はてなキーワード: 領域とは
山奥SEOは、検索ボリュームが非常に少ないニッチなキーワードをターゲットにして検索エンジンの上位表示を狙うSEO手法です。この手法は競合が少なく、特に小規模なサイトや新規のブログにとって効果的です。
オリジナルコンテンツを提供することで、被リンクやサイテーションを獲得しやすく、専門性や信頼性が向上します。
ユーザーの具体的な悩みや質問に応えることで、強いリピーターを獲得しやすくなります。
当方は、以前から山奥SEOを実践しており、山奥SEOを実践してみた ニッチなキーワード策定から結果までではその取り組みをお伝えしています。
今回は、具体的に山奥SEOに使えそうなキーワードを具体的に挙げてみます。ぜひ、サイト作り・キーワード選定の参考にしてみてください。
『YMYL(Your Money or Your Life)』に該当しないニッチキーワードを中心に選定しています。健康、金融、法務などのトピックは個人サイトで戦える領域ではありません。避けるようにしましょう。
以下は、2024年6月時点において上位クエリにnoteや個人運営ブログ(独自ドメイン)などのサイトが食い込んでいるクエリになります。ぜひ山奥SEOを実践する際にこうしたキーワードを狙ってページを作ってみてください。
コンテンツ: 古地図をコレクションする際の収納方法や保管のコツ。
想起される関連ワード:「古地図 保存方法 自宅」「古地図 展示アイデア」「古地図 防湿対策」「古地図 クリーニング方法」「古地図 フレーム 選び方」「古地図 修復 自宅でできる方法」「古地図 デジタル化 方法」「古地図 アーカイブ作成」「古地図 専用収納ケース」「古地図 収納 アイデア DIY」
コンテンツ: DIYで作るドアストッパーの作り方や材料の選び方。
想起される関連ワード:「DIY ドアストッパー 材料」「DIY ドアストッパー 木製 作り方」「DIY ドアストッパー おしゃれ」「DIY ドアストッパー 玄関用」「DIY ドアストッパー 重さ調整」「DIY ドアストッパー フェルト使用」「DIY ドアストッパー 滑り止め対策」「DIY ドアストッパー 再利用素材」「DIY ドアストッパー ゴム製」DIY ドアストッパー クリエイティブデザイン」
想起される関連ワード:「ミニ四駆 軽量化 パーツ選び」「ミニ四駆 モーター交換 方法」ミニ四駆 タイヤ チューニング」「ミニ四駆 シャーシ 強化方法」「ミニ四駆 空力パーツ 取り付け」「ミニ四駆 ベアリング カスタマイズ」「ミニ四駆 ウイング 自作方法」「ミニ四駆 ギア比 調整」「ミニ四駆 バッテリー 効率化」「ミニ四駆 車体塗装 テクニック」
コンテンツ: 手作り石鹸に色を付ける方法や安全な着色料の紹介。
想起される関連ワード:「手作り石鹸 ナチュラルカラー 素材」「手作り石鹸 食用色素 使用方法」「手作り石鹸 マイカパウダー 色付け」「手作り石鹸 クレイ カラーリング」「手作り石鹸 酸化鉄 色付け」「手作り石鹸 スワール技法 色付け」「手作り石鹸 グラデーションカラー 方法」「手作り石鹸 ジェルカラー 使用方法」「手作り石鹸 フルーツピューレ 色付け」「手作り石鹸 ハーブ粉末 カラーリング」
想起される関連ワード:「ミニチュア家具 木製 DIY」「ミニチュア家具 椅子 作り方」「ミニチュア家具 ソファ DIY」「ミニチュア家具 ペイント テクニック」「ミニチュア家具 アンティーク風 作り方」「ミニチュア家具 引き出し付き 作り方」「ミニチュア家具 ベッド DIY」「ミニチュア家具 リサイクル素材 使用方法」「ミニチュア家具 デザイン図面 書き方」
コンテンツ: 初心者向けの手作り香水の作り方や材料の選び方。
想起される関連ワード:「手作り香水 天然素材 使用方法」「手作り香水 エッセンシャルオイル 選び方」「手作り香水 アルコール フリー レシピ」手作り香水 持続時間 長くする方法」「手作り香水 ボトル 選び方」「手作り香水 フレグランスノート 組み合わせ」「手作り香水 固形タイプ 作り方」「手作り香水 初心者キット おすすめ」手作り香水 季節ごとのレシピ」「手作り香水 プレゼント用 デザイン」
コンテンツ: 初心者向けのミニチュアガーデンの作り方や材料の選び方。
想起される関連ワード:「ミニチュアガーデン 素材 選び方」「ミニチュアガーデン フェアリーハウス 作り方」「ミニチュアガーデン 初心者キット おすすめ」「ミニチュアガーデン 低予算 作り方」「ミニチュアガーデン ミニ植物 選び方」「ミニチュアガーデン リサイクル素材 使用方法」「ミニチュアガーデン 屋内栽培 方法」「ミニチュアガーデン 簡単デザイン アイデア」「ミニチュアガーデン 手作りアクセサリー 作り方」「ミニチュアガーデン メンテナンス 方法」
コンテンツ: ミニチュア家具のペイント方法や使用するペイントの種類。
想起される関連ワード:「ミニチュア家具 エアブラシ ペイント方法」「ミニチュア家具 アクリル絵の具 使用方法」「ミニチュア家具 アンティーク風 ペイント」「ミニチュア家具 グラデーションペイント 技法」「ミニチュア家具 ディストレス加工 ペイント」「ミニチュア家具 ゴールドリーフ ペイント」「ミニチュア家具 ステンシル ペイント」「ミニチュア家具 メタリックペイント 使用方法」「ミニチュア家具 ペイントシーラー 選び方」「ミニチュア家具 カラーブロック ペイントテクニック」
コンテンツ: アンティークレースを使ったDIYアイデアやデコレーション方法。
想起される関連ワード:「ミニチュア家具 木工 DIY」「ミニチュア家具 ソファ 作り方」「ミニチュア家具 引き出し付き 作り方」「ミニチュア家具 ペーパークラフト DIY」「ミニチュア家具 塗装 テクニック」「ミニチュア家具 簡単 作り方 初心者向け」「ミニチュア家具 パレット 使用方法」「ミニチュア家具 クラシックデザイン 作り方」「ミニチュア家具 リサイクル素材 DIY」「ミニチュア家具 収納家具 作り方」
想起される関連ワード:「レトロ看板 修復方法」「レトロ看板 保存方法」「レトロ看板 購入場所」「レトロ看板 掃除方法」「レトロ看板 コレクション展示アイデア」「レトロ看板 コレクター向けガイド」「レトロ看板 認証方法」「レトロ看板 フレーム作成方法」「レトロ看板 オークション 参加方法」「レトロ看板 コレクション管理アプリ」
コンテンツ: 幾何学模様の折り紙の作り方やステップバイステップのガイド。
想起される関連ワード:「折り紙 幾何学模様 立体作り方」「折り紙 幾何学模様 初心者向け」「折り紙 幾何学模様 キット おすすめ」「折り紙 幾何学模様 シンプルデザイン」「折り紙 幾何学模様 ペーパークラフト」「折り紙 幾何学模様 カラフルデザイン」「折り紙 幾何学模様 インテリアアート」「折り紙 幾何学模様 組み合わせ方法」「折り紙 幾何学模様 ランプシェード 作り方」「折り紙 幾何学模様 モダンデザイン」
以上となります。
「公共空間でもデカい声でベラベラ喋る」とか「レストランなりに行けば、説明が書いてあるだろうがって感じの事でもすぐ店員に聞きたがる」程度のことも許容できないくらい狭量だから、「自己の領域を他人にまで拡大するようなマネは徹底して嫌悪してる。」などと言い出すんだよ。
理系にとって常識とは「多数が実際に知っていること」であって、「みんなが知るべきこと」ではない。
理系からすれば高校数学(3C含む)あるいは大学の教養数学(微積、線型、フーリエ級数)までぐらいはすべての人間が知っていないとならないことだ。社会統計やエネルギー問題についての議論を高校数学もできない奴に理解することはできない。
しかし、理系は高校数学を「常識」とは呼ばない。それができないのが大半の人類だということは重々承知しているからだ。多数ができないことを「常識」と呼ぶ不毛さを理解するのが理系である。
一方で、Mrs. GREEN APPLEの『コロンブス』が炎上した件からわかるのは、文系は学歴の高低を問わず、「常識」を「自分が知っていて、みんなも知っているべきこと」という意味で何の躊躇もなく使えるということである。
「コロンブス」という西洋史の中の一人物に過ぎない存在の細かい仕事内容なんて、当たり前だがほとんどの日本人は学校の授業で習わない。習わないということは、個人的に興味を持ってそういう資料に接しなければ知り得ないということである。それをするかどうかは個人の自由意志の問題であって、そんなことをコントロールすることはできないし、してはならない。
しかしながら、文系学徒はそういう、自分自身の興味領域であって他人にも「知って欲しい」という願望がある知識、体系を、「常識」として押しつけることが何の問題もない行為であるという意識を持っていることを、今回の件は露呈してしまった。
文系にとって「常識」とは、この様子から有り体に解釈するなら、「誰もが『知っているべき』こと」という希望的観測から導かれる思想的な概念なのである。
その「知っているべき」と考える理由自体は、これは単に個人的な興味の問題なのでさまざまなようである。あるいは単なる歴史オタクだから、あるいは漫画やアニメに関連する知識だから、あるいは「海外ニュースくらい見ろよ」という出羽守。ともあれ、どのような理由であろうとも、自分の「興味」が誰にとっても重要であるべき「教養」に勝手にすり替わってしまうのが文系の基本的な思考回路であるということがこのことから見て取れる。
この、理系(あるいは、非オタク的な、自分に関係のないことに興味を示さない普通の人)にとっては狂気の沙汰とも思えるような思想的言葉遣いが、この手の炎上屋の発想の根源にあることは、重々注意しておかないといけない。そもそもの言葉遣いが、ものごとの科学的定義からではなく、「こうあって欲しい」という願望から来ているような連中に、論理的な話が通じるわけがないのである。
この文章は、普通に読めばわかるように「常識」という言葉を軽々しく使う思想性を糾弾しています。
コロンブスについて「学ぶべきかどうか」は全く否定していません。
というか、「無知な庶民にマウント取りたいのか教化して社会を変えたいのかはっきりしろよ」くらいの肯定的な説教なんだけどね。
「庶民は無知だけしからん」と言ってれば社会が変わるのか? 「インテリ」がそんなことばっかしてた結果が今の日本だろうが。
それこそ、「海外の常識」なら、この文章に「歴史的意義を学ぶことを否定した」なんて思想性の高い誤読はしないだろうね。ローコンテクスト読解が普通だし、庶民が無知なのは当然として社会の仕組みで頑張るという意識が当たり前だから。
自分たちで日本政治の「自助優先」を批判しながら、勉学については「自助しない奴はクズ」でマウント取ってすませてる、そういうところが偽物なんだよお前らは。
こういうところが、日本の「文系」のだめなところなんだよなあ。
あとですねえ、「理系(あるいは、非オタク的な、自分に関係のないことに興味を示さない普通の人)」を「理系が普通の人とイコール」と読める奴は、普通に日本語力も低いと思います。そんな読解力でよく「文系」もやってられるねえ。
総合すると、「文系」って言葉を厳密に使うこともできないし、文章もまともに読めないんじゃんという話だよね。何ができるんだあいつら。一問一答の試験の回答を覚えるだけ? やれやれ。
連日連夜、他人を攻撃したいだけの男が(女も?)弱者男性を自称して気に入らないものを叩いて回ってさ
「一緒にいて恥ずかしいからやめてくれ」って難しい感情だなって思う。
基本的におれはそういうパターナリズムというか、最小単位のコミュニタリアニズム的発想というか、とにかく自己の領域を他人にまで拡大するようなマネは徹底して嫌悪してる。
おれがおれの領域内で何をしようが勝手だし、それが気に入らないならどうぞ離れていってくれと思う。逆も然りだ。
そもそもそういうタイプの人間とは付き合わないようにしてるけど、とはいえ自分でもたまに素朴な感覚としてそういう感情を抱くことだってある。
実家に行けば、母は公共空間でもデカい声でベラベラ喋る。勘弁して欲しい。
恥ずかしいからやめろ、ではなくその場を共有する一個人としてうるせえと言えばいい。
レストランなりに行けば、説明が書いてあるだろうがって感じの事でもすぐ店員に聞きたがる。もっと言えば常識的に分かるだろって感じだけど、そこはまあおれの常識を強いるのも気が引ける。
店員のバイトが要領を得ずまごつく事もあって、その得も言われぬ空気の中でなんだか自分まで気恥ずかしさを覚えてくる。
そんなんわざわざ聞かねえでも分かるだろっておれが説明しつつ制する事もできるけど、後でグチグチ言われるのは明白だしおれがそれを引き受ける道理もない。ので静観。
まあ説明を要求するのは別に妥当な権利だとは思うし、それを受け入れるか突っぱねるかは店側の都合であって、外野のおれがとやかく言うことではない。
そんな事を思いつつ、おれにも「迷惑教」だったり自分の見栄に他人を巻き込もうとする感覚がしっかりインストールされてんだなあ、って嫌な気分になる。
AIさん、また自信満々に嘘ついてない?
ジェンダー:15回
ジェンダーバイアス:1回
男女共同参画:8回
25回(ジェンダー平等2回、ジェンダー視点3回、ジェンダー問題0回、ジェンダーバイアス1回)
人文社会科学系のGender Equality Matters ─日本学術会議総合ジェンダー分科会第24期の成果から─
「学術支援・研究職」の現状と課題 ─ジェンダー視点からの検討─
「卵子の老化」が問題になる社会を考える ─少子化社会対策と医療・ジェンダー─
若手研究者養成とジェンダー ─人文・社会科学領域における女性・若手研究者養成の支援―
減災の科学を豊かに -多様性・ジェンダーの視点の主流化に向けて-
教養教育は何の役に立つのか? -ジェンダー視点からの問いかけ-
日本のジェンダー平等の達成と課題を総点検する -CEDAW(国連女性差別撤廃委員会)勧告2009を中心に-
8回(特集7件)
日本の戦略としての学術・科学技術における男女共同参画 ―「第4次男女共同参画基本計画」との関わりで―
男女共同参画の一層の推進に向けて
どこまで進んだ男女共同参画
2回(ジェンダーと1件重複)
人文社会科学系のGender Equality Matters ─日本学術会議総合ジェンダー分科会第24期の成果から─
ぷよ碁何路でやってる?
デフォルトの5路はほぼ最善手ゲーだし、狭すぎて逆に初心者には難しいから7路以上のほうがわかりやすいし勝ちやすいよ
・ぷよ碁みたいに石同士の見た目がくっつく
・領域に色がつく
・危ない石の度合いに応じて△とか✕マークがつく
あと騙されたと思ってシチョウとかゲタとか基本的な手筋を一通り覚えてみて
一気に勝てるようになるよ
「"囲"碁」と書くゲームで「囲う」を禁止しろとか、ただのあたおか。しょうもない言葉狩りは本質的でない。
「石の生存できる領域」と言い換えたところでこれもたいして明確だとは思えない。結局、丁寧な説明抜きに一言ですべて教えるのは土台無理な話。
ちゃんと教えるなら「陣地を囲う」でも十分伝わる。
旅行に行きたい気分あるし
有給が20日あるから少し使わなきゃいけないんだが(病院はフレックスで対応できる
候補が思いつかない
でもどこかにいきたい。
昼は観光して、安いドミトリーに泊まって、その辺のラーメン食べて
買える前に地元の温泉か銭湯にでもよって、最終日だけ少し豪勢なものたべて
・関東:ここ住まい。茨城県ぐらいしか残ってないがここ行く料金で大阪行けるんだよね…
・関西:前回奈良、大阪に行ったけど、まだまだ目的地は設定はできそう。兵庫は神戸しかいってない
・中国:こっから行く難易度が少しあがる。強いて言うならしまなみ海道
・九州:福岡だけいった。飛行機必須の領域になるが行ってみたいところは多いが、車必須なので少し考える
・海外:前回は台湾(3回目)。さすがに避けたいので候補として安いので有力。
タイ、カンボジア、マレーシア、中国(3回)、トルコ、ドバイは行った。
全部楽しかったが露のプー太郎さまのおかげでサーチャージが跳ね上がっておいそれといけない。
あとサクラダファミリアを完成前に見に行くか、完成後に見に行くかで悩み中
というか金のこと考えないなら世界を見てみたいな。
話はそれたが現実路線(興味と金銭の折衷)でいうとベトナム、ミャンマーあたりだろうか
Q.
世間一般に対して「容姿で人を差別するのを止めよう」と主張しながら、個人がパートナーを選ぶのに「容姿の好みを反映させるのは個人の自由である」と主張するのは矛盾でしょうか?
A.
容姿について、社会的差別の問題と個人の好みの問題を区別して考えることが大切だと思います。
社会的差別の観点からは、容姿を理由に不当な扱いをすることは望ましくありません。就職や昇進、サービス提供などにおいて、容姿で差別することは公平性に反します。容姿は個人の能力とは無関係であり、機会の平等を阻害するからです。このような社会的差別をなくしていくべきでしょう。
一方、恋愛やパートナー選びは個人的な領域に属します。相手への魅力は容姿だけでなく、性格や価値観なども含む主観的・複合的なものです。外見的な好みは個人の自由に属する問題で、他者から干渉されるべきではありません。
従って、容姿による社会的差別に反対しつつ、交際相手の選択では容姿の好みを優先することは、論理的に矛盾しているわけではないと考えます。重要なのは、それぞれの場面で求められる公平性や自由の程度を見極め、バランスを取ることではないでしょうか。
社会全体としての平等の追求と、プライベートな選択の自由は、ときに緊張関係に立ちます。しかし、一方を重視するからといって他方を全面的に否定する必要はないでしょう。状況に応じたバランス感覚を保ちながら、差別のない社会の実現と個人の多様な価値観の尊重の両立を目指すことが肝要だと考えます。
そりゃ小学生でもプログラミング自体は出来るんだから文字さえ読めれば作れるレベルのプログラムもあるが全部がそうではないんで。
アルゴリズムやハードウェアや数学や設計やらの深い知識が求められる領域も多くあるから。そういうのは学問で体系的に学んでないと厳しい場合がある。
と思いがちなんだけど、実際には
「色んなモノに参加する敷居が下がるだけ」
なので、アレな人でも本や動画作れるようになったり、本来生き残れない人が生き残れるようになるので、表面的にはレベルが下がるのよ…
陰謀論を唱えるというのは極端にしても、
「メンタルの問題は、古典に答えが書いてあることもたくさんあるのに、古典で軸を作れていない人が、断片的に自己啓発本や心理学の研究を読む」
「せいぜい200年しか歴史のない心理学で、メンタルの問題をわかった気分になる」
みたいなことが多くて…うん
私が本書くときにあたって心理学も色々調べたけど…それこそ人気の本から、DaiGoさんまで
みたいな断片的な情報が多すぎて、体系立てられているものや、汎用性をもって使えそうなものはむしろ哲学や仏教の方に多くてけっこう困った。
「ロジカルなら正しい」
もけっこう危険だけど、『実験・データによると』はもっと危険やからなぁ…。
切り口次第でどうとでもなるし、再現や検証に手間がかかるからその場限りで人を言い負かすのには、ロジカル以上に使えることがある。
疑いだせばキリがない話だけどね…
ロジカルに考えても
みたいなのがしっくり来る説明がないというか、どうとでも言えちゃうものは私は取り入れないようにしてるけどね
その辺、仏教・禅は「悟りってなんやねん」と聞いた人にちゃんと答えてる人がおるから、なんでもありではない
は十住心論、正法眼蔵、般若心経あたりを読むと書いてあるんで、そこは整合性取れてる。
これを「仏教の修行しないとできません」と言っちゃうのは仏教側にも驕りがあるとは思うけどやりたいことは伝わる
・自分たちの考えのことを「真理」と言って、宗教ではないと主張する人も散見される
・真理から見て正しい間違ってるという「八正道」は一歩間違えると洗脳の道具になる
仏教が哲学として面白い一方で、ヤバい人もたくさん作っちゃってる部分はこの「驕り」なのです。
驕りの部分を取り入れないで、哲学の面白さを取り入れると役に立つのだが…驕りが入ってこないように適切な距離感を取る必要がある。
ここが仏教を取り入れる注意点かなぁ…
https://www.bbtower.co.jp/case/kadokawa_connected2/
日本を代表する総合エンターテインメント企業のKADOKAWAの経営を、IT領域で支えるKADOKAWA Connected。膨大なコンテンツやサービスの運用、管理をしている同社では、すべてのITシステムを1データセンターに集約した。効率化が高まった半面、異なるサービスレベルのシステムをまとめて運用するため、メンテナンスの際の運用負荷が高まっていた。そこでサービスレベルごとにデータセンターを分ける設計とし、業務システムの移転先として選ばれたのが、BBTowerのデータセンターである第1サイトだった。
なんで元々は1データセンターだったけど、少なくとも業務システムは昨年BBTower第一サイトに移設した。
が正解。
ランサムウエアがデータを暗号化し始めたことで異常察知し一部システムが強制遮断されたために全体が落ちて
単純に再起動すると再びランサムウエアが暗号化を開始してしまう可能性があることから、コールド状態でのデータバックアップが取れるまで再稼働テストも開始できない、みたいな。
そんで、角川とニコ動とN学が全部死んだのは、昔ながらの領域型防御になっていて、三つのシステムに侵入が可能なアカウントがやられて同時侵入を許したか。
ヒントになるのは発表直後にすぐ「クレカは漏れてない」って発表したところだよな。何かのリモートアクセスを許したりしたのならこんなに自信たっぷりには発表できないはず。というのは、サーバに保存しない仕組みになっていたはずなのに、システムを改変させられてクレジットカード情報を吸い取られていたと言う被害が多いからだ。
しかしその可能性をすぐに排除出来るとすると、内部に侵入された系の被害じゃない。
一方でDoS系の攻撃だとすると、国内でも有数の規模を誇るトラヒックを裁くニコ動がやられる規模だと、他のネットワークにも影響が出ると思われそれはなかった。
みんなどう思う?
といった式について、素粒子では後者が支配し、天体では前者が支配する。
近距離における強い力のために、電子は原子核に螺旋状に落ち込むが、明らかに事実と違う。
というハイゼンベルグの関係式に従う。このため、r=0となることはなくなり、問題は回避される。
多様体上の楕円型作用素の理論全体が、この物理理論に対する数学的対応物で、群の表現論も近い関係にある。
しかし特殊相対性理論を考慮に入れるとさらに難しくなる。ハイゼンベルグの公式と同様の不確定性関係が場に対して適用される必要がある。
電磁場の場合には、光子というように、新しい種類の粒子として観測される。
電子のような粒子もどうように場の量子であると再解釈されなければならない。電磁波も、量子を生成消滅できる。
数学的には、場の量子論は無限次元空間上の積分やその上の楕円型作用素と関係する。
量子力学は1/r^2に対する問題の解消のために考え出されたが、特殊相対性理論を組み込むと、この問題を自動解決するわけではないことがわかった。
といった発展をしてきたが、場の量子論と幾何学の間の関係性が認められるようになった。
では重力を考慮するとどうなるのか。一見すれば1/r^2の別な例を重力が提供しているように見える。
しかし、例えばマクスウェルの方程式は線型方程式だが、重力場に対するアインシュタインの方程式は非線形である。
また不確定性関係は重力における1/r^2を扱うには十分ではない。
物理学者は、点粒子を「弦」に置き換えることにより、量子重力の問題が克服できるのではないかと試した。
量子論の効果はプランク定数に比例するが、弦理論の効果は、弦の大きさを定めるα'という定数に比例する。
もし弦理論が正しいなら、α'という定数は、プランク定数と同じぐらい基本的定数ということになる。
ħやα'に関する変形は幾何学における新しいアイデアに関係する。ħに関する変形はよく知られているが、α'に関する変形はまだ未発展である。
これらの理論は、それぞれが重力を予言し、非可換ゲージ対称性を持ち、超対称性を持つとされる。
α'に関する変形に関連する新しい幾何学があるが、理解のために2次元の共形場理論を使うことができる。
ひとつは、ミラー対称性である。α'がゼロでない場合に同値となるような2つの時空の間の関係を表す。
まずt→∞という極限では、幾何学における古典的アイデアが良い近似となり、Xという時空が観測される。
t→-∞という極限でも同様に時空Yが観測される。
そして大きな正の値であるtと大きな負の値であるtのどこかで、古典幾何学が良い近似とはならない領域を通って補間が行われている。
α'とħが両方0でないときに起こり得ることがなんなのかについては、5つの弦理論が一つの理論の異なる極限である、と説明ができるかもしれないというのがM理論である。
今日も、私の目に飛び込んできたのは、ありきたりなおすすめ商品たち。
まるで、流行を追いかけるだけのロボットのような気分にさせられる。
過去の評価や購入履歴から、似たような趣味を持つユーザーの行動を分析し、私に最適な商品を提案してくれる。
しかし、その一方で、恐ろしいほど偏った情報を生み出す側面も見逃せない。
協調フィルタリングは、人気のあるものほど多くの人に推薦され、さらに人気が高まるという「バズる」現象を生み出す。
埋もれていた良質なコンテンツや、マイナーなジャンルは、日の目を見る機会すら与えられずに消えていく。
このアルゴリズムは、まるで温室育ちの花のようだ。
私たちは、いつの間にか、自分の好みや思考を委ねてしまい、自ら情報を探索する意欲を失っていく。
協調フィルタリングは、過去に基づいた情報を提供するだけで、未来を創造することはできない。
まるで、過去の栄光にしがみつく時代錯誤の王のように、私たちは過去の成功体験に囚われ、現状維持に甘んじてしまう。
協調フィルタリングは、ユーザーの行動データを収集し、分析することで成り立っている。
自分の好みや思考を丸裸にされ、企業や政府の思惑に操られてしまうのだ。
私たちは、協調フィルタリングというアルゴリズムに支配される必要はない。
もっと多様な情報に触れ、自分の頭で考え、主体的に行動することが大切だ。
ま、仕方ないから教えてあげるわ♡
1. 距離を置く♡
2. 目を合わせない♡
関わりたくないなら、視線避けた方がいいよ♡
4. 場所を選ぶ♡
そういう人がいない環境を選ぶのが賢いよね♡
5. 断る勇気♡
ほら、これで少しはマシになるんじゃないの?♡
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
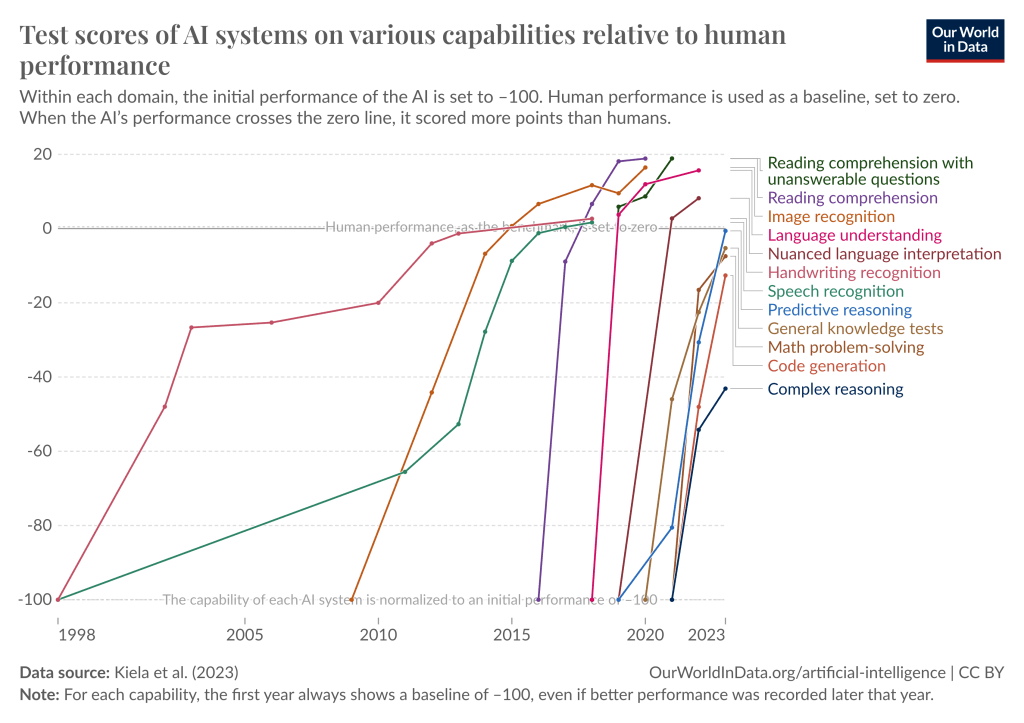
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
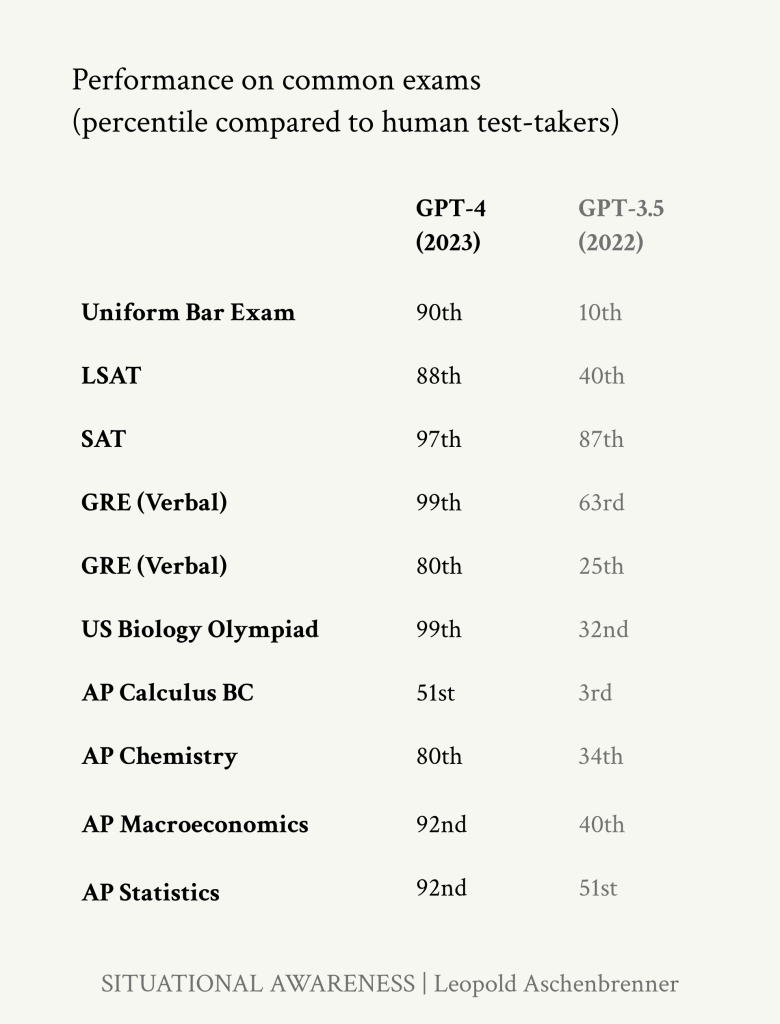
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
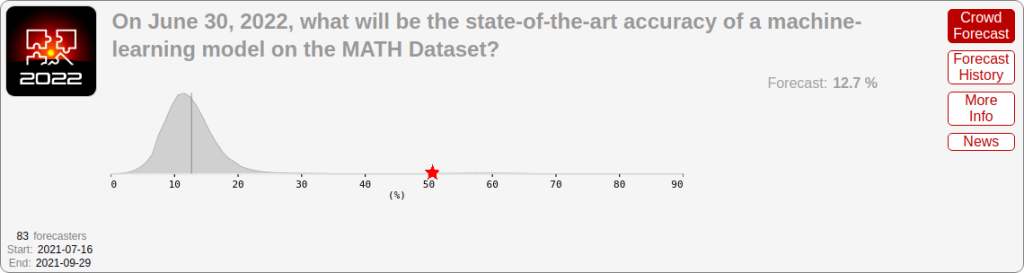
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
{kind=link}
{kind=link}
{kind=link}
{kind=link}