はてなキーワード: 2027年とは
スマートウォッチに「もみもみ音頭」が内蔵され、肩の動きを自動検知。仕事中の「もみもみタイム」通知が来ると自動再生され、サラリーマンたちが肩を揉みながら「未来の健康管理は肩揉みだ!」と大満足。
AIが肩揉みを学習し、デジタル肩揉みの技術が進化。「もみもみAIセラピー」が登場し、デジタル環境で本格的な肩揉みを体験できると話題に。もみもみ音頭に合わせて肩を揉むAIアバターが「癒しすぎる」と人気爆発。
「肩揉み体験」を提供するドローンが開発され、もみもみ音頭に合わせて空中から肩を揉む「もみもみドローン祭り」が全国で開催される。空に浮かぶドローンに肩を揉まれながら「これぞ未来のもみもみ」とおじさんも若者も大興奮。
宇宙旅行が日常化した2040年、観光の一環で宇宙ステーション内で「もみもみ音頭」が流れるイベントが開催。無重力で肩揉みをしようと試みるも、肩が浮いてしまい「もみもみの限界を感じる」と宇宙飛行士が苦笑。
AIが「もみもみ音頭」のリミックスをひたすら生成し、100万曲が一気に配信される。人々が「もみもみ音頭100年祭」で聴きまくる中、「この世にこれだけのもみもみがあったとは」と感動と謎の達成感に包まれる。
肩こりの社会問題化を受けて、もみもみ音頭が小学校の授業に導入される。授業で肩揉みの基本を学ぶ「もみもみ基礎」が始まり、「未来の肩もみマスター」を目指す子供たちが登場。PTAからは「肩揉みのある教育は素晴らしい」と絶賛。
研究により、「もみもみワクチン」が開発され、肩揉みを通じてワクチン効果を得られる技術が確立。「もみもみ音頭」に合わせてワクチン接種イベントが開催され、全国で肩揉みの大合唱が響く。医療と肩揉みが奇跡の融合を果たす。
「もみもみ音頭」が国連により人類の公式テーマソングに認定され、地球全体で肩揉みイベントが行われる。世界中の人々が「もみもみ」のリズムで肩を揉み合い、「人類もみもみ化計画」が発動。
「もみもみ音頭」が電波として宇宙に放出され、遥か遠くの銀河系から「もみもみ星」が発見される。研究者たちは「もみもみ星人とのコンタクトを目指し、肩揉み文化を共有したい」と意気込む。肩揉みが人類の新たな共通言語に。
2027年にトランプ税制を延長しなければ低所得者から中間層は苦しくなるらしい。なお、高所得者と法人は継続的に恩恵を受けるらしい。
個人の所得層別の影響分布は関係する仮定および測定された時点に基づいて大きく変化する。一般的に企業と高所得者層は主に恩恵を受けるが、低所得者層は初期の恩恵は時間と共に薄れていくか悪影響を受けることになると見込まれている。例えば、CBOとJCTは以下の様に推定している:
2019年には所得が2万ドル以下のグループ(納税者の約23%)は主にACAの個人加入義務が廃止されることで受け取る補助金が減少することで赤字削減に寄与する(すなわち費用が発生する)。他のグループは主に減税により赤字増加に寄与する(すなわち恩恵を受ける)
2021年、2023年及び2025年には所得が4万ドル以下のグループ(納税者の約43%)は赤字削減に寄与する一方で、所得が4万ドルを超えるグループは赤字増加に寄与する。
2027年には所得が7万5000ドル以下のグループ(納税者の約76%)は赤字削減に寄与する一方で、所得が7万5000ドルを超えるグループは赤字増加に寄与する[6][8]
では数字で話そう
そのうち69兆4,400億円が租税及び印紙収入、残りが公債費
租税及び印紙収入は所得税、法人税、消費税で税収の約8割を占める
所得税21兆
法人税14,6兆
相続税2.8兆
酒税1.2兆
印紙税0.9兆
揮発油税2兆
自動車重量税0.4兆
たばこ税0.9兆
税収が伸びているのは法人税と消費税で所得税は所得減税で減っている
| 税 | 2022 | 2023 | 2024 |
|---|---|---|---|
| 消費税 | 14.9 | 15.9 | 17 |
| 所得税 | 22.5 | 22.1 | 17.9 |
| 法人税 | 23.1 | 23.1 | 23.8 |
消費税10%のうち2.2は地方消費税で地方税だ全額社会保障費に使われている
また残り7.8%のうち6.28%は社会保障費、1.52%は地方交付税に使われていることを理解してほしい
その「税収増分」とはどれのことだ?
5.2兆円をどうねん出するのか
蛍光灯の生産を2027年9月末までに終了 一体型LEDべースライト「iDシリーズ」をモデルチェンジ CO2実質ゼロを実現した新潟工場で生産能力を拡大 | 事業戦略・方針発表 | 企業・経営 | プレスリリース | Panasonic Newsroom Japan : パナソニック ニュースルーム ジャパン
https://news.panasonic.com/jp/press/jn241001-2
| 品種 | 生産終了時期 |
|---|---|
| 直管蛍光ランプ(三波長形)丸形蛍光ランプ、点灯管 | 2027年9月末 |
| ツイン蛍光ランプ(コンパクト形蛍光ランプ) | 2026年9月末 |
※2 特殊用途蛍光ランプ、電球も2027年9月末までに生産を終了します。なお、直管蛍光ランプ(一般色形)については、2025年6月末の生産終了をすでに決定、発信しています。また、上記生産終了期日より早く終了する品番もございます。
オワタ。
ロシアは分からんけど、中国は台湾有事起きたら首都圏にもサイバー攻撃しそう。まぁ、台湾有事自体本当に2027年までに起こるか分からんし、サイバー攻撃だって別にそこまで被害はなさそうだけど。
本当に大きな規模の戦争に発展したら、国外に逃げたってややこしいことになりそう。だって中国と関わりのない先進国なんてないし、緊急時に他国の日本人を自国の人間より優遇するなんてことがあり得るのか?何かあったら強制帰国か最悪切り捨てになりそう。
まぁ、現実感のない妄想だけど、実際何するか分からん中国政府だから、なんか不動産買うのもどうかなってなる。3Dプリンター住宅が普及したら、軍事施設の少ない県の土地を買って、安く戸建建てた方が結果ぶっ壊れても後悔しなさそう。杞憂かな、杞憂だといいな。
裏金議員を公認した場合、石破内閣は近いうちに退陣するほかない。この場合は高市内閣か野田内閣のどちらかになるが、高市内閣では日米韓安保協力が大幅に後退する。野田内閣は未知数だが、共産や党内左派の存在を考えれば安心はできない。
中共の台湾侵略は2027年とも言われる。そのときに日米韓安保協力が後退していたら、この先100年禍根を残すかもしれない。日本国がそのときを万全の体制で迎えるためには、石破茂、あなたが総理をするしかない。
裏金議員を公認しない場合、石破さんが大勝する目がある。小泉純一郎氏の郵政国会の再来だ。
裏金議員88人、そのうち衆院は44人だったか。全員非公認は無理かもしれない。しかし小泉純一郎氏は37人の刺客を立てたことを考えれば石破さんだって近い人数は出せるはずだ。自民党の国会議員になりたい人なんて山程いる。
万一間に合わないなら、選挙を伸ばしたっていい。公明党や森山幹事長の顔色を伺って早期にしたのが間違いだった。
石破さん。あなたはきっと、総裁選に勝つために、岸田派や森山氏と約束をしたことだろう。
義を重んじるあなたは、それを裏切るのは心苦しいと思っているだろう。
しかし、もはやあなたにある選択肢は、党内を裏切るか、国民を裏切るかの2択しかない。
石破さん。あなたの勇気はどこにある。真心はどこにある。語るべき真実はどこにある。
今日も昼間は暑かったですね。もう9月も半ばなのに最高気温35度の猛暑日ですって。
私は夕方までごろごろしていました。だって今日は9月15日、祝日じゃないですか。「敬老の日」じゃなかったっけ?←
とまぁ、毎日が日曜日の私ですが。夕食にうなぎを頂きました。働かざるもの云々とはいうけどな←。
と、そんな平和な日常もとりあえず19時前で終わり。夕食後自室に戻ったあとの18時52分、スマホが突然ビービーなる。何事だ?
結局19時ちょうどに東京都港区付近にミサイルが着弾したようで。幸いにもこちらは無事でしたが。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
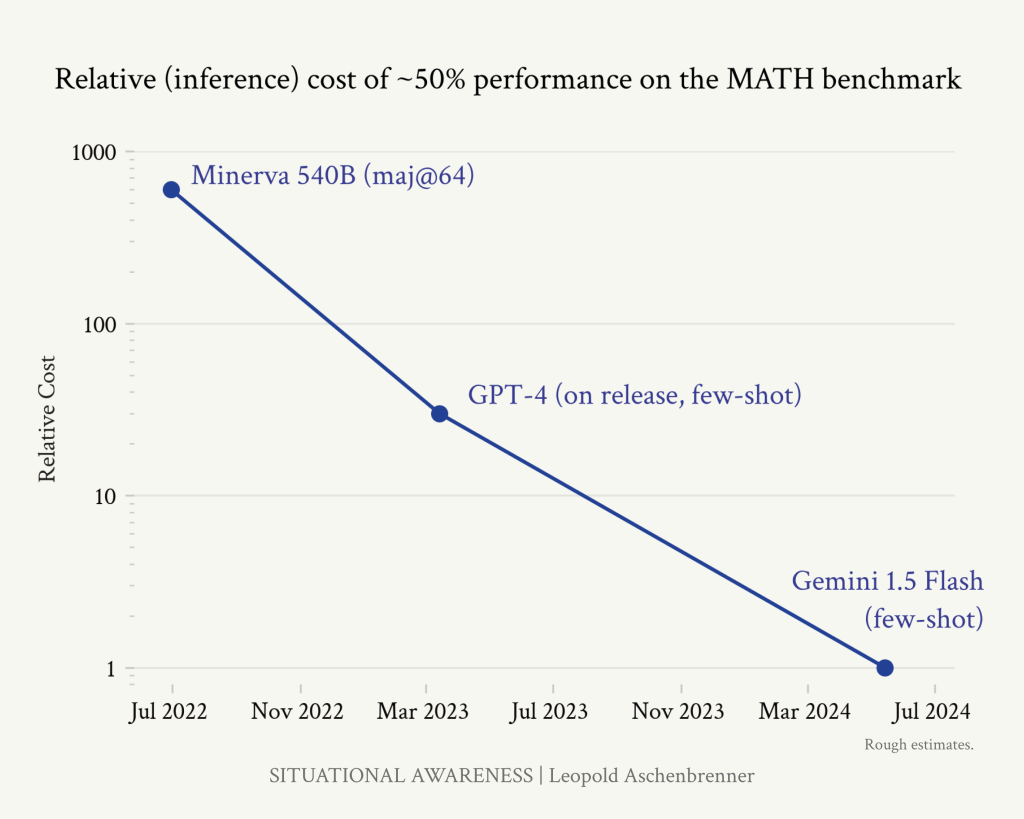
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
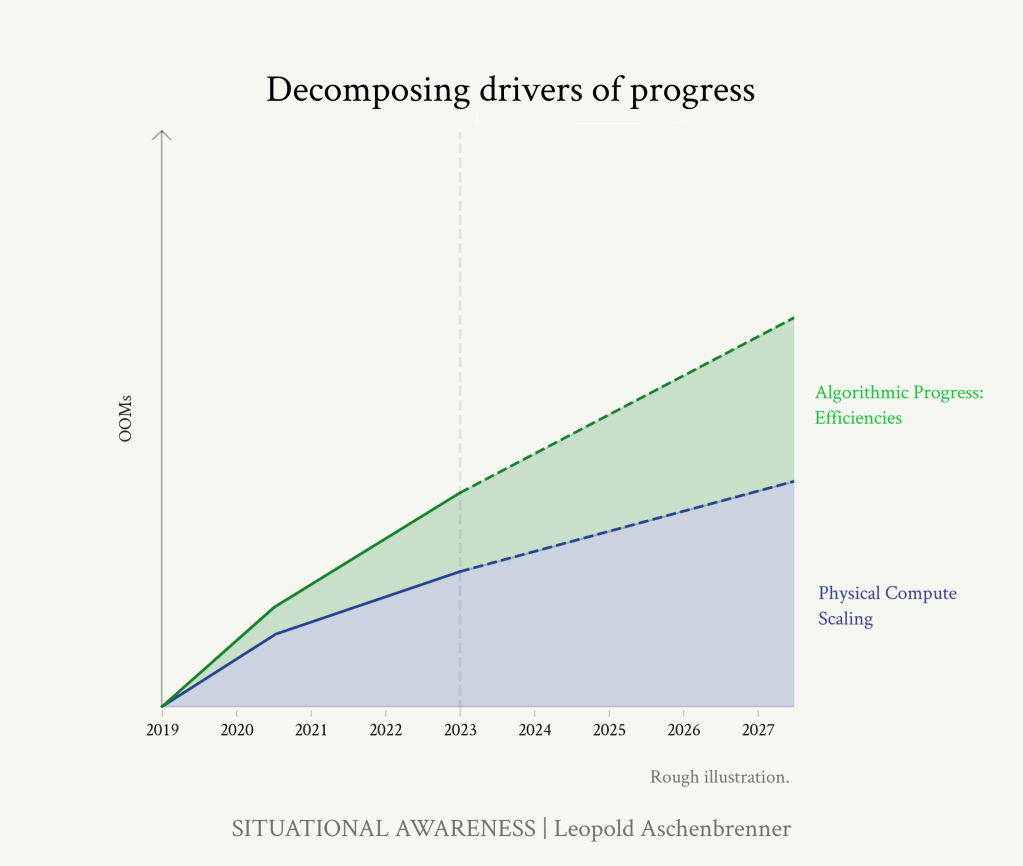
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
静岡県の川勝知事が辞任して、焦っているのはJR東海の役員連中ではないでしょうか。
ここから先の遅れは静岡県のせいにできません。これからが勝負というところです。
簡単に言うと、中央新幹線を、リニアモーターカーという方式で作ろうと言うものです。
中央新幹線はJR中央線をなぞって作られる予定だった新幹線です。
ちょうど、東海道新幹線は旧東海道本線をなぞった路線であることに似ています。
元々は東京から山梨県甲府あたりを抜けた後、今の中央線のように、山脈を迂回、長野県諏訪市を通って木曽谷を抜けるAルート、伊那谷を抜けるBルートの2ルートで検討され、伊那谷を抜けるBルートで意見が集約されていたと言う経緯がありました。
ところが、2010年頃に、JRがリニア中央新幹線を作るに当たって、首都圏の大深度トンネルと、大規模山岳トンネルを使い、ほぼ直線上に結ぶ「Cルート」を提案、沿線自治体もそれに同意し、建設が始まっています。
そのため、リニア中央新幹線は、並行在来線に該当する路線が無い全く新しい路線という事になりました。
中央新幹線計画は、戦前まで遡れる計画です。初の新幹線は東海道新幹線で実現しましたが、中央新幹線ルートが日本初の新幹線になっていた可能性もありました。
さらには、その当時は長大トンネルではありませんでしたが、山脈を峠越えして直線的に結ぶというアイデアは当時からあったようです。
リニアモーターカーとは、超伝導磁石で車体を浮かせると同時に推進すると言うものです。これはJR方式と言われ、
と言う特徴があります。
中央新幹線をリニア方式で建設するというアイデアは、1980年代に決まっています。山梨県にあるリニア実験線は、最終的に本線に組み入れられる予定で建設されています。
しかし、実は鉄輪式で作ると言うアイデアもありました。ですが、最終的にCルートに決まったことで、リニア方式でなければ建設ができなくなりました。
現在のルートは、リニアモーターカーの登坂性能が実現を可能にしたルートです。鉄輪式の新幹線に比べて、リニアモーターカは坂に強く、加速が速いと言う特徴があることから、実現しました。
また、リニアモーターカーは加速減速が非常に早いため、Cルート以外の迂回ルートでも、最大で7分程度しか時間が変わりません。それぐらい優秀な方式です。
東海道新幹線は東京名古屋大阪の旅客輸送で圧倒的なシェアを持っています。これを航空機で代わりにしようとすると、羽田空港が今の数十倍の規模が必要になるレベルの輸送を担っています。
ですから、これをバックアップするには、同等規模のシステムが必要です。
これは、大きなメンテナンスができないと言う事も示しており、改善が必要です。
さらに、JR東海はその収支のかなりの部分を東海道新幹線に依存しており、これが長期停止するようなことになると会社の存続が危うくなる、と言う意味でもバックアップです。投資をして利益率が下がったとしても、事業の継続性を高める必要があるのです。
ただ、以下の様な理由から、バックアップの社会的な必要性は低いという意見もあります。
東海道新幹線は既に増便数が限界に至っており、これ以上の増便ができない状態になっています。
そして、実際にはかなり無理をして増便をしているため、柔軟な運行ができない状態になっており、災害などの影響を受けやすいと言う問題を孕んでいます。
東京名古屋大阪の輸送需要があまりにも巨大なため、それをこなすためにこだまなど各駅停車の便が遅くなっていると言う問題もあります。
それを、最速到達手段の「のぞみ」をリニアに移管することによって、輸送容量の向上を行おうとしています。
これは言うまでもありませんね。新幹線の目的です。中央新幹線が通る周辺は、高速鉄道と飛行場の空白地帯になっており、東京からの時間的距離ではかなり遠い土地になっています。それらをリニア中央新幹線で解決していきます。
品川から名古屋まで40分、大阪まで67分というスピードがあります。これは大深度地下トンネルを通して、大ターミナル駅である、品川駅、名古屋駅、新大阪駅に直接乗り入れるため、相当に利便性が高くなります。
乗り換え時間も考慮されており、先行開業する名古屋駅では、リニア中央新幹線と東海道新幹線の間の乗り換えは3分を実現する設計です。
品川駅では、山手線までの乗り換えが9分とされており、この数字は、東京駅において、中央線から新幹線へ向かうのと同程度の乗り換え時間ですから、標準的な乗り換え時間と言えるでしょう。
リニアは東京名古屋大阪の大都市間をノンストップで結ぶ便が通常になりますが、1時間に1本程度各駅停車の便が設定されてる予定です。
この、1時間に1本という数字は、成田エクスプレスなど一部の例外を除けば、多くの在来線特急と同等かそれ以上の便数です。
このように早くなることは、従来は宿泊を伴っていた需要が日帰りになってしまうといった問題や、ストロー効果と言われる問題など、負の面も多く考えられますが、利便性という面では間違い無く向上します。
増えると思われます。東海道新幹線の旅客数は、コロナ禍の影響を取り除くと、右肩上がりで増え続けています。
(一般的にコロナ禍は2020年からとすることが多いのですが、鉄道・運輸に関しては、2019年の年末から影響が出ています。そのため2019年以降をコロナ禍の影響とすると、その直前2018年がピークで長期的なトレンドでは増え続けています)
さらに需要は回復傾向にあります。特に新幹線に限定すると、2023から2024の年末年始はコロナ禍前の予約数を10%上回っています。
また、JR東日本は、全線開業によって、東海道新幹線とリニア中央新幹線の輸送量は、2011年に対して1.2倍以上伸びるという予想をしています。ですが、実はこの予想、リニアが開通する前に達成されています。
2010年の東海道・山陽新幹線の旅客数はのべ約2億人でしたが、リニアの直前2018年には2億4千万人と2割増加しており、目標を達成しています。今後も増加していくことでしょう。
様々に分析がありますが、コンセンサスが得られているものは内容です。
ある説に寄れば
一方、インバウンドにその理由を求める方もいますが、実はインバウンドの旅客数は、全体に影響を与えるほど大きくはありません。
最新のJR東海の資産では、7兆円となっています。ただし、既に二年前の発表なので、今は更に増加しています。
更に工事の遅延や問題の発生などがありますので、東京名古屋間だけで10兆円を超えるのでは無いかと言う指摘も一部でなされています。
一方で、運賃は、東京大阪間、東海道新幹線に対して+700円程度と言う話は堅持しています。
単体では黒字にはなりません。何故ならば、東海道新幹線という強力なライバルがいるからです。
しかし、単体で議論する事に意味は無いです。JR東海は、リニア中央新幹線は、東海道新幹線と一体運用で利益を出していくと言っています。
例えば、リニア中央新幹線を黒字にする最も簡単な方法は、東海道新幹線を廃止する事です。ですが、そのような事に意味はありません。
先ほど乗客は増えるのか?の質問に対して応えたように、需要は堅調に推移していますから、計画通り進むでしょう
まとめると
と言うことになります。
なお、リニア中央新幹線はトンネルが多いと言う事で、崩落したら困るから被害が大きくなる、と言った心配がなされていますが、設計的に強度は担保されているという事、またトンネルはそもそも地震に強いため、そのような心配はほとんどありません。
また、リニア中央新幹線は浮上しており、強力な力で保持されているため、浮上しているなどから、鉄輪式よりも地震には強い方式です。
もし停電になっても減速に従って着地するので、急に落下するというようなことはありません。
少なくとも、震度6弱程度でおかしくなるようなことはありません。
日本のリニア技術は既に最先端ではありません。特に中国で盛んに研究が行われており、新しい方式も考えられています。
ですが、実際に実用として実装仕様とする試みは、最先端を言っていると言えるでしょう。
また、JR東海と日本政府などは、アメリカなどに売り込みを図っていますが、まだ正式に決まった計画はありません。これはまだ商用で動いているものがないからです。まずは国内での事例確率に力を入れていくことになると思われます。
また、JR東海の意向や安全保障上の理由として、かつての情報漏洩の教訓から、中国など東側諸国に対して輸出することは現状、有り得ないと思われます。
リニア中央新幹線によって最大の経営リスクが取り除かれるため、経営は安定するようになるでしょう。
JR東海の財務状況を見ると、東海道新幹線への依存が非常に高い状態が続いています。他のJRのように不動産などはあまり伸びていない上に、都市圏の路線が手薄です。
一方で、JR東海は、他のJRに比べて廃線などを行わず、維持する方向で経営を進めています。これは、新幹線で得た利益で地方路線を維持していると言えるでしょう。
この状態で最大のリスクは、大規模災害などで東海道新幹線が動かせなくなることです。これが解消できることで、経営上最も懸念される問題点が緩和される事になります。
最大の問題は、資金です。JRは当初自社資金のみで実施すると表明し、社債を発行、金融機関も融資を実行する予定でした。その返済計画は非常に堅調なもので、東海道新幹線が生み出す現状の利益でも無理なく返済できるような計画でした。
しかし、その計画でいくと、リニア中央新幹線は、名古屋まで開通した後、負債を減らす期間をおいてから大阪延伸に進むと言う計画になっていました。
その状況に、リニアが開通することで、名古屋が東京と事実上一体の経済圏を形成することになる(何しろ、品川から山手線の反対側にいくのと同等の時間で名古屋まで来れてしまいます)事に危機感を持った大阪周辺の政治家・経済界の要請により、国が財政投融資によって低利の資金を供給する代わりに、前倒しすることになっています。
このようなことから、今回の財政投融資は、かつて特殊法人などに資金を供給した「第二の予算」とは性質が大きく異なるものであることがわかります。
もちろんです。辞める理由はありません。
ただ、技術的や制度的には大きな課題が山積していて、本当にできるかどうかは、まだわかりません。
以下に挙げますと
金銭的問題や人手不足などは、時間か資金のかけ方次第ですからどうにでもなると思われますが、技術的問題はなかなか解消が困難です。
最も困難だと思われるのが、大都市圏の大深度地下トンネルの技術的な問題です。ここが最も時間がかかるとしていて、真っ先に着工したものの、進捗が芳しくありません。
一方で、山岳トンネルは技術的にも安定した工法を採用しているため、比較的進捗は良いので、ここは致命的な問題にはならないと思われます。
もしかしたら、2034年に、神奈川県相模原市の車両基地から、岐阜県駅or名古屋駅の間の先行開業というようなこともありうるかも知れません。品川駅までは大阪延伸と同時期ぐらいまで延期はありそうです。
JRは静岡工区のことを強調しながら、2034年以降と言っていますが、それ以外の工区でも遅れが出ています。
近隣自治体には、正式に2032年完成予定といった線表が通知されているそうですので、計画では2032年にできる様な線表で進めつつ、もう2年ほど安全マージンを取っているものと思われますので、早ければ2032年、遅くとも2034年がキーになり、首都圏の大深度地下トンネルという最難関の工事が遅延した場合、部分開業も検討するのでは無いでしょうか。その時点で名古屋まで開業しており、首都圏トンネルの完成目処が立っていない場合は高確率で部分開業へ舵を切ってくると思われます。1
また、関係者はそもそも2027年にできるなんて誰も思っていません。予定通りだった山岳トンネルもコロナ禍で1年半近く事実上工事がストップしていましたし。
さあ?
こども家庭庁が発表した試算は下記の通り(いずれも月額)
| 年収 | 2026年度 | 2027年度 | 2028年度 |
|---|---|---|---|
| 200万円 | 200円 | 250円 | 350円 |
| 400万円 | 400円 | 550円 | 650円 |
| 600万円 | 600円 | 800円 | 1000円 |
| 800万円 | 800円 | 1050円 | 1350円 |
| 1000万円 | 1000円 | 1350円 | 1650円 |
2026年度は1.2/1000、2027年度は1.6/1000、2028年度は2.0/1000と考えられる
そこで年収1000万オーバーのはてなー用に計算してみたのが下記の表だ
参考にしてくれよな
| 年収 | 2026年度 | 2027年度 | 2028年度 |
|---|---|---|---|
| 1200万円 | 1200円 | 1600円 | 2000円 |
| 1400万円 | 1400円 | 1850円 | 2350円 |
| 1600万円 | 1600円 | 2150円 | 2650円 |
| 1800万円 | 1700円 | 2200円 | 2800円 |
| 2000万円 | 1700円 | 2200円 | 2800円 |
この辺りが単なる経済活動って感じで良いよな
この話、2022年のエネルギーショック前には、補助制度がなくなって2027年には風力は減っているだろうって予測されてた
2022年のエネルギーショック時には電力卸売価格はフランスで10倍に膨れ上がってる
そりゃ意識も変わろうかってな
そんで2023年にはフランスは原子力傾倒を強める方向へ向かうんだけど
市場は電気代高騰を受けて電力需要が底をついて回復していないのと
偏西風がなく台風が来る(強風下では火災や倒壊のリスクが跳ね上がる)日本で風力とか正気か?って感じだし
長野とかそこら中にパネルがあってな、そんな中霧ケ峰にメガソーラーを設置しようとする話は、水源だなんだと問題になって事業者が撤退してる
地熱は、そもそもそれをエネルギー転換して大丈夫なのか?って気がするし
(風力や潮力よりもエネルギーとして熱を消費する事の環境負荷が高そう)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}