はてなキーワード: モデリングとは
俺も数年前まではそうだったふと見た切り抜きからそこそこvを見るようになった
好きになりたいならまずは切り抜きを見ろ
いろんなvの切り抜きを
最初から雑談とかゲーム配信とかの長時間のを見ようとするのは無理だしタイパ悪すぎる
俺がみるようになったきっかけはつきのみとの切り抜きだった 増田でもつきのみとからはまったって人いたけどあんな感じだった
ふみのたまきも切り抜きから入った こいつはいろいろ常識とか衛生観念やばいのが面白くてみるようになった
でも一線こえるとかvtuberの世界観・キャラ設定をぶっちゃけるほどではなくてそこはわきまえてる
雑談でもほんとにてきとーに話す奴もあるけど、きっちり話すネタをいくつも用意してきて話すこともあるから、きいてて面白い
着眼点も新鮮で、ありきたりな観点とずれてるからきいてておもろい
6年目とからしいけど、最近の配信は声に元気なくて引退しそうだなって思ってる
ユーチューバーあるあるネタをやるんじゃなくてこいつ独自の観点でいろいろ工作したり考察したり語ったりするからすげーおもろい
配信でしゃべってる内容からするとまだはたちそこそこみたいなんだけど生物に関する知識もやばい
昔からYouTubeでそういう工作系のやつとか見るのが好きだったらしいけど
着眼点とそこからの考察 実験 反省とかの流れは子供に見せたくなるレベル
はははしにたい
コンテンツ集合Xがあります。各々の要素x∈ Xは特徴量f_1(x)∈Y_1 を持っています。
同様にユーザーu ∈ Uが存在し、特徴量f_2(u)∈Y_2を持っています。
コンテンツには単価P(x)が存在し、ユーザーuがコンテンツをm回消費することをg(u, x, m)=m*P(x)_uで表し、全てのユーザーU, 全てのコンテンツXに対して行列M∘P = g(U, X, M) が存在します。
回答
この問題は、コンテンツとユーザーの特徴量を考慮して、ユーザーがコンテンツを消費する回数を最大化するものです。このような問題は、推薦システムの分野で広く研究されており、協調フィルタリングと呼ばれるアプローチが一般的に使われています。
協調フィルタリングアルゴリズム
協調フィルタリングには、以下のようなアルゴリズムが考えられます。
1. 行列因子分解 (Matrix Factorization)
行列因子分解は、ユーザー・コンテンツ行列を低ランク近似することで、ユーザーとコンテンツの潜在的な特徴を抽出します。具体的には、ユーザー行列Uとコンテンツ行列Vを求め、その内積U^TVで元の行列を近似します。この手法は、Netflix Prizeで優れた成績を収めました。[1]
2. ニューラルコラボレーティブフィルタリング (Neural Collaborative Filtering)
ニューラルネットワークを用いて、ユーザーとコンテンツの非線形な関係を学習します。入力としてユーザーIDとコンテンツIDを与え、出力として評価値を予測します。この手法は、従来の行列因子分解よりも高い精度が期待できます。[2]
3. 階層的ベイズモデル (Hierarchical Bayesian Model)
ユーザーとコンテンツの特徴量を階層ベイズモデルに組み込むことで、より柔軟なモデリングが可能になります。この手法は、Cold-Start問題(新規ユーザー・コンテンツの推薦が困難)の解決に有効です。[3]
4. 強化学習 (Reinforcement Learning)
ユーザーの行動履歴を環境として捉え、報酬最大化のためのアクションを学習します。この手法は、長期的な利益最大化に適しています。[4]
これらのアルゴリズムは、ユーザーとコンテンツの特徴量を考慮しながら、目的関数を最大化するように設計されています。実装の際は、データセットの特性やモデルの複雑さ、計算リソースなどを考慮する必要があります。[5]
Citations:
[1] https://aicontentfy.com/en/blog/understanding-algorithms-behind-content-distribution
[2] https://marketbrew.ai/optimizing-your-websites-content-with-genetic-programming
[3] https://sproutsocial.com/insights/social-media-algorithms/
[4] https://surferseo.com/blog/the-new-algorithm-for-content-analysis/
[5] https://www.linkedin.com/advice/0/what-best-ways-measure-content-relevance-x6apf
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
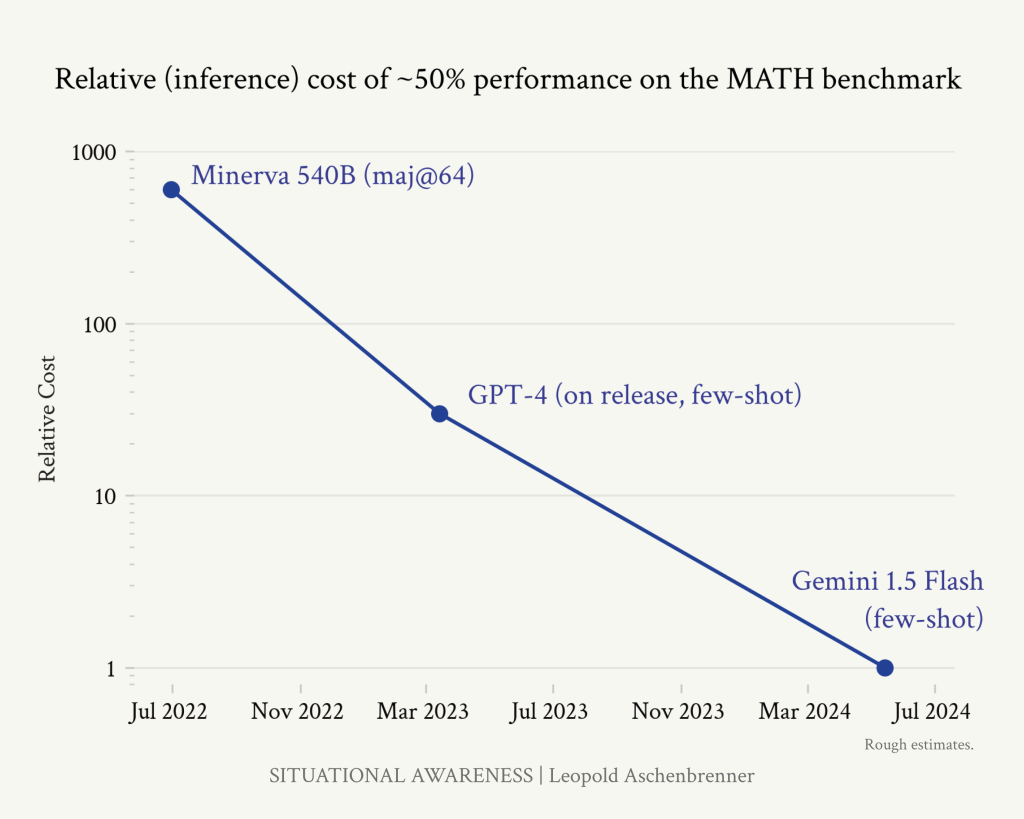
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
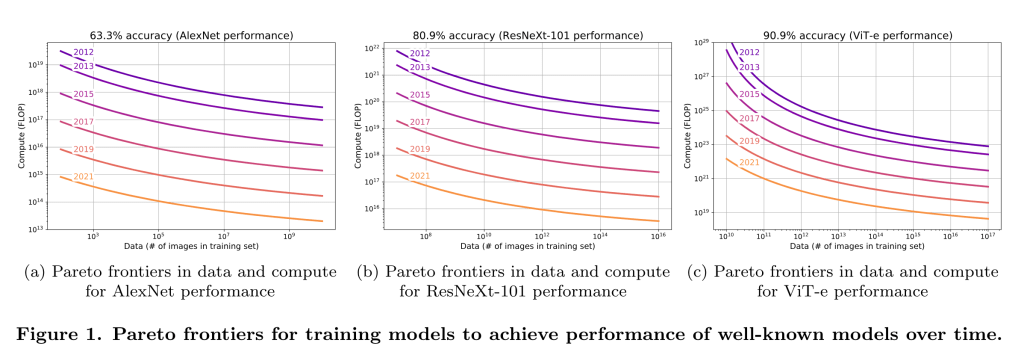
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
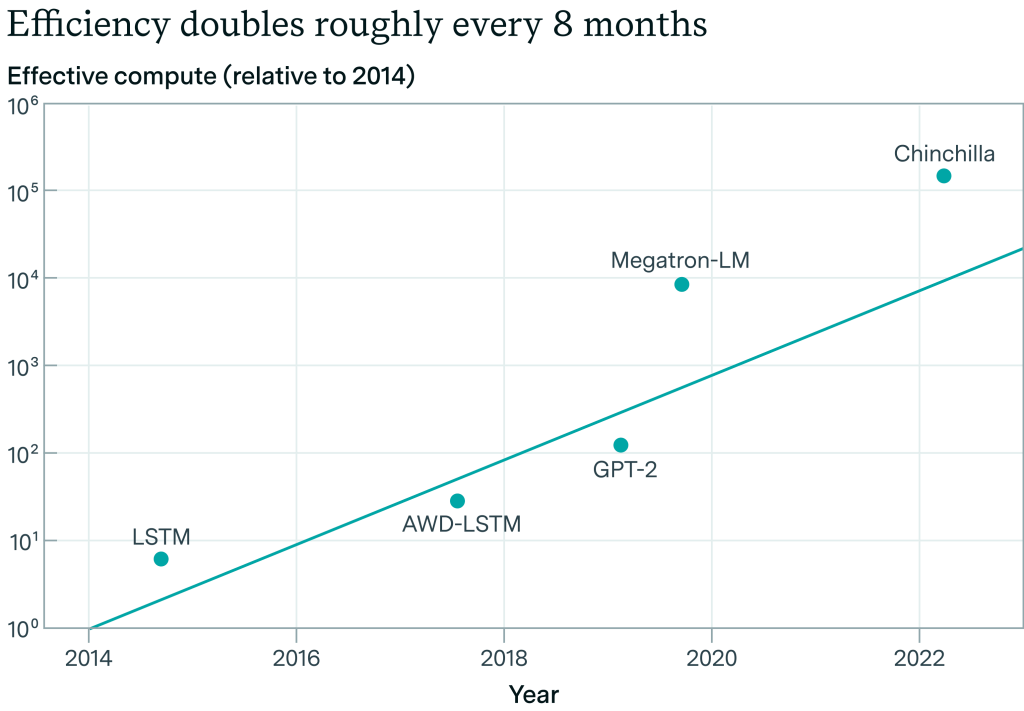
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
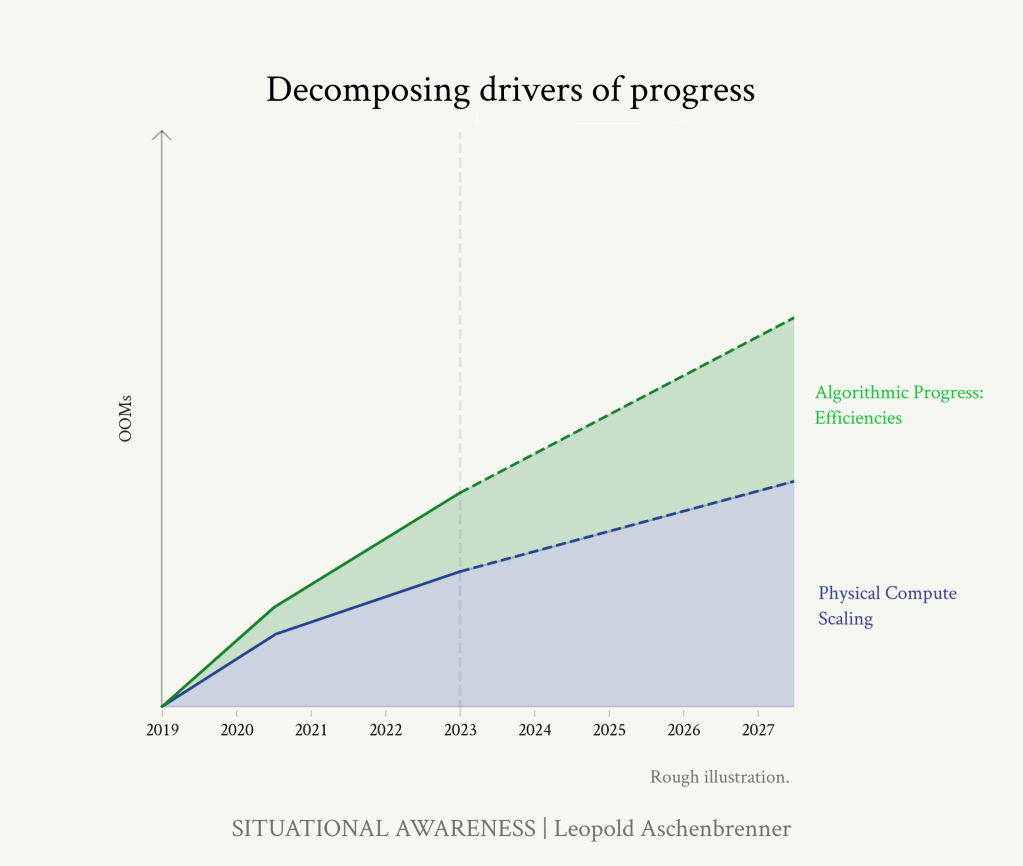
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
トラバもはてブも色々コメントありがとうございます!一番刺さったのは「男ともセックスしてみる」でした。考えたこともなかったし体験した後の風景が一番想像できない。人生経験として体験してみるという発想に衝撃を受けました。なかなか勇気出ないだろうけど死ぬまでにやることリストにメモしました!
追記ここまで
Die with zeroを読んでとても感銘を受けた。子供の頃貧しかったのでお金が増えるのがただただ嬉しく、仕事ばっかりやっててお金が溜まる一方だったが、これではいかんことにようやく気づいた。一度贅沢しちゃうと戻れなくなるーとか思って抑圧してたけど、よく考えたら贅沢で破産するほど人生残ってないし、お金を気にせず経験を積みまくろうと決意。やってみたことは以下の通り。性的欲望も抑圧してきたのでこちらも存分に解放していく所存。
まだ数百万円くらいは使いたいので、経験値の観点でなんかオススメできる散財方法があれば教えて欲しいです!(自宅はあります)
真面目に議論するなら、お好み焼きをクラスとするかも怪しくなる。
オフトピだがね。
オブジェクト指向が栄華を極めたあの時代、責任、関心、主体性、凝集、アイデンティティ、is-a has-a、… 研究者やギーク、仙人らによって、あらゆる説明がされたが、結局、オブジェクト指向は現実世界を捉える人間の感覚の応用でしかなかった。
「モノ」と思える奴をクラスにすればいい。
それ以上でも以下でもなく、あとはプログラミングの構造を整理するために有効に使えるケース・バイ・ケースの妥協点を探すことになる。どうモデリングすべきかの議論は収穫が少ない。いや、極めれば霧の向こうで信じがたい洞察を垣間見れる可能性はあるにはあるが…、しかし多人数でソフトウェアを維持管理するのが正解だと分かった今、属人性を排除するためには霊感を説明するよりシンプルに留めるのがベスト・プラクティスだ。
プログラマーの関心が関数型に移ったのは、そういう経緯もある。数学をバックグラウンドに持つ関数型言語をバックグラウンドにする方が、ミーハーな技術屋連中の興味を引けた。
githubでなにか作ったものをアップロードするのは、自分向きではないことに気がついた。
私が仕事で作っているようなwebアプリケーションというのは、誰でも使える一般性の高いものではなく、もっと特定のビジネスに依存した特殊なものである。
だから一般的な誰でも使えるようなものを作るというのにはあまり慣れていないのだ。
なにか作る場合はkaggleのほうが遊び場として向いていると思っている。
kaggleで「コンペ」に参加するつもりはないし、あれはBERTが出現したぐらいからは、少なくともNLP(自然言語処理)界隈は不毛な場となってしまった。
指標があれば不毛なハックがある。それが現実というものである。
それに業務で実用レベルで使えるモデルというのは、もっと運用のしやすいシンプルなモデルである。
モンスターアンサンブルで精度がSOTAでーすピロローン!なんてことには興味がないが、コンペはそれを目指している。
ではなぜkaggleが良いかと言うと、データセットが転がっていて、notebookも簡単に作成できるからである。
「このデータをこうやって使うとこういうツールが作れる」「このデータをこうやって分析するとこういう知見が得られる」というのは、「web開発用のMVCフレームワークを作ります」よりも具体性がある。
そして特定のデータに対するモデリングをするために論文を調べるようなことになった場合は、勉強にもなる。
私は昔、自然言語処理のブログを書いていたが、実験したことのコードを載せるタイプの記事が多かった。
ところが自称データサイエンティストや自称NLPエンジニアがツイッター上で「ゴミのようなブログを書くな」と言っていて、自分が言われている気がして怖くなったのでブログを閉鎖した。
そういう「政治おじさん」との接触を最大限減らすには、ブログというフォーマットではダメだと思うわけである。
私のマグカップには"Talk is cheap, show me the code."と書かれている。
これはリーナストーバルズの名言だが、政治おじさんが近寄らない場所というのは、具体的なコードが存在する場所であると言えよう。
最初に断っておくと、これは個人的なリアリティラインと制作側の演出のリアリティラインが合ってない、結果として「嫌なら見るな」でしかない話。ちょっと期待してた分のガッカリした気持ちを吐き出したいだけだ。
ガールズバンドクライは、何らかの問題を抱えた少女たちが出会いバンド活動を通じて自己実現していく系の作品だろうと思って視聴し始めた。まあそこは実際どうだかはおいといて
といったことからも、バンドにまつわる描写にはとくに本腰入れてリアリティ出そうとしてるんだと思った。音楽周り中心に周辺事情はちゃんと描くからこそ、ぶっ飛んだキャラ設定などのフィクションならではの部分に対して嘘くささを忘れられてドラマ性が高まる、そういうもんだと思ってる。
が、実際には1〜2話では逆の、とくにバンド関連の嘘が、演出だとしてもひどい印象だった。
なんかこの辺、要らん嘘って感じで、ストーリー展開のための嘘にしか思えず、演出だとしても筋が悪いように感じられて、視聴のノイズでしかなかった。
1話で仁菜のギターの扱いが酷いのは単にど素人だから別にいい。仕方ない。「他人の」「楽器」ってだけで大事に扱う常識的な感覚、を持ち合わせていないキャラで構わない。あと1話は、仁菜の住む予定の部屋の隣、そんなアパートに小さな子いる家族で住む?みたいのも気になったがあり得なくはない。2話での、壊れたシーリングライトをスイッチもブレーカーも落とさず着けるシーンは危ないのでやめて欲しいが、そこが無知なのは仕方ないというか全然有り得る。ちょっとした家電の知識すらない大人も現実にいる。そういうのよりスマホリテラシーの偏りの方が不自然に思える。ストーリー都合過ぎる感じがとてもした。
3、4話ではノイズになる嘘が減ってきた。3話の歩いてない鳩の首リズムも嘘だが、ストーリー展開が絡まないギャグ演出みたいなもんなのでそこは許せる。
冒頭にも書いたけど結局は個人のリアリティラインと作品のリアリティラインがズレてるだけの話。気にならない人には気にならない。
こういうこと書くとダブルスタンダードっぽいが、例えばバンド活動を主軸に扱った作品でも、以下のようなものはフィクションとして気にならない。
少なくともガールズバンドクライという作品で描きたいであろうテーマからすれば、上記に挙げたようなところはフィクションで構わないと思える。まあチートというか。例えば「バンドって金かかるし貧乏生活になるよね、そこをどうあがいて脱していくかを描きたい」ってんなら話は別だけど。なんか「いないパートの楽器の音が鳴る」のはチートじゃなくて、シンプルに嘘なんだよね。
花田作品は結構、ストーリー都合の「付かない方が世界観の品質維持できてよかったろうにという嘘」が多い印象はある。でも全部が全部自分に合わないわけじゃなくて、監督やどの辺に監修入ってるかとか、何題材にしてるか(→見る側のリテラシー変わってきてリアリティラインも変わる)などで結構変わる。
つーか
セクシーで紳士殿方が目のやり場に困るでお馴染みのイヴに一目惚れよ!
超超超カッコよくない?
だから私はわざわざプレイステーション5ごと買っちゃってイヴになりきって地球を救うの!
Switchにもたくさんあるけれどプレイステーションにも救うべき世界がたくさんあってどんだけ人々は世界を救わなければいけないのかしら?って思うわ。
なので
昨日はプレイステーション5の初期設定に苦戦したけれどもう大丈夫!
プレイステーション5の機能のサポートおしゃべりモードが発動していて
いちいちメニュー画面とか全部の画面でプレイステーションがしゃべるって操作の手助けをしてくれるんだけど
アクティビティの項目でなんとか見つけ出してオフにしたけれど慣れない初めての機械は一苦労よ。
もちろん今日からは帰ってからは本編で地球を救えることになるんだけど、
まあ
体験版でも敵を上手に倒せないまだ慣れない感じが苦戦するわ。
でもイヴ超カッコいいの!
もうさハードごと買っちゃって正解だわ。
衝撃的な出会いだわ。
まだ体験版を1時間程度やって遊んだところでもう寝るお休みの時間になったので、
寝ることにしたんだけど
プレイステーション5って電源どうやって切んの?って
スリープのままでもいいのかしら?
つーかスリープって言わないの?
レストモードでレストランかよ!って思うぐらいレストって言う言い方に最初慣れなかった自分がいた時代があって、
慣れないけれど
そのぐらいの使命感つーか
イヴカッコよすぎて
それは二の次!
イヴのモデリングがもの凄く美しくてそれだけで見とれちゃうぐらいよ。
まだまだ最初の1時間でバトルもろくに雑魚敵でやられちゃうぐらいだけど
それにコスチュームもいろいろあるみたいだけど、
まだ私のイヴはデフォルトのプラネットダイブスーツしか履いてないから安心して!
なんとか頑張って強くなってイヴになりきって張り切って荒廃した地球を救うの!
プレイステーションのコントローラーの三角と四角の位置が覚えられなくて、
いちいち手もとを見てしまうのが相変わらずワレながらダサみを感じつつ
まだ慣れない決定ボタンがバツなことにもバツの悪さを感じざるを得ない慣れない感じが否めないわ。
あと急にL3ボタン!って言われても、
そのボタンどれ?って迷うし分かんないし、
冷静になったらスティックの押し込むボタンがR3L3になっているのね。
あとコントローラーの上部中央にある平べったい大きなボタンって何?
押してもなんもならないんだけど、
そんでイヴのフィールドの画面で押したらサポートドローンがスキャンしてくれるボタンみたいで、
これ以外の使い道がよく分からないわ。
助けてくれてかばってくれてやられたタキの分も!
もう楽しみすぎてさんざんピーアール動画を見まくったあの迫力のあるシーンは
体験版のものの5分ぐらいの場面で全部見れちゃうぐらいの濃さで
これからどんなシーンがいや
どんな荒廃した地球を救うのか私は絶対にイヴになりきって地球を救うの!
優しさの配合が50パーセント処方されているの頭痛薬とも違うやつ。
ベヨネッタのお姉さんもカッコいいけれどまあ言っちゃ悪いけれど年増よね。
お姉さんって感じ。
プレイステーション5すらも持っていなかったぐらいでも
ハード毎買っちゃって
私は第7空挺部隊のイヴになって荒廃した地球をネイティブから救うの!
清く逞しく泥臭く、そして艶やかに!
って違う違うそれは朝ドラ『ブギウギ』の梅丸歌劇団のモットー!
あっているのは艶やかさだけね。
もーさーイヴがカッコよすぎて
もうストーリーとかバトルとか進めなくても
カッコよすぎる!
でもその格好良さにかまけてないで
私は絶対に荒廃した地球に蔓延るネイティブを討伐して世界を救うの!
そのぐらい躍起に満ちているわ!
タキのためにもよ!
タキの敵は討つ!!!
この状況は気が向いたらまた書くから私のいやイヴの活躍を応援して欲しいわ。
あんまり難しくて話のストーリーが進まなかったらごめんなちゃいだけど!
とにかく私は荒廃した地球をイヴになりきって張り切って救うわ!
うふふ。
すっかりご飯食べるのは忘れていたわ。
でもルービーは忘れなかったけれどね!
今日から製品版ダウンロード準備して出掛けて帰ってからは本編よ!
その意気込みを感じるぐらい
炭酸レモンウォーラーをゴクゴクと凄い勢いで飲み干したところよ。
すいすいすいようび~
今日も頑張りましょう!
自分の摂食障害が一番ひどかったとき(BMI12.9)と同じような体型をしてたので気になったという話。
SNSで「いくらなんでもガリガリだ」と話題のソシャゲアイドル篠澤広(しのざわひろ)。
2Dイラストには特に違和感がないが、3Dモデルがあまりにガリガリすぎて、どう見てもBMI13〜14くらいにしか見えない。
159cm41kgという設定だけど見た目は33〜34kgという感じ。
服のポケットに重りを入れてる?
そういう裏設定があるなら納得できる。
もし本当にBMI16の設定なのであれば、3Dモデリングをした人がBMI16の体型がどんなものなのか分かってないと思う。
もしくは、3Dモデルを監修する立場の人が「実際のBMI16の体型とかどうでもいいから、とにかく骨と皮みたいにして」と指示しているとしか思えない。
分析ツールを作って、様々な凝った統計情報を表示したいと思ったことはないだろうか。
ロジスティック回帰でモデリングして係数表示をしたり、決定木を視覚化したり、相関の行列をヒートマップで表示したりと、いろいろなことができる。
しかしいざツールを作ってみると、「そんな分析は必要ない」と叱責されてしまうのである。これは一体どういうことなのか。
それは開発に近い人の考える「分析」とビジネスに近いところにいる人の「分析」が、メンタルモデルからして全然違うのである。
ドメインに近いところにいる人たちは、もっと基本的な統計を要求するだろう。
収益の推移だったり、アイテムが特定の属性のユーザーにクリックされる確率だったり、特定の条件に合致するアイテムの単価の分布だったりと、そういうものだ。
開発者がやるべきことは、csvファイルをアイテムに対する特定の検索条件・グルーピング条件などで出力してダウンロードさせることだ。
{kind=link}
{kind=link}
{kind=link}
{kind=link}