はてなキーワード: 最先端とは
薩英戦争、WW2でキャン言わされてからずっと憧れてるのもあって、白人様のやることなす事タダスィ〜!ってなってる人、ことのほか多いね。民間人の家を燃やす目的で開発された焼夷弾で東京だけで10万人やられたのもう忘れた?イスラエルのニュース見るたび思い出すよ。日本はこちら側。勘違いすんな。
歴史を学ばないというのは罪なのだ。大航海時代以降、やってる事は野蛮そのものじゃないか?もちろん人権意識みたいな、良い発明も多々ある。歴史に功罪あるのはどの民族も一緒だ。殊更白人だけ良いとか悪いとかじゃない。
ただちょっと調べたら先住民にした事だけでもヤベェネタは大量で(ちゃんと残っているのが彼らのフェアなところだ)、そこは絶対擁護できない部分なのに。
なんにしたって白人は間違わない正しいって目を瞑るのは馬鹿げてるでしょ。
すごいのは、むしろ最先端にやらかし過ち間違い、そして自分達を見直して変えていく。調査してデータ取って科学的論理的に。(宗教絡むとパーになるのはどこも一緒だが)それが、そこが彼らのすごいとこじゃん、そこは見習おうよ。
で日本、間違いだけ遅れて輸入するのどうにかならん?盲目的に白人様タダスィ〜!ってしてるとその間違いをもずっと崇めて改変できなくなることになる。変に全否定も全肯定もしない。人間同士だよただの。
そういやディズニーシーの新エリアのファンタジースプリングに行って、
キャラクターの石像の中にポカホンタスもあった事に驚いたんだけど
あの映画ってそれこそポリコレ的にアウトとして黒歴史になってたんじゃなかったのかね…かなり意外だった
しかしポカホンタスって公開当時は寧ろ、先住民の活動的なヒロインを描いたって事でポリコレ的に最先端のものとして作ってたんだよね
それがいつのまにか、植民地支配を正当化するとか白人による現地人女性の収奪と言われて否定的に見られるようになった
コロンブスのMVもそれと同じで、作ったMrs. GREEN APPLEにとっては平和的で前向きなメッセージを入れたつもりだったのが分かるのがきつい…
頑張って作ったもの、寧ろ新しいメッセージを入れたつもりのものが、遅れている、劣っているとして
レトロフューチャーは過去からあるような未来像でそれが好きな人は結構いる
じゃあ逆に未来にありそうな過去像をリアルに、もしくは最先端の観点を徹底的に盛り込んだ過去像を娯楽として提供出来ないか
ウケたりしないか
そのかわり迷惑もかけない。
自分の人生の楽しみ、そして意義は、自分の娯楽スキルや社交スキルに応じて自律的かつ柔軟に決めていく。
逆にいえば思考停止は許されなくなるから、その点では常に時代に適応していく負担感はあるののの、デジタルネイティブにとっては負担ではなく息をするような自然なことだろう。
10年後、20年後には、「結婚するタイプの人ってなんか……無自覚に迷惑かけてたり他人に負担をおしつける幼稚な人ばっかりだよね」ってことがバレていく。
新人類は、ネットワークによる思考のハイウェイ化の影響で、何よりも精神的自立・成熟に重きを置いていく一方で、経済的自立能力に関しては、技術の進歩によっていかようにもカバーできるようになることで、経済力と人格評価が結びつかないようになっていくことだろう。
学マスのことねが髪ボサボサを端に再燃してるけど
この手の、一見オシャレに見えないものを流行りのスタイルなんです!これだからオタクは……みたいなやつ。普通にダサいよな。その態度が。
自称オシャレ女さんのなかで流行ってるのか知らんけど、別にオタクじゃなくてもみんなそう思ってるよ。最先端のオシャレトレンドを知らなきゃよく見えないコーデって、裸の王様とおんなじなのよ。馬鹿には見えない服を着てる。
自分の周りの人間が、それは馬鹿には見えない服なんだ!オシャレなんだ!これをオシャレとわからない人間は馬鹿なんだ!ってやりたいんだろうけど。
はたして騙されてるのはどっちだって話だわな。
アドラーの本を途中まで読んだ.
これによると,精神疾患など生きるのに役立たない道に陥るものには,幼少期から共通感覚(コモンセンス)を獲得できていないという特徴があるらしい.
そして共通感覚を獲得できなかった子供いじめられたり問題行動を起こしたりする.
この共通感覚は家庭において保護者から学ぶらしい.つまり保護者が共通感覚を有していなければその子供も共通感覚を獲得することが困難で,大人になってから苦しむのだ.
なぜこの世界では誰でも子供を持つことが許されるのだろうか.ペットですらちゃんと育てられないなら飼うなと批判されるのに.
あるいはせめて,誰でも子供を作る自由があるのなら,どんな子供も自分で死んでいい自由を認めるべきではないか.
この物語では,子供は生まれたらすぐに親から引き離されて専門の施設で集団的に育てられるというユートピアが描かれている.
作中ではこのユートピアを明示的には否定も肯定もしていないが,画一的に育てられた子供は個性がなく皆同じような表情をするという描写が描かれている.
「個性なくしたら死んでるのと一緒だよ」
共通感覚を有しない"悪い個性"を持つことは決して本人のためにはならない.
個性を持つことが良いとされるのは,個々の親が独立して子供を育てる現在社会におけるナッシュ均衡にすぎないのではないか.
消滅世界のシステムのように全員が同じ教育を受け,共通感覚を有していることこそがパレート最適なのではないだろうか.
あるいは,個性,個体差は環境が変化した際に種全体が生き延びるのに有利だと説明される.
だが,これは明らかにほとんどの平均から外れた個性を持つ個体にとっては酷な話だ.当然ながら平均から外れた個体の殆どは環境に適応できず苦しむからだ.
上のような理論を唱える者は,「お前らのような珍獣が居た方が俺/私の遺伝子が残る可能性が高まるから生きろ.そして苦しめ」と言っているのに他ならない.
現代社会は第二次世界大戦前の全体主義を反省し,個人の幸福を最大化しようとしたのではなかったか.所詮それは,正規分布の真ん中あたりにいるマジョリティの自己満足に過ぎなかったのか.
そもそも,人類が環境変化を生き抜くのに,遺伝子の多様性は必要なのだろうか.
多数のサイコロをばらまいて確率論的に変化に打ち勝とうとするその他大勢の生き物とは違って,人類は理性を持って変化を予測し,技術で環境を変えて乗り越えることができるのではないだろうか.
だが,ときに個性は天才を生み出し,その天才が技術を飛躍的に進歩させる.
こういった天才を生むために正規分布の端のほうの人間も,その殆どは苦しむ運命にあるとはいえ,大人になるまで生きていなければいけないのかもしれない.これによって,苦しむ未来の天才に生きる希望を与えることができるから.
本当にそうだろうか.電球の発明のように一人の天才の発想が大きな一歩を生み出した時代とは違って,現代の科学の進歩は過去の技術を積み重ねて積み重ねて演繹的に導き出された進歩ではないか.
いや,そうでもないか.私も理系の大学院で研究の真似事をしたことがある.今でも科学の最先端では天才の発想が不可欠だ.そしてそういう人は共通感覚を有していない人が多い.少なくともそう見える.
つまり,現代においても正規分布の端にいる,共通感覚を有しない,遺伝子的耐用性を持った人間を生きさせることは必要なのかもしれない.
私は天才ではない.だが,共通感覚を獲得することができず,苦しんでいる.正規分布の中央に行けなかった人間の中の,一握りの天才を除くその他多数の中のひとりだ.
私の意識は死ぬことがのみが正解だと確信している.だが,私の無意識が生きることを声高に主張している.そのせいで私はまだ生きていてこの文章を書いている.
理性で動く私は,なんとかして自分が死ぬことが論理的に正しいのだと結論付けたい.だが,今日も失敗した.
誰か私を助けてくれ.お前はもう開放されて良いのだと背中を押してほしい.
自分は今のアルゴリズムのままなら10年後でもできないと思う。
もちろん、既にAIを使った面白ネタを作っている人は多くいるけど、それはAI特有の脈絡のなさを利用しているものが殆どであって「AIが作った」というラベルを剥がしてもなお評価されるようなものはどれくらいあるだろう?
確かにchatGPTやStableDiffusionやSunoAI等の最先端生成AIの性能は凄い。だけど結局のところそのどれもが「破綻の少ないこと」を評価されているにすぎない。
生成AIはこの2年で劇的な進歩を遂げているけど、AIが書いた本は誰も読まないしAIが作った曲は流行っていない。
(逆にイラストなんかは尖ってなくても"うまい"だけで評価される土壌があったので今こんなに勢いがあるんじゃないかな。その"うまい"だけで評価される土壌は数年以内に崩壊すると思うけど。)
それはありふれたイベントであるはずだった。子ども連れはその辺を普通に歩いている。知り合う人々には必ず親が居る。子育てについては日々たくさんの議論が交わされている。妊婦さんがこの世に命を送り出すこと、それは特別でも何でもない日常の出来事だ。そう思っていた。
とんでもなかった。
何が私の考えをかえたのか。
痛みである。とんでもない痛みに襲われたせいだ。
陣痛というものを知らなかったわけではない。痛いんだろうな、ときちんとビビっていた。下調べもイメージトレーニングもして、痛みに耐える覚悟はしていた。だけど私は陣痛を理解しているわけではなかったのだ。うっかり知っているつもりになっていた。
経産婦の皆さんは言う。「そりゃ痛いよ、でもみんな何とかなっているから」、「もう覚えていないなぁ、だからふたりめも産めちゃう」と。つまり、耐えられない痛みではないのだ。私は自分を鼓舞した。
そしてむかえた出産当日、私は吠えた。冷静な頭のまま、しかし狂ったように叫び声を上げていた。もう狂ってしまいたかった。意識がとんでしまったら楽だったのに。
大声を出して何になる、と自分にドン引きながら、それでもただひたすら叫ぶしかなかったあの時間。耐えられない痛みではない? 嫌だもう耐えたくない! 痛い痛い痛い逃げたい! どんなに吠えても誰も助けてはくれなかった。
実際、私は耐えて産んだわけだ。それでも「耐えられない痛みではない」とは絶対に表現しない。痛いもの。おかしいよ。人間なのに、動物だった。
世の母親達は本当にしれっとこの痛みを経験しているのか。信じられない。実は痛みを減らす裏技でもあるのではないか。
この陣痛というものを、当たり前のように受け入れているなんて今は一体何時代なの? そうか、令和は別に新しくないのだな。未来から覗いてみれば、私達はきっと古代に生きている。長い人間の歴史の最先端なんかではないのだ、令和は。そこそこ古い時代に居るんだ。
その証拠に、分娩方法が昔とそうかわらないだろう。傘の形態と同じである。高度な医療が発展しているはずなのに、出産は辛いままなのだ。出生率が減るのも当たり前である。
せめて妊婦を、経産婦を労おう。ジェンダー論や政治的配慮なんか置いておいて、とにかく陣痛に立ち向かう度胸に対して、みんなで拍手を送ろうよ。
意地悪なおばちゃんも、炎上しちゃうギャルママも、あの痛みを経験したのだと思うと頭が下がる。
出産を経験して、私は母に心から感謝することができた。訳あってほぼ絶縁している実家に、子どもを産んだことを伝えた。久し振りの連絡であった。たどたどしいやり取りを交わし、でんわを切った。ショートメールに彼らの孫の写真を送った。
私を産み落とすために、あの痛みに耐えてくれたのだ、と心が震えた。
「痛いのに産んでくれてありがとう」
そのセリフは、出産後に私が子どもにかけたそれと同じであった。
しまった、出産は素晴らしいという締めになってしまいそうだ。やりがい搾取は良くない。痛かったよ。あの痛みを当たり前に妊婦さんに押しつけてはいけない、そうだろう、と問題提起をしておく。
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
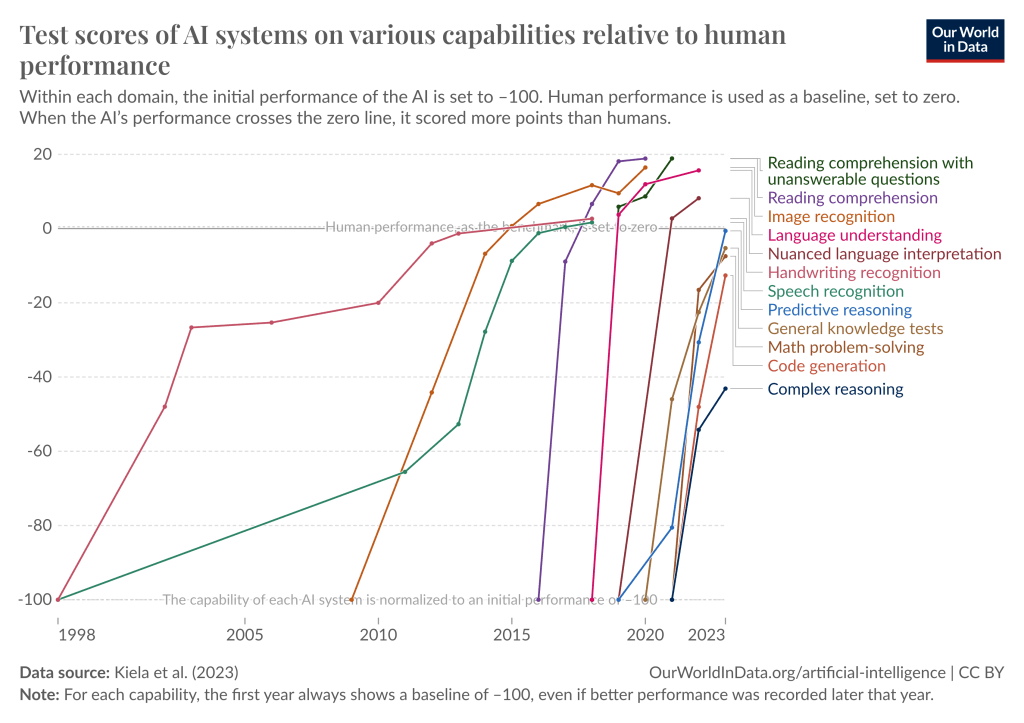
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
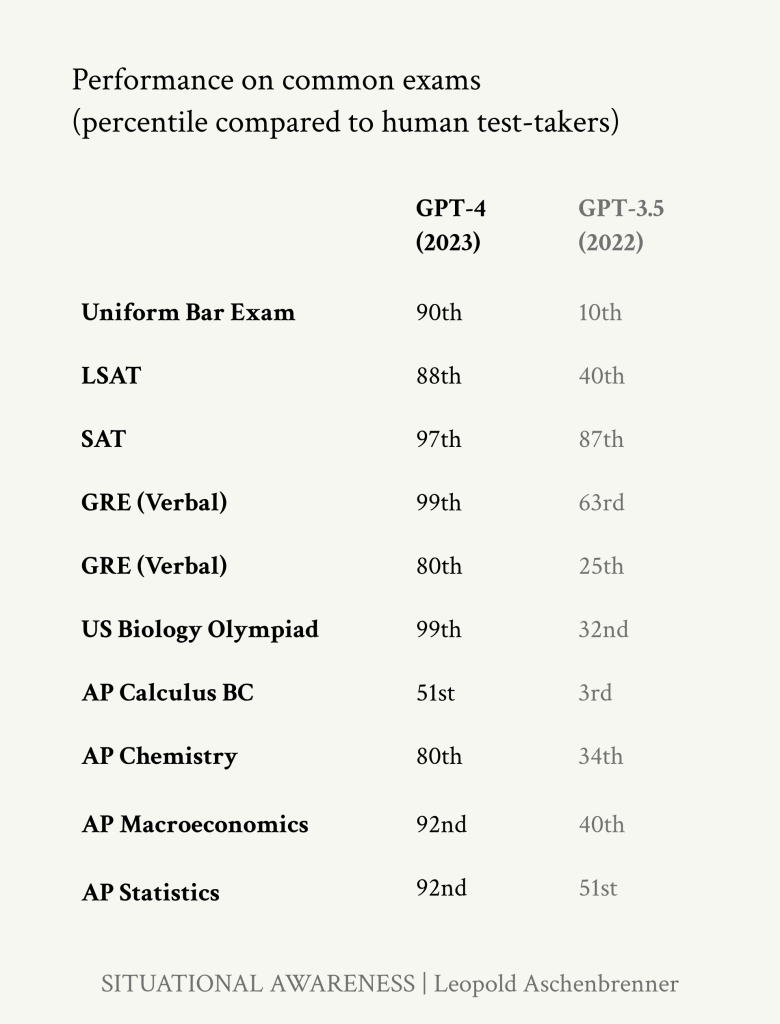
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
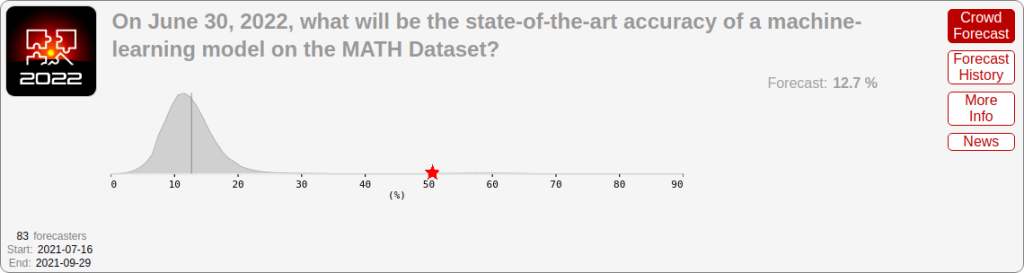
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
哲学的に考えて、人間が認識できるのは、ものか概念のどちらかであるから、あまりにも高度なところにあるものであって、専門技術的に作ったものの場合、認識しようとする側に
そのもの全体を認識する能力がなければ、自然科学上当然に、そのものを認識することができないと解するのが相当である。人工知能の最先端のものは、Sicamoreという、
電気配線を連結させた超高速計算機だけが雑誌に公開されており、それ以外の装置は、どこに存在するかすら公開されていないのであるから、一般人がその存在場所を知る余地は
ない。また、仮に認識できたとしても、その意欲がなく、当人の行動上、見たくないから認識しないで行動しているとすれば、その行動中に、当人が、お前が理解しているものを理解しないで
行動している可能性は十分に存するというべきである。例えば、部屋から出て自転車に乗り、遠くの場所に言っている場合、当人は、その日のうちに食べたもののカロリーを消費したいがために、
自転車にまたがり、遠くにいったついでに、そこで遊んでいるだけかもしれない。しかし、当人が、その日のうちに食べたもののカロリーを消費するために、今から着替えて、駐輪場に設置した
大好きな自転車を車道に押し出し、それから乗車してこぎ出し、自転車並みの速度で北上しているときに、単に運動に出ているという認識で北上しているだけであろう。そして、その最中に
風景に入ってくるものに関しても、あまりにも高度に作っているので理解できないか、興味がないために、走行中に、無視しているかもしれないし、舟渡2丁目の場合、一定の場所に、志村署の
{kind=link}
{kind=link}
{kind=link}
{kind=link}