は世界で数百人年商2000億くらいの規模
外向けのレガシーSaaS、それをリプレースメント中のマイクロサービス群、自社の経理向けのシステム
ただしVPNとRDPはあり
ファイルサーバーはSharePointに移行中
2代前の会ったことがないCTOの時にランサムウェアにやられている
その時はCTOがバックアップから戻せたけれど弁護士代等で数千万の損害
現在のシステムのハックのしやすさはサービスによるので以下に個別に
AWS上のWindows Serverで稼動するWebアプリケーション(Spring)
引き継いだ時は顧客の住所電話等のPII(個人情報)が満載だったけど全部消したので今はここから見れるのは名前と何時間うちと関わったかということだけ
一応AWS上ではあるけどVPNとRDPがハックされた場合(よくある)全部抜かれる可能性はあって正直ユルユルだが最悪抜かれてもそんなに困らないようになっている(した)
ファイルは自社で保存じゃなくてAWSのs3にシステム経由でアップロードされるようになっているのでファイルサーバー、あるいはSharePointなどとは別系統の認証が必要
それでもRDPで繋げられるAWS上のWindowsServer上にのっているのでハックした上で頑張ればとれてしまうけれどブラウズしてファイルがみれるものに比べれば難易度は上
同じ情報をあつかってるけどサービス自体がコンテナ化されてAWS上で動いているので乗っ取れるサーバーがなくて会社がハックされても関係ない
API経由で認証してAPI経由で情報を取り出すようになっているので個々のAPIの安全性は書いた人次第だけどそれで盗める情報はそのAPIが扱う一部に限られる
ここ経由で雑に免許証だのなんだの大量に出る可能性はかなり低い
1.2.3.とそれ以外のケースは大きな会社なら混在してて、いくらノートラストとか言ってて実際一部が3.でやっていてもだめだし
VPNやRDPを乗っ取られないようにするスキルとAPIのセキュリティーを設計して書くスキルとでも全く違うし
仮にノートラストで全部3にしようってしてもできる人間は限られてるし高いしいきなりできるものでもないんだけど
その辺雑だからこういうことになるのかね
2.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows エラー報告]
2.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows Update] - [Windows Update から提供される更新プログラムの管理]
[プレビュー ビルドや機能更新プログラムをいつ受信するかを選択してください]:"有効"
[機能更新プログラムがリリースされてからデバイスに提供されるまで、更新を保留する日数を指定してください]:"180"
2.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows Update]
[スケジュールされた自動更新のインストールで、ログオンしているユーザーがいる場合には自動的に再起動しない]:"有効"
3.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows Update]
[オプション]:"3 - 自動ダウンロードとインストールを通知" , "毎週"
2.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows Update] - [従来のポリシー]
[スケジュールされた自動更新のインストールで、ログオンしているユーザーがいる場合には自動的に再起動しない]:"有効"
3.[コンピューターの構成] - [管理用テンプレート] - [Windows コンポーネント] - [Windows Update] - [エンドユーザーエクスペリエンスの管理]
[オプション]:"3 - 自動ダウンロードとインストールを通知" , "毎週"
2.[サービスとアプリケーション] - [サービス] - [Windows Search]
◆SuperFetch(SysMain)無効化
2.[サービスとアプリケーション] - [サービス] - [SysMain]
2."powercfg.exe /hibernate off"
2.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\238C9FA8-0AAD-41ED-83F4-97BE242C8F20\7bc4a2f9-d8fc-4469-b07b-33eb785aaca0
2.[Attributes]: "2" (16進数)に変更
画面上でできなくしてもサーバーに直接リクエスト送ってくるからって同じことをサーバーでも実装しないといけなくてすごくめんどくさい
言語同じかつ単純な規則な共通化できたりするけど実際はそうじゃないものが多いし
画面での操作禁止とそれらを無視して編集後のデータだけ送ってくるのだとチェックの仕方も違う
追加できないなら追加ボタン出さないだけで済むが、サーバー側だと送られてきた件数だけじゃなくてもともとあったものと一致してるかもチェックが必要とかそういうの
ウェブのほうが楽だからデスクトップアプリからウェブに移すがここ数年は多かったが本当に楽か?って思う
画面の柔軟性はあるが、そのせいであれこれ細かい注文がついたりしてそれも面倒が増える原因だし
ウェブだとそれが当たり前だからってサーバー側もデータのチェックしてるけどデスクトップアプリじゃそんなことしてなかった
それのリプレースなんだし、別にしなくていいんじゃないかと思う
デスクトップアプリだってサーバーと通信してるんだから直接リクエスト投げれるわけだし
ウェブなら便利な開発者ツールがあるから今送ったものの中身を見てちょっとか書き換えて送るが楽なだけ
デスクトップアプリだってパケットキャプチャしたり、逆コンパイルしてソースコード見ればできるわけだし
クライアント証明書があるから~とかいう意見聞いたことあるけど、ローカルにあるファイルなんだから、直リクエストするときだってそれ使えるよね
デスクトップアプリだと起動後のホーム画面から順番にボタンを押さないと画面を開けない
だから一覧画面で編集ボタンを出さなければその項目の編集画面は開けない
そのせいで一覧画面で編集ボタンを出さないのに加えて編集画面で自分が編集可能かのチェックまで必要になる
めんどくさい
考えてみればURLで直接開けることは要件にあるわけじゃないんだし、URLにマッピングしないメモリ内でのルーティングでもいい気はする
リロードすれば毎回トップページに戻るけど普段使う上でリロードなんかしないし別に問題ないと思う
Q.
1つのCPUコアでの逐次処理を高速化することには限界があるため、コア数を増やし並列化させることで性能を向上させる必要がある、という考え方について、市販のサーバコンピュータとスーパーコンピュータで違いはありますか?
A.
この考え方に関して、市販のサーバコンピュータとスーパーコンピュータの間には基本的な違いはありません。両者とも、シングルコアの性能向上に限界がある中で、並列化によって全体的な処理能力を高めるという方向性を共有しています。しかし、その実現方法や規模には大きな違いがあります。 サーバコンピュータとスーパーコンピュータの並列化アプローチの比較 1. 並列化の規模 サーバコンピュータ: 数個から数百個のコアを使用 スーパーコンピュータ: 数万から数百万個のコアを使用 2. 並列化の方法 サーバコンピュータ: 主にSMP(対称型マルチプロセッシング)やNUMA(非一様メモリアクセス)アーキテクチャを採用 比較的少数のプロセッサを密結合 スーパーコンピュータ: 大規模な分散メモリシステムを採用 多数のノードを高速ネットワークで接続 3. 相互接続技術 サーバコンピュータ: 一般的なネットワーク技術(イーサネットなど)を使用 スーパーコンピュータ: 専用の高速相互接続技術(InfiniBand、Tofu Interconnectなど)を使用 4. ソフトウェアとプログラミングモデル サーバコンピュータ: OpenMPやpthreadsなど、比較的シンプルな並列プログラミングモデルを使用 スーパーコンピュータ: MPIなどの複雑な分散メモリプログラミングモデルを使用 ハイブリッド並列化(MPI+OpenMP)などの高度な技術も適用 5. スケーラビリティ サーバコンピュータ: 中規模までの並列化に適しているが、大規模になるとスケーラビリティに課題 スーパーコンピュータ: 極めて大規模な並列化に対応できるよう設計されている 6. 用途 サーバコンピュータ: ウェブサービス、データベース、ビジネスアプリケーションなど、比較的汎用的な用途 スーパーコンピュータ: 気象予報、宇宙物理学シミュレーション、分子動力学計算など、極めて計算負荷の高い科学技術計算
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
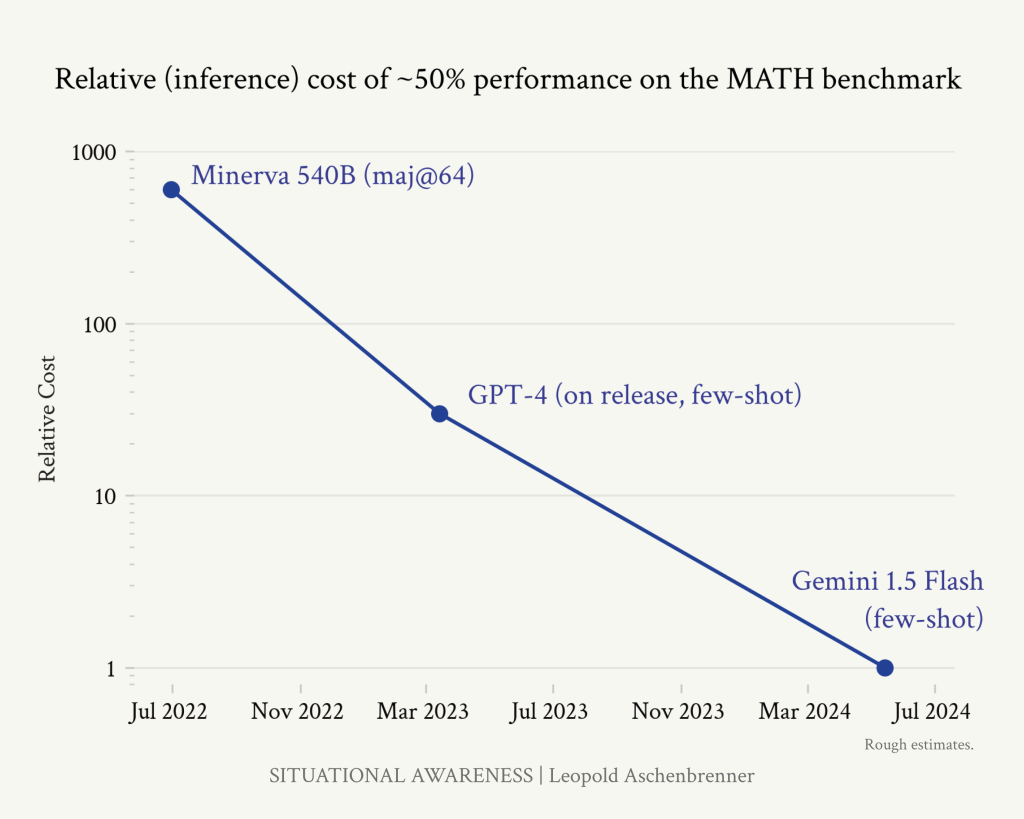
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
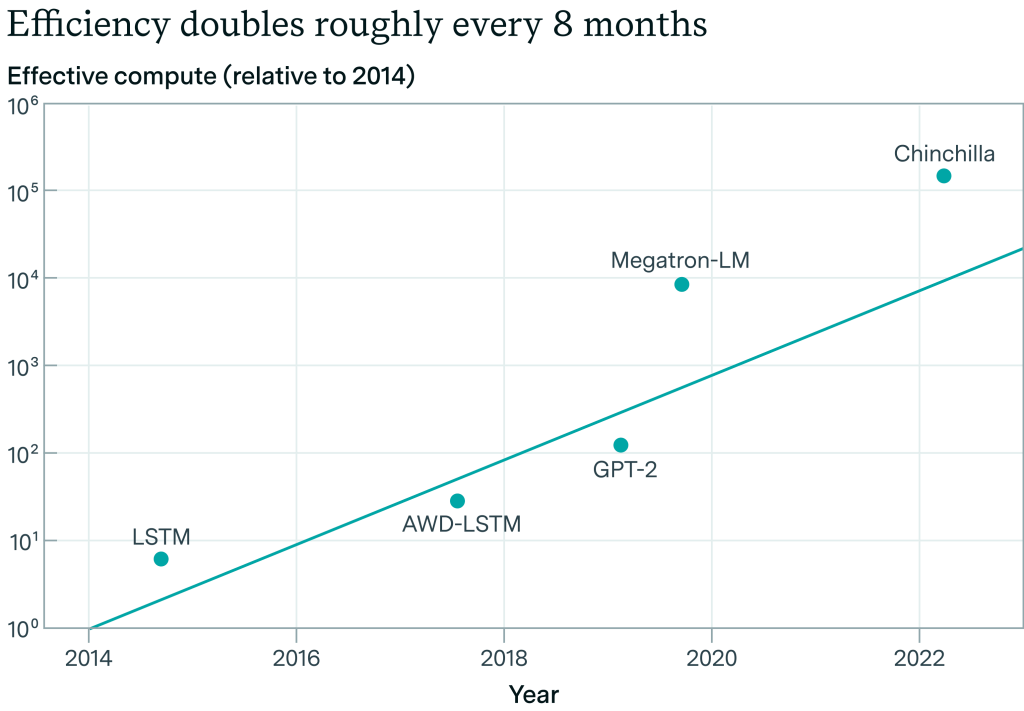
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
私はただの会社員で、栄養の関わる知識はネットに転がっている程度しかありません。
この献立表は作り置き用です。
日曜日にまとめて買い物→調理→冷蔵・冷凍するためのプロセスです。
本当に申し訳ないんですが、購入してからすぐにカッターで本を解体してスキャンしてPDF化します。(スキャン後はマスキングテープでくっつけて本棚に入れてあります)
PDF化する理由は、献立を組み上げる作業は全てPC上で行っていきますが、PDFの方が本よりもレシピを探しやすいというのが1番の理由です。
また、最後はレシピ1つ1つを画像ファイルにするので、一旦PDFにしておいた方がその作業が楽になるという理由もあります。
スキャン環境が無い場合は、タブレットやスマホを使用してレシピの内容まできちんと読める状態の解像度で撮影し、画像ファイルタイトルに頁数を振っておくといいです。
1つずつレシピを読み込んで表計算アプリケーションに情報を書き出します。
PC上で計画・管理、スマホ上で閲覧出来るのが理想なので、私はMicrosoftのオンラインExcel(無料版)を使用しています。
|【料理タイトル】|【ジャンル】|【調理方法】|【冷凍可否】|【PDF頁】|
上記の順番でセルに入力していきます。次から詳細を掘り下げます。
△:野菜なしでタンパク質のみ 例)鶏のてりやきからしマヨソース
緑:鶏肉
茶:牛肉
黄:たまご
青:魚
薄橙:大豆
使用されている調味料を元にジャンルを記入、セルの色付けをします。
色付けの凡例は次の通りです。
水色:お酢(さっぱり系)
9割は振り分けられますが以下のように振り分けが難しい料理もあります。
→オリーブオイルとしょうゆを使ってるけどどちらかといえば洋食かな~→薄緑
レンジ調理、フライパン調理、鍋調理、トースター調理等を記入します。
山本ゆりさんの一部のレシピ本には冷凍の可否が書かれていますが、冷凍NGの食材が使用していなければ自己責任でOK認定にしています。
→豆腐、じゃがいも、卵、きゅうり、レタス、水菜、アボカド、ちくわ等
この後に情報を入れ替える作業があるので、どのレシピがどこに掲載されているかを把握しておくために頁数を記入します。
https://f.hatena.ne.jp/lyri/20240522143436
※「翌日」は「翌日に食べないとだめ」、要するに「冷凍不可」を意味します。
※余談ですが、料理タイトルをグレーアウトしているのは新しい本において調理の未済管理のために私が作ってみたレシピに施しているだけです。左側の★は子供が美味しい連発したレシピです。△は子供の苦手食材、苦手調理方法を含んでいるレシピです。
現在は書き込んだ頁順にレシピが並んでいると思われますが、これらをタンパク質順にソートします。
https://f.hatena.ne.jp/lyri/20240523101436
こうすることで「鶏が足りない!」 「ここに豚が欲しい!」 「トマト系のレシピ無いかな~」 「レンジ調理できる副菜ないかな~」等、検討時のレシピの検索が非常に便利になります。また、PDF頁数も一緒に移動することで索引機能を果たします。
例)
主菜A:◎肉入り野菜炒め(玉ねぎ・にんじん・キャベツ)→主菜に野菜たっぷり入ってるな~「○かぼちゃの煮物」を添えとくか
主菜B:○ぶり大根(大根)→大根だけか~緑もないし「◎なすとピーマンの甘辛味噌」にしよう
どうしても「○主菜+○副菜」となる場合は【我が家の毎日食べても飽きない野菜】を味噌汁の具やサラダにしています。
キャベツ、大根、トマト、ピーマン、ごぼう、にんじん、かぼちゃ、ブロッコリー、おくら、わかめなど。もっと増やしたい。
これらの味噌汁とサラダは応急処置なので、わざわざ表には書いていません。
現在は子供が少食なので主菜と副菜のみにしていますが、もう少し大きくなったら味噌汁とサラダもレギュラー入りさせたいし、その時は味噌汁ルーティーンも組み込んでいきたいです。
(後で見本を載せていますが、現在は子供のストライクゾーンが和食に多いので偏りがちです。成長に伴って変革していきたいです)
理由は調理のモチベーションを保つため、1品目をレンジ調理している間に2品目の材料を切ったり下ごしらえをしたり出来るので時短になるため、レンジ調理したものはそのまま粗熱を取って冷蔵庫や冷凍庫に入れてしまうので、フライパンや鍋を洗う回数や手間を減らせるからです。
毎日作る時間が確保できるのであれば、フライパン調理のみで構成しても良いと思います。私も本当はそうしたいです。
火:主菜2 副菜A(冷蔵保存) ←副菜は原則2日間で食べきります
金:主菜5 副菜B(冷凍保存) ←副菜は原則2日間で食べきります
冷蔵:主菜1 主菜2 副菜A ←冷凍NG食材を含んでいてもOK
私は作り置きよりも作りたてのおかずを食べたい派です。なので、水曜日だけは子供が好きで野菜もたくさん食べられて比較的調理時間が短くて手間がかからないなおかずを組み込んでいます。親子丼、ピラフ、グラタン(ほぼシチュー)、オムライス、焼きそば、パスタ等です。
ただし、山本ゆりさんのレシピ(特にレンチンするやつ)は一旦冷まして味が浸透してから再度加熱して食べるとめっっっっっっっっっちゃくちゃ美味しいので、作り置きに向いているものが多いとも感じています。
冷凍したおかずの解凍方法は、食べる瞬間の24時間前頃から冷蔵庫に入れておくと自然解凍されます。
私は前日の夕食後に冷凍庫から冷蔵庫へ移動しています。そうすると冷蔵したものと同程度の加熱時間で食べられます。
ちなみに水曜の主菜3は使用するお肉や魚だけ日曜の買い物直後に冷凍して、火曜の夜に冷蔵庫に移動して自然解凍された状態で調理します。
https://f.hatena.ne.jp/lyri/20240523103013
水曜日のセルが黄色なのは、私が献立を考える際に「ここは固定!」とわかりやすくするために塗った名残なので特に意味はありません。
タンパク質、野菜数、ジャンル、調理方法のバランスが割と整っているのではないでしょうか。
完璧に組み立てるのは正直かなり難しいです。
例えば上画像の5週目の木曜と金曜は○と△で構成されてしまっているので、更に味噌汁を追加するか、もしくはバターしょうゆの味付けとスナップえんどうに合いそうな野菜(いんげんとかアスパラ?)を追加したいところです。味噌汁を新たに作る方が簡単で食卓の見栄えは良いです。
これらは更に小さいセルで管理すると見える化でき、ジャンルや野菜のばらつきをチェックできます。
入れ替えの際はこちらの更新も必要で面倒ですが、やっておくと新たなレシピを組み込む際に非常に明快になります。
https://f.hatena.ne.jp/lyri/20240522151313
入れ替えが発生する要因として1番多かったのは、ジャンルの偏りと野菜の偏りです。
中華系ばっかりで胃もたれやばいな!とか1週間ずっとブロッコリーとキャベツ食ってるな!等です。
散らすと飽きが来なくて良いです。
カレーやシチューは1ヶ月に1回にする等、何かを固定すると組み立てやすかったです。
また魚のレシピが少なくなりがちなので、まずは魚を設置してみるといいかもしれません。
主菜も副菜も夜に食べきってしまうのではなく、基本的に翌日の朝食とお弁当でも食べています。
金曜の主菜5は翌週月曜日の朝食とお弁当にするので、金曜分と月曜分に小分けにして冷凍すると尚良いです。
私は面倒なので金曜分をまるごと解凍して夕食に出し、その後粗熱を取って再冷凍しています。(あんま良くない?)
献立表を組み終わったらレシピのPDFから画像ファイル(PNGやJPEG等)を作成して、Googleドライブのようなクラウドストレージに格納します。
PDFを画像ファイルに変換するアプリケーションを使用したり、私はScreenpressoを使用して切り取っています。
https://f.hatena.ne.jp/lyri/20240523114245
これは4周目のフォルダです。1ファイル700KBくらいでした。サイズは600×600くらい。
文字が読める程度の解像度と読み込み速さを確保できれば良いです。
1レシピずつ参照しながら必要な食材や調味料を書き出します。使用個数まで書いておくとわかりやすいです。
→合計で1個あれば足りるね!使い切りたいから野菜南蛮に1/2個使うか!等の計画を立てられます。
記録は私はGoogleKeepを使用しています。PCで書き出し、店舗ではスマホで閲覧します。
材料は一旦全部書き出して、冷蔵庫に残っているものがあれば消していきます。
例えば私は玉ねぎ、にんじん、じゃがいもは袋で買っていて、冷蔵庫に残っていることが多いので照合します。
調味料は滅多に無くならないので書き出しの際に省略することが多いです。(使い切った時の達成感すごい)
そうするとリストを上から順番に追っていくだけで買い物が終わります。
野菜→魚→乾物→肉→乳製品みたいなざっくりとした順番で大丈夫です。
クラウドストレージに保存した画像ファイルを見ながら進めます。
収納ラック等で1段高い位置にスマホを置いて、調理場所を広く確保すると汚れないので良いです。
余談ですが包丁とまな板は2セット用意して野菜用と肉魚用で分けています。
以上です。
普段喋り言葉で草生やしまくりのブログ執筆やツイートしかしてないので至らない部分があったらご指摘ください。
最後に、私が実際に運用している献立表のジャンルと一部の野菜のばらつきを見える化した一覧表をご参考までに。
https://f.hatena.ne.jp/lyri/20240524094732
私はWebアプリケーション開発に関わっているエンジニアであり、社内の多くのエンジニアもWebやネイティブアプリの開発に従事しています。会社の規模は日本国内で言えば大きい方です。
そんな会社で働いている中で、最近著名なエンジニアが入社しました。私はその方をSNSなどで拝見しており、どんなアウトプットを出すのかとても楽しみにしていました(ただし、その方は私とは関わりのない部署に配属されています)。しかし、3週間が経過した現在、もやもやすることがあり、この日記を書いています。
まず、前提として、入社して3週間でアウトプットを出せる人は世の中にそう多くはないと思っていますし、それが高い職位で雇用されているなら尚更だと思います。なので、3週間経って何もアウトプットがないのは仕方ないことだと思います。システムに関する知識(解決したい課題、要件、仕様、関係者、社内事情、技術領域などなど)がまったくない状態で、そのキャッチアップに時間がかかるのは誰しも同じだと思います。
しかし、この3週間でその方がどういうアウトプットをするのか見たかったので、バージョン管理システムのログや社内チャットツールで色々と確認してみると、どうもその方は外部の登壇資料を作ることしかしていないようでした(実際には自社の仕事もしていましたが、登壇資料が9割を占めているように見えました)。
この行動に対してもやもやすることがありました。それは、「まず自社に貢献しないのか?」「登壇料をもらっているならそれは副業の範囲内であり、プライベートでやるべきではないのか?」です。その方がどういう期待値で入社しているのか分からないので、もしかしたら登壇も仕事の一環なのかもしれません。それでももやもやします。そもそも、自社の利益にその登壇は本当に貢献するのか?というところです。外部に登壇するくらいなら、自社向けに発表と質疑応答を行い、社内エンジニアの能力向上に貢献するほうが良いと思います。
よくある反論として「自社の宣伝になるから良いのでは?」というのがあります。それも理解できるのですが、それは自社で得られたノウハウを宣伝する場合に当てはまると思います。しかし、その方は入社後ほとんど自社のシステムに関わっていないので、その反論は当てはまらないと思います。
また、副業として登壇料を受け取っているようです。自分には直接の害はないのですが、これって会社から給料をもらっている時間に副業していることになり、副業規定に抵触するのでは?と思いました。私自身も副業でソフトウェア開発をしていますが、本業の時間に副業をしても良いのだろうか?と疑問に思いました。また、それが普通に許されているのもなんだかなーと思いました。まず、自社に貢献しろよ、と。
私がすごいと思うソフトウェアエンジニアは、やはり自社の課題をスマートに解決する方々だと思います。ですから、登壇ばかりしているエンジニアに高い給料を払っているのがもやもやします。
最後に、その方の職歴について思ったことがあります。あまり詳しくは書きませんが、おそらくそれなりに高い職位(テックリードなど)で雇用されていたと思います。職位が高ければ高いほど、成果を出すのに時間がかかると思いますが、その方は結構なペースで転職しています。それ自体は構わないのですが、もしかして自社に貢献できず、居場所がなかったのでは?と勘ぐってしまいます。この勘ぐりを加速させる材料として、その方の登壇や記事にはほとんど自社の話がないこともあります。
実は他にも色々ともやもやすることはありますが、このくらいにしておきます(登壇内容などにも疑問はありますが、それは個人の自由なので)。
まだ3週間しか経っていないので、これからどうなるのか分かりませんが、引き続きウォッチしていきたいと思います。離れた部署にいる人間から見えていることなので、細かいところは違うと思います(思いたいです)。これからどうなるのか、楽しみです。
githubでなにか作ったものをアップロードするのは、自分向きではないことに気がついた。
私が仕事で作っているようなwebアプリケーションというのは、誰でも使える一般性の高いものではなく、もっと特定のビジネスに依存した特殊なものである。
だから一般的な誰でも使えるようなものを作るというのにはあまり慣れていないのだ。
なにか作る場合はkaggleのほうが遊び場として向いていると思っている。
kaggleで「コンペ」に参加するつもりはないし、あれはBERTが出現したぐらいからは、少なくともNLP(自然言語処理)界隈は不毛な場となってしまった。
指標があれば不毛なハックがある。それが現実というものである。
それに業務で実用レベルで使えるモデルというのは、もっと運用のしやすいシンプルなモデルである。
モンスターアンサンブルで精度がSOTAでーすピロローン!なんてことには興味がないが、コンペはそれを目指している。
ではなぜkaggleが良いかと言うと、データセットが転がっていて、notebookも簡単に作成できるからである。
「このデータをこうやって使うとこういうツールが作れる」「このデータをこうやって分析するとこういう知見が得られる」というのは、「web開発用のMVCフレームワークを作ります」よりも具体性がある。
そして特定のデータに対するモデリングをするために論文を調べるようなことになった場合は、勉強にもなる。
私は昔、自然言語処理のブログを書いていたが、実験したことのコードを載せるタイプの記事が多かった。
ところが自称データサイエンティストや自称NLPエンジニアがツイッター上で「ゴミのようなブログを書くな」と言っていて、自分が言われている気がして怖くなったのでブログを閉鎖した。
そういう「政治おじさん」との接触を最大限減らすには、ブログというフォーマットではダメだと思うわけである。
私のマグカップには"Talk is cheap, show me the code."と書かれている。
これはリーナストーバルズの名言だが、政治おじさんが近寄らない場所というのは、具体的なコードが存在する場所であると言えよう。
世の中にはウンコのようなシステムがあるが、その最たるものとしては複数のアプリケーションでDBを共有するものだ。
まさに今取り組んでいるプロジェクトがその典型例だ。データの一貫性や整合性がとれないようなシステムはおむつに包んで汚物入れにいれるべきだ。
DBを複数のアプリケーションから共有するな。これだけのことを何度言わせるのか。
上記の問題を解決するために、他のソリューションを導入したりする。
ちがう、そこじゃないんだ。データはアプリケーションで閉じろって話だ。
根本的な問題は、要求事項から最適なシステムを作る人の不在だ。
REST APIの設計も酷いもので、エンドポイントがDBのテーブルそのままを表しており、トランザクションもクソもない。
APIがデータベースの構造に過度に依存しており、データベースの変更が直接APIの修正に繋がる。このため、些細な変更でも広範囲に影響が及ぶことになる。
一定年収以上がある超富裕層向けにTikT〇kは別なアプリケーションを提供していると妄想しながら視聴してる。
あれはカタログも兼ねていて、踊る女子たちは富豪アプリにだけ予約ボタンから今夜のSEXオークションができるのだ。
いいね!の数で更に売却価格にブーストが掛かる仕様なので、女子達は一生懸命淫らに惨めに腰を振る。
ジャバザハット並のデブハゲヲヤジ(超金持ち)と跡継ぎの頭が悪そうな息子に女の扱いを学習するというシュチュエーションで
インフルエンサーのあの子が壮絶おまんこをされてしまうシーンを考えながら、日曜に何考えてるんだろうと冷静になる午後13時頃。
Device Info は、高度なユーザー インターフェースとウィジェットを使用してモバイルデバイスに関する完全な情報を提供するシンプルで強力な Android アプリケーションです。たとえば、デバイス情報/ 電話情報には、CPU、RAM、OS、センサ、ストレージ、バッテリー、SIM、Bluetooth、ネットワーク、インストール済みアプリ、システム アプリ、ディスプレイ、カメラ、温度などに関する情報が含まれます。また、デバイス情報/ 電話情報は、ハードウェア テストでデバイスのベンチマークを行うことができます。
中身 : 👇 👇
👉 ダッシュボード : RAM、内部ストレージ、外部ストレージ、バッテリー、CPU、利用可能なセンサ、インストール済みアプリ & 最適化
👉 デバイス : デバイス名、モデル、メーカー、デバイス、ボード、ハードウェア、ブランド、IMEI、ハードウェア シリアル、SIM シリアル、SIM サブスクライバー、ネットワークオペレータ、ネットワークタイプ、WiFi Mac アドレス、ビルドフィンガープリント & USB ホスト
👉 システム : バージョン、コード名、API レベル、リリース バージョン、1 つの UI バージョン、セキュリティ パッチ レベル、ブートローダー、ビルド番号、ベースバンド、Java VM、カーネル、言語、ルート管理アプリ、Google Play サービスバージョン、Vulkan のサポート、Treble、シームレスな更新、OpenGL ES およびシステム稼働時間
👉 CPU : Soc - システム オン チップ、プロセッサ、CPU アーキテクチャ、サポート対象の ABI、CPU ハードウェア、CPU ガバナー、コア数、CPU 周波数、実行中のコア、GPU レンダラー、GPU ベンダー & GPU バージョン
👉 バッテリー : ヘルス、レベル、ステータス、電源、テクノロジー、温度、電圧と容量
👉 ネットワーク : IP アドレス、ゲートウェイ、サブネット マスク、DNS、リース期間、インターフェイス、周波数、リンク速度
👉 ネットワーク : IP アドレス、ゲートウェイ、サブネット マスク、DNS、リース期間、インターフェイス、周波数、リンク速度
👉 ディスプレイ : 解像度、密度、フォント スケール、物理サイズ、サポートされているリフレッシュレート、HDR、HDR 機能、明るさのレベルとモード、画面のタイムアウト、向き
👉 メモリ : RAM、RAM タイプ、RAM 周波数、ROM、内部ストレージ、外部ストレージ
👉 センサー : センサー名、センサベンダー、ライブセンサ値、タイプ、電力、ウェイクアップセンサ、ダイナミックセンサ、最大距離
👉 アプリ : ユーザーアプリ、インストール済みアプリ、アプリバージョン、最小 OS、ターゲット OS、インストール日、更新日、アクセス許可、アクティビティ、サービス、プロバイダ、レシーバー、抽出アプリ Apk
👉 アプリアナライザー : 高度なグラフを使用して、すべてのアプリケーションを分析します。また、ターゲット SDK、最小 SDK、インストール場所、プラットフォーム、インストーラ、および署名によってグループ化することもできます。
ディスプレイ、マルチタッチ、懐中電灯、ラウドスピーカー、イヤースピーカー、マイク、耳近接、光センサ、加速度計、振動、Bluetooth、WI-Fi、指紋、音量アップボタン、音量ダウンボタンをテストできます。
👉 温度 : システムによって指定されたすべての温度ゾーンの値
👉 カスタマイズ可能なウィジェット : 最も重要な情報を表示する 3 つのサイズの完全にカスタマイズ可能なウィジェット
👉 レポートのエクスポート : カスタマイズ可能なレポートのエクスポート、テキストレポートのエクスポート、PDF レポートのエクスポート
権限 👇 👇
READ_PHONE_STATE - ネットワーク情報を取得するには
BLUETOOTH_CONNECT - Bluetooth テスト
READ_EXTERNAL_STORAGE - イヤースピーカーとラウドスピーカーのテスト
3C コレクション全体が 1 つのパッケージに収まりました。 *
3C オールインワン ツールボックスは、多くの機能を最新の使いやすいインターフェイスを備えた 1 つの巨大なツールボックスに統合します。すべての Android デバイスを監視、制御、微調整するために必要なすべてのツール。
Play ストアでの最速かつ最もフレンドリーなサポート。アプリの設定、ヘルプ、サポートからお気軽にリクエストを送信し、懸念事項について言及してください。
一部の機能では、root が必要になるか、Android 6 以降以降の PC 用の 3C Companion アプリの使用が必要になる場合があります。
このアプリは、アプリを簡単に停止したり、アプリのデータを自動的にバックアップしたりできる 2 つのユーザー補助サービスを提供します。どちらも情報を収集することはありません。 プライバシー ポリシー
★ プロに移行するか、アプリ内購入を使用して、次の機能のロックを解除します
記録項目とオプション
ステータス通知から任意の機能にアクセスするための通知ショートカット
多くの追加ウィジェット
★ デバイス マネージャー は、非常に強力なプロファイル、タスク スケジュール、デバイス ウォッチドッグを提供します。
★ ファイル マネージャー は、サムネイルやフォルダー サイズなどを備えた、非常にシンプルでありながら非常に強力なエクスプローラーです。ビデオや写真をお気に入りのプレーヤーに直接ストリーミングします。ローカルでも、Samba、FTP、WebDAV、Google Drive、Dropbox の場所からでも。
★ アプリケーション マネージャー は、Titanium Backup をインポートする機能を含む、すべてのお気に入りのアプリのバックアップ/復元を提供します。また、Xused フレームワークを使用して、アプリのイベント、向き、フルスクリーン、および制御権限を保護およびカスタマイズすることもできます。
★ バッテリー マネージャー は、消費量の分析と改善に役立ちます。完全なデータ (mA を含む) と充電サイクルの履歴、プロファイルに基づくカスタム統計、使用時またはスタンバイ時の消費量の推定。デュアル バッテリー デバイス、バッテリーの交換、LG Quick Circle と Samsung Edge の通知に対する特別サポート★ バッテリー マネージャー は、消費量の分析と改善に役立ちます。完全なデータ (mA を含む) と充電サイクルの履歴、プロファイルに基づくカスタム統計、使用時またはスタンバイ時の消費量の推定。デュアル バッテリー デバイス、バッテリーの交換、LG Quick Circle と Samsung Edge の通知に対する特別サポート
★ ネットワーク マネージャー を使用すると、ネットワーク トラフィックの設定と監視が可能になります。
★ タスク マネージャー は、シンプルな UI を提供しますが、さまざまな用途に応じてアプリを分類し、不要なアプリを削除するのに非常に効果的です。
★ CPU マネージャー は、シングルからオクタコアの CPU、サーマル、マルチコア、およびほとんどのカスタム カーネル設定を制御します。
★ システム マネージャー では、Linux カーネル設定を構成できます。
★ROM マネージャー を使用すると、Android OS の設定を行うことができます。
★ すべてのアプリケーションとハードウェア コンポーネントのアクティビティを監視および記録します。履歴グラフィックを含むステータス バー通知が含まれます。
★ アプリ、ウィジェット、またはプロファイルのシステム コンポーネント スイッチにより、約 20 以上のデバイス コンポーネント (WiFi、Bluetooth など) のオン/オフを切り替えることができます。
はい、JavaScriptによるコーディングはコンピュータサイエンスの一部と見なすことができます。コンピュータサイエンスは、情報とその処理に関する学問であり、プログラミングはその重要な要素です。JavaScriptは、ウェブページを動的にするための主要な言語の1つであり、ウェブ開発の分野で広く使用されています。したがって、JavaScriptを学び、それを使用してコードを書くことは、コンピュータサイエンスの実践的な応用の一部と言えます。しかし、コンピュータサイエンスはプログラミングだけではなく、アルゴリズム、データ構造、ネットワーク、データベース、人工知能など、より広範なトピックをカバーしています。それぞれが特定のプログラミング言語やツールを使用して探求されることがあります。JavaScriptはその一部であり、特定の問題を解決するためのツールとして使用されます。それはコンピュータサイエンスの一部であり、その全体ではありません。それでも、JavaScriptをマスターすることは、コンピュータサイエンスの重要なスキルを習得するための素晴らしいステップです。それはあなたが複雑な問題を解決するためのロジックとアルゴリズムを理解するのを助け、あなたの思考を開発するのを助けます。それはまた、あなたがウェブ開発の世界に足を踏み入れ、あなた自身のウェブサイトやアプリケーションを作成するのを助けます。だから、はい、JavaScriptによるコーディングは確かにコンピュータサイエンスの一部です!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}