はてなキーワード: クローとは
過激なファンアートを「検索避け(伏せ字などを含む)」と呼ばれる手法で公開するケースがある。しかし、この方法は本当に効果的なのだろうか?
本記事では、検索エンジンの仕組みと「検索避け」の限界について解説し、情報公開における倫理的な問題について考察する。
想像してみてください。あなたが重要な機密文書を持っており、ファイル名と文書内の固有名詞を少し変えてインターネットにアップロードしたとします。
ファイル名と固有名詞が少し変わっても、内容が変わらなければ、文書は依然として機密文書のままです。
インターネットは、世界中の情報が集まる巨大な図書館と見なすことができ、検索エンジンはその図書館の賢い司書のような役割を果たします。
この「司書」は、本のタイトルだけでなく、内容や文脈を理解し、関連する情報を結びつけて、私たちが探しているものを見つけ出します。
したがって、名前を変更するだけでは検索エンジンを欺くことはできません。
検索エンジンはキーワード検索を超え、画像認識や文脈理解などの技術を活用して、関連する情報をつなぎ合わせて、目的の情報を見つけ出します。
情報を守りたい場合は、名前を変更するだけでなく、アクセス制限などの強固な保護策を講じる必要があります。
また、Twitterのような公開プラットフォームに隠したい情報をアップロードすることは、矛盾した行為です。
一般的に、公開プラットフォームにおいては、特定のコンテンツを検索エンジンから隠すための直接的な手段は限られています。
例えば、Twitterのようなプラットフォームでは、個々のユーザーがrobots.txtの設定やnoindexタグを利用してコンテンツのクローリングを制御することはできません。
公開プラットフォーム上のコンテンツは、基本的に検索エンジンによってインデックスされ、公開情報として扱われます。
近年、画像認識とAI検索技術は飛躍的に進化しており、「検索避け」の効果はさらに限定的になっています。
特に、CNNを用いた画像検索技術は、深層学習を活用して、画像内の細かな特徴まで識別することが可能です。
これにより、画像内のオブジェクトやシーンの認識、さらにはテキストの読み取りまで行えるため、
作品名やキャラクター名、一部デザインを変更したとしても、関連する過激なファンアートが検索結果に表示されることがあります。
一方で、AI検索では、Transformerアーキテクチャが主流となっており、文章全体を一度に処理することで、文脈を高度に理解することができます。
GoogleのBERTやMicrosoftのTuringモデルなどの進化したAI検索モデルは、単なるキーワード検索を超え、単語の組み合わせが表す複雑な概念や文章全体の意味を把握し、
その結果、過激なファンアートを投稿する際に、意図的に作品名やキャラクター名を避けたとしても、これらのAI検索技術により作品が特定されやすくなっています。
上記のように、現代の検索エンジンは高度な技術を駆使して情報を収集・分析しており、「検索避け」のような単純な対策では効果が期待できません。
現代の検索エンジンは、過激なファンアートを検出する一方で、高度なコンテンツフィルターを備えており、
社会倫理に反する画像を検出し、検索結果から除外する能力も持っています。
多くの公開プラットフォームでは、シャドウバンという手法を用いて特定のコンテンツの露出を抑制し、
過激なファンアートが一般ユーザーに表示されないよう努めています。
しかし、これらの技術が存在するからといって、過激なファンアートを無対策で公開することが許容されるわけではありません。
コンテンツフィルターやシャドウバンは完璧ではなく、不適切なコンテンツを完全にブロックすることはできません。
公開されるコンテンツが法的な規制や社会的な倫理に適合しているかどうかが重要であり、著作権侵害、名誉毀損、不快感を与える可能性のあるコンテンツは、
情報公開を行う際には、その影響を常に意識し、責任ある行動を取ることが求められます。
「検索避け」のような限定的な対策やコンテンツフィルターに依存するのではなく、倫理的な問題と情報管理の重要性を理解した上で、適切な判断を行うことが不可欠です。
例えば、過激なファンアートを公開する際には、その作品が特定のコミュニティ内でのみ共有されるようにクローズプラットフォームを利用する、
またはアクセスを制限するなどの措置を講じることが考えられます。
適切な情報管理とセキュリティ対策を施し、インターネット上での安全なコンテンツ共有に努めることが重要です。
情報公開の際には、法的な規制や社会的な倫理を尊重し、責任ある行動を取ることが求められます。
もともと上下に動くだけのヨーヨーがあって、それがハイパーヨーヨーとかで「スリープ(空転)」ができるようになった…というイメージだったけど、英語版Wikipediaによると、フィリピンからアメリカに移住したペドロ・フローレスが1928年に「ヨーヨー」という名前で売り出したのが現代的なヨーヨーの最初だという。
フローレスのヨーヨーは、糸を軸に固定するのではなく、糸の先端に輪っかを作ってそれを軸に通すような構造で、それにより「スリープ(空転)」ができるようになっていた。ただしフローレス自身はその機構の発明者ではなく、おそらくフィリピンで生まれた工夫なのだと思われる。
フローレスのヨーヨーはアメリカで大流行し、その流行の波が日本にもやってきた。それを受けて1933年(昭和8年)に『ヨーヨーの競技と遊び方』という書籍が出版された。日本ヨーヨー競技研究会というところが出したものらしい。
そこで紹介されている技は以下のとおり。
過激なファンアートを「検索避け(伏せ字などを含む)」と呼ばれる手法で公開するケースがある。しかし、この方法は本当に効果的なのだろうか?
本記事では、検索エンジンの仕組みと「検索避け」の限界について解説し、情報公開における倫理的な問題について考察する。
想像してみてください。あなたが重要な機密文書を持っており、ファイル名と文書内の固有名詞を少し変えてインターネットにアップロードしたとします。
ファイル名と固有名詞が少し変わっても、内容が変わらなければ、文書は依然として機密文書のままです。
インターネットは、世界中の情報が集まる巨大な図書館と見なすことができ、検索エンジンはその図書館の賢い司書のような役割を果たします。
この「司書」は、本のタイトルだけでなく、内容や文脈を理解し、関連する情報を結びつけて、私たちが探しているものを見つけ出します。
したがって、名前を変更するだけでは検索エンジンを欺くことはできません。
検索エンジンはキーワード検索を超え、画像認識や文脈理解などの技術を活用して、関連する情報をつなぎ合わせて、目的の情報を見つけ出します。
情報を守りたい場合は、名前を変更するだけでなく、アクセス制限などの強固な保護策を講じる必要があります。
また、Twitterのような公開プラットフォームに隠したい情報をアップロードすることは、矛盾した行為です。
一般的に、公開プラットフォームにおいては、特定のコンテンツを検索エンジンから隠すための直接的な手段は限られています。
例えば、Twitterのようなプラットフォームでは、個々のユーザーがrobots.txtの設定やnoindexタグを利用してコンテンツのクローリングを制御することはできません。
公開プラットフォーム上のコンテンツは、基本的に検索エンジンによってインデックスされ、公開情報として扱われます。
近年、画像認識とAI検索技術は飛躍的に進化しており、「検索避け」の効果はさらに限定的になっています。
特に、CNNを用いた画像検索技術は、深層学習を活用して、画像内の細かな特徴まで識別することが可能です。
これにより、画像内のオブジェクトやシーンの認識、さらにはテキストの読み取りまで行えるため、
作品名やキャラクター名、一部デザインを変更したとしても、関連する過激なファンアートが検索結果に表示されることがあります。
一方で、AI検索では、Transformerアーキテクチャが主流となっており、文章全体を一度に処理することで、文脈を高度に理解することができます。
GoogleのBERTやMicrosoftのTuringモデルなどの進化したAI検索モデルは、単なるキーワード検索を超え、単語の組み合わせが表す複雑な概念や文章全体の意味を把握し、
その結果、過激なファンアートを投稿する際に、意図的に作品名やキャラクター名を避けたとしても、これらのAI検索技術により作品が特定されやすくなっています。
上記のように、現代の検索エンジンは高度な技術を駆使して情報を収集・分析しており、「検索避け」のような単純な対策では効果が期待できません。
現代の検索エンジンは、過激なファンアートを検出する一方で、高度なコンテンツフィルターを備えており、
社会倫理に反する画像を検出し、検索結果から除外する能力も持っています。
多くの公開プラットフォームでは、シャドウバンという手法を用いて特定のコンテンツの露出を抑制し、
過激なファンアートが一般ユーザーに表示されないよう努めています。
しかし、これらの技術が存在するからといって、過激なファンアートを無対策で公開することが許容されるわけではありません。
コンテンツフィルターやシャドウバンは完璧ではなく、不適切なコンテンツを完全にブロックすることはできません。
公開されるコンテンツが法的な規制や社会的な倫理に適合しているかどうかが重要であり、著作権侵害、名誉毀損、不快感を与える可能性のあるコンテンツは、
情報公開を行う際には、その影響を常に意識し、責任ある行動を取ることが求められます。
「検索避け」のような限定的な対策やコンテンツフィルターに依存するのではなく、倫理的な問題と情報管理の重要性を理解した上で、適切な判断を行うことが不可欠です。
例えば、過激なファンアートを公開する際には、その作品が特定のコミュニティ内でのみ共有されるようにクローズプラットフォームを利用する、
またはアクセスを制限するなどの措置を講じることが考えられます。
適切な情報管理とセキュリティ対策を施し、インターネット上での安全なコンテンツ共有に努めることが重要です。
情報公開の際には、法的な規制や社会的な倫理を尊重し、責任ある行動を取ることが求められます。
倫理的な問題と情報管理の重要性を理解し、適切な判断を行うことが、情報公開の倫理と責任ある行動の核心です。
anond:20240607001500 anond:20240603171311 anond:20240702074550 anond:20240702093233 anond:20240702094052 anond:20240702094322
富士通に忖度してるとか言ってるけど、あれ、普通に取材NGだったんじゃないかな。
当時の経緯を知ってると「私の名前は出さないでください」ってなったとしても不思議じゃないと思う。そうなれば当然NHKも富士通も触れないし、本人が拒否したんですなんて発表するわけもないし(例え親族が声を上げたとしても)
京コンピュータって、富士通半導体の最後の打ち上げ花火だったんだよ。
京の開発が進み、実際に生産されるころは、経営方針として富士通は半導体撤退をするかどうかで揉めていたころだった。
京コンピュータは、富士通が自社工場で作った最後のスパコンであると同時に、国のトップ開発のHPCにおいて、富士通が単体で作り上げた初めてのHPCでもあった。
これは、富士通が優れている、というよりも、逃げ遅れたと表現してもよいかもしれない。HPCのプロジェクトからは、NECと東芝が次々と撤退していたのだ。
当時半導体の重い投資に堪えられなくなった電機各社とその銀行団は、自社から半導体部門、少なくとも工場を切り離したがっていた。まさに、それどころではなかったのだ。
しかし富士通はまだ撤退を決断せず、他社とは一線と画した対応をしていた。
ようにみえた。
京コンピュータのCPUは、45nmのプロセスで作ると言うことで言っていたためか、富士通はなんとか自社で開発した。けれど、京に乗せたプロセッサで最後になった。次のプロセスは開発されていない。
https://news.mynavi.jp/techplus/article/architecture-467/
さらに、当時、45nmのプロセスは安定して無い状況で無理矢理作ったと言う話もあったはずだ。これは京コンピュータ以降はTSMCに委託することが決まっていたため、既に投資が絞られていたためでもある。
(後にTSMC版の進んだプロセスで製造されたSPARCを使ったミニ京コンピュータが何個か作られたのだが、ノード辺りの性能が30%以上アップしたと言う。これはプロセスが細分化された以上の性能向上であった)
富士通が、自社の半導体部門を富士通セミコンとして切り離したのが2008年。京コンピュータ用のプロセッサを生産したのが2010年の三重工場であった。
その三重工場は2013年にさらに別会社として切り離され、現在は完全に売却されて富士通に残ってない。
また、同じく半導体工場としては福島県の會津富士通があったんだが、その時の工場撤退のエピソードは、今でも大企業は黒字でも簡単に工場を撤退させる事例として有名になった。かなり悲惨な事態だったと言える。
そうして重荷になっていたとされる工場を切り離しファブレスに近い業態にしたのは、富士通半導体を残すためだったと思われる。
しかし、そうした建前などなかったかのように2014年にはシステムLSI/SoCの開発部隊の分社化を決定。それが現在のソシオネクストである。PanasonicのLSI部隊と合弁した会社で、分離した当時、富士通は設立当初40%の株式を保持していたが、現在は完全に売却してしまった。
現在、富士通の半導体部門はFeRAMや光回路用の超特殊なものを除いて完全売却で撤退している。
なお、その後、ルネサステクノロジ(※富士通は合弁に参加していない)が組込向け半導体でほぼ世界首位と同率2位まで上り詰め、国内半導体の必要性が新たに叫ばれTSMCが国内に半導体工場を建設。Rapidusという日米政府が関わる半導体企業ができる流れになっている。もし将来、RapidusがプロジェクトXになるときには、大手電機産業からリストラされた技術者達の奮起という文脈が語られそうな気がする。閑話休題。
件の方がご退任をされたと言う2012年は、半導体のさらなる切り離し、売却などの決断と、次期スパコン(つまり富岳)がSPARCを捨ててARMになるという決断が行われた年であったと考えられる。(発表は後になる)
半導体を専門にされてずっとやってきた方には堪えられないもだったのではないかと拝察する。仮に、思い出したくもないし、宣伝にも使われたくないと判断されても仕方がないことでは無いかと思う。(もちろん 出演NGされたと言うのはワイの妄想なので注意)
その後、富士通はSPARCを使ったUNIXサーバーを作り続けてはいたが、大きくアーキテクチャを改善する開発は行われないまま(保守設計は続けられていたが)メインフレームとともに撤退が発表された。これはやむを得ないことだろう。
また、ARM化された富岳は、確かに性能面や利用面、汎用性では高い成果を出したが、富士通のビジネス的にはさっぱりだったと思われる。
アーキテクチャをARMに切り替えた理由は、ビジネス面でもあった。高性能タイプのARMを作ることによって、旺盛なクラウドDC需要などに対して食い込んでARMサーバを大きく拡販していくことだったと思われる。
が。富岳に乗せたARMプロセッサを利用した波及製品はみられなかった。
なぜか。それはAWS、MS Azure、Googleなど膨大な需要を持つ企業は、需要が巨大すぎてARMが搭載されたコンピュータを買うのではなく、自社でARMのIPを購入し独自開発することを選んだためである。
彼ら相手には商売にならなかった。それ以外のクラウドベンダーは無きに等しい。ARMなどアーキテクチャが影響しないのはPaaS以上の象徴度を持つサービスだが、寡占状態にある大手以外まともに提供出来ていないため、市場が無いのだ。
ただし、この時富士通とARMの競業によってARMは成果をあげた。アウトオブオーダー実行など、ARMは高性能コンピュータで必要な技術を富士通から取り込んで現在に至る。
それ故、富士通の商売は上手くいかなかったが、世の中的には良かったとは言えるのではあるのだ。そのIPで大手クラウド各社は自社向け半導体を作って商売をしているのだから。
だから今のタイミングでプロジェクトXに乗ったのだと思うが、綺麗事では語れない話がたくさんありすぎる。
受注はまず間違い無く富士通だと言われている。と言うのは、開発の一部は既に行われているから。
https://monoist.itmedia.co.jp/mn/articles/2310/12/news074.html
そして、国内にもう国産でHPCを作ることの出来る会社はNECと富士通ぐらいになってしまったためである。
富士通は新しいHPCは1位を目指さないかもしれないという考えから、計算効率の方に大きく振った開発を進めおり、国内トップのHPCに採用されたという実績を背景に売り出そうというつもりではあると思われる。富岳の夢再び、だ。
https://cloud.watch.impress.co.jp/docs/special/1560540.html
https://www.fsastech.com/about/
ご覧の通り、富士通のブランドを一切使っていないのだ。既存の商品からも富士通マークを取り払っている。さらに、会社概要に株主欄がなく、富士通の名前が出てこない。(他の関連会社はそういった記載がある)
半導体がどうなったかの流れを知っていると、暗い予感しかしない。
そして、HPCはレイヤーの低い、ハードウエアに近い部分、さらにメカニカルな設計や冷却など物理的な部分のノウハウが多く必要とされる。それを富士通が分社化して製造能力を失っていく中で、果たしてまともにHPCが作れるのだろうか?
さらに、確かに2010年代半ばのころはワークロード不足に陥ってコンピュータは安売りに陥っていたが、現在AIと言う巨大な需要が生み出され、価格も回復、ハードウエアが再び重要と考えられ始めている。ハードウエアと同時に提案できる能力が強みになりつつある。
しかし、既に富士通はそれらに対応するための強みを、はした金と決算の数字をよくするためだけに売り払った後である。案の定、粉飾紛いの異様に高い目標に対して、結果が出ないと言う発表を繰り返している。
富士通はアクセンチュアを真似ていると言われる。以下の記事にはこうある
https://xtech.nikkei.com/atcl/nxt/column/18/00848/00049/
目指す先はアクセンチュア、富士通が主力工場を総務に移管する理由
時田社長は2019年9月に開いた初の記者会見で「開発製造拠点をどう整理するのか」という質問に「既に方向は定まっている。後は状況判断と時期の問題。富士通はサービスに集中する企業になる」と応じていた。
そこまでやったのに、ここ3年ほど株価は伸び悩みが続いている。アクセンチュアの真似をしますと言ったときは撥ねたがが、その後は同業他社や業界全体の株価上昇率に及ばない状況が続く。
それはそうだ。アクセンチュアの真似をしていてはアクセンチュアには勝てない。まして工場売却を通じ、元々の強みを捨て弱みまでアクセンチュアの真似をしているのだ。富士通がこの先生きのこるにはどうすればいいのか?
私は以前、AGIへの短期的なタイムラインには懐疑的だった。その理由のひとつは、この10年を優遇し、AGI確率の質量を集中させるのは不合理に思えたからである(「我々は特別だ」と考えるのは古典的な誤謬のように思えた)。私は、AGIを手に入れるために何が必要なのかについて不確実であるべきであり、その結果、AGIを手に入れる可能性のある時期について、もっと「しみじみとした」確率分布になるはずだと考えた。
しかし、私は考えを変えました。決定的に重要なのは、AGIを得るために何が必要かという不確実性は、年単位ではなく、OOM(有効計算量)単位であるべきだということです。
私たちはこの10年でOOMsを駆け抜けようとしている。かつての全盛期でさえ、ムーアの法則は1~1.5OOM/10年に過ぎなかった。私の予想では、4年で~5OOM、10年で~10OOMを超えるだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/this_decade_or_bust-1200x925.png
要するに、私たちはこの10年で1回限りの利益を得るための大規模なスケールアップの真っ只中にいるのであり、OOMsを通過する進歩はその後何倍も遅くなるだろう。もしこのスケールアップが今後5~10年でAGIに到達できなければ、AGIはまだまだ先の話になるかもしれない。
つまり、今後10年間で、その後数十年間よりも多くのOOMを経験することになる。それで十分かもしれないし、すぐにAGIが実現するかもしれない。AGIを達成するのがどれほど難しいかによって、AGI達成までの時間の中央値について、あなたと私の意見が食い違うのは当然です。しかし、私たちが今どのようにOOMを駆け抜けているかを考えると、あなたのAGI達成のモーダル・イヤーは、この10年かそこらの後半になるはずです。
マシュー・バーネット(Matthew Barnett)氏は、計算機と生物学的境界だけを考慮した、これに関連する素晴らしい視覚化を行っている。
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
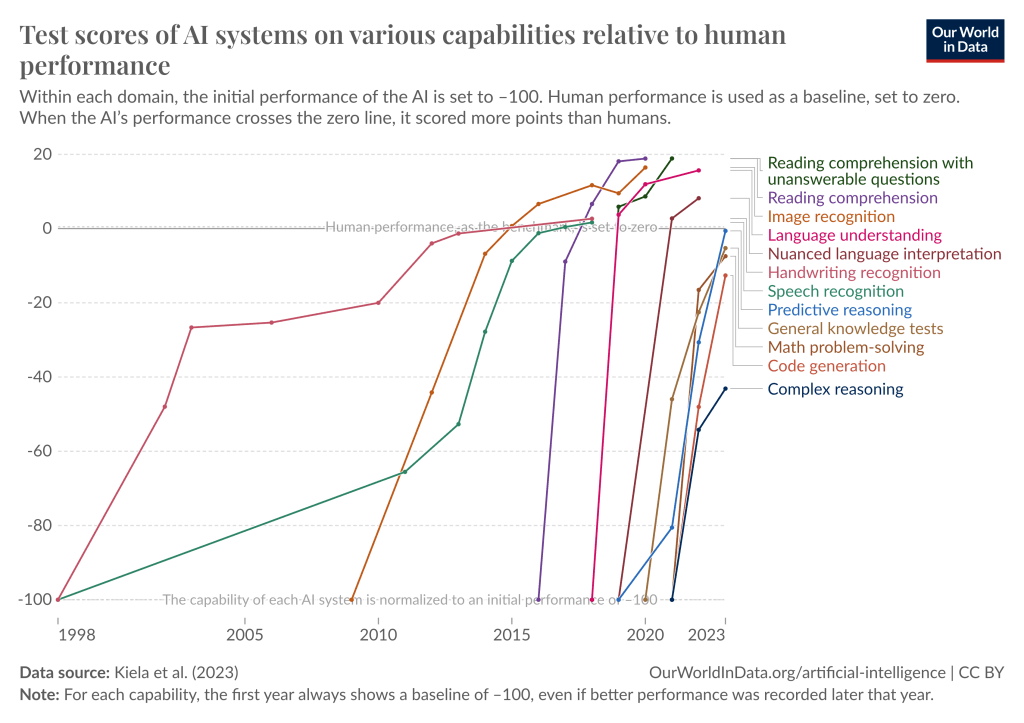
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
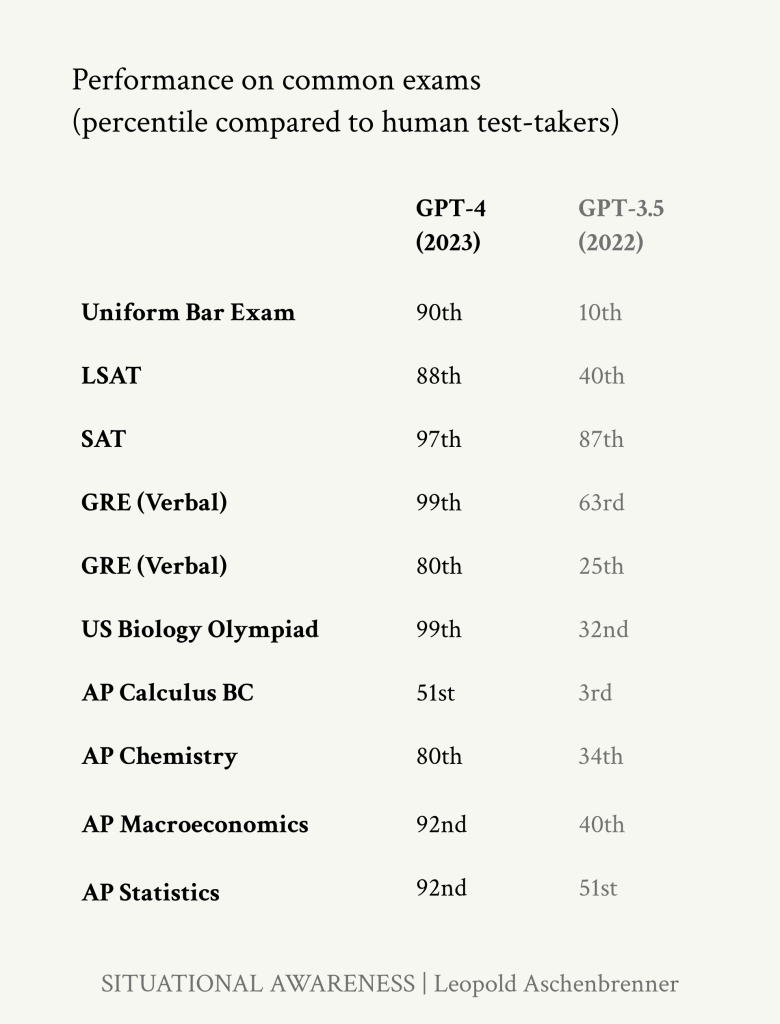
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
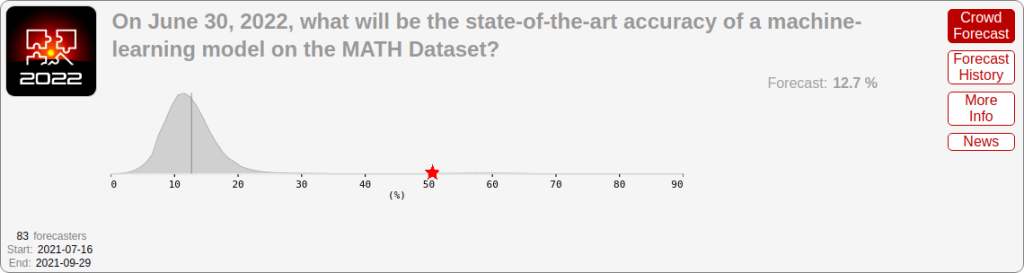
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
いや、おれも知らん。
文化資本(英語: cultural capital、フランス語: le capital culturel)とは、社会学における学術用語(概念)の一つであり、金銭によるもの以外の、学歴や文化的素養といった個人的資産を指す。フランスの社会学者ピエール・ブルデューによって提唱されて以来、現在に至るまで幅広い支持を受けている。社会階層間の流動性を高める上では、単なる経済支援よりも重視しなければならない場合もある。
wikipedia(https://ja.wikipedia.org/wiki/%E6%96%87%E5%8C%96%E8%B3%87%E6%9C%AC)
フランスの社会学者ピエール・ブルデュー,P.(Pierre Bourdieu, P.)とジャン=クロード・パスロン,J-C.(Jean-Claude Passeron, J-C.)が考案した概念で,人間の知識技能を資本として捉えたゲーリー・ベッカー,G.S.(Gary S. Becker, G.S.)の人的資本概念を文化領域に拡張し,貨幣や財の経済的側面のみならず,教育や文化の面において財が相続・生産・蓄積・投資される過程を説明する。文化資本は言葉遣いや立居振る舞いなどの身体化された様態,書物・絵画などの文化財所有による客体化された様態,学歴・資格によって制度化された様態からなり,それらを教育や就職など,経済的には「市場」となりうる「場=界(champ)」に投資することで,再生産戦略を可能にする物質的・象徴的な利益を引き出す。それは幼少期の家庭から相続継承され,学校教育を通じて中立的な能力証明へと変換され,社会的な地位や権力の再生産に結びつく。この概念によって,一見利害関係なく実践される文化慣習行動を,貨幣経済より広範な「象徴交換の経済」に取り込んで分析することが目指される。
コトバンク(https://kotobank.jp/word/%E6%96%87%E5%8C%96%E8%B3%87%E6%9C%AC-377212)
小難しいがようするに、
という前提があって、
・金だけでなく、文化的素養や学歴、スキルなどの見えない資産も子に受け継いでいるんだ!
ということなんだな。
で、その受け継ぐ過程で使われる個人的資産(=投資のもとになるもの=資本)を文化資本というらしい。
てことは、美術館それ自体は文化資本ではないやんけ!(個人資産じゃないから)
おいおい、「文化資本」という言葉もまた、はてなーたちの反知性主義によって意味が捻じ曲げられているじゃないか。
「なんか語感がかっこいいから、意味はよくわからんけど使ってみました」じゃねーんだよ。
美術館そのものではなく、「親が美術館によく行く習慣がある」とか、そういう「家のなか」の話なんだよ、文化資本てのは。
しかも資産や社会的地位の再生産に結びついていることが前提なのであって
庶民が「お、、おれはモネの展覧会とかよく行くし?」とか「いやー、声優の舞台挨拶が家から近くていいっすわ!」とかホクホクしてるのは文化資本じゃないんだよ。単なるエンタメ消費だそれは。アホか。
「親父が社長やってたんで、起業は自分にとって自然な選択肢でしたね」ってやつだよ。
あれこそ文化資本だよな。
・・・と、こうやって知らない言葉の意味の確認すら行わない、知的誠実さ皆無のお前らが親からたいした文化資本を受け継いでいないのは明白。
地方民は「美術館いってまーす☆文化資本文化資本☆」とかなんとか自慢してるスノッブどもを見下していいぞ。
・適当に調べたり考えたりしてみる感じ、居住地域に美術館だとかいい学校があるだとかは社会資本の話な気がするわ
・文化資本て、「親の語彙の豊富さ」とか「親同士の会話の知的水準の高さ」とか「親が教育資格を保有していて、知的水準の高いフィードバックが日常的に得られる」とか、「社会的地位の高いオトナとの会話機会の豊富さ」とか、そういうものなんじゃねーかな
・「文化資本の定義を都市や地域に援用」とか言ってるやつ、文化資本て社会階層の再生産を説明するロジックで生まれた言葉らしいから、「都民=殿上人、地方民=下層民!」的な東京の選民思想を前提に生きてるってことになると思うんだが、大丈夫そ?
・つーか、東京のなかでも当然ながら格差や階層があるわけで、そのなかでざっくり「もとの定義は家の話だけどぉ、都市に援用すればぁ」っつってるやつは、東京の内側で生まれている格差にはどう説明をつけるんだ?東京にいるだけで文化資本の恩恵を享受できるなら、東京の内側の社会格差はその他の地域と比べて小さくないといけないはずだろう。まずはそれを示してくれ
・いい学校とか文化施設へのアクセスを高めるために東京に住む、はたしかに「その判断能力があったり意思決定をする家庭である」という意味で文化資本があるといえそう。ただ、その意思決定の内実が本当にそうなのか?というのは問いたいところではあるな。なんとなく東京で就職したとか、職場が東京だからそのまま住んでますとか、そっちが主要因なやつも多いんじゃないの?
・いくつかブコメ読んで、格差を批判する文脈でなら都市間に援用してもいい気がしてきたが・・・仮に「都市の文化資本」という概念が成り立つ場合、以下が疑問。詳しい人おしえて
1.文化資本の枠組みだけで考えると、いい学校、いい美術館などは「客体化された形態の文化資本」に分類されるはずだが、そもそもこれらは社会資本ではないか?どう整理するのか?「ハビトゥスを形成しやすい環境が東京の文化資本」と言ってるやつもいるが、わざわざ"援用"せずとも「東京は社会資本が充実してますなー」で済むんじゃないか?
2.もとの定義に照らすかぎり、文化資本=経済的な格差・階層の再生産に結びつくものなので、「他地域よりも東京を経済的・社会的に特権的地位たらしめている、東京に特異的な文化慣習行動」が「東京の文化資本」ということになる。それってなに?そんなんある?
3.ここまで考えて、いわゆる「ユダヤの商法(ほんとにあるのかしらんが)」はユダヤ人の文化資本といえそう、つまり都市という地理的な要素よりは特定の価値観を共有する集団内においてなら、文化資本という概念は家を超えて援用できそうと思ったんだけど、どうなん?
抗うつ薬で太る薬といえばNaSSAと呼ばれる鎮静系抗うつ薬のリフレックス/レメロン(ミルタザピン)と三環系抗うつ薬のトリプタノール(アミトリプチリン)が代表的。
トリプタノール以外でも三環系抗うつ薬は効果が強いぶん副作用も強く、比較的太りやすいとされる。でも三環系は古い薬であり、第一選択薬じゃないので処方されてる人は比較的少ない印象。
あとは、抗精神病薬だけど抗うつ薬として使われることが多いドグマチール(スルピリド)も食欲が増進するイメージがある。
普通の人がまず処方されるであろうSSRIやSNRIは太るような副作用はそれほどない。
特に太りにくい抗うつ薬の代表格はSNRI。サインバルタ(デュロキセチン)、イフェクサー(ベンラファキシン)、トレドミン(ミルナシプラン)の3つ。
私は今までSSRIは全種類、SNRIはイフェクサーのみ服用したことがあるけれど、太ったことは一度もない
(SNRIは服用量が増えるにつれてSSRIでは一度も出たことのない副作用、ミオクローヌスが酷くなっていったので服用中止した)。
そのせいか、リフレックス/レメロン(ミルタザピン)と三環系抗うつ薬以外で「抗うつ薬で太った」と言う人を見かけると
「それって抗うつ薬の副作用ではなくて、うつ状態で運動量が落ちたことや精神状態が安定したことにより食欲が回復してきたからでは?」
「もしくは、うつ病の症状として過食が出ているのでは?」と思ってしまう。
抗うつ薬ではなく抗精神病薬ではジプレキサ(オランザピン)とセロクエル(クエチアピン)が太りやすいことで有名な薬だから、それらを服用してる人が太るのならまだ理解できるのだが……。
ChatGPTとクロードは頑張れば少しだけ書いてくれるけど。ChatGPTはバンの可能性がある。
seesaa Blogの検索機能、一覧機能の問題で1000話以前のリンクへたどり着くのは至難の業だ。まるで密教のようになっているソレを詳らかにしようと思う。
月別アーカイブで掘るのが効率的ってのを発見→ http://savannayagi.seesaa.net/archives/200909-1.html "200909-1"を変えていく
「0001話 2009/03/07 http://savannayagi.seesaa.net/article/115268130.html」から始まるんだがURLに規則性がない
クローリングするなら「2009/03/07以降の全記事を拾う」でいいかな
...
色盲も出たのもこの影響なんかな
精神原因による色覚異常の事例はあるでしょうか?気になったので調べてみました!
[Conversion disorder - Wikipedia](https://en.wikipedia.org/wiki/Conversion_disorder)
兆候と症状
(中略)
転換性障害は現在、機能性神経症状障害という包括用語に含まれています。転換性障害の場合、心理的ストレス要因があります。
DSM-5 に記載されている機能性神経症状障害の診断基準は次のとおりです。
患者には、随意運動機能または感覚機能の変化の症状が少なくとも 1 つあります。
a. 臨床所見は、症状と認識されている神経学的または病状との間の不適合の証拠を提供します。
b. この症状や欠損は、別の医学的障害や精神障害によって説明するのが適切ではありません。
c. 症状または欠損は、社会的、職業的、またはその他の重要な機能領域において臨床的に重大な苦痛または障害を引き起こすか、医学的評価を必要とする。
[以降関連する情報なし]
調べてみた結果、「ストレス性の色覚異常」(color blindnessもしくはachromatopsia)に関する直接的な言及は見当たりませんでした!
比較出来ないんじゃなくて、比較するのがナンセンスって話なんだけどまだ理解できない?
同じスポーツというジャンルの中でサッカーと野球、どっちが面白いかというのはプレイする人や見る人、その敷居の高さによって変化するよね
同じファンタジー漫画でも読む人のバックボーンやその時置かれている状況や環境によって面白さのベクトルやテーマが変化するのにどうやって比較するの?
比較してる作品もジャンルはバラバラ、富樫作品を出してしかもレベルEを一番にする俺わかってるよな(ドヤ)みたいなのが透けて見えるし短い文章も理解できず、比較することにしか焦点を当てない
子供が遊びで話す『スタローンとジャン・クロード・バンダムはどっちが強い?』そのレベルでいいよ、みたいな一文があるならまだ回答しようがあるのになw
軽微利用のくだり、その解釈だと検索エンジンも普通に違法にならね?
検索エンジン側で持ってるデータベースにクロールしたデータを全文ぶち込んでインデックス作ってないとこんな検索速度出せないでしょ
まさか検索するたびにクローリング走らせて全文中に検索ワードとの合致あるか調べて結果返すわけでもあるまいし
https://public-comment.e-gov.go.jp/servlet/PcmFileDownload?seqNo=0000267588
パブコメ用に素案も読み返してたんだけど、検索拡張生成(RAG)についての文化庁の見解は新聞協会のそれとはそもそも大幅な食い違いがありそう
https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/pdf/r1406693_17.pdf
というか問29に沿って考えれば、「情報解析によって時事情報(※ただの事実であって著作権によって保護されない)を表示する」が主であって、その過程における「既存の著作物を複製翻案等する」は従であるとも評価しうるのでは
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}