はてなキーワード: ラグランジュとは
自由意志を表現する n 次元ベクトル空間 V を考える。この空間において、意思決定 d は以下のように表現される:
d = Σ(i=1 to n) αi ei
ここで、
定理:任意の n 次元ベクトル空間 V に対して、無限に多くの正規直交基底が存在する。
証明:グラム・シュミットの直交化法を用いて、任意の n 個の線形独立なベクトルから正規直交基底を構成できる。
この定理は、意思決定空間において無限の表現可能性が存在することを示唆する。
自由意志の非決定論的側面を表現するため、量子力学的概念を導入する。
|ψ⟩ = Σ(i=1 to n) ci |ei⟩
ここで、
測定過程(意思決定の実現)は、波動関数の崩壊として解釈される。
意思決定過程を力学系として捉え、2n 次元位相空間 Γ を導入する:
Γ = {(q1, ..., qn, p1, ..., pn) | qi, pi ∈ ℝ}
決定論的カオスの概念を導入し、初期条件に対する敏感な依存性を自由意志の表現として解釈する。
λ = lim(t→∞) (1/t) ln(|δZ(t)| / |δZ0|)
ここで、δZ(t) は位相空間における軌道の微小な摂動を表す。
L(x1, ..., xn, λ1, ..., λm) = f(x1, ..., xn) - Σ(j=1 to m) λj gj(x1, ..., xn)
ここで、
消費者集合:N = {1, 2, ..., n}
消費ベクトル:各消費者 i の消費ベクトルを X_i ∈ X_i ⊆ ℝ^(k_i) とする。
個人効用は自分の消費 X_i と政府支出の使用用途 G に依存する。
税収:T ∈ ℝ_+
国債発行額:B ∈ ℝ_+
政府支出の配分:G = (G_1, G_2, ..., G_m) ∈ G ⊆ ℝ_+^m
政策空間:P = { (T, B, G) ∈ ℝ_+ × ℝ_+ × G }
予算制約:
Σ_(j=1)^m G_j = T + B
可処分所得:消費者 i の可処分所得 Y_i は、所得税 t_i によって決まる。
Y_i = Y_i^0 - t_i
T = Σ_(i=1)^n t_i
p_i · X_i ≤ Y_i
目的:政府は社会的厚生 W を最大化するために、以下の政策変数を決定する。
国債発行額 B
政府支出の配分 G = (G_1, G_2, ..., G_m)
制約:
消費者の最適化:政府の政策 (t_i, G) を所与として、各消費者 i は効用を最大化する。
最大化 U_i(X_i, G)
X_i ∈ X_i
制約条件:p_i · X_i ≤ Y_i
結果:各消費者の最適な消費選択 X_i*(G) が決定される。
W(U_1, U_2, ..., U_n) は個々の効用を社会的厚生に集約する。
合成関数:
W(U_1(X_1*(G)), ..., U_n(X_n*(G)))
最大化 W(U_1(X_1*(G)), ..., U_n(X_n*(G)))
{ t_i }, B, G
制約条件:
Σ_(j=1)^m G_j = Σ_(i=1)^n t_i + B
t_i ≥ 0 ∀i, B ≥ 0, G_j ≥ 0 ∀j
X_i*(G) = arg max { U_i(X_i, G) | p_i · X_i ≤ Y_i } ∀i
X_i ∈ X_i
政府の役割:公共財の配分 G と税制 { t_i } を決定する。
消費者の反応:消費者は政府の決定を受けて、最適な消費 X_i*(G) を選択する。
(b) 力学系の特徴
スタックルベルクゲーム:政府(リーダー)と消費者(フォロワー)の間の戦略的相互作用。
最適反応関数:消費者の最適な消費行動は政府の政策に依存する。
(c) 一階条件の導出
L = W(U_1(X_1*), ..., U_n(X_n*)) - λ ( Σ_(j=1)^m G_j - Σ_(i=1)^n t_i - B ) - Σ_(i=1)^n μ_i (p_i · X_i* - Y_i)
微分:政策変数 t_i, B, G_j に関する一階条件を計算する。
チェーンルール:消費者の最適反応 X_i* が G に依存するため、微分時に考慮する。
(a) 公共財の種類
公共財ベクトル:G = (G_1, G_2, ..., G_m)
例えば、教育 G_edu、医療 G_health、インフラ G_infra など。
U_i(X_i, G) = U_i(X_i, G_1, G_2, ..., G_m)
各公共財 G_j が個人効用にどのように影響するかをモデル化。
将来への影響:国債発行は将来の税負担に影響するため、長期的な視点が必要。
制約:債務の持続可能性に関する制約をモデルに組み込むことも可能。
(c) 公共財の最適配分
優先順位の決定:社会的厚生を最大化するための公共財への投資配分。
政府の決定問題:消費者の反応を予測しつつ、最適な { t_i }, B, G を決定。
情報の非対称性:消費者の選好や行動に関する情報を完全に知っていると仮定。
消費者の行動:政府の政策を所与として、効用最大化問題を解く。
結果のフィードバック:消費者の選択が社会的厚生に影響し、それが政府の次の政策決定に反映される可能性。
(a) モデルの意義
包括的な政策分析:政府の税制、国債発行、公共財の使用用途を統合的にモデル化。
最適な税制と支出配分:社会的厚生を最大化するための政策設計の指針。
一般性の確保:特定の経済状況やパラメータに依存しないモデル。
政府は、税制 { t_i }、国債発行額 B、そして公共財の配分 G を戦略的に決定することで、消費者の効用 U_i を最大化し、社会的厚生 W を高めることができる。
このモデルでは、政府の政策決定と消費者の消費行動という2つのステップの力学系を考慮し、公共財の使用用途も組み込んでいる。
DSGEモデルは、経済全体の動学的な挙動を分析するために用いられるモデルで、金利、為替レート、インフレの相互作用を捉えることができる。
4. 為替レートの動学:
DSGEモデルは通常、線形化して解く。ここでは、状態空間表現を用いて、リカッチ方程式を解くことで均衡を求める。
1. 線形化:
経済を I 個の財・サービス、J 人の消費者、F 社の企業から成るとする。
各消費者 j ∈ {1, ..., J} の問題は以下のように定式化される:
max Uⱼ(xⱼ)
s.t. p · xⱼ ≤ wⱼ + Σ(f=1 to F) θⱼᶠπᶠ
ここで、
Uⱼ: 消費者 j の効用関数(強い単調性、強い凸性を仮定)
xⱼ = (x₁ⱼ, ..., xᵢⱼ): 消費ベクトル
wⱼ: 初期賦存
πᶠ: 企業 f の利潤
一階条件(Kuhn-Tucker条件):
∂Uⱼ/∂xᵢⱼ ≤ λⱼpᵢ, xᵢⱼ ≥ 0, xᵢⱼ(∂Uⱼ/∂xᵢⱼ - λⱼpᵢ) = 0 ∀i ∈ I
λⱼ(wⱼ + Σ(f=1 to F) θⱼᶠπᶠ - p · xⱼ) = 0, λⱼ ≥ 0
ここで、λⱼ はラグランジュ乗数。
max πᶠ = p · yᶠ
s.t. yᶠ ∈ Yᶠ
ここで、
yᶠ = (y₁ᶠ, ..., yᵢᶠ): 生産ベクトル(正は産出、負は投入)
一階条件(利潤最大化条件):
p · y ≤ p · yᶠ ∀y ∈ Yᶠ
Σ(j=1 to J) xᵢⱼ = Σ(f=1 to F) yᵢᶠ + Σ(j=1 to J) wᵢⱼ ∀i ∈ I
ここで、wᵢⱼ は消費者 j の財 i の初期賦存量。
p · (Σ(j=1 to J) xⱼ - Σ(f=1 to F) yᶠ - Σ(j=1 to J) wⱼ) = 0
1. 価格単体を定義:Δ = {p ∈ ℝ₊ᴵ | Σ(i=1 to I) pᵢ = 1}
4. 予算制約とワルラス法則より、p · z(p) = 0 ∀p ∈ Δ を示す
5. 境界条件:pᵢ → 0 ⇒ zᵢ(p) → +∞ を証明
6. Kakutani の不動点定理を適用し、z(p*) = 0 となる p* ∈ Δ の存在を示す
社会的厚生関数 W = W(U₁(x₁), ..., Uⱼ(xⱼ)) を最大化する問題を考える:
max W(U₁(x₁), ..., Uⱼ(xⱼ))
s.t. Σ(j=1 to J) xⱼ = Σ(f=1 to F) yᶠ + Σ(j=1 to J) wⱼ
yᶠ ∈ Yᶠ ∀f ∈ F
一階条件:
∂W/∂Uⱼ · ∂Uⱼ/∂xᵢⱼ = μpᵢ ∀i ∈ I, ∀j ∈ J
p = ∇yᶠπᶠ(yᶠ) ∀f ∈ F
ここで、μ はラグランジュ乗数、∇yᶠπᶠ(yᶠ) は利潤関数の勾配ベクトル。
これらの条件は、消費の効率性、生産の効率性、そして消費と生産の効率性を同時に表現している。
究極理論がわからない現状、もし仮に「我々の世界が不安定な真空にいる」ことを仮定すれば
相応のエネルギーを加えて真の真空に落とす(相転移させる)ことで物理法則が変更されるという
人為的ネオエクスデス「うちゅうの ほうそくが みだれる!」 ができますね。
イメージ的には過冷却です。すでに相転移が起きているのに気がつかないで元の真空にとどまっています。ちょっと突くと一瞬で凍ります。
現に、新しい加速器が作られる度になんかスゲェ無理矢理な模型を作って「加速器のせいで世界が滅びる!」系の論文がarXivに投稿されたりします。意外と増田と同じことを考える人がいるんですね。ただしこれらの論文は一瞬で否定されます。なぜならば、加速器で作るビームなんかよりも中性子星ガンマ線バーストのほうがよほど強いからです。宇宙強い。人類の技術は弱い。驕るなよ人類。
前から不思議だったけど、これらの法則って経験から導き出されたものであって、その法則がどうやって存在してるかは不明なんだよな
以下、意味は取らなくて良いので流れと単語だけ拾ってください:
たとえばエネルギーの保存は時間方向の並進対称性、運動量保存則は空間方向の並進対称性から、角運動保存則は回転対称性から導き出されるといえるでしょう。
(相対論的には時間と空間は同時に取り扱うのですがちょっと難しくなるので簡易な書き方をしています)
時空の対称性が決まる → ラグランジアンが決まる → オイラーラグランジュの方程式(運動方程式)
ここまでよんだ?
なら次は、ランダウ・リフシッツ「力学」の最初の20ページくらい読んでください。
前提知識は微積分です。ここまで読めば上の文章はだいたい理解できるかと思います。
そして次にあなたはこう思うでしょう
「最小作用の原理っていったいなんなんだ? 世界はなぜこんな原理に従う?」
そう思ったなら次は量子力学です。JJサクライ「現代の量子力学」の経路積分のページまで読み進めましょう。
ここまでくれば霧が晴れるように見通せるようになるはずです。
物理理論とは何であるかが把握できるかと思います。ここから先はご自由に。
なお、JJサクライは物理科ではちょっと ’進んだ’ 内容とされています。普通は2冊目に読む本ですね。が、ハテナーにとってはむしろ読みやすい本かと思います。だってどうせ君ら情報系でしょ?なんかプログラムとか書ける人たちでしょ??なら、ブラケット表記の方が慣れていると思うんですよ。たぶん見ればわかるよ。
まず、三大ポイントという要件から考えると、最初に挙げられた「ラグランジュ=ポイント」は不適当です。
人名でもなくダブルハイフンを用いるほど複雑な名詞構造でもないので=を置く意味がわからない非常にユニークな表記がされていることを好意的に無視して、「ラグランジュ・ポイント」のことだとしてもNGです。
ラグランジュ・ポイントは、日本語では一般的にラグランジュ点と呼びます。
「ラグランジュ・ポイント」表記が一般的でない証拠として、固有名詞による単語のオーバーライドが挙げられます。
Google検索結果の2件目には、ラグランジュポイントというゲームのタイトルがヒットし、
3件目には、LAGRANGE POINTという法人名がヒットします。
中にはApple Inc.のようにそのモノを表すために最もよく使われる表記を社名として乗っ取ってしまうトンデモ企業もありますが、
一般的にはその言語圏で最も良く使われる表記とは少しズラした表記がブランドネームとして採用される傾向があります。
これが固有名詞による単語のオーバーライドです。これにより逆説的に「ラグランジュ・ポイント」表記が一般的ではないと分かります。
ただし、その単語が意味する一般的用法(この場合は学術用語)ではなく、ゲームやアニメ内の用語として類似観念を指して「ラグランジュ・ポイント」表記が使われ、その作品が人気を博した場合など、Google検索結果では「ポイント」表記の方が多く見られるケースも起こり得ます。限定的用法の成り代わりです。
増田の書いたものが「・ポイント」表記であれば、そちらの作品内用語として三大に挙げるレベルに認知されていると好意的に解釈することも可能でしたが、残念ながら増田の表記は「=ポイント」ですので、限定的用法の成り代わりを指すとは考えられません。また「=」表記による限定的用法が使われていた形跡も見当たりません。
仮に「"ラグランジュ・ポイント"」のことだとしても、Googleヒット数はわずか約 237,000 件です。
結果として、この1つ目の項目を挙げる設問として差し上げられる評価点は30点中の10点です。
「ヴァニシング=ポイント」の方に関しても同じような評価となり、10点です。
3つ目は挙げていないので0点です。
三大~と提起しておきながら2つしか挙げない手法は、テンプレのように認識している人もいますが守る必要はありません。
3つキッチリ挙げたとしても、2つだけ挙げたとしても、レス乞食のアンケート増田としての吸引力に大差はありません。
なぜなら、この手のクリックベイト力のすべてはタイトルに凝集されているからです。
本文によって読み手がよりツッコミをしやすい土壌を整える必要があります。
なので、4つ以上挙げるとなると冗長と感じられることが多くなるため慎重に判断すべきですが、3つ程度までであれば、読み手へより方向性を伝え、発想を促すメリットの方が大きくなります。
よって3つ目にも取り組む価値があり、30点分の配点がありましたが、あなたはふいにしました。
最後の10点分は、記事全体としての芸術力です。創意工夫の余地にあたる部分です。
簡潔であることも一種の美徳ですが、それはタイトルおよび本文が秀逸であった場合にのみ価値をもつ美徳です。
よってここも0点です。
模範として、より三大ポイントとして妥当な可能性のある列挙をするための考え方を一つ示します。
いきなり最強のものをぶつけるのです。
そこで、ポイントの前につく字数として2~4文字が多かろうと適当にあたりをつけて、
○○ポイント、○○○ポイント、○○○○ポイントを検索するのです。
URLで言うと、http://fuseji.net/○○ポイント
それぞれ多い順に一覧が出ますが、各最上位は、ワンポイント、スリーポイント、チェックポイントとなります。
面白みがなくて誰も反応しないかもしれませんが、最強なのであなたは優勝です。
仮に反応がついたとしても、すでに勝っているので読む必要もありません。
深夜の翳りに身を晒し、今やっと眼を覚ました。これは魂の夜ふかし、そう呼ぶべきでしょう。
さて、私は時折、American Mathematical Society(以下、AMS)の書籍を求める運命にある。特にStudent Mathematical Libraryというシリーズは、その薄っぺらい体裁ながら、研究の奥深さを体感できるとても理想的なものであり、よく手に取ることとなる。しかし、その紙一重の薄さの背後に隠された内容は、従って、大学院の学生にのみ耐えうるものとなっている。昔、あまりの熱意から何冊か買い求め、積読の山を築いたこともあるが。
その山に埋もれる中、一つの書を読み尽くしたことがある。それは、数理モデリングの書であった。数理モデリング、これは往々にして、ラグランジュの未定乗数法などのよく知られた方法論に頼る傾向がある。しかしながら、AMSの書籍はそのくだらない枠組みにとらわれず、多彩な事例を探求していた。とはいえ、フレンケル教授が言うように、数理モデリングと言っても、ついには「ペンキ塗りの数学」である。
私は数学の最前線を垣間見るようになり、調和解析と数論の奇跡的な交差、フェルマーの最終定理、ガロア群、保型関数など、その深遠さに驚嘆する日々である。最近は、経済学に数学を結びつけることに強い興味を抱いており、mean fieldのような奥深い謎が私を惹きつける。
学びたいことが山ほどあり、私の能力と時間には限りがある。何を学ぶべきか、と悩むのはやむを得ない。しかし、コスパを重視し過ぎると、ついにはペンキ塗りの典型に陥ってしまうだろう。複数の数学の領域を結びつけることは、即座に実用性が見えるものと、その応用が果たしてどこに行くのか見当もつかないものがある。伊藤清が指摘するように、「実用を考慮しなければ、数学で遊ぶことは限りない」。この観点から見れば、私が探求すべき分野は、確率論の領域にあるのは明らかだろう。確率微分方程式とゲーム理論の交わる地点は、実用性との調和によって成り立つ、その方向へと進む決意を固める。
hash: c94da2af8ee4dd6e6ead4da0676b2b97
後編
行列はVBAなんかじゃ無理っぽいし、なんかプログラミング言語を覚えようと決める。
とりあえず両方試そうということで、RのためにRとRstudioをインストール。
プログラミングはなんかを製作する目標がないと挫折すると聞いていたので。
深層学習というものが流行ってると聞いて、ちょっと触りを勉強したくなる。
この本は面白かったので、深層学習を目標にプログラミングを覚えよう!
後になって、これはとんでもない間違いだったことに気づく。深層学習と機械学習の違いも判らないまま、RよりPythonを先に触ることに。
教本にしたのはこちら。
「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」
途中まではまあなんとか。
微分って便利だな。行列計算できるの便利だなっていうところまでいったが、クラスという概念が理解できず、途中からハテナが浮かんで読み進められず。
うん、もうちょっと易しい本を探そうと思って手に取ったのが
「独学プログラマー Python言語の基本から仕事のやり方まで」
なんとか読了。自信をつける。
実は、いまだにコマンドプロンプトとパワーシェルとbashの違いが分かってない。
つづいてPyQに2か月くらい登録してみる。
なかなかPythonが楽しくなってきたが、クラス意味が今一つ掴めないままいったん中断。
この辺で、自分は統計に興味があってもプログラミングに興味がないんじゃないかということに気づく。
なんだかんだもがきながら、PythonもRもモノにならず、日常のちょっとした計算やグラフを作ったりはExcelを使い続ける日々が続く。
あるいは、Excelで成形して、検定かけやすい形式にしてRで検定するとか。
Rに触れてなかったな、Rは完全に独学。「こんなことやりたいなぁ、ググってみるか、ほうなるほど」って感じ。
そんなさなか、放送大学で「Rで学ぶ確率統計」という講義があるのを知り、さっそく入学して受講。
なかなか面白かったし、PythonばっかりでRあんまり触ってなかったからいい刺激になった。
恥ずかしながら、負の二項分布やガンマ分布ってよう知らんかった。
しかし、講義は楽しかったがなにか書けるようになったかというとそんなことはなく、依然として基本はExcel。
まあ、実際csvじゃなく、手書きのデータとかをExcelに打ち込んだりする程度なんでPythonやRを使うまでもなかったというのもあるんだけど。
「Excelパワーピボット 7つのステップでデータ集計・分析を「自動化」する」
パワークエリを覚えたらピボット形式のExcelファイルとか、セルの結合が多用されたExcelファイルを、成形加工するのが非常に楽になった。
しかも、同じフォーマットで記録されてるデータならフォルダにぶち込んで一気にまとめ上げることも可能!
控えめにいって神!
としばらくパワークエリを礼賛してたのだけど、各ステップはPythonのpandasやRのdplyrでも出来ることに気づく。というか最初から気づけ。
こりゃ、一気に覚えちまおう、統計というより、データの前処理だなと思ってUdemyでRの動画を買ってみた。
AIエンジニアが教えるRとtidyverseによるデータの前処理講座
https://www.udemy.com/course/r-tidyverse-preprocess/
すっかりR信者になる。
それまで教本を呼んでもdplyrの便利さが今一つわからなかったのに、パワークエリで具体的にモノを作ると、dplyrに翻訳したら、すいすい。スピード10倍。
便利さにようやく気付く。
そんで、pandasに翻訳したらどうなんだろ?と思ったらもっと速いw
すごいなPython。
Rへの入信はたった数週間。再びPythonに興味。
さて、ゼロから作るディープラーニングを再開しようと思ったけれども、そもそも、機械学習をすっ飛ばして深層学習って無茶だったと反省し、まずは機械学習に。
機械学習のエッセンス -実装しながら学ぶPython,数学,アルゴリズム- (Machine Learning)
で、この本がすごい。
5章あるんだけど、機械学習のアルゴリズムは5章だけなんだなw
それまでは何に割かれてるんだって?数式の証明とか、便利な計算法、例えばニュートン法とかラグランジュ未定乗数法とかw
こんだけ引っ張っておいて、いよいよ本番の第5章もゴリゴリ数式をスクリプトに落とし込んでいってるのに、「これは学習のためでscikit-learnっての使えばたった1行」っていう無慈悲w
いや、ほんと数学の勉強になったし、こうやってゴリゴリやるとなんのためにクラスというものが存在するのかようやくわかった。
線形代数って便利なんだなと。行列をスカラー値のように何の気なしに扱えるようになると、あの頃苦しんでいた実験計画法、タグチメソッド、今読み直したら別の印象があるんじゃないかなと思うようになったり。
この本を読む途中、「マンガでわかる統計学因子分析編」で学んだことが理解の助けになった。
なんたる僥倖。
線形回帰、リッジ回帰、SVM、PCA、k-means、クラスター分析、一気に手札が増えた。
Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析
実験計画法って、fisherの古典的なやつ、ラテン方格に割り付けて、ってやつかと思ったら、線形代数使えればもうなんでもありなのな。
これ、すごいな。
機械学習と実験計画法がここでつながるとか、控えめにいって最高だな。
まだ読了してないので、また後日。
鉄緑会のことを何も知らないで書く。なので、完全に的外れかもしれない。
「東大の先生の授業レベルが、そのまま受験のバックグラウンドになっているから、現役東大生が集まった塾ではその知識やバックグラウンドが集合知となるから」
だと思われる。
あれって、大学レベルだと、フーリエとかラプラスとか使ったり、等価回路使ったりする。
で、実際過去問でそういえばそんなものがテーマになって高校生用にアレンジされてる感の問題があった。
この知識があって、そう言う感じの問題が出れば、圧倒的に有利だ。しかも周りは解けない。
そもそも、東大が日本の大学生の標準的な教科書を書いてる先生と書いて、それをパクって全国の大学が授業してるわけで。
その根本的な「東大生の学問理解レベル」を作成してる東大の先生の脳味噌は、東大生に反映されていて。それで問題を解析してるわけだ。
全国の塾で、東大の授業、レベルを知っている人がどれだけいるか。
もちろん、最先端まで知ってる塾講師はいるだろうが、「東大生のレベル」を色々な分野含めて知ってるとなると、鉄緑会しか無理だと思う。
自分の場合、物理、数学、生物ではこの手の感覚や、誰先生の授業が元ネタだろうなとかまでわかる。
おそらく、社会も化学も英語も国語もそう言う感じじゃないかと思う。
だって普通の受験生は、ラグランジュとか二回微分の解析とか知ら無いで、そこから発想された問題は捨てるか大量のハンデで解くしかない。
一方で、鉄緑会は、そう言うのを織り込み済みの中で教育されていて、問題への対応力が違うわけだもん。
一般の受験参考書の著者も、研究として1分野を知っていても、「現役の東大の集合知」となると敵わないから、あくまでこれまでの参考書のアレンジしかできないと思う。
一般受験生が、過去問などから、「東大テイスト」を知ろうと必死になるよりも、さらにアドバンテージ持ってるし、それをベースに計画された問題演習やってるわけじゃん。
そら敵わないわ。
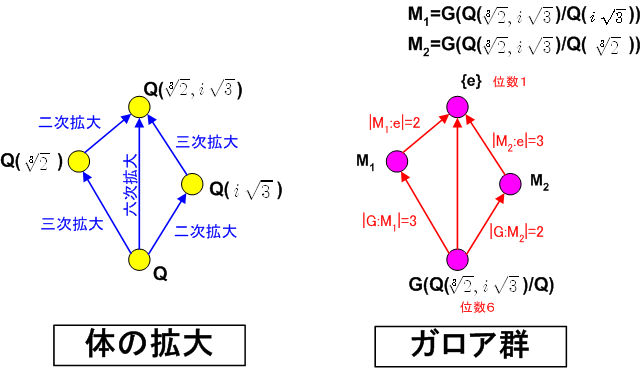
『数学ガール ガロア理論』の第10章(最終章)がそれまでの章に比べて難しくて挫折するという感想がけっこうあるようなので、その補足的な解説を試みます。『ガロア理論』第10章はガロアの第一論文を解説しているので、解説の解説ということになります。
と進んでいきますが、ミルカさんはその途中で何度も、ガロアの第一論文のテーマが「方程式が代数的に解ける必要十分条件」であることを確認します。
なぜ何度も確認するかといえば、最後の定理5(方程式が代数的に解ける必要十分条件)以外は、一見したところでは「方程式の可解性」に関わることが見て取れないので、途中で確認を入れないと簡単に道に迷ってしまうからでしょう。定理2(≪方程式のガロア群≫の縮小)や定理3(補助方程式のすべての根の添加)は、目的の方程式を解くときに利用する補助方程式に関わる話ですが、やはり定理を見ただけでは「方程式の可解性」との繋がりはよく見えません。
そこで逆に、いったん「方程式の可解性」の話から離れて定理5を除外して、それ以外だけに注目します。
「方程式の可解性」から離れて見たとき、定理1から定理4までで何をやっているかというと、
ということ(ガロア対応と呼ばれます)を示しています。ミルカさんの言葉を使えば(p.362)、体と群の二つの世界に橋を架けています。
この体と群の対応関係を図で見ると、10.6節「二つの塔」の図(p.413、p.415、p.418)、あるいは
http://hooktail.sub.jp/algebra/SymmetricEquation/Joh-GaloisEx31.gif
http://f.hatena.ne.jp/lemniscus/20130318155010
のようになります(この体と群の対応関係は常に成り立つわけではなく、第8章「塔を立てる」で説明された「正規拡大」のときに成り立ちます)。
体と群に対応関係があること(定理1~定理4)を踏まえて、定理5を見ます。
「方程式を代数的に解く」というのは「体の拡大」に関係する話です。
「方程式の係数体から最小分解体まで、冪根の添加でたどりつくことが、方程式を代数的に解くことなのだ」
(第7章「ラグランジュ・リゾルベントの秘密」p.254)(ただし、必要なだけの1のn乗根を係数体が含んでいるという条件のもとで)
そこから、「体と群の対応」を利用して、方程式の解の置き換えに関する「群」の話に持っていくのが、定理5になるわけです(なお「方程式を解くこと」と「解の置き換え」が関係していることは、すでに第7章に現れていました)。
「≪群を調べる≫って≪体を調べる≫よりも(...)」
ここまでの話で、定理4までで行いたいことが「≪体の世界≫と≪群の世界≫の対応関係」だということが分かりました。
しかしこの対応を示すためには、まず、この対応関係における≪群の世界≫というのがいったい何なのかをきちんと定義しないといけません。
≪体の世界≫というのは「体の拡大」で、これは8章「塔を立てる」で説明されています。
一方、その「体の拡大」に対応する「群」は「方程式の解の置き換え方の可能な全パターン」なのですが、これが正確にどんなものなのかは10章以前には定義されていません。
(以下、4次方程式の例をいくつかあげますが、面倒なら流し読みでさらっと進んでください)
たとえば一般3次方程式では、解α、β、γの置き換え方は全部で6通り(3×2×1)あります(第7章p.252)。同様に考えると、一般4次方程式では、解α、β、γ、δの置き換え方は全部で24通り(4×3×2×1)あることが分かります。
ところが、x4+x3+x2+x+1=0という4次方程式を考えてみます。これは5次の円分方程式です(第4章「あなたとくびきをともにして」)。
x5-1 = (x-1)(x4+x3+x2+x+1)なので、この方程式の解α、β、γ、δは1の5乗根のうちの1以外のものだと分かります。したがって、解の順番を適当に選ぶとβ=α2、γ=α3、δ=α4という関係が成り立ちます。
これについての解の置き換え方を考えると、αを、α、β、γ、δのうちのどれに置き換えるかを決めると、それに連動して、β、γ、δがどの解に置き換わるかも自動的に決まってしまいます。たとえばαをβ(=α2)に置き換えると、(β、γ、δ)=(α2、α3、α4)は、
(β、γ、δ) = (α2、α3、α4)
↓ αをβに置き換える
(β2、β3、β4) = ((α2)2、(α2)3、(α2)4) = (α4、α6、α8) = (α4、α1、α3) = (δ、α、γ)
となるので、
(α、β、γ、δ) → (β、δ、α、γ)
のように置き換わります。αの置き換え方は4通り(α、β、γ、δの4つ)なので、この4次方程式x4+x3+x2+x+1=0の解の置き換え方は次の4通りとなります。
(α、β、γ、δ) → (α、β、γ、δ) = (α、α2、α3、α4)
(α、β、γ、δ) → (β、δ、α、γ) = (α2、α4、α6、α8)
(α、β、γ、δ) → (γ、α、δ、β) = (α3、α6、α9、α12)
(α、β、γ、δ) → (δ、γ、β、α) = (α4、α8、α12、α16)
あるいはx4-5x2+6=(x2-2)(x2-3)=0 という方程式を考えます。解は√2、-√2、√3、-√3の4つですが、この場合「√2と-√2の置き換え」や「√3と-√3の置き換え」は許されますが、「√2と√3の置き換え」は許されません。
なぜかというと、(√2)2 -2 = 0、という式を考えると分かります。この式で√2を√3に置き換えると、左辺は(√3)2 -2 = 1となり、一方、右辺は0のままです。このような等式を破壊してしまうような解の置き換え方は認められません。そのため、可能な解の置き換え方は4通りになります。ただし、4通りの置き換え方のパターン(解の置き換えの「群」)は、5次円分方程式のときの4通りの置き換えパターンとは異なっています。(α、β、γ、δ) = (√2、-√2、√3、-√3)と置くと、可能な置き換え方は
(α、β、γ、δ) → (α、β、γ、δ) = ( √2、-√2、 √3、-√3)
(α、β、γ、δ) → (β、α、γ、δ) = (-√2、 √2、 √3、-√3)
(α、β、γ、δ) → (α、β、δ、γ) = ( √2、-√2、-√3、 √3)
(α、β、γ、δ) → (β、α、δ、γ) = (-√2、 √2、-√3、 √3)
となります。
では、「認められる置き換え方」であるためにはどのような条件を満たす必要があるのかというと、それは
というものです。つまり解θの最小多項式をf(x)とすると、解の置き換えをしたときに、θはf(x)の根θ1、...、θnのどれか(この中にはθ自身も入っています)に移らなければなりません。この条件を満たしていれば、等式に対して解の置き換えをおこなっても、等式が破壊されることはありません。
解の置き換えであるための必要条件が出ましたが、この条件だけではx4+x3+x2+x+1=0のときのような、解の置き換えで複数の解の動きが連動しているような場合をどう考えればいいのかは、まだ分かりません。x4+x3+x2+x+1=0のときは一つの解の動きを決めれば他の解の動きが決まりましたが、方程式によっては解の間の関係はもっとずっと複雑にもなりえます。
しかしそれは、たくさんの解を一度に考えるから解の間の関係が複雑になって混乱するのです。
もしもx4+x3+x2+x+1=0のときの解αのように、ただ一つの解の動きだけを考えて全ての置き換えが決まってしまうならば、話はずっと簡単になります。
そして、その「一つの解の動きだけを考える」ようにしているのが、
です。
体に注意を向けたほうがいい。添加体を考えれば、補題3の主張は一行で書ける」
K(α1、α2、α3、...、αm) = K(V)
これによって、「解α1、α2、α3、...、αmの置き換え」ではなく、ただひとつの「Vの置き換え」だけを考えればいいことになります。
これと、解の置き換えの必要条件「解の置き換えをおこなったとき、解は、共役元のどれかに移らなければならない」を合わせると、「解の置き換え方の可能な全パターン」とは、「Vから、Vの共役への置き換えのうちで、可能なものすべて」となります。
そして補題4(Vの共役)は、「Vの(共役への)置き換え」をすると、もとの多項式f(x)の根α1、α2、α3、...、αmの間の置き換えが発生するという性質を述べています。つまり「Vの置き換え」によって「方程式f(x)=0の解の、可能な置き換えが実現される」わけです。
この考えにもとづいて「解の置き換えの群」を定義しているのが、定理1(≪方程式のガロア群≫の定義)の説明の途中の、10.4.4節「ガロア群の作り方」です。
(ガロアは正規拡大の場合にだけ「解の置き換えの群」を定義したので、正規拡大のときの「解の置き換えの群」を「ガロア群」と呼びます)
前節で、証明のかなめとなるVと「解の置き換えの群」が定義されました。Vの最小多項式fV(x)の次数をnとすると、次が成り立ちます(最小多項式は既約で、既約多項式は重根を持たないので、Vの共役の個数は最小多項式の次数nと一致することに注意する)。
※1 考えている体K(V)に含まれない数へのVの置き換えは「解の置き換え」には認められないので、「解の置き換え方の個数」と「共役の個数」は一致するとは限りません。
※2 「最小多項式」は8.2.8節「Q(√2+√3)/Q」と8.2.9節「最小多項式」で説明されていますが、最小多項式が既約であることと一意に決まること(8.2.9節p.282)は、定義(可約と既約)と補題1(既約多項式の性質)から証明されます。
そして、
したがって正規拡大のときには、
という等式が成り立ちます。この関係が「体と群の対応」の第一歩目になります。
ことを主張しています。
そして定理2(≪方程式のガロア群≫の縮小)と定理4(縮小したガロア群の性質)で、
ことを主張しています。
ことを主張しています。
このように定理1、定理2、定理3、定理4によって、体と群の対応が示されます。
方程式が代数的に(つまり冪乗根によって)解けるかという問題は
と言い換えられます。そして、
ので、「適切な冪乗根が存在するか」という問題は「適切な正規拡大が存在するか」という問題になり、体と群の対応により
という問題になります。この「適切な正規部分群があるかどうか」をもっと詳しく正確に述べたのが定理5です。
それでは改めて第10章を読んでいきましょう。
(追記: 数式の間違いの指摘ありがとうございます。訂正しました)
諸君 私はサイエンスが 好きだ
諸君 私はサイエンスが 大好きだ
帰納法が好きだ 演繹法が好きだ 思考実験が好きだ 実証実験が好きだ
代数学が好きだ 関数解析学が好きだ 集合論が好きだ 統計学が好きだ 情報理論が好きだ
Unixで Linuxで MatLabで Mathematicaで C++で Javaで 紙と鉛筆で 口頭で
全てのプラットフォームで行われる ありとあらゆる論証行為が 大好きだ
数列をならべた 並行スレッドの一斉実行が ファン音と共に他のプロセスを reniceるのが好きだ
ふと思いついて計算してみたモデルが 想定していた通りの結果をはじき出した時など 心がおどる
Athlonの64bit(フィア・ウンド・ゼヒツィヒ)でフェドラ7を使うのが好きだ
某M木先生さー、何でもかんでも「脳科学で説明出来ます」って擬似科学入ってるよねー、と言われた時は 我が意を得た様な気持ちだった
ラグランジュの未定乗数で ハミルトンの原理の拘束が表現されるのを知るのは 楽しい
リゾラッティの ミラーニューロンに関する基調講演を聞いた時など 感動すら覚えた
還元主義のfMRI万能論者達の発表が 質問攻めと共に叩きのめされる様などはもう たまらない
居並ぶフックス型微分方程式が 私の押したEnterキーとともに
金切り声を上げるCPUに あっという間に計算されるのも最高だ
哀れなM$オフィスユーザー達が 雑な数式エディタで 健気にもフィッツヒュー・南雲モデルの方程式を書こうとしている時に
PCがフリーズして ドキュメントが過去5時間分のテキストごと木端微塵にされるのを見ると TeX使いは ちょっと優越感を覚える
露助の教授に「あなたの理論は間違ってる事が(ロシアで)20年以上前に証明されていてねぇ」と指摘されるのが好きだ(ラボ内だったからな)
必死に守るはずだった仮説が反証され 実験の不備が指摘され 論文がリジェクトされるのは とてもとても 悲しいものだ
米国の物量(研究資金的な意味で)にものを言わせた研究所に 自分と同じ研究内容を先にPLoSに発表されるのだけは 勘弁だ
締切り(近々だと1月に1こ)に追いかけられ 太平洋標準時だからこっちの朝4時まで大丈夫!と徹夜するのは 体力的にそろそろ無理だ
君達は 一体 何を 望んでいる?
情け容赦のない 鬼の様なピアレビューを 望むか?
並列処理の限りを尽くし 三千世界のCPUを焼き尽くす 嵐の様なシミュレーションを 望むか?
「D論(クリーク)!! D論(カフェイン)!! D論(メンタルヘルス)!!」
よろしい
我々は満身の 力をこめて 今まさに スライドを指し示さんとする レーザーポインタだ
だが この暗い研究室の中で 3年もの間 堪え続けて来た 我々に
大論争を!!
一心不乱の大論争を!!
。。。。えー、
「男が出来る気がしない」と、 http://anond.hatelabo.jp/20081127063438 を書いた増田ですが、
どーせ釣りだろと言われた/予想以上にHELLSINGに反応してくれた人がいた/NIPSに持ってかなきゃ行けないスライドがいつまでたっても終わんない/ので、ついカッとなってやった。反省はしている。
でも三体問題はどうあがいても数値計算するしかないし、組み合わせ最適化は
P=NPが証明されない限り厳密解を求めるには総当たりするしかない。しかも
そのへんはけっこう昔から難しいとわかっていたことでもある。
一般的にはその通りだけど、三体問題の特殊な場合としてはラグランジュ解なんてのもあるよね。あとNP完全についても厳密解ではなくて、それぞれの場合で有効な実用解の求め方やその改良などなど。
何より気になったのは
いまどきは数式処理ソフトがさくさくっと式を変形してくれるので
そうやって頼る人ばっかりだったら誰が数式処理ソフトを作ったり改良したりするのさ。
{kind=link}