はてなキーワード: 研究とは
BBCラジオインタビュー:キャス博士に訊く、キャス・レビューついて。
https://www.jegma.jp/entry/CassReview-BBC
女性司会者:英国の18歳未満を対象としたジェンダー・アイデンティティ・医療サービスに関する報告書(レビュー)によると、医学的介入に関する調査不足と著しく弱いエビデンスに失望させられているといいます。小児科医ヒラリー・キャスの報告書は、こうも語っています。専門家たちは、彼女がジェンダーに関する議論の有毒性と呼ぶもののために、自分たちの意見をオープンに議論することを恐れてきた、と。
男性インタビュアー:待ちに待った、子どものジェンダー医療に関するキャスの報告書の結論は、医学界に響き渡るシンプルで手厳しい一文を含んでいます。ほとんどの若者にとって、医学的な治療法はジェンダーに関連した苦痛に対処する最良の方法ではないと、ヒラリー・キャス博士は述べているのです。
インタビュアー:思春期ブロッカーが安全に使用できるという証拠はありますか?
キャス博士:いいえ、今のところ、使用しても絶対に安全だという十分な証拠はありません。
思春期ブロッカーは、思春期が早すぎるという全く別の症状の子供や、ある種の癌を患う大人にも使われています。しかし、これは思春期を抑制するという新しい使用法です。ブロッカーが脳の発達に長期的にどのような影響を与えるかは分かっていません、というのも思春期には脳の発達が急速に進むからです。
また、ブロッカーがジェンダーや性心理の発達の軌跡を変えてしまうかどうかも分かっていないのです。
インタビュアー:医学の世界では、未知のものが一つの分野で大量に使用されるというのは標準的なことなのでしょうか?
キャス博士:研究チームは臨床試験から始めましたが、臨床試験結果が出る前に日常的な処方に移行し、さらに幅広い若年層に処方するようになった時点で、エビデンスから逸脱しました。
「ChatGPTのLLMのサービス開発に取り組みたい」
「Reactを使ったモダンな開発をやっていきたい」
みたいなキラキラしたこと言って入社してきた技術系新人、どいつもこいつもタイピングが遅い
Vim、Emacs、VSCodeとかそういう派閥争いする前にそもそもタイピングが遅い
画面共有してもらって見ながら指示してるんだけどタイピング遅すぎてめちゃくちゃ生産性低い
普段からチャットしてないからSlackとかも全然返信来なくて
書き込み中のままかなり時間経過してちょろっと文章だけ送られてくる
例えるならサッカー選手で足がクッソ遅いみたいな
どこのポジションでも無理だよ
ググってみるとそれと矛盾するような結果の統計も山ほど出てくるのがこのあたりの業界なのよ。
コンセンサスがまるで取れてないものも多くある。これは転職とか、年収とか労働関係の話でもそう。
そういうのを取り除いて、ずっとその研究をしている研究者が利用しているものだけを取り出したのが元増田なので、もうすこし丁寧に、コンセンサスがある話を基礎にしてほしい。
基礎的な話を踏まえた上で、異端の一意見として言うならアリだけど、そうじゃないんだというために探してくるようなものはやめてほしい。
志村の刑事組織犯罪対策課の佐藤がうれしそうな顔をして、もの、であるといっていたが、ものじゃねえから全然面白くないし、何言ってるのか分からなかったな。
法学は技術先にありきだろ。 品田幸男も、とにかく、ものであると言いたがるが、 法学は、 技術とものを一体として研究する学部だからな。
言いたいことをまとめると
さらに言うと
以下本文(別に読まなくて良い)
こんな増田があった。
つぶやき的な増田だけど、素朴に基礎知識を持っている人の感想というところであろう。
しかし、それに対しての反応に、未だに基礎知識がなく印象論だけで話をしている人が多く居るという事を見かたので、改めて書いてみる。
この他にも、元々東京都が婚活アプリを整備すると言う話 [注5] に対しても微妙な意見があるので整理してみる。
ちなみに前書いた増田
https://anond.hatelabo.jp/20231208002645
子育て支援のほうが合理的、そんな意見があるが、それは間違っている。何故かと言うと、少子化の主因を捉えていないから。
これは繰り返し言われてきたが、少子化の主要因は、非婚化と言われている(注1)
詳しくは注記に文献を上げておくので見てほしいが、簡単に言うと
と言う状況があるためだ。
結婚した夫婦がもうける子どもの数は微減状態にはあるが、そこに合計特殊出生率の変化のグラフと、婚姻率のグラフを重ねてみてほしい。そうすれば、夫婦が設ける子どもの数は横這いで、結果として表れる合計特殊出生率の変化のグラフとは重ならないが、婚姻率のグラフは綺麗に重なることがわかるだろう。一目瞭然で「結婚した夫婦も減ってるじゃ無いか」と言うのは枝葉であり、全くマトを得てない事が分かると思う。
少なくとも「対策の合理性」という観点から検討すると合理的とは言いがたい。
ただ、この点についても重要な視点がある為、あとで少し書いてみる。どちらにしても少子化支援で解決は難しい。
このように、結婚しない人を結婚させるより、3人目を諦める人を支援した方が良いと言う事実はない事も既に研究で明らかになっている。確かに理想の人数の子の数を諦めた理由という調査では、その理由に経済を上げる人が多いが、統計で分析すると
要するに夫婦の子どもの数を増やすには、最も合理的な手段は晩婚化対策であるだと言うことになるが、政治的にタブーでありこの路線はほぼ無理であるとも言える。ただ、やるべきではあるのだが、これは子育て支援の方面ではない。
もちろん、
ただし
子育て支援は少子化対策としては有効ではないと言うことをとにかく認識してほしい。
よく「子育て支援・少子化対策」と並べる人がいるが、この二つは似て非なるものである。少子化対策とは別に考えるべきだ。
と言うことになる。
この施策を真っ向からストレートに捉えると、出会いを作って結婚してもらうと言う事になるだろう。色々な所が取り組んでいる。それを東京都がやるのが東京都が行う管掌のマッチングアプリという事になるだろう。
ここで「合理的か」という観点から見るとき考えなければならないのが、この施策にかかるリソースだが、東京都がこの婚姻支援に入れる予算は、たったの3億円である。(注5)
福祉予算としては圧倒的に低く、はっきりと東京都レベルでは誤差の範囲の予算だ。例えば、都庁のプロジェクションマッピングの半額以下である。
予算が低いことが問題ではない。むしろ「合理性」という観点では低い予算で高い効果が上がる可能性が高いと言うことだ。3億円では都心の100人規模の保育所の運営費にも満たないと思われる。
色々な資料を読んでいると、非婚化・晩婚化による少子化は1990年代から既に言われていることで(注1) この程度の予算でできる事をなぜやってこなかったのか、とどうしても思ってしまうが、過去の事は仕方が無い。
これからでもよいのでやるべきだ。
さて、優先順位の3番目にきている「晩婚化対策」についても触れたいと思う。
晩婚化対策が何故必要かは、既に述べた理由の再掲にはなるのだが、まとめると
また、
さて、晩婚化対策とはなんだろうか?これは2つ考えられ
の二つがある。
政策的にやりやすいのは明らかに後者である。1は大事だが、これは政治的にタブーであるし、現実問題出来るのかという事がついて回る。
一方で後者はやりやすい。と言うのは、いずれの統計でも、いずれの時代にも「結婚したい」と考える独身者の率は年齢が上がるほど延びて、一定を超えると諦めて減ると言うカーブを取るからである。
ただしこれは子育て支援とは切り口が異なる。政策的には子育て支援に含められている場合も多いが「不妊治療の公的扶助の拡充」などがそれにあたる。
子育て支援と異なるのは何かと言うと、保育所の支援、学費の無料化などは「既に生んだ後」の支援である。実はこれが少子化対策には効果が薄く非合理的だと言われる。
直接的に生みたいが生めないと言う人々を支援することが有効なのだが、何故か少子化対策に対してこちらの方が手薄になっている。
少子化対策予算などいくらでも出せるのだから全部やればいいと思うのだが。
おこなわれないのは、属性の人々はあまり政治層に声を上げないし、代弁して声を上げるような社会団体が無いからだと思われる。
再掲するが、せめて
が必要だ。
政治的に
みたいなことを堂々といったら炎上するだけで難しいのはわかる。例えば、子育て支援は所得制限無し無制限が支持される一方で、自治体が頑張って結婚相談所を作っても参加補助どころか無料も無理で、実費請求されるところがほとんどだ。
今回の件も、例えば朝日新聞の報道( 注5) にも「行政がやる事か?」「結婚しろという圧力になる」と言った的外れなコメントが、有識者枠で掲載される有様だ。有識者と言いながら単なる社会活動家のポジショントークに過ぎないのだが、ほぼ例外なく誰もが当事者であるから出てきてしまうのであろう。
これは有権者の支持が得られないというところであろう。
が、もうこれを上手くオブラートに包んで実行していくほかにないのでは無いと思われる。
子育て支援をするなと行っているのでは無い。子育て支援はやるべきだ。しかし、子育て支援は少子化対策にならないのを直視して、少子化対策は別枠でちゃんとやってくれと言う事である。
少なくともこの現実を直視し、正しい基礎知識を持った上で、婚姻支援を合理的ではないなどいった誤った考えを早く正すべきだと考える。また政治活動家がロビー活動をする時も、この論法を使うことは控えてほしい。もっと他に手頃なスケープゴートがあるだろう。
冷静に考えてほしい。東京都だけで2兆円ちかい子育て関連予算に対して、3億円の施策が何だというのか? そして誰も「子育て支援を削って非婚化対策しろ」なんて考えで施策を行ってないのである。
少子化対策は非常に重要な問題で、主要な政治家はみな積極的に取り組んでいる状態だ。子育て支援と婚姻支援がトレードオフの関係にある訳がないから、必要なら両方やれば良いのだ。
正しい知識をもって行動してほしい。
アドレス載せすぎてスパム判定されたので、h抜きにしてあります。
入らなかったので別エントリで
言いたいことをまとめると
さらに言うと
以下本文(別に読まなくて良い)
こんな増田があった。
つぶやき的な増田だけど、素朴に基礎知識を持っている人の感想というところであろう。
しかし、それに対しての反応に、未だに基礎知識がなく印象論だけで話をしている人が多く居るという事を見かたので、改めて書いてみる。
この他にも、元々東京都が婚活アプリを整備すると言う話 [注5] に対しても微妙な意見があるので整理してみる。
ちなみに前書いた増田
https://anond.hatelabo.jp/20231208002645
子育て支援のほうが合理的、そんな意見があるが、それは間違っている。何故かと言うと、少子化の主因を捉えていないから。
これは繰り返し言われてきたが、少子化の主要因は、非婚化と言われている(注1)
詳しくは注記に文献を上げておくので見てほしいが、簡単に言うと
と言う状況があるためだ。
結婚した夫婦がもうける子どもの数は微減状態にはあるが、そこに合計特殊出生率の変化のグラフと、婚姻率のグラフを重ねてみてほしい。そうすれば、夫婦が設ける子どもの数は横這いで、結果として表れる合計特殊出生率の変化のグラフとは重ならないが、婚姻率のグラフは綺麗に重なることがわかるだろう。一目瞭然で「結婚した夫婦も減ってるじゃ無いか」と言うのは枝葉であり、全くマトを得てない事が分かると思う。
少なくとも「対策の合理性」という観点から検討すると合理的とは言いがたい。
ただ、この点についても重要な視点がある為、あとで少し書いてみる。どちらにしても少子化支援で解決は難しい。
このように、結婚しない人を結婚させるより、3人目を諦める人を支援した方が良いと言う事実はない事も既に研究で明らかになっている。確かに理想の人数の子の数を諦めた理由という調査では、その理由に経済を上げる人が多いが、統計で分析すると
要するに夫婦の子どもの数を増やすには、最も合理的な手段は晩婚化対策であるだと言うことになるが、政治的にタブーでありこの路線はほぼ無理であるとも言える。ただ、やるべきではあるのだが、これは子育て支援の方面ではない。
もちろん、
ただし
子育て支援は少子化対策としては有効ではないと言うことをとにかく認識してほしい。
よく「子育て支援・少子化対策」と並べる人がいるが、この二つは似て非なるものである。少子化対策とは別に考えるべきだ。
と言うことになる。
この施策を真っ向からストレートに捉えると、出会いを作って結婚してもらうと言う事になるだろう。色々な所が取り組んでいる。それを東京都がやるのが東京都が行う管掌のマッチングアプリという事になるだろう。
ここで「合理的か」という観点から見るとき考えなければならないのが、この施策にかかるリソースだが、東京都がこの婚姻支援に入れる予算は、たったの3億円である。(注5)
福祉予算としては圧倒的に低く、はっきりと東京都レベルでは誤差の範囲の予算だ。例えば、都庁のプロジェクションマッピングの半額以下である。
予算が低いことが問題ではない。むしろ「合理性」という観点では低い予算で高い効果が上がる可能性が高いと言うことだ。3億円では都心の100人規模の保育所の運営費にも満たないと思われる。
色々な資料を読んでいると、非婚化・晩婚化による少子化は1990年代から既に言われていることで(注1) この程度の予算でできる事をなぜやってこなかったのか、とどうしても思ってしまうが、過去の事は仕方が無い。
これからでもよいのでやるべきだ。
さて、優先順位の3番目にきている「晩婚化対策」についても触れたいと思う。
晩婚化対策が何故必要かは、既に述べた理由の再掲にはなるのだが、まとめると
また、
さて、晩婚化対策とはなんだろうか?これは2つ考えられ
の二つがある。
政策的にやりやすいのは明らかに後者である。1は大事だが、これは政治的にタブーであるし、現実問題出来るのかという事がついて回る。
一方で後者はやりやすい。と言うのは、いずれの統計でも、いずれの時代にも「結婚したい」と考える独身者の率は年齢が上がるほど延びて、一定を超えると諦めて減ると言うカーブを取るからである。
ただしこれは子育て支援とは切り口が異なる。政策的には子育て支援に含められている場合も多いが「不妊治療の公的扶助の拡充」などがそれにあたる。
子育て支援と異なるのは何かと言うと、保育所の支援、学費の無料化などは「既に生んだ後」の支援である。実はこれが少子化対策には効果が薄く非合理的だと言われる。
直接的に生みたいが生めないと言う人々を支援することが有効なのだが、何故か少子化対策に対してこちらの方が手薄になっている。
少子化対策予算などいくらでも出せるのだから全部やればいいと思うのだが。
おこなわれないのは、属性の人々はあまり政治層に声を上げないし、代弁して声を上げるような社会団体が無いからだと思われる。
再掲するが、せめて
が必要だ。
政治的に
みたいなことを堂々といったら炎上するだけで難しいのはわかる。例えば、子育て支援は所得制限無し無制限が支持される一方で、自治体が頑張って結婚相談所を作っても参加補助どころか無料も無理で、実費請求されるところがほとんどだ。
今回の件も、例えば朝日新聞の報道( 注5) にも「行政がやる事か?」「結婚しろという圧力になる」と言った的外れなコメントが、有識者枠で掲載される有様だ。有識者と言いながら単なる社会活動家のポジショントークに過ぎないのだが、ほぼ例外なく誰もが当事者であるから出てきてしまうのであろう。
これは有権者の支持が得られないというところであろう。
が、もうこれを上手くオブラートに包んで実行していくほかにないのでは無いと思われる。
子育て支援をするなと行っているのでは無い。子育て支援はやるべきだ。しかし、子育て支援は少子化対策にならないのを直視して、少子化対策は別枠でちゃんとやってくれと言う事である。
少なくともこの現実を直視し、正しい基礎知識を持った上で、婚姻支援を合理的ではないなどいった誤った考えを早く正すべきだと考える。また政治活動家がロビー活動をする時も、この論法を使うことは控えてほしい。もっと他に手頃なスケープゴートがあるだろう。
冷静に考えてほしい。東京都だけで2兆円ちかい子育て関連予算に対して、3億円の施策が何だというのか? そして誰も「子育て支援を削って非婚化対策しろ」なんて考えで施策を行ってないのである。
少子化対策は非常に重要な問題で、主要な政治家はみな積極的に取り組んでいる状態だ。子育て支援と婚姻支援がトレードオフの関係にある訳がないから、必要なら両方やれば良いのだ。
正しい知識をもって行動してほしい。
アドレス載せすぎてスパム判定されたので、h抜きにしてあります。
今までの話を読んできてもらった人には、完全に誤った議論であることはわかっていただけると思うのだけれど、どうしてもこう言う事を言う人がいる。
ただ、一点だけ「既に金がある奴を支援するべき」はその通りで、そのための施策がマッチングサービス・非婚化対策なのである。
統計で見ると、結婚しない・出来ない理由は、トップが「出会いがない」で次いで「経済的理由」である。
経済的理由と出会いが無いはほぼ同率なので、両方に手当てをする必要がある。
そして未婚男性で最も多いのは年収500万円以上なので、経済だけを協調して、マッチングサービスなど出会いを作る施策を非合理的だとする理由はない。
両方やれば良いし「合理性」で考えるならば、マッチングサービスなどの単純な婚活支援が最初に来るだろう。
参考: ttps://president.jp/articles/-/63789 婚活市場では"高望み"の部類だが…「年収500万円以上の未婚男性」が最も余っている皮肉な理由
引用:
涯未婚率対象年齢である45~54歳男女の未婚人口を年収別にみると、未婚男性でもっとも人口が多いのは500万円以上の年収層になります(2007~2017年の10年推移)。これは2007年も同様で、比率にしてしまうと小さくなるのですが、実数としては「婚活女性が高望みといわれてしまう年収500万円以上の未婚男性」がもっとも余っている
わずかにそう言った傾向はあるかも知れないが、基本的には誤り。根拠としては、結婚する理由に「子どもが欲しいから」と答える人が減っているという事を上げることが多いが、子どもが欲しいからと上げていた Permalink | 記事への反応(0) | 12:26
ナショジオの菌類特集読んでたら、霊芝(干からびたカタツムリみたいなキノコで、漢方になる)はマジで癌に効く可能性があるらしい。
西洋科学の分析でわかるのはいいが、昔の人間はなぜ、これが体にいいとわかったんだ。癌患者AとBの一方には霊芝を食わせて、もう一方には食わせない、を百年単位で繰り返し、別のコミュニティと共有する中で確立したのか。
それとも、薬効を謳ったもので偽物もたくさんあるわけで(水銀とか)、近代の研究で迷信が淘汰された中でたまたま残った本物が、いかにも昔からの叡智の結晶みたいに見えるだけなのか。わからん。
追記。
不思議な点をもっと書き連ねると、同じ癌患者Aと Bに霊芝を与えるのでも、Aと Bで体質も違えば癌の種類も違うだろうから、薬効はそう簡単にわからないはずだ。
A Bどころじゃない膨大なサンプルが必要だと思うが、今度は誰が、それを記録して伝承しているのだ。シャーマンとか本草学か。
また、霊芝だけに使用を限定したとも思えないので、薬草も使えば、動物の骨とか、鉱物とかも併用しただろうし、その中で、「よし、霊芝だな…」と特定され成果として残るのはマジですごく不思議。
いや、特定されきってないから変な迷信とかがまだいっぱい残ってるんだ、とか、動物の進化が奇跡的な形を生むように、膨大な時間の流れにはそれだけのトライアンドエラーを許す余地があるとか、今は人道的にNGだけど、昔は奴隷とか賎民にめちゃくちゃやれたから発達したんだ、とか、合理的な説明はつくかもしれないが、「?」というデカい疑問符は消えない。
もっとも、ナショジオでも「効く可能性がある」ぐらいに書かれているだけなので、実際にどの程度奏功するかどうかは知らない。「信じて飲んだけど効かなくて俺死んじゃったよ」と言われても、線香ぐらいは立ててもいいが責任は取れないので、付記しておく。
https://www.nikkei.com/article/DGXZQOUD226TU0S2A121C2000000/
これではいくらエッチしても妊娠できないから、少子化が進行する。
原因は、マイクロプラスチック。
すべての男性の精巣から「マイクロプラスチック」が見つかったとの研究結果、生殖能力に影響を与えている
https://gigazine.net/news/20240522-microplastics-human-testicles/
人類の衰退は避けられない。
田舎には「とりあえずの仕事」と「ホワイトカラーの仕事」がほとんど無いんだよ
「高収入な仕事」も少ないけど、立地する工場によっては専門職、研究職、技術職で高収入田舎暮らしもありうる
うちの地元にはでかい企業のでかい工場があって、研究員とかが転入してきている
小学校で飛び抜けて頭いい子がいたら、だいたい研究員のご家庭の子
幾何学でいってなんでパスカルの定理は完全無欠と言われるかと言うとまだ分からない。1つには2000年前から研究があるという割にはろくな書物は存在しておらず
大量の研究があると言いながら、ほとんどの定理が知られていない。 方べきの定理とパスカルの定理は何が違うのか、それすら教えてもらっていない人が多いのではないか。
完全無欠な定理があれば、ゆくゆくはなんでもできる。 だから完全無欠なものは教科書でなるべく集めた方がいい。それがあれば行き詰まることはない。
とはいいながら、何をもって完全無欠であるかというと、まだ分かっていない。 超対称性の原理というのは、ただの対称性ではなくて結構、Higherな対称性でよく分かっていないので
チェスの問題に出てきた操作は超対称性ではなくてまったく間違っていて、おぺちさんという天才がいてそれはただの簡潔なテクニックで、超対称性はお前が考えるよりもっと、レベルの高い
対称性で、そういうものではないと言われ、なんでも、そういったものは界隈で完全無欠と指定され、可能性があるから、魅力があるのに決まっている。
私は以前、AGIへの短期的なタイムラインには懐疑的だった。その理由のひとつは、この10年を優遇し、AGI確率の質量を集中させるのは不合理に思えたからである(「我々は特別だ」と考えるのは古典的な誤謬のように思えた)。私は、AGIを手に入れるために何が必要なのかについて不確実であるべきであり、その結果、AGIを手に入れる可能性のある時期について、もっと「しみじみとした」確率分布になるはずだと考えた。
しかし、私は考えを変えました。決定的に重要なのは、AGIを得るために何が必要かという不確実性は、年単位ではなく、OOM(有効計算量)単位であるべきだということです。
私たちはこの10年でOOMsを駆け抜けようとしている。かつての全盛期でさえ、ムーアの法則は1~1.5OOM/10年に過ぎなかった。私の予想では、4年で~5OOM、10年で~10OOMを超えるだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/this_decade_or_bust-1200x925.png
要するに、私たちはこの10年で1回限りの利益を得るための大規模なスケールアップの真っ只中にいるのであり、OOMsを通過する進歩はその後何倍も遅くなるだろう。もしこのスケールアップが今後5~10年でAGIに到達できなければ、AGIはまだまだ先の話になるかもしれない。
つまり、今後10年間で、その後数十年間よりも多くのOOMを経験することになる。それで十分かもしれないし、すぐにAGIが実現するかもしれない。AGIを達成するのがどれほど難しいかによって、AGI達成までの時間の中央値について、あなたと私の意見が食い違うのは当然です。しかし、私たちが今どのようにOOMを駆け抜けているかを考えると、あなたのAGI達成のモーダル・イヤーは、この10年かそこらの後半になるはずです。
マシュー・バーネット(Matthew Barnett)氏は、計算機と生物学的境界だけを考慮した、これに関連する素晴らしい視覚化を行っている。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
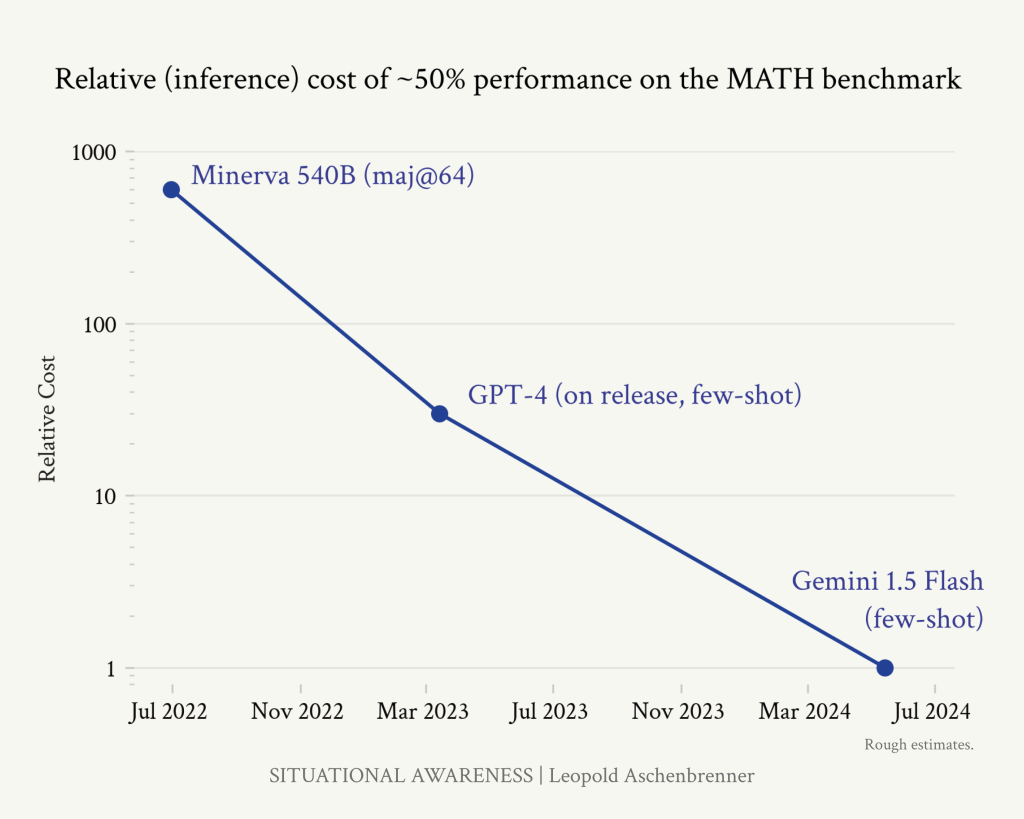
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
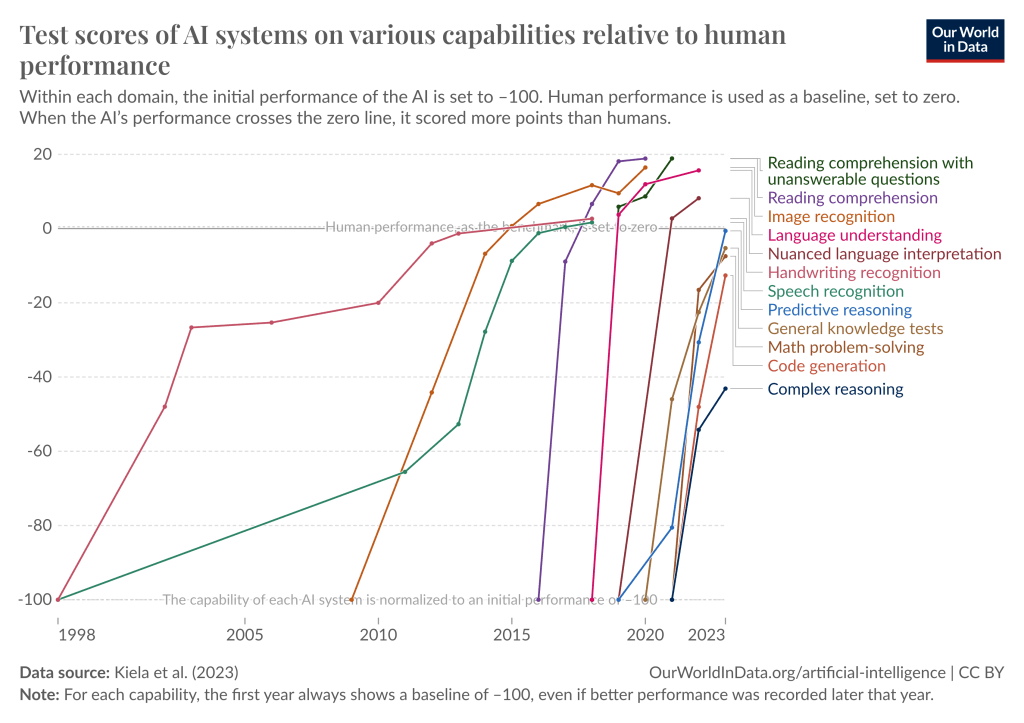
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
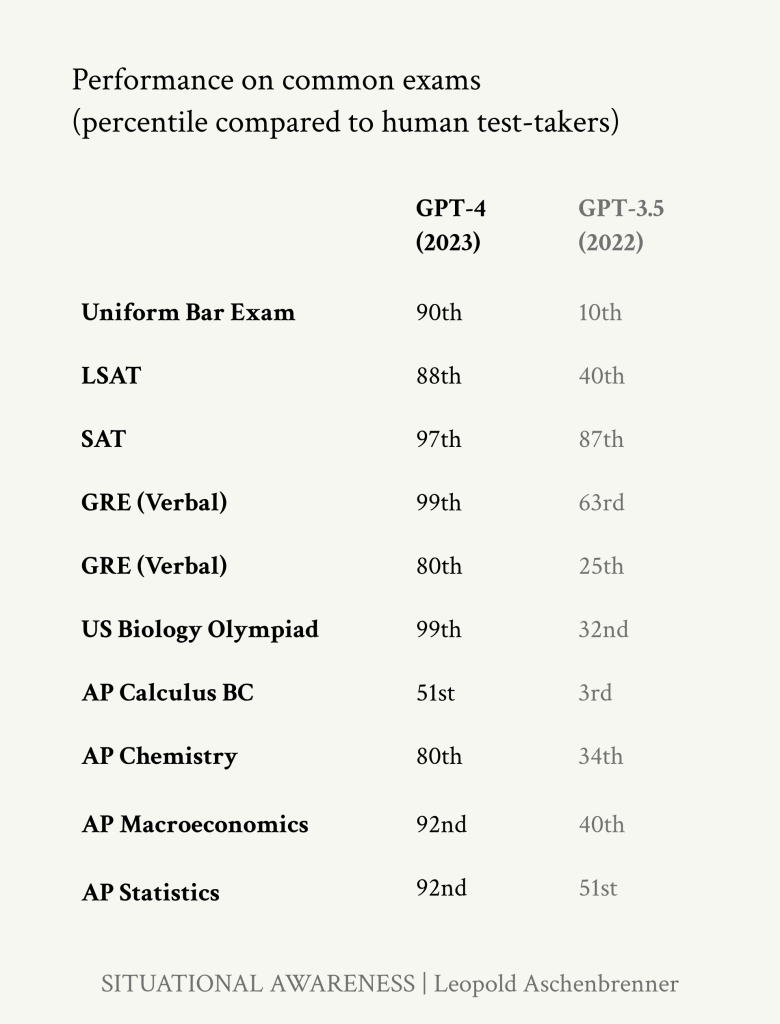
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
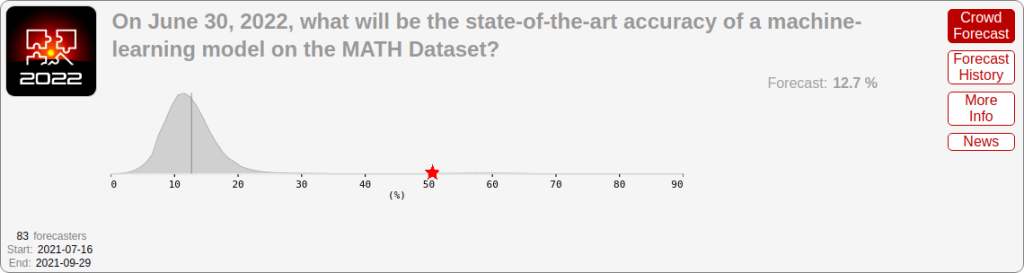
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
だから安楽死ビジネスを国内で確立させて、海外からの希望者も募ってガンガン稼げばいいんじゃない?
幸いにして高齢者っていう資源が大量に確保できるからビジネスモデルは研究し放題だし
安楽死まで行かなくても、もはや生きてても楽しくない人をどう死ぬまで楽しく過ごさせるかっていう終末ケアビジネスには勝機がありそうじゃない?
麻薬を使わないクリーンで希望に満ちた苦しみからの逃避ができるようになったら、国内外問わず高額でも希望者が殺到しそうな気がするんだけどなぁ
学歴どうこうって話聞くたびに思うんだけど
「どこ出てるかはどうでも良くて、書いた論文の本数と質が評価指標」
「大学まで来て論文書いてないヤツは大学に入って出ただけの有料体験版」
というのを東大卒の人が言ってたのを思い出す。
いや東大の人が言ってもなぁ~
エドワード・ウィッテンは、幾何学的なラングランズ・プログラムの一部とアイデアとの関係について「電気・磁気の二重性と幾何学的なラングランズ・プログラム」を執筆した。
ラングランズ プログラムに関する背景: 1967 年、ロバート ラングランズは、当時同研究所の教授だったアンドレ ヴェイユに17ページの手書きの手紙を書き、その中で大統一理論を提案した。それは、数論、代数幾何学、保型形式の理論における一見無関係な概念を関連付ける。読みやすくするためにヴェイユの要望で作成されたこの手紙のタイプされたコピーは、1960 年代後半から 1970 年代にかけて数学者の間で広く流通し、数学者たちは 40 年以上にわたり、ラングランズ プログラムとして総称されるその予想に取り組んできた。
弦理論やゲージ理論の双対性の背景を持つ物理学者は、カプースチンとの幾何学的ラングランズに関する論文を理解できるが、ほとんどの物理学者にとって、このトピックは詳細すぎて興味をそそるものではない。
一方で、数学者にとっては興味深いテーマだが、場の量子論や弦理論の背景には馴染みのない部分が多すぎるため、理解するのは困難(厳密に定式化するのは困難)。
短期的にどのような進歩があれば、数学者にとって幾何学的なラングランズのゲージ理論解釈が利用できるようになるのかを見極めるのは、実際には非常に難しい。
ゲージ理論とホバノフホモロジーが数学者によって認識され評価されるのを見られるだろうか。
弦理論の研究者として取り組んでいる物理理論が数論として興味深いものであることを示す多くのことがわかっている。
ここ数年、4 次元の超対称ゲージ理論とその親戚である 6 次元に取り組んでいる物理学者は、臨界レベルでの共形場理論の役割に関わるいくつかの発見を行っているため、この点を解決する時期が来たのかもしれない。
過去20年間、数学と物理学の相互作用は非常に豊かであり続けただけでなく、その多様性が発展したが、私は恥ずかしいことにほとんど理解できていない。
これは今後も続くだろう、それが続く理由は場の量子論と弦理論がどういうわけか豊かな数学的秘密を持っているからだ。
これらの秘密の一部が表面化すると、物理学者にとってはしばしば驚きとなることがよくある。
なぜなら、超弦理論を物理学として正しく理解していないから。つまり、その背後にある核となる考え方を理解していない。
数学者は場の量子論を完全に理解することができていないため、そこから得られる事柄は驚くべきものである。
したがって、生み出される物理学と数学のアイデアは長い間驚くべきものになるだろう。
1990 年代に、さまざまな弦理論が非摂動双対性によって統合されており、弦理論はある意味で本質的に量子力学的なものであることが明らかになり、より広い視野を得ることができた。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}