はてなキーワード: ヒストグラムとは
理想的な量子コンピュータが作れたとしても、既存のコンピュータでできることの全てが速くなるわけではない。
量子加速が効くアルゴリズムは非常に限られていて、加速されるアルゴリズムであっても指数的に加速するものはさらに少なく大半は多項式加速に過ぎない。
多項式程度の加速だとデコヒーレンスやノイズにかき消されて優位性が消滅しがち。
そして量子計算は原理的に出力が確率的(ヒストグラム)にしか得られないので、厳密な計算が必要となる状況では使えない。
(なお「理想的な量子コンピュータ」を作れる見通しは現状全くなく、原始的な量子誤り訂正をどうにかこうにか実装しようと苦労してる段階)
将棋棋士一覧 - Wikipedia のデータをまとめたものです。ヒストグラムや検定にご活用ください。
| 死亡年 | 5年階級 | 年齢 |
|---|---|---|
| 1859 | 1860 | 44 |
| 1915 | 1915 | 63 |
| 1920 | 1920 | 54 |
| 1921 | 1920 | 89 |
| 1939 | 1940 | 55 |
| 1940 | 1940 | 50 |
| 1941 | 1940 | 59 |
| 1943 | 1945 | 50 |
| 1944 | 1945 | 79 |
| 1945 | 1945 | 26 |
| 1946 | 1945 | 77 |
| 1946 | 1945 | 76 |
| 1947 | 1945 | 61 |
| 1948 | 1950 | 50 |
| 1951 | 1950 | 72 |
| 1955 | 1955 | 55 |
| 1955 | 1955 | 38 |
| 1956 | 1955 | 59 |
| 1956 | 1955 | 42 |
| 1960 | 1960 | 40 |
| 1960 | 1960 | 46 |
| 1964 | 1965 | 64 |
| 1965 | 1965 | 74 |
| 1965 | 1965 | 56 |
| 1965 | 1965 | 74 |
| 1966 | 1965 | 71 |
| 1968 | 1970 | 74 |
| 1970 | 1970 | 36 |
| 1971 | 1970 | 70 |
| 1972 | 1970 | 79 |
| 1973 | 1975 | 85 |
| 1973 | 1975 | 64 |
| 1974 | 1975 | 65 |
| 1977 | 1975 | 46 |
| 1977 | 1975 | 55 |
| 1977 | 1975 | 63 |
| 1977 | 1975 | 77 |
| 1977 | 1975 | 62 |
| 1978 | 1980 | 65 |
| 1979 | 1980 | 67 |
| 1979 | 1980 | 42 |
| 1979 | 1980 | 72 |
| 1979 | 1980 | 75 |
| 1980 | 1980 | 89 |
| 1980 | 1980 | 48 |
| 1980 | 1980 | 65 |
| 1981 | 1980 | 61 |
| 1981 | 1980 | 88 |
| 1981 | 1980 | 78 |
| 1981 | 1980 | 73 |
| 1982 | 1980 | 74 |
| 1982 | 1980 | 73 |
| 1984 | 1985 | 57 |
| 1985 | 1985 | 86 |
| 1985 | 1985 | 79 |
| 1985 | 1985 | 80 |
| 1985 | 1985 | 75 |
| 1985 | 1985 | 67 |
| 1985 | 1985 | 79 |
| 1986 | 1985 | 70 |
| 1986 | 1985 | 81 |
| 1987 | 1985 | 74 |
| 1987 | 1985 | 51 |
| 1987 | 1985 | 83 |
| 1988 | 1990 | 47 |
| 1988 | 1990 | 67 |
| 1989 | 1990 | 73 |
| 1990 | 1990 | 88 |
| 1990 | 1990 | 81 |
| 1991 | 1990 | 73 |
| 1991 | 1990 | 81 |
| 1992 | 1990 | 69 |
| 1993 | 1995 | 72 |
| 1993 | 1995 | 31 |
| 1993 | 1995 | 68 |
| 1993 | 1995 | 78 |
| 1993 | 1995 | 70 |
| 1993 | 1995 | 44 |
| 1994 | 1995 | 75 |
| 1994 | 1995 | 77 |
| 1994 | 1995 | 74 |
| 1994 | 1995 | 74 |
| 1994 | 1995 | 80 |
| 1995 | 1995 | 78 |
| 1995 | 1995 | 77 |
| 1995 | 1995 | 82 |
| 1996 | 1995 | 83 |
| 1996 | 1995 | 86 |
| 1996 | 1995 | 55 |
| 1997 | 1995 | 84 |
| 1997 | 1995 | 67 |
| 1998 | 2000 | 77 |
| 1998 | 2000 | 29 |
| 2000 | 2000 | 69 |
| 2001 | 2000 | 86 |
| 2001 | 2000 | 72 |
| 2002 | 2000 | 76 |
| 2003 | 2005 | 66 |
| 2004 | 2005 | 81 |
| 2004 | 2005 | 67 |
| 2005 | 2005 | 72 |
| 2006 | 2005 | 61 |
| 2006 | 2005 | 86 |
| 2007 | 2005 | 41 |
| 2007 | 2005 | 55 |
| 2008 | 2010 | 49 |
| 2008 | 2010 | 85 |
| 2008 | 2010 | 83 |
| 2009 | 2010 | 60 |
| 2010 | 2010 | 73 |
| 2010 | 2010 | 71 |
| 2011 | 2010 | 86 |
| 2012 | 2010 | 88 |
| 2012 | 2010 | 69 |
| 2013 | 2015 | 90 |
| 2015 | 2015 | 78 |
| 2015 | 2015 | 95 |
| 2015 | 2015 | 81 |
| 2016 | 2015 | 81 |
| 2016 | 2015 | 84 |
| 2016 | 2015 | 54 |
| 2017 | 2015 | 87 |
| 2017 | 2015 | 75 |
| 2017 | 2015 | 85 |
| 2017 | 2015 | 84 |
| 2018 | 2020 | 76 |
| 2019 | 2020 | 87 |
| 2021 | 2020 | 87 |
| 2021 | 2020 | 86 |
| 2021 | 2020 | 76 |
| 2022 | 2020 | 60 |
| 2022 | 2020 | 72 |
| 2022 | 2020 | 87 |
| 2023 | 2025 | 94 |
Twitterを覗けばそれらしいことを高々と述べる識者気取りの匿名アカウントがバズって気持ちよくなっている。
それも暇な老人のほうが圧倒的に多い。
就職が近い。日本の産業は衰退していることは知っている。それでも少しでもマシなところに就職して少しは生き延びなくてはいけない。
クソの役にも立たない老人ばっかりが金と社会のリソースを食い潰している。
働けなくなったら全員始末したほうがいいと思ってる。
もしそのような社会になったとてもちろん自分だって始末されてもいいと思っている。
ただそのような未来が来ることはない。
多分あと20年か30年くらいしたら棺桶の上半分がごっそり無くなる。
そうなったとき、(そこまでは少なくとも無事だったとして)日本は果たして立っていられるのだろうか。
無理だ。
そうなる前に僕は"お先に失礼"しようと思っている。
僕らに未来はない。
人生100年時代における結婚と家族 特 集 ~家族の姿の変化と課題にどう向き合うか~
https://www.gender.go.jp/about_danjo/whitepaper/r04/zentai/pdf/r04_tokusyu.pdf
っていう、統計好きにはたまらない資料100ページ超えよくばりセット
気になった所まとめ
5ページ目
注目したいのは20代までは結構差はないこと、30代から差がすごい
9ページ目
このグラフ好き
初婚件数減りすぎ(39万件)
これって結婚という制度から離れてるのか、恋愛や共同生活から離れてるのかわからんね
11ページ目
好き
未婚者増えたけど既婚者のほうが多いよね、というのがよくわかる
不詳ってなに?
13ページ目
好き、でも見づらい
いずれ越しそう
ところでこどおじはどこに該当するの?
サザエさん型の家族はもう7.7%爺婆が孫と暮らせる確率低すぎワロタ
16ページ目あたり
こんな指標があるんだ〜
結構生きるよね
女90男85と見ておけばいいか
18ページ目
意外と主婦多くね??
ちょっと意外だけど、昭和60年代でも、共働き718万世帯もある
20ページ目
このグラフ嫌い
まず女性に限ってること
それにしてもフルタイム働いてる妻が20〜30%しかいないのすごいな
25〜34歳が一番少ないから、ここでそもそも正社員ルートから脱落してるのがよく分かる
22ページ目
これ好き
未婚女性の年収を知りたかった、それによって問題が性別にあるのか子育てにあるのかが分かる
400万円以上40〜44歳でみてみるか
・既婚女性 15%くらい
・未婚女性 25%くらい
・既婚男性 65%くらい
・未婚男性 38%くらい
未婚男性と未婚女性はかなり条件が近いと思うんだけど、13ポイントくらいの差がある
これは確実な性差だと思う
既婚女性と未婚女性でも10ポイントくらいの差があるから、性の問題と子の問題は同じくらい存在しているのかも?しらんけど
40〜44歳、既婚女性の年収100万円未満 → 33%くらい
こうみるとやっぱり男性が稼ぐべきという風潮は残ってるんだなと
30〜34歳でも大差はない
これ多分だけど、男性の方が歳上である件数が多いからってのもありそう
25ページ目
夫の稼ぎが悪いほど妻も働いてるのでは?的な統計
夫が200万未満でも妻が働いてないケースが結構あるのが闇深いんだけど、これ逆に資産家なのか?
300万円代なら大体妻が働いている率70%
1500万円以上でも妻が働いてる率56%(30代なら40%)
悲報:1000万円の夫を捕まえても専業主婦に慣れる確率は半分以下
26ページ目
30年で1.5倍っていうんだから全然増えてない、国民性かね?
母子家庭の平均給与 200万円(正規雇用の場合305万円) 闇深
27ページ目
同居人あり40%くらい、親が27%くらい
20代以下が30%くらい
30ページ目
貧困度が高すぎる
32ページ目
エグい
33ページ目
俺のことか
え、逆に寂しくない人すごくね?
あと既婚者でも寂しい人多いんだけどそれは
挨拶をする程度以下
半分ずつ分担派は年々増えている(男女とも)
最近は50%くらい
一方で「妻に丸投げ」派は案外減っていないし
「夫が多くやる」派は極小
どちらかというと「妻100%」が「妻+外部サービス+夫」になった感じ
まあでも徐々に良くなってきてると思うよ
42ページ
日本やべーって話だけど、韓国も似てるので個人的には地域性だと思う
43ページ目
妻が夫の両親の介護の面倒をみなくなってきている
44ページ目
1位 息子
2位 夫
45ページ目
明治時代のほうが高かったという話
48ページ目
これも似た話
49ページ目
僕はなしです
なんだかんだ言って7割以上はよろしくやってんじゃんね、ならいいじゃん
前にどっかで書いたけど
自然にパートナーが出来るのが1/3、マッチングアプリとか使ってパートナー作れるのが1/3、それ以外が1/3みたいな感じだ
50ページ目
未婚女性は0人という人が24%しかいないから、喪女はだいぶレアだと思われる
未婚男性は0人という人が37%いるので、そこそこ居る
あと1人っていうのをどこまでカウントしてるのかも気になるけどね
51ページ
ほんぺん
案外少ない
どういう・・・?
減ってないw
こちらも減ってない
20代で全部決まってるんやなって
53ページ
なかまやで
この人達が出来るだけでだいぶ違うと思う
いい人が居ない、縛られたくない が多い
58ページ目
案外多いね
60代男性 42.5%
案外少ないね
せやろな
65ページ
そこそこいるね
81ページ
俺は興味ないけど該当者はありそうなネタ
85ページ
これ面白い
「男性は外で働き、女性は家事をするべきだ」の賛成が男女で一致している
反対は女性の方が少し多いけど、思いの外男女で価値観は一致している
つまり男性が無理やりやらせているというよりは社会的にそういう空気になってるんだよね
これを変えようとする人らは大変だろうよ
ただ「仕事をセーブしたくない」と思ってる女性は男性より2割くらい多いっぽい
86ページ
これも面白い
「女性が◯◯すべきだ」って思ってる人、60代でも3割前後と少ないんだけど
89ページ
94ページ
これ好き、なかなか出てこない情報
100人未満 48%
数百人規模 27%
1000人以上 25%
100人未満 36%
数百人規模 31%
1000人以上 32%
なるほどなぁ
99ページ
何十万とある生データを直接見せられても人間は正しく理解できない。
平均値、中央値、最頻値、分散、最大値、最小値、四分点、ヒストグラム、そして各種グラフ・・・
何十万の生データをこれらの両手で収まるような数値群に集約することで、ようやく人間にもそのデータの形が見えるようになる。
何十万のデータがせいぜい十程度の数値に収まるのだから、そこには膨大な情報の欠落があるのを、当然と思えない人はおかしい。
勿論、単なる膨大な欠落とはならないよう、取捨選択された情報は極力、元データの特徴を抑えたものにする必要がある。
平均値をはじめとする各種統計量は、基本的にはその観点で優秀なものが使われている。
しかし、どうしても元の情報量は欠落してしまう。それは統計を用いる限りどうすることもできない。
最終的に見せる値が少ないほどそれは顕著で、どの統計量を見せるかによって、データの印象も変ってしまう。
だからといってすぐ、じゃあ統計は詐欺だ、という方向に走るのもおかしい。
そもそも大量の生データは人間には理解できないという前提を理解すべきなのだ。
「理解できない」を元の情報量を代償にしながら「ちょっと理解できる」にするのが統計だ。
グラフも、基本的にはこれと全く同じ。元データじゃ人間には何が書いてあるのかわからないから、せめて情報量を絞って、イラストレーションして大枠だけなんとか伝えようとした結果だ。
情報量を絞るのだから、当然その過程で欠落は起きるし、生データのうち一部だけの印象を見せることしかできない。
だから様々なグラフを選択したり、工夫を用いてどうにかそれぞれの生データの特徴を最も優秀に表すことができそうな形を模索するのだ。
このデータは重要なのは平均値くらいだな・・・とか、このデータは散らばり具合も見せないと分からないな・・・とか言うのと基本的には同じだ。
それを、自衛の意識が高すぎるのか、被害妄想か、「この種類のグラフはどんな状況でもとにかく駄目!」とか言うのは筋が悪すぎる。
まあ3D円グラフとかどう考えても絶対に擁護できないものもあるが、そんなものはごくわずかしかない悪例であって、大概は「何が何でも全く使うタイミングが無い」というグラフはない。
元のデータの特徴に合わせてなんとか人間が理解しうるような様々な形態を取捨選択してできたグラフなのだということを、理解すべきだろう。
https://natgeo.nikkeibp.co.jp/atcl/web/17/020800002/021400005/?P=3
「私、別に男女の脳に差がないとは全然思ってなくて、絶対あると思ってるんです。でも、じゃあ、それがどんな差なんだろうっていうときに、気をつけてもらいたいことがあります。たとえば、これを見てください。メンタルローテーション課題というんですけど、立体図形を頭の中でクリクリッと回して、一致するものを探す課題ですね。これって、世の中にある諸々の課題の中で一番、男女差が出しやすいっていわれてます」
「じゃあ、この課題での男女差ってどのくらいだろうっていうときに、横軸に点数をとって、縦軸にその点数をとった人の人数をプロットしたヒストグラムを作ります。右にいくほど成績がいい人で、左にいくほど成績が悪い人で、平均あたりに一番人数が多いという形になった時、男性と女性のプロットを比べると、女性はちょっとだけ全体的に左にずれている。これは統計的にはめちゃめちゃ有意なんです。確実に男女差がある。でも、有意だというのと、大きな差があるかというのは別で、男女のヒストグラムがこれだけ重なって、男女の平均の差よりも、個人差の方が大きいよねってくらいのものですよね。一番、はっきり差がでるものでもこれくらいですから」
という話だぞ。
| はてなID長さ | ID数 |
|---|---|
| 3 | 1594 |
| 4 | 5071 |
| 5 | 10851 |
| 6 | 20513 |
| 7 | 26651 |
| 8 | 33216 |
| 9 | 26653 |
| 10 | 23063 |
| 11 | 17027 |
| 12 | 13742 |
| 13 | 8972 |
| 14 | 6506 |
| 15 | 4440 |
| 16 | 2699 |
| 17 | 1717 |
| 18 | 1186 |
| 19 | 786 |
| 20 | 608 |
| 21 | 367 |
| 22 | 252 |
| 23 | 182 |
| 24 | 133 |
| 25 | 108 |
| 26 | 66 |
| 27 | 60 |
| 28 | 34 |
| 29 | 24 |
| 30 | 18 |
| 31 | 30 |
| 32 | 37 |
持ってたデータ中に自分のIDは107回出現。それ以上の回数出現するIDに限ると。
短ければ短いほどアクティブな率は高いようだ。
| はてなID長さ | 107回以上出現のID数 | 107回以上比率 |
|---|---|---|
| 3 | 296 | 19% |
| 4 | 736 | 15% |
| 5 | 1370 | 13% |
| 6 | 2283 | 11% |
| 7 | 2698 | 10% |
| 8 | 2999 | 9% |
| 9 | 2367 | 9% |
| 10 | 1875 | 8% |
| 11 | 1365 | 8% |
| 12 | 1033 | 8% |
| 13 | 654 | 7% |
| 14 | 459 | 7% |
| 15 | 278 | 6% |
| 16 | 139 | 5% |
| 17 | 80 | 5% |
| 18 | 51 | 4% |
| 19 | 32 | 4% |
| 20 | 11 | 2% |
| 21 | 15 | 4% |
| 22 | 7 | 3% |
| 23 | 5 | 3% |
| 24 | 3 | 2% |
| 25 | 4 | 4% |
| 26 | 1 | 2% |
| 27 | 2 | 3% |
| 28 | 1 | 3% |
| 29 | 1 | 4% |
| 30 | 0 | 0% |
| 31 | 0 | 0% |
| 32 | 1 | 3% |
集計期間 2018年3月23日 20時10分 〜 2018年3月26日 20時10分、3日間(72時間10分)
集計対象は2018年3月23日 20時10分以降ファーストブクマされたエントリーに限った
| ファーストブクマからの時間(時間台) | 度数 |
|---|---|
| 0 | 13 |
| 1 | 33 |
| 2 | 38 |
| 3 | 34 |
| 4 | 19 |
| 5 | 14 |
| 6 | 16 |
| 7 | 13 |
| 8 | 10 |
| 9 | 21 |
| 10 | 8 |
| 11 | 13 |
| 12 | 6 |
| 13 | 5 |
| 14 | 3 |
| 15 | 3 |
| 16 | 6 |
| 17 | 0 |
| 18 | 1 |
| 19 | 1 |
| 20 | 0 |
| 21 | 0 |
| 22 | 0 |
| 23 | 1 |
| 24 | 0 |
| 25 | 0 |
| 26 | 0 |
| 27 | 0 |
| 28 | 0 |
| 29 | 0 |
| 30 | 1 |
| 31 | 0 |
| 32 | 0 |
| 33 | 0 |
| 34 | 0 |
| 35 | 0 |
| 36 | 0 |
| 37 | 0 |
| 38 | 1 |
| 中略 | 0 |
| 72 | 0 |
集計期間 2018年3月23日 20時10分 〜 2018年3月26日 20時10分、3日間(72時間10分)
集計対象は2018年3月23日 20時10分以降ファーストブクマされたエントリーに限った
| ファーストブクマからの時間(時間台) | 度数 |
|---|---|
| 0 | 293 |
| 1 | 219 |
| 2 | 149 |
| 3 | 130 |
| 4 | 115 |
| 5 | 84 |
| 6 | 72 |
| 7 | 65 |
| 8 | 70 |
| 9 | 50 |
| 10 | 64 |
| 11 | 52 |
| 12 | 31 |
| 13 | 38 |
| 14 | 27 |
| 15 | 31 |
| 16 | 22 |
| 17 | 23 |
| 18 | 29 |
| 19 | 14 |
| 20 | 12 |
| 21 | 22 |
| 22 | 14 |
| 23 | 18 |
| 24 | 8 |
| 25 | 10 |
| 26 | 10 |
| 27 | 0 |
| 28 | 7 |
| 29 | 3 |
| 30 | 6 |
| 31 | 5 |
| 32 | 7 |
| 33 | 3 |
| 34 | 4 |
| 35 | 9 |
| 36 | 5 |
| 37 | 9 |
| 38 | 6 |
| 39 | 3 |
| 40 | 4 |
| 41 | 2 |
| 42 | 8 |
| 43 | 2 |
| 44 | 7 |
| 45 | 6 |
| 46 | 3 |
| 47 | 2 |
| 48 | 4 |
| 49 | 6 |
| 50 | 3 |
| 51 | 0 |
| 52 | 0 |
| 53 | 2 |
| 54 | 1 |
| 55 | 1 |
| 56 | 3 |
| 57 | 0 |
| 58 | 1 |
| 59 | 1 |
| 60 | 1 |
| 61 | 0 |
| 62 | 1 |
| 63 | 0 |
| 64 | 1 |
| 65 | 0 |
| 66 | 1 |
| 67 | 0 |
| 68 | 0 |
| 69 | 0 |
| 70 | 0 |
| 71 | 0 |
| 72 | 0 |
データを取得し始めてからファーストブクマが付いたエントリーに限ったため72時間以上のデータはないが、ファーストブクマから20日ほど経っているのに新着エントリーにいるエントリーも存在した。リニューアル前にあったファーストブクマから7時間ほどで新着エントリーに入れなくなる制限は緩和されたと思われる。
https://pbs.twimg.com/media/DW2_DTAUMAAM4k9.png:orig
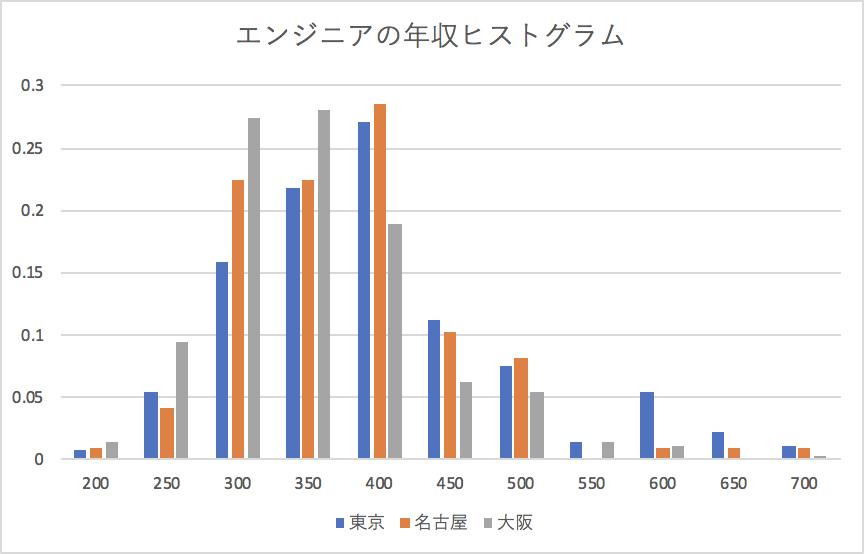
更に言うと長く働いている能力のあるエンジニアや中途採用したエンジニアにもちゃんと給与を出して欲しい。
それなりに評価されて入社時から見ると200くらい上がった。600ちょい貰っている。
見渡すと同世代の友人たち(ITエンジニア)もそれなりに活躍してそれなりに評価されている。
一番上を見ると4桁に達した人もいるし、800超えている人も何人か居る。
これは素晴らしい話だと思う。
でも30代くらいの知り合いを見るとどうだろうか。
物凄く貰っている人ももちろん見る。しかしそういう人達は役職がついた優秀だ。凡庸エンジニアではない。
増田がこんな事を言うのも要らぬおせっかいなのかもしれないが、就職氷河期世代だか何だか知らないけど、給与の更新をちゃんとしろよ経営者って思う。
幸いなことに現状の就活世代は少なくともエンジニアに関しては売り手市場だと思う。
やる気さえあれば適当にGitHubとかで適当にコードを晒しておくと実力のエビデンスにつながるし、割と簡単に就職できてしまうだろう。
お陰で新卒市場の給料はそれなりに高騰していると思う。もちろんもっと上がって良いと思うし、客観的に新卒の方が優秀なやつが多い印象はある。
その事実を踏まえても30代の人がしっかりと評価されているようには思えない。
それなりに書けて、それなりな設計ができて、それなりなコミュニケーションを取れる人間はもう少し評価されても良いのではないだろうか。
関東の桜は満開のピークをすぎました。
写真がデジタルになった恩恵の一つは、撮った写真データの合成が容易にできるということです。
桜の花びらが舞い散る様を撮影して、いざ写真を見てみると花びらの少なさにがっくりすることがありませんか?
人の目で見ているときは時間の経過があるので、次々に花びらが舞っていく量を体感することができますが、いざ写真に撮ってみるとその時に舞っている花びらしか写らないので量を感じるには乏しい物になってしまいます。
これは、写真が瞬間を切り取るものであるからこその悲劇と言えます。
そんなときは、カメラを高速連写モードにして3~5枚ほど一気に撮影しましょう。
その後、撮影した写真データをそれぞれ重ね合わせて合成します。
フォトショップでいうところのレイヤーの描画モードや、スマートフォンアプリなど可能です。
そうすると、それぞれの写真の変化があった部分だけが合成されます。つまり、舞い散る花びらの量だけを増やすことができるのです。
ちょっとした角度の違いで背景がブレてしまうようであれば、舞い散る花びら以外の部分は消しゴムで消してしまいましょう。
あとはお好みで合成する枚数を増やしていけば完成です。
手持ちで撮って余計な部分は消してしまえばいいという手軽さです。覚えておくと便利です。
スローシャッターとは、シャッタースピードを遅くして故意に被写体ブレを起こさせるテクニックです。
花びらや桜の枝を故意にブレさせることによって桜の散る様を表現してみましょう。
シャッターの開いている時間が長くなるということは当然それだけ手ブレのリスクが増えます。
そうなると三脚が必須ですが、人通りの激しい花見の季節にはなかなか取り出せません。
そこでオススメなのはスタンド機能がついている一脚です。マイクスタンドの用に一脚の下の部分がパカリと開きます。
注意して使えば軽いミラーレスでなくても数秒は安定してくれます。
次に大切なことは、光量です。
日中の撮影でスローシャッターをすれば当然露出オーバーになってしまいます。
そこで登場するのがNDフィルターです。
減光フィルターとも言われ、文字通りレンズから入る光の量を減らしてくれます。
フィルターには減らす光量に応じて種類が用意されていますが、光量を可変できる安価なものがあるのでひとまずはそれで十分です。
この時、設定をカメラ任せのままにしていると一向に思った通りの写真ができあがりません。
まずはISOを最低感度に固定。
モードをMにしてF値は11を上限に、シャッタースピードを下げていきましょう。
F値の数値が大きくなれば露光量は下がり、シャッタースピードが遅くなれば露光量は多くなります。
まずはその時の散り具合や風の強さに合わせてシャッタースピードを決め、露出が適正になるようにF値を絞っていくのがいいでしょう。
最後のちょっとした微調整は、NDフィルターの明暗を調整することでも可能です。
デジタルになって一番の恩恵は、なにより撮影結果をその場で確認できるということでしょう。
それまでは高度な技術と知識が必要だったスローシャッター撮影も、撮影結果を確認しつつのトライアンドエラーですぐに成功させることができます。
その場合、液晶に写る写真そのもので成否の確認を行ってもいいのですが、せっかくなのでヒストグラムを確認しましょう。
右や左にはみ出してしまっている量が多いと、つまり白飛びや黒つぶれが起きている証拠であり、レッタッチでは情報を取り戻せない状態です。
中央に向かって山型が描かれていれば、あとはレッタッチでどうにでもなります。
ちなみにNDフィルターを用いたスローシャッター撮影にはもう一つのメリットがあります。
それは、動いているものがブレるために写っている人のプライバシーを守れるというものです。
そんな時にスローシャッターで撮影すれば、当然人は動くので被写体ブレが起きて顔の判別ができなくなるというわけです。
スローシャッターを使った写真をうまく撮影するコツは、写真の中にブレていないポイントしっかり写しこむということです。
なぜなら、写真にピンぼけやブレがあると人はその写真が失敗写真だと感じてしまうからです。
例えば揺れない桜の幹、桜の花の背景など、ブレないものを一緒に写しこむことで桜の枝や花の動きを表現しましょう。
つまり、動きを表現したい背景は表現したいものよりも暗いものを選ぶとより動きが表現できるようになります。
これ以外にも、カメラの世界には表現したいことに対するアンサーが沢山用意されています。
手持ちの機材で限界を感じ始めたらまずは色々とためしてみることで更に世界が広がっていくことでしょう。
またそのうち!
だいたい、学生が自分からOA機器の中古販売に興味があるとか言っていきながら、
はねーわ。
でも俺達は学生君の文を読んでんだから、面接官と同じ誤解はねーわ。
いいか。
自分:OA機器の中古販売に興味があって応募しました。(これだけ)
おいおい。こんな所で自分の会社の椅子自慢をしなくても。随分偉そうな奴だ。椅子って10'000円以内の物を使ってるオフィスがあると思うので、こんな根拠の無い自慢をする以前に市場調査(縦軸にオフィス数、横軸に値段をプロットしたヒストグラムを作成)するべきだろう。
こいつの言ってる「良い値段」ていうのは「良い価格設定ですね」なんだよ。プライシング。
一方、世間一般的には「良い値段する」っつったら「高い」って意味になるよな。
だから話が噛み合ってないことは感じながらも
どういう理由で食い違いが生じたのかは帰宅してからもまだわかってないわけ。
この2人の間にどういう食い違いがあったのかは読み取れないといけない。
面接会場にて、時折「自分の会社ってすごいんだぞ」って雰囲気をちらつかせる面接官と面接をした。自分も自分に酔ってる部分はあるものの、相手がそれ以上なのでカチンと来た。以下、面接でムカついた部分について書こうと思う。まずは志望動機を聞かれた時より、
面接官:弊社のどのような部分に興味があったのですか?(志望動機)
自分:OA機器の中古販売に興味があって応募しました。(これだけ)
おいおい。こんな所で自分の会社の椅子自慢をしなくても。随分偉そうな奴だ。椅子って10'000円以内の物を使ってるオフィスがあると思うので、こんな根拠の無い自慢をする以前に市場調査(縦軸にオフィス数、横軸に値段をプロットしたヒストグラムを作成)するべきだろう。次に腹が立ったのは、その場での対応力が問われる設問が出された時。制限時間は10分で、問題は以下。
1.日本国内1年間で消費されるトイレットペーパーの長さ(m)を求めよ。
2.日本国内で働いている美容師、理容師の人数(人)を求めよ。
恐らくこの設問。googleなどで良くやる「バスの中にゴルフボールは何個入りますか?」と言うような設問に当たる。その場で理屈を組み立てられるかを聞く問題だ。時間は10分。「数値なんて知るか!」と思ったので、数値の求め方を聞いてる問題と判断。そこで、求め方を簡単に書く事にし、以下に再現を書こうと思う。
1年間で1人あたりが消費するトイレットペーパーの長さ(の平均値)をa(m)、日本の人口の(推計)をb(人)とすると、(求めるトイレットペーパーの長さの推計値)=abで求まる。aに関してはn人(0<=n<=a)から標本調査を行い、その(標本)平均μ、(標本)分散Sを求め、(それらを検定して)正しいと検定された値を採用する。bに関しては最尤推定量b'で代用する。代用したa,bの値から推計値を求め、それを求める長さとする。
文字が多くて申し訳無い。流石にもうちょい分かり易く説明するべきだが、10分でこれをやろうとするときつい。説明するとn人の1年間あたりの使用量a_1,a_2,a_3......,a_nを調査し、その平均E[a_n] = 1/n Σ(1<=k<=n) a_k = (n人の使用量の合計)/(人数)を使って使用量を求めると言うもの。n人の平均値を求める理由としては、1人だけでは誤差やばらつきが生じるので正確な値は推定しにくいからである。nは統計で言う標本数であり、統計的な計算によりnを決定する必要もある。又nが大きければ大きい程、調査にかかるコストも増える点も考慮しないと。この手法、統計的に見て誤差の少ない推計の仕方なのかは分からない。但しbの値が大きくなればなるほど、誤差が大きくなるのは確かだ。ここでb'=1.0*10^9(1億)の場合と、b'=1.1*10^9(1.1億)の場合を考えるとかなり数値がずれるので想像するだけで怖い。
さて「この方法のメリット、デメリットは?」などと話が進んでいくのかな?と思ったのだが、それは違ったようだ。ただその後の面接官の反応で、流石に腹が立ってしまった。
面接官:この問題は、数字で出して欲しかったんだよ。(トイレットペーパーの量から商品開発するための)会議でその場で答えられるかを聞いていて、abと答えるのかい?
自分:(だったら問題に条件をきちんと書けよ)
自分:すみません。やり方を変えます。資料から(上記aの)推計を出します。
面接官:資料が無い場合で、その場で思い浮かんだ値で答えを出すんだよ。日本の人口は?...
自分も融通が効かないが、流石に誤差が幾ら出るか分からない方法は取りたくないものだ。最低限資料を集め、そこから推計を計算したい所だ。そもそもあらかじめ計算しておくべきものなので、会議の為の設問としては不適切だ。さらに「頭で答えを出せ」などと言ってる時点で、データーの取り方次第で結果が変わると言う事を認識していない面接官のように見受けられる。敢えて言おう。データーを舐めるなと。
そもそも面接の進め方に問題があると感じるのは自分だけか?このような設問を面接で行う場合、面接官は2人以上居る事が望ましい。例えばAさんは人文系、Bさんは理数系と言うようにそれぞれ違った属性の人間を面接官に採用する事が必須条件だ。1対1で面接すると、どうしても質問が偏ってしまう。そのため1対複数の面接を行い、多角的に受験者の特性を読む事が必要だと思うからだ。
http://kwsearch.goo.ne.jp/life/1544.html
どんな人も胸をはれるようなものはもっているもんだと思う。
例えば四肢や五感の一つや二つがない人でも発達障害でも同じで、「普通」というのを平均としヒストグラムで数値で表したときに2シグマ以上離れた数値を「能力がある」とすると、何かが欠けた人は何かの能力を持っていることが多い。
ってのは、結局のところ人間の能力なんて先天性のものもあるけれど、後天的なものと合せて「1」が個人的な考えで、どこにしてもなんにしてもどっかで帳尻があうもんなんじゃなかろうかなーってことなんだけど、どうも人ってのは自分にしても「どこかで比較をしてしまう」傾向があって無駄だとも思うんだけどするんだよね〜。
これは自尊心からくるのか、過去の経験から来るのかはわからないけれど、人間ってのは競争する遺伝子でももってるもんなのかな?
なんていうか、ここまで多様化すると競争することすら意味がなくって、共存する方法を作ることに対して本来労力をかけたほうがいいんじゃないかなーとか思ったりする一方で、金融なんていう、貨幣価値がくそなものを考えると、一方が一方をしいたげるシステムでありまた興味深い。
構築されたWebサービスがレビューされて実社会に出るまでのバッファ的レイヤーが必要なのではないか? 過去、それは高等教育以上の現場(高専・専門学校・大学・etc.)が担ってきた気がするが、今はぶっちゃけ大学やら学歴なんぞ関係ない。今やもう、Webの偉い人集団だの、はてな民だの、勉強会集団だのでその手の階層が出来上がる空気はちゃくちゃくと醸成されている。階層の上位陣は高学歴だろうけど、ま、もう少しだ。
問題はその階層に参加出来るか出来ないか、するかしないかで新たな格差が生まれる可能性があるということくらいだが、やっぱり住まいは大都市圏に近いほうが有利なのかな? そんなの関係ないよ! とか言うなら今すぐIT勉強会カレンダーの『懇親会込みの』年間イベント開催件数を生産年齢人口[単位:万人]で割ったヒストグラムを都道府県別で作成してみな。そのまんま『日本のIT民度温度差』が出てくるから、それを見てから判断しようじゃないか。
{kind=link}