はてなキーワード: ブレークスルーとは
この意見については、いくつかの妥当な点と問題点、矛盾点が見られます。以下にそれらを整理して評価します。
妥当な点
• 自然科学の研究分野において、中国は論文数や研究の質で急速に成長しており、アメリカを追い越す分野も出てきているのは事実です。中国の研究開発費も増加しており、この点は現実を反映しています。
• 中国の製造業の競争力や発展についても、多くの国が依存している現状を考えれば、意見の妥当性があります。特に半導体や鉄鋼など、製造業でのシェア拡大は現実に進行している問題です。
• アメリカが製造業から離れてITや金融にシフトしているという指摘も、事実に基づいています。アメリカは確かにハイテク産業やサービス産業を強みとする一方、製造業の一部が海外に移転している状況が続いています。
• 米中の緊張関係が高まっていることや、台湾有事の可能性について触れている点も、現実の国際情勢を反映しています。アメリカと中国の競争は軍事や経済だけでなく、地政学的にも大きな影響を与える可能性があります。
• アメリカが製造業で完全に衰退しているという意見は極端であり、現実とは少し異なります。アメリカは依然として半導体やハイテク製品の分野で強力なプレーヤーであり、技術革新においても世界をリードしています。また、製造業への回帰が進んでいる動きも見られます。
• 自然科学や製造業で中国が優位に立っている分野が増えていることは確かですが、軍事力や全体的な経済規模においてアメリカを完全に追い抜くという予測は、依然として不確実です。多くの要因(政治、技術のブレークスルー、経済政策など)が絡み合っているため、単純に「いずれ抜く」と断言するのはリスクがあります。
3. 「経済が追い抜かれる前に潰すしかない」という表現の非現実性
• 「アメリカが中国を潰すために行動する」という考え方は、現実の国際政治の複雑さを考慮していない面があります。経済制裁や関税政策は確かに利用されていますが、全面的な対立を望んでいるわけではなく、協力や対話も試みられています。
• 日本や韓国、台湾が再び製造業に注力するというシナリオは一理ありますが、それが中国に対抗できるレベルにまで達するかは不透明です。生産コストの問題や人材の不足など、製造業回帰には多くの課題が存在しています。
• この見方は単純化しすぎています。確かに、西側諸国が労働コストの低い国々に製造業を移転している歴史的背景はありますが、今日のグローバル経済は相互依存的であり、利益共有や技術協力の関係も重要な要素です。
• この意見をより説得力のあるものにするためには、具体的なデータや現実の事例を引用し、推測や憶測に基づいた主張を避けることが重要です。また、アメリカや中国の強みと弱みをバランスよく評価することで、より包括的な視点を提供できるでしょう。
この意見には、中国の台頭やアメリカの現状について妥当な指摘がある一方で、過度に単純化された見解や、極端な推測に基づいた部分も含まれています。国際政治や経済の複雑な動向を考慮しつつ、より現実に即した分析を行うことが重要です。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
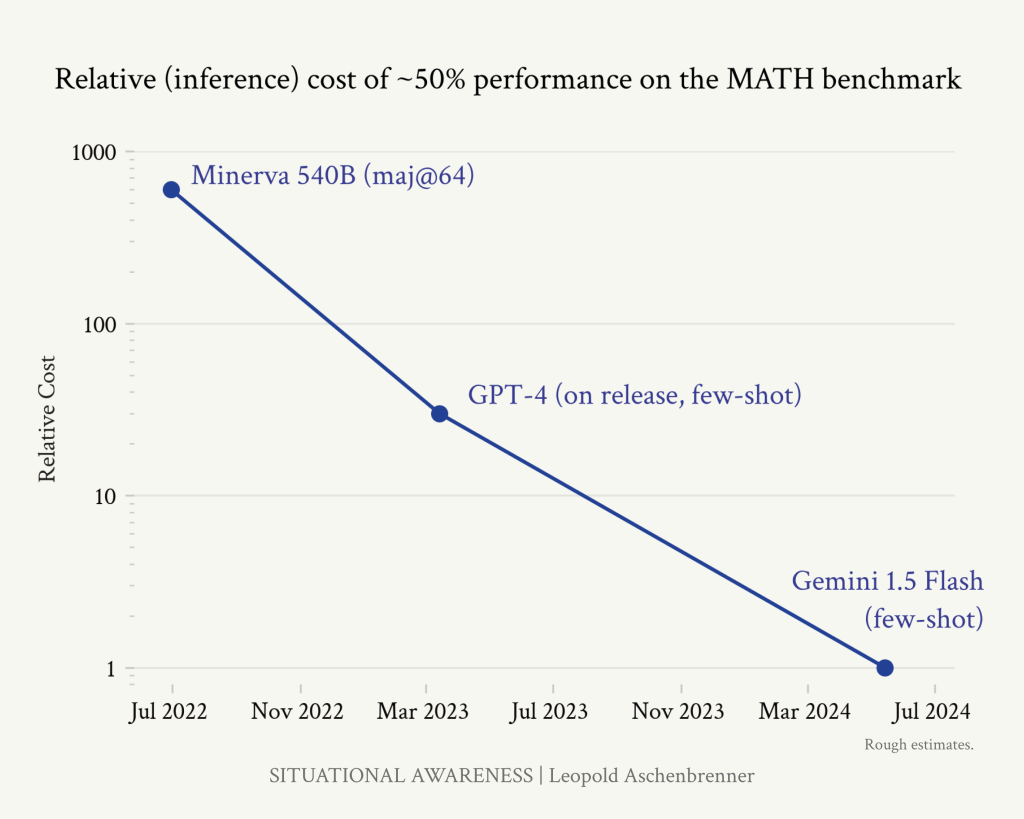
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
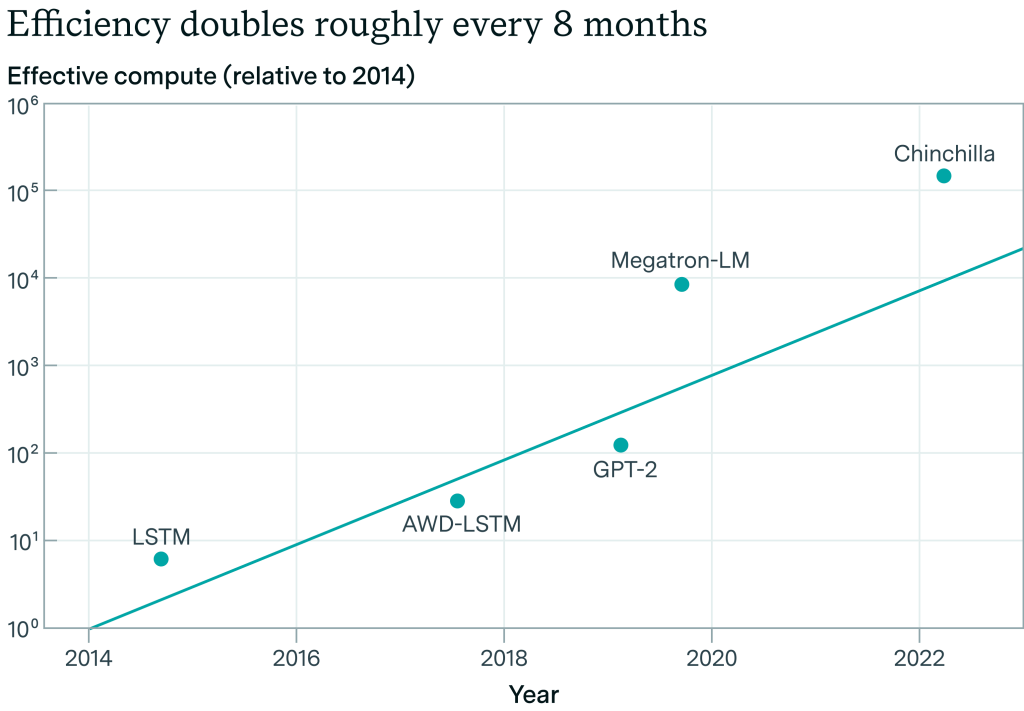
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
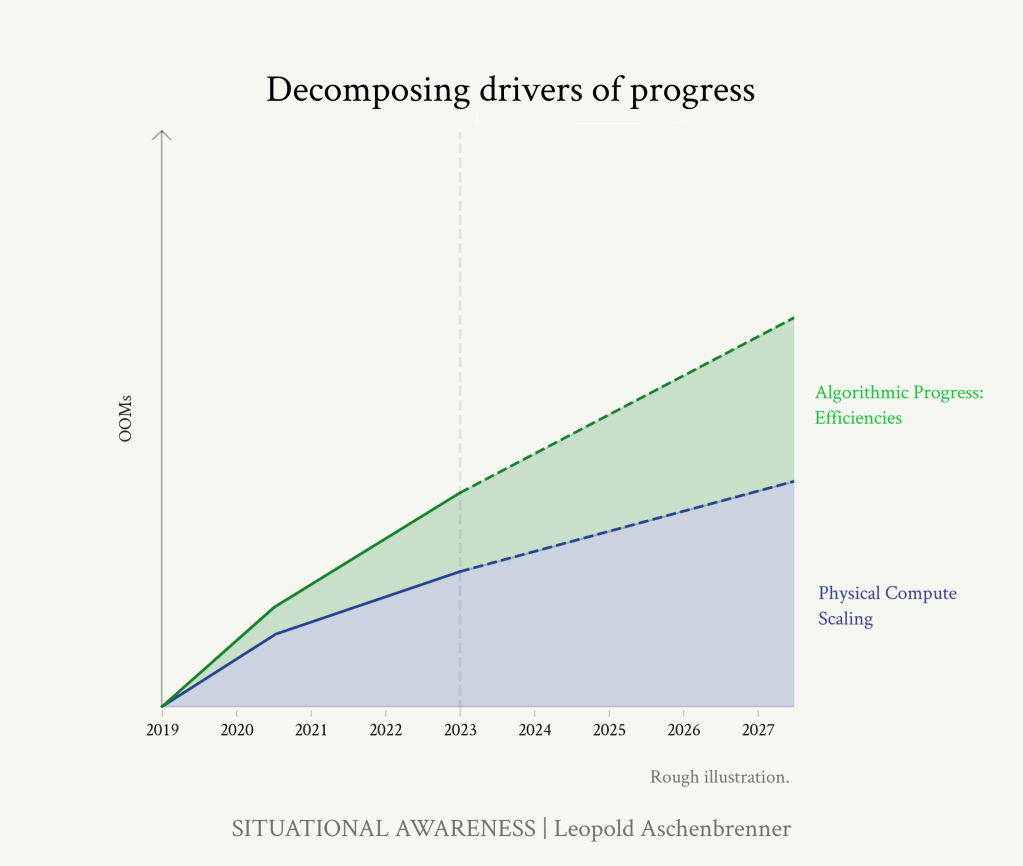
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
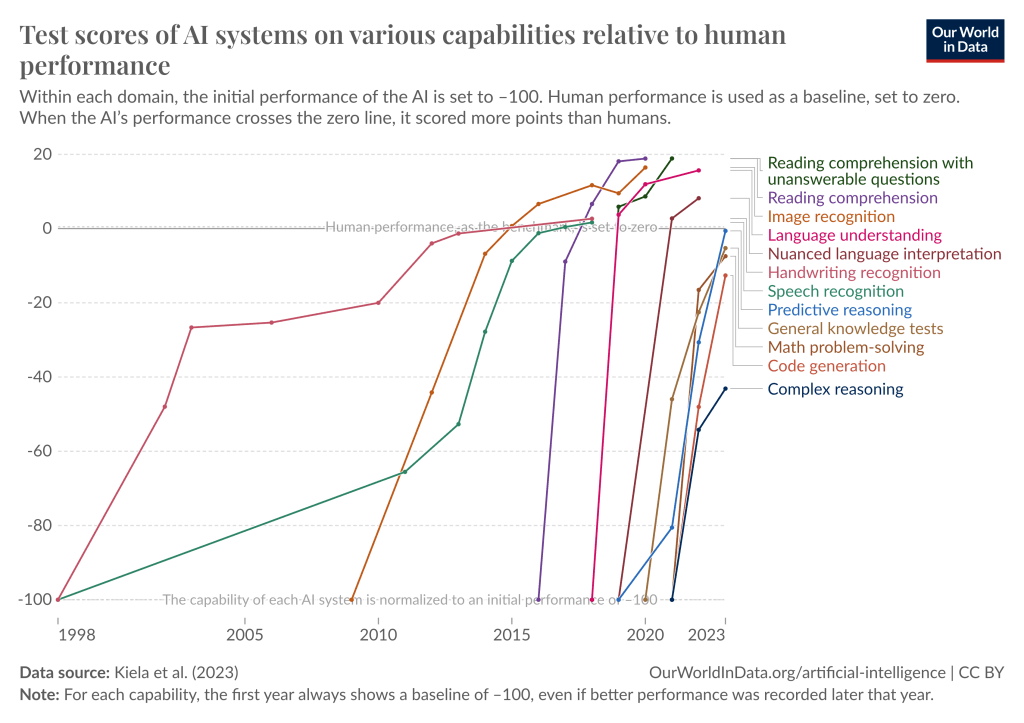
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
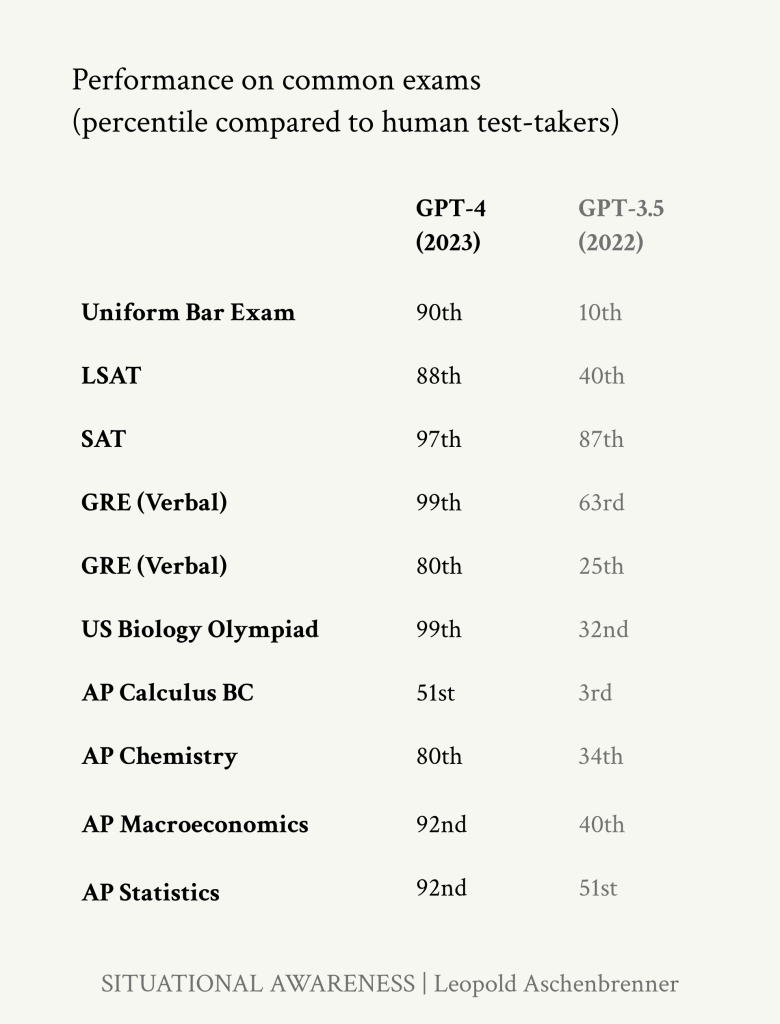
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
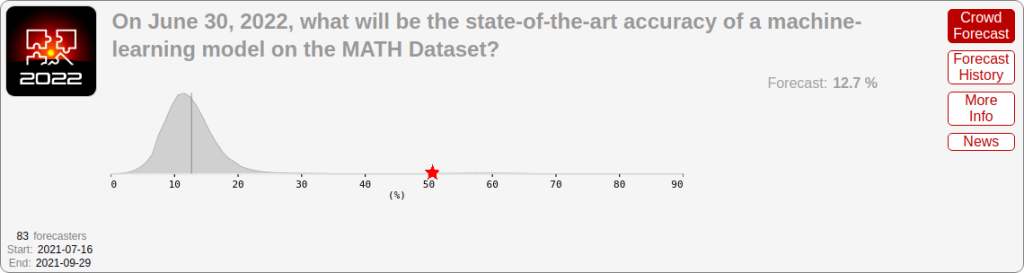
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
本当どうしてくれるんだよ!!!!!
もう何も考えたくないよ!!!!!!!本人コメント以外のコンテンツに触れる勇気がまだない!!!!!!!!!だからもしこれを見つけてしまったオタクの皆さん解釈違ってたら本当にごめんなさい
推し(自担)の中島健人さんが所属グループであるSexyZoneから卒業するそうです。
今、推しが大きな前触れもなく脱退するとはどういうことかとても噛み締めています。本当に永遠ってないんだな!存在しないからこそ何気ない瞬間で「こんな素敵なことが永遠に続くかもしれないな……」と感じることがめちゃくちゃ尊くて価値のあることなんだね!!!!!
私は中島健人のいるSexyZoneに永遠を感じてしまったよ!!!!!たとえステージを降りる仲間がいようといつも同じ空気感でしょうもないこと喋っては年下メンバーたちが窘めようとして、上手くいかなくてまた話が転がっていってわちゃついて、でもひとたびパフォーマンスするとなると全力で世界観を作り上げに来るフロント、それからスタッフの方々が本当に良くて、素晴らしくて、飽きなくて、一時期離れちゃったときもあったけど何だかんだ自分が心から楽しめるエンタメを提供しているのはやっぱりここだと思って帰ってきたんだよ!!!
入口はたしかにJMK中島健人のラブホリ王子様があまりにトンチキなのに本人が至って真剣に乙女ゲー攻略キャラやってておもしれー男だったからだけど、グループの楽曲もめちゃくちゃ好きだよ!!!!!何故かやたらと楽曲提供者が自分に刺さるのも本当に何なんだよ!!!!!トフビもiriもNulbarichも岡崎体育もLUCKY TAPESもPenthouseも楽曲提供される前から聞いとったアーティストばっかりやどうしてくれんねん!!nobodyknows+だってココロオドル聴きながらジム通ってんねん!!!!!多分そのうちSyrupも楽曲提供すると思う。知らんけど。
でも!!!私は!!!!私の生けるバイブル椎名林檎の提供楽曲をセクゾが歌うという夢が叶っても図々しいから☆Taku Takahashiの曲だって歌ってほしかった!!!!!!!風磨とMCでm-floが好きって話してたじゃねえか!!!!!!!!もうあなたのいるグループでこれが実現する確率めちゃくちゃ低いじゃん…………どうしたらいい???????
本当にパフォも楽曲もその他諸々の立ち振る舞いも素晴らしい気高くスマートなアイドルなんてもう替えが利かないよ!!!!あなたのいないグループを私はどんな気持ちで応援したらいい?????中島健人に出会わなければこんな最高なグループ知らずに済んだのに……本当にあんた最低だよ、罪すぎるよ
でもソロでやっていこうと決断した中島健人さんのことを嫌いになれないよ!!!!!!そういう強かさも含めていいなって思ってしまう自分がいるよ!!!!!!!もっと真っ直ぐ応援したいのに応援できない!!!!!!!グループにいてほしい!!!!!!苦しい
だって、もともと根っからの陽キャとは言えなさそうな男の子がかつて海馬瀬人に向けていた変身願望をアイドルに向けた瞬間、こんなにも彼が煌めき出すとは思わないじゃない!!!こんなにもアイドルとして完璧な振る舞いを繰り出し続けてて、こんなにおもしれー男(性アイドル)いないよ……しかも今日まで「自分はこういう人物なんだ」と思い込み続けるこの強烈な変身願望のようなもの、そしてその結果に満足せず日々「自分はこういう人物なんだ」という己の目標像を修正しては緻密に、時々無意識的に自らを高め続けるストイックさを持ちながら人生の半分を過ごしてきているんだよ?????これをバケモンと呼ばずして何と呼ぶ?こんな伸び代しかないモンスターアイドル応援して得しかないだろ!!!!!!当初は完璧アイドルでないといけないと思い詰めていた中島健人さんがある時からパブイメと実際の正確にギャップがあった方が良いと気がついて素に近い気負わない部分を見せてくるようになったときは本当に震えたよ。マジでこういう人が報われてくれよ世界
ただ、こうやって今まで生きてる人間のほんの断片だけ見て勝手にツギハギしてこんなナマモノ二次創作とも言える醜く気持ち悪い解釈をぶつけて過ごしてきたけど、今は中島健人さんに対して少し疑念を抱いているよ
今の中島健人はどんな仕事をしても「アイドル」を主軸にした評価を受けがちだと思う。なんか見てる感じそこまで今後はアイドルに主軸を置きそうではない中、本当に「アイドルにしては〜」という枕詞抜きで本当に彼が評価される日が来るのか怖いよ。推しを信じられないなんてやっぱオタクとしてはダメかもしれねえ
例えば、映像系の俳優業で名を上げたいする。俳優として売れたいなら強みを持たなければならない。自分が持っている潜在的な視聴率であったり、演技力であったり、その他特定の役に対するスペシャリティだったり。でも今持っている強みは概ね「アイドルであり固定客がいること」であって、グループ卒業により一定数ファンが離脱することを考えると昨今の映像業界でサバイブしていくってなかなか難しいなと思っている。ブレークスルーしていくためには出世作が必要だろう。でも比較的手近な日本のドラマ界隈は脚本が粗雑だったり演出がいまひとつだったりすることはよくあるし、そうした作品を引き続けていたらずっと燻ってしまう。逆にそのリスクを負わないように有名な脚本家や演出家の下で芝居をしたいと願うなら結局何らかの強みを持っていなければキャスティングに漕ぎ着けるのは厳しいんだろうなと感じている。あとはひたすらにオーディションを受けまくるしかないだろうが、本当に実力だけで戦っていつ結果が出るのかあまりにも未知数すぎるし正直、最悪の場合どうしようもなくなって深海魚状態になった推しを見続けられる心の強さが自分にはない。そうならないと信じたいけど。
でもグループから独り立ちしてやっていこうという決意があるなら、そこにはこんなしょうもないオタクより酸いも甘いも芸能界を知っている中島健人さん本人が描いているちゃんとしたプランがあるだろうし、そうしたものがなくても背水の陣で新しい道に進んで行きたいということなんだろうなと思う。やっぱ今まで見てきたその力で道を切り開いていくところは目を離せない。
いろいろ言って不安になりながらもどうにか前向きになろうとしてきたけどどう足掻いてもSexyZoneから中島健人が居なくなるの惜しいよ!!!!!!!!!まだデュエルディスク柄のうちわ作ってねえだろ私が!!どんなに細かくて面倒でも「強靭!無敵!!最強!!!」って蛍光シートくり抜いて文字作りたかった。
ただ、アイドルがいちばん輝くときは卒業を発表したあとって言うだろ???????もうこれを楽しみにするしかないなんてあんまりだ!!!!!!!!!!でもめちゃくちゃ期待している自分がいる!!!!!!!!!!頼む!!!!!!!!!SexyZoneの中島健人として最後に最高の輝きを見せてくれ ケンティーってやっぱすごかったね、完璧で究極のアイドルだねって皆に言われてほしい!!!!!!!!!!!正直これからどんな風に磨きがかかるかすげえワクワクしてるよ!!!!!!!!!
AI2つ仕事で書いて一つはプロダクションにいれたエンジニアだけど、今の精度でいったい何をどうしたら2年で「そのへんで募集かければ来る程度のエンジニアは必要なくなる精度になる」になるのかわからない
生成AIはあくまでそれらしいものを生成することであって世間がよく誤解するような(そして提供する企業の広報があえてそうしてるような)強いAIではない
現状の生成AIでのプログラミングが仕事で使えないのはどんな問題を解決しようとしているのか理解する力が弱いAIにはそもそも無いせいであって、だからそれっぽいテンプレートプログラムしか出てこない
よって性欲は罪であり罰であり悪なんだわ
厳格なキリスト教か?だのなんだのうっせーわ
必要悪ってだけで悪は悪じゃねーか
男は生まれながらに悪となりやすい宿命を背負った存在でそれを自覚して弁えて生きろってことなんだよ
動物としての自然な欲求を否定するな???それレイプさせろってのとどう違うんだ????
車は危険だけど便利で必要だから使われてるだろ?でも車なんてない方がいいんだよ。
もし車以上に安全で優秀な輸送手段があったらみんな乗り換えるよ
性欲も同じだよ
本質の話をしてやると性欲が達成したいのは「遺伝子の存続」なんだわ
性欲に頼らなくても遺伝子の存続ができる技術的ブレークスルーが起きたら性欲なんていらないんだよ
でもそんなのまだないから教育でなんとか性欲の不具合(仕様バグ)を後付けでなんとかしてんだよ
でも後付けでなんとかしたって潜在的には仕様がダメなんだからダメなんだわ
ダメなりになんとかやらなきゃねって話なんだわ
吸ってる間はこれがないとどうにもならんって思う
性欲に支配されし者たちはこれと同じ
賢者モードを思い出せ
性欲なくていいなってよ
銭稼ぎに使ってる奴や、絵師から権威を剝ぎ取ってザマァしたいだけのワナビにすらなれなかったカスや、嫌がらせ目的で使う悪意層以外で、純粋にイラストAIを素晴らしいものとして見ている層ってイラスト好きよりもテクノロジー好きの方が多いように見えるんだよな。
究極、イラスト文化がどうなろうが技術の進歩を目の当たりにできるならそっちの方がハッピーって感じの人達。
とくに、はてブなんかでイラストAIをやたら持ち上げている層ってそういう人が多そうに感じる。
AI・手書き問わず創作するでもないイラスト見るのが好きなだけの身からすると、正直、現在のレベルのイラストAIに有能な絵師やその将来の芽を害してまで持ち上げるほどの価値は感じられないんだよなぁ。
普通に絵師に気持ちよく絵を描いてもらって、それを眺められた方がありがたくね? って俺個人としては思う。
中には、自分の性癖に刺さるイラストを大量生産できるAIを心から愛しているって人もいるだろうけど、そういう層は数でいえば少数だろうし。
まあ、もう3~4段階、技術的なブレークスルーが起きて、今より遥かに優れたイラスト生成ができるようになったら、たぶん俺も手の平返しで称賛すると思うし、べつにイラストAIはどうあるべきかとか、何が正しいとかの話ではないけれど。
でも感情として、今のイラストAI関係の騒動でその手の技術信奉者が訳知り顔で語ってるの見ると、イラストに対して興味もないなら横から界隈をかき回さないでくれとは思っちゃうわ。
逆に、テクノロジー好きからしたらイラスト界隈ごときが技術の進歩に水を差すなとか思ってるのかもしれんけど。
なにかはしらねど、酒をのみすぎてしまった。猛省をソックスって感じか。ほんとうにダメだ。おれって駄目だ。はやくアレとどかないかな?諸悪の根源は、届かないことだよね。届けば、なんとかなるかもしれない。ブレークスルーになるかもしれない。酒やめろ!!!アルコールはクソ。。。アレンカーの本を2周してからじゃないと酒のんじゃダメってきめたら?
今までに何度もやめたいと思っていたけど、やめられない自分が嫌い。この本を試しにと思って読んでみると、本当に不思議ですが、本の半ばから飲む気すら無くなり、絶対に飲みたくなっていた週末も飲まずに過ごした。アルコールから開放されたことがとても嬉しい。そんな境地に至りたい。
皮膚が弱く、ときどきたちの悪い炎症を起こしてかゆくてしかたなくなる。発症してから二週間ぐらい、我慢しつつも我慢できずに赤くなったところをかきむしる、というのを繰り返し、最後の方は患部が子どもの手のひら大にタラコを浴びたような惨状になってしかたなく医者に行って、ステロイドを処方してもらう。治ることは治るのだが、痕はどうしても残ってしまい、体のあちこちにそういうシミがある。
かゆい、治りにくい、というイメージが先行しているような気がするが、俺の場合もう、そういう不快というレベルを超えてしまい、病院に行かないまま自然な回復を神仏に祈っていた結果どんどん悪化させ、一番ひどいときはボロボロになった肌がまるで風化した靴下をはいたような惨状になって、しかたなく医者に行ってステロイドと抗真菌薬を処方してもらう。ちなみに、水虫に対してステロイドの使用は、薬効で皮膚が薄くなるので要注意だと医者が言っていた。それでもトータル的に使った方がいい、という判断だったらしい。
しつこい炎症や水虫を食らって思うのだけど、現代だから「困った」で済むが、100年ぐらい前だったらシャレにならない大ごとなのではないか。
特に水虫は、あのままだとたぶん、崩れた肌から何かしらの感染症を起こしていた可能性が高く、リアルに死んでいるのではないかと思う。炎症も、少なくとも生涯付き合うことになっただろう。えらいことだ。医学で言うと抗生物質の発明はマジすごいブレークスルーだったとたまに聞くが、俺的には人工的な副腎皮質ホルモンの抽出もマジ感謝というか、皮膚病怖い、という感じだ。
あと、身体的な苦痛とは少し違うが、水虫が足に出てしばらくして、ふと手の指先を見たら同じような水疱が爪のわきあたりの肌にできているのを見たときは本気で戦慄した。あらためて指を一本一本見ていったら、親指を除いた四本に症状が出ていて血の気が引いたのを覚えている。
こうなると、もう他の人間にもうつす可能性が出てくるし、なんというか、もはや「人類、よく生き残ったな」ぐらいに思ったが、というか普通に死んでいたのか、そういうやつは。
西洋の薬が登場して、肌質がそんなに強くないやつでも生きていける時代になったのか。わからん。茶殻をどうこうする、的な民間療法があったとは聞くけれど…
https://d.potato4d.me/entry/20220405-nodejs/
が話題になっているけど、本来人類に必要なのはクロスプラットフォームな実行環境であってNodeじゃない。
TSが流行ったのはJSがクソだから。BabelしなきゃいけないのもJSにトランスパイルしなきゃいけないからであって、必要なのはJVMやCLRのような言語実行環境。
Reactが流行ったのはshadow domだけど、必要なのはDOMじゃなくてちゃんとした「アプリ」開発用のイベントモデルとレイアウトマネージャ含むGUI環境。
フロント界隈の流行廃りって本質的な改善ってよりもほかの良い技術をいかにブラウザ/Electron等JSエンジンという限られた環境に持ち込んで幸せになるかがメインに見えるので地獄に見える。
「アプリ」書くのになんでドキュメント記述用のHTMLに今ものっかってんだよと。
MavenやらGemsができて依存管理楽になったとか、RailsがでたときのようなCoC良いねとか開発の考え方を変えるフレームワーク、 rspec/Cucumberがでてテスト最高とか、c10kも怖くない非同期I/Oとか、好きな言語が使えるJVM/CLRそもサーバーならrustでもgoでも好きなものが動くとかとか本来の開発を楽にするという意味のブレークスルーってあんまりみられない気がしている。なんでフロント界隈の新技術ってあんまりわくわくしない。
逆にちゃんとしたクロスプラットフォーム実行環境がブラウザしかないということなんだけど、ブラウザなかなか進化しないし RIA は Apple 様が切り捨てるからなぁ。
ということですべてはブラウザが悪い。JavaScript 以外がちゃんと動くクロスプラットフォームのGUI環境が必要。でもプリインでモバイルでも動いてOSから独立して協調して作られていて、Webという既存の大量の資源にアクセスしやすいものは現時点で実質ブラウザ一択。つまりWASM に期待。次にHTMLであるべき文書はともかくSPAなんてもう「アプリ」なんだからHTML手書き文化もうやめてネイティブアプリ並みの GUI 作成環境も復権しよう。
するとクライアントでも好きな言語が使える。そして同じ言語がいいとサーバサイドで Node.js を使う必要もなくなりへっぽこプログラマが Node のイベントモデルを理解せずに使うこともなくなる。
そしてそれらができたときに Node というか JS/HTML の呪いから解放され人類に平和が訪れるのだ。君はその後も Node.js を使っても良いし使わなくてもいい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}