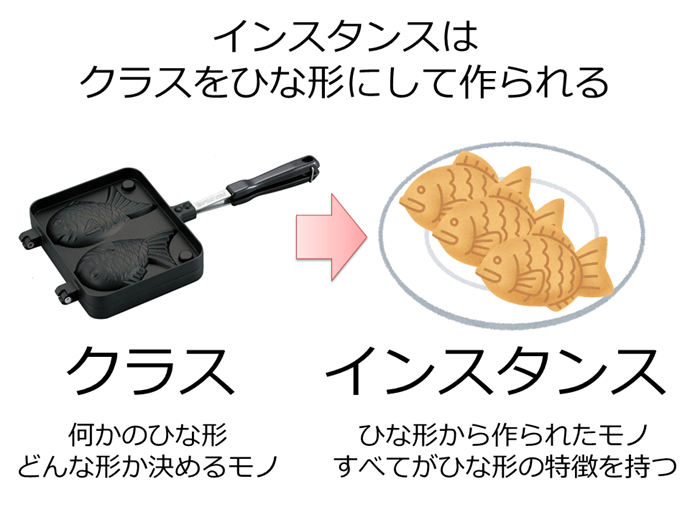
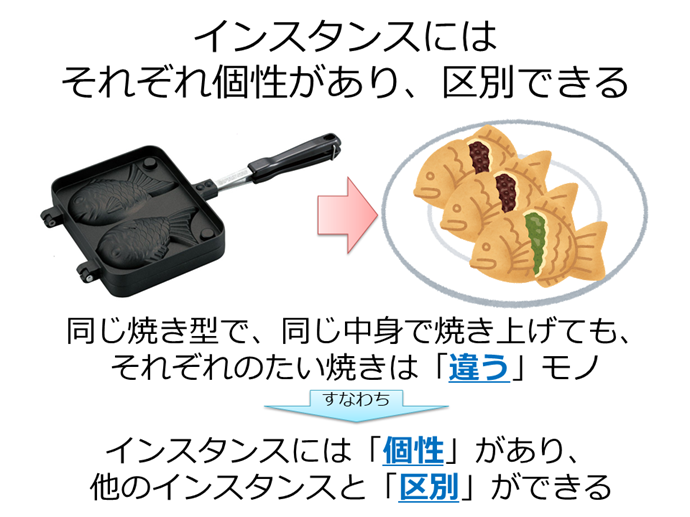
はてなキーワード: インスタンスとは
Google Cloud Platformで無料枠で最小インスタンスを使っているつもりで、2019年からやっていたのだけど、設定も一切変えていないはずなのに、2021年3月から急に課金がされていったぽい。
6637円+今月600=8237円
勉強代としてはそこそこ高いな。
泣きたい。 ;_;
クレカの総額だけ見て、明細をチェックしないで、無料枠だからと安心していたのがまずかった。
いきなりクレジットカードが使えなくなって、問い合わせしたら、不正利用されていたっぽい。
いったいどこから漏れたのかわけわからんが、知らない所で5万円の商品の購入があったみたいで、そんなの買っていないので、取り消しをして一件落着・・・なはずだった。
ただ、直近の課金の内容をオペレーターと1件ずつ確認していたんだけど、Google Cloudから529円請求がありますねと言われて、無料プランなのにそんな馬鹿なと思った。
今月だけではなく先月もあるし、先々月もあると。
おいおい嘘だろうって思った。
そして、ちゃんと調べてみると、上記のとおりの請求書がメールの山の中に埋もれていた。
2019年から利用してて、ずっと課金が発生していなかったので、無料プランの範囲だと信じていたので、確認がザルだった。
とりあえずサポートに何で2021/3から課金されているの?ってメールは送ったけど、回答はあまり期待していない。
お前らも注意しろよ。
横からだけどステートフルなプロトコルを使うとこは仕方なくインスタンス立てることあるよ
WebSocketとかWebRTCとか
そうしておけば、放置できる。自前で立てたマシンもインスタンスもないから落ちてるかどうかとか気にしなくてもいい。負荷も考えない。
負荷とか落ちてるとか(そんなに)気にしなくていいのでは・・・
★★再追記
レンタルサーバは、自由度が低くてストレスになるからやらない。SQLでwith使いたいからMySQL8をって言ってもさくらレンタルサーバじゃ無理なんでしょ? あと同居利用者のせいで高負荷ってのも避けたい。そこを気にしない人はレンタルサーバでいいと思うよ。
あと LB $0.025/h だった。月2000円くらいか。
★追記
LBは独自ドメイン+自動更新無料SSL証明書のためね。Cloud Storageの無味乾燥なドメインでいいなら、SSL自動かつ無料でほんとに月数円。
-------
もうねめんどくさいんだわ。もちろん以前はそうやってたよ。
PHPだのApacheだのMySQLだのインストールしたり設定ファイル置いたり、
脆弱性対応したり、SSL証明書更新したり、一応落ちてないか無料監視サービス使ったり。
でも仕事ならともかく、趣味だからこそこんなことやりたくないじゃん。
なので、コンテンツは Cloud Storage に置く。
Cloud Load Balancing も使う (無料 SSL 証明書のために)。
動的部分は Cloud Functions で。
AWS なら S3+ALB+Cognito+Lambda だな。
そうしておけば、放置できる。自前で立てたマシンもインスタンスもないから落ちてるかどうかとか気にしなくてもいい。負荷も考えない。クラウド様がよきにはからってくれるさ。たまにクラウド障害あるかもしれないけど、Google なり AWS なりが頑張って直してくれる。
って感じ。
ちなみにこちらは 1日数十アクセスの過疎サイト。独自ドメイン+自動SSL証明書にするための Cloud Load Balancing に 4000円くらい払ってる。それがなければ月数円。
ワイの一番古い増田はDHCP理解してないマン宛のトラバやったで
2018-08-14 anond:20180814213814
Radius も Active Directory も無い世界線どころか、DHCPサーバ側でMACアドレスとIPアドレスの組み合わせを予約しておくことすらできない世界線の増田
最近でも Azure AD なんか導入している企業ないマン、Microsoft365 や Google Workspace は存在しない+それらと連携させるセキュリティプロダクトは存在しないマン、
AWS や VM や Dockerが存在しない世界線マン、AWS で起動テンプレートを作らないインスタンスを複製しないマン、Debianと契約するマン、
Linus Torvalds を知らないマン、資産管理の意味が理解できないマン、フリーデスクの基本的な運用を知らないマン、基幹システムにアクセスしないマン、
Teamsなどのコミュニケーションツールが存在しない世界線マン、今時は Teams などのコラボレーションプラットフォームに内線を統一する流れなのに
一昔前の BYOD で個人の携帯にアプリで内線を割り当てるどころか固定電話を廃止して携帯定額通話でドヤ顔マン、ユニコーン企業で働いてる設定なのにお局云々マン、
AWSで年収1000万余裕マン+AWSについての歴史改変マン、既存の不正検知AIプラットフォームは使用せず依頼を受けてサイゲ参考に不正検出システムを作ったマン、
Pythonは仕事は無いマン・・・・・ほか、上げたらキリがないんだわ
とりあえず、時が止まり過ぎ+IT業界に妙な憧れがあることだけは伝わる
因みになんだがこれやってるのすべて同じ増田なんじゃ無いか?って思ってるよ。文字が文字通り読めない増田
もちろん、だからといって、増田に書き込んじゃダメってことは一切ない。今まで通り好きなこと書いたらいい
その自覚さえあれば、在りし日のVIPがみんなニートという体だったのと同じく、
ワイも増田も
MMMO (M 無教養で M 無能で M 無収入な O オタク) か
まずは、日立のサーバーでのWindows Server 2022への対応からお聞きした。
木村: サーバーにはHA8000VとRV3000の2ラインアップがあります。HA8000VがPCサーバーで、汎用的なサーバーとして、エントリー向けや、HCI、VDIのソリューションなど、いろいろな用途で使われています。RV3000はミッションクリティカル向けです。Windows Server 2022のプレインストール対応は、HA8000Vの全機種で2022年5月を予定しています。
Windowsサーバー市場における日立の強みとして、木村氏は、サポート力を挙げる。
木村: 日立は長年に渡ってプラットフォーム製品の開発を行ってきました。作ってきたからこそ、中身がわかっている技術力があります。できることとできないことを技術者がわかっているので、障害が起きたときや問い合わせのときに、お客様に事実を真摯に伝え、重大な不具合があっても技術力で解決に向けていきます。何かあったときに問題をたらい回しにせず、技術力をコアにしてしっかり対応するサポート力が強みです。
こうした日立のDNAを結実させたサポート商品が「日立サポート360」だ。通常はサーバーのハードウェアからOS、ソフトウェアなどは、それぞれと契約し、サポートを受けることになる。日立サポート360ではこれらをワンストップで受け付け、支援することができる。
広瀬: 窓口が1つになるというのは他社でもありますが、そういう表面的な話だけではなく、複合的な力で問題解決支援にあたれるのが真の価値です。内部で、サーバーからOS、日立ミドルウェア、導入ミドルウェアなど、いろいろな製品の部門の連携がすごく濃密にされているからこそ、複合的な力で問題解決にあたれます。これが本当のワンストップの意味です。
この日立サポート360でWindows Server 2022のサポートにも対応する。日立では、長年のサポート実績により蓄積された技術力により高い自社解決率を誇るという。自社解決率が高ければ、それだけパートナーへのエスカレーションが減るわけで、短期間でのトラブル解決が期待できることになる。
日立のハイブリッドクラウドのソリューション「EverFlex from Hitachi」
木村氏は、日立のハイブリッドクラウド戦略としてEverFlex from Hitachi (以下、EverFlex)ソリューションを説明した。EverFlexは2021年10月にクラウドとのデータ連携ソリューションとして始まり、2022年2月にハイブリッドクラウドのソリューションとして強化された。
木村: お客様がオンプレミスとパブリッククラウドを使うときに、最適なシステム設計にして、コストも最適化していきます。ハイブリッドクラウドの導入には事前にアセスメントやコンサルティングを行うことが大切です。なぜなら、パブリッククラウドを導入することで負担が減るかと思われがちなのですが、ハイブリッド化されることで負担が増えることがあるからです。
EverFlexの特徴の中でも特に「クラウドライクなサービス提供」について木村氏は紹介した。
木村: ハイブリッドクラウドになると保守や運用が煩雑になります。パブリッククラウドとオンプレミスの両方を管理しなくてはならないため、システム管理において両方のノウハウが必要になります。このため保守・運用フェーズにおいて簡単化されずコスト最適化が課題となってきます。それを避けるために、共通化するニーズに応えるようにいろいろと工夫しています。
ハイブリッドクラウドソリューションEverFlex from Hitachi
まず、問い合わせをワンストップ化したり、運用管理を1つのツールで一元化したりすることで、顧客の負担を軽減する。
プラットフォームにおいては、オンプレミスからクラウド接続を可能にしてシームレスにお互いやりとりできるOSが各社ある。Windows Server 2022はまさにそれを特徴としており、同じくAzure Stack HCIも選択肢に入る。
さらに、支払い/利用形態についても、オンプレミスでも売り切りだけでなくフィー型も採用する。こうしたEverFlexの中でWindows Server 2022のユースケースを木村氏は2つ挙げた。
1つめは、運用管理の簡単化の部分で、Azure Portalからオンプレミスを管理できる機能の強化だ。
木村: オンプレミスにエージェントを入れておけば、管理者がAzure Portalだけをさわって、オンプレミスのリソースやイベントの管理も全て一元化できます。これに期待しています。
もう1つはセキュリティの強化だ。
木村: ハイブリッド化が進むと、両方の基盤をネットワークで接続することになります。従来には存在していなかった接続となるため、その部分でセキュリティの強化も進めなければなりません。そこでWindows Server 2022では、Secured-core ServerによってOSそのもののセキュリティレベルが上がっています。TPMと連動する機能によってハードからOSのレイヤーを守り、マルチレイヤーでセキュリティを強化しています。
そのほかにもクラウドライクの取り組みとして2つを木村氏は紹介した。
1つめは「サーバ予備リソース提供サービス」。サーバーを余分に設置し、支払いは電源を入れて使った月だけ発生するというサービスだ。
木村: 迅速でタイムリーにリソースを増強したいときに、クラウドなら自由に構成を変えられます。それをオンプレミスでもできるようにします。クラウドではインスタンス単位となり、ハードウェアの構成はメニューの中から選択することになりますが、オンプレミスでは構成を自由に組む事ができます。まずHCIソリューションから開始しましたが、2022年4月からはそれ以外にも拡大する予定です。
もう1つが「ハードウェア安定稼働支援サービス」。オンプレミス環境のサーバー運用管理を省力化するものだ。
木村: 旧来の保守では、ファームウェアのバージョンアップがあると、技術的にどういう影響があるかを確認して、その都度適用するかどうかを判断する必要がありました。それを提供元が判断するのがこのサービスです。お客様の機器を弊社で管理して、ファームウェアの推奨バージョンの選定や、更新作業などを一括でやります。
サブスクリプションに力を入れる
日立のこれからの注力分野について木村氏は、サブスクリプションに力を入れていくと語った。
木村: 全社的な方針で、サブスクリプションに力を入れていきます。クラウド化で初期投資をおさえるニーズと同時に、オンプレミスも求められています。そうしたお客様のニーズにアラインしていきます。
サブスクリプションやクラウドライクなサービスで管理を簡単にして顧客企業がコストを抑えることで、究極的な目的はその先のDXだと木村氏は語る。
木村: 既存のプラットフォームのコストを最適化させ、浮かせた費用を新たな投資先として、AIやEdgeを活用する新たなデジタルソリューションの領域に向けていくことを支援していきたいと考えています。
そのために木村氏は、よりハイブリッドで使いやすいようなライセンス体系をマイクロソフトに期待している。
木村: 今後ハイブリッド化が進むと、繁忙期にリソースを拡張するといったこともあります。そのときにライセンスが、オンプレミスはオンプレミスで買って、AzureはAzureで課金してと、ハイブリッドで使いづらい体系になっています。将来的にライセンス体系を統一するなど、両方の基盤で使えるような体系になることを期待しています。
また、Azure Portalからオンプレミスを管理できる機能についても、さらなる強化を木村氏は期待する。
木村: Azure Portalからは管理できる範囲に限りがあります。OSから上のリソースやイベントは監視できるのですが、ハードウェアの死活監視や電源管理などは対応していないため、JP1やその他のツールなど、複数のツールを使いこなす必要があります。それらの管理ツールが乱立してしまうと、また管理の手間が増えてしまう。こういったことをオンプレのツールか、Portal側で統一することも期待したいところです。
やあ、
https://anond.hatelabo.jp/20220226180821 の元増田だよ。
安酒飲んだ勢いで適当に書いた「はてブプレミアム」案への各種感想ありがとう。
更に上位の「はてなブックマークプラチナム」案も思いついたからざっくり列挙するよ。
---
・弁護士特約プラチナム(訴訟案件年2回+発信者情報開示請求プロテクション年3回まで付与。専用カラースター購入のち充当で回数復活)
・はてな匿名ダイアリープラチナム(プレミアムの特典全部+専用サーバーで楽しく匿名日記)
・はてブTor(プラチナムな達人向けの試験機能。情報セキュリティに興味はある? はてなidと強固に結びついたセキュアかつサクサクのTor鯖を使いこなそう!)
・はてブ丼(プラチナムなあなただけのMastodonインスタンスで他のユーザーと差を付けよう! ※一部の単文トゥートは自動的に公開状態でブクマされ、一部の長文トゥートは匿名ダイアリーに自動的に投稿されます)
・はてブ電話(※物理SIMのみ数量限定先着順。ブックマークサービスなのに電話番号が貰える!? そう、プラチナムならね)
・eはてブ電話(↑のeSIM限定版。ブックマークサービスなのに以下略)
・はてブ自警団(はてブヘビーユーザー待望の自警機能。利用規約違反かつ人倫にもとるブコメを投票で非表示にしよう! 自警ランキングもサービス開始と同時に公開。自警上位10アカウントにはなにかいい事あるかも?)
--
この本は5章まであるが、4章と5章はハンズオンであるため、文字としてまとめるのは1から3章に留める。
1章
【コンテナとは】
他のプロセスとは隔離された状態でOS上にソフトウェアを実行する技術
コンテナにはアプリの稼働に必要となるランタイムやライブラリを1つのパッケージとして全て含めることができる。そうすることでアプリの依存関係をすべてコンテナ内で完結できる。
全ての依存関係がコンテナ内で完結するため、オンプレでもクラウドでも起動する。
ステージング環境でテスト済みのコンテナイメージをプロダクション環境向けに再利用することで、ライブラリ差異による環境ごとのテストに必要な工数を削減できる。
サーバー仮想化では、仮想マシンレベルでリソースを分離し、ゲストOS上でアプリが起動する。つまり、アプリだけでなく、ゲストOSを動かすためのコンピューティングリソースが必要。
一方コンテナは、プロセスレベルで分離されてアプリが稼働する。OSから見ると単に1つのプロセスが稼働している扱いになる。
【Dockerとは】
アプリをコンテナイメージとしてビルドしたり、イメージの取得や保存、コンテナの起動をシンプルに行える。
イメージ(アプリケーションと依存関係がパッケージングされる。アプリ、ライブラリ、OS)
レジストリに保存
【Dockerfileとは】
このファイルにコマンドを記述することで、アプリに必要なライブラリをインストールしたり、コンテナ上に環境変数を指定したりする。
1章まとめ、感想
コンテナの登場により、本番・開発環境ごとに1からサーバーを立ててコマンドや設定ファイルを正確に行い、環境差異によるエラーをつぶしていき...というこれまでの数々の労力を減らすことができるようになった。
2章
ECSとEKSがある。
オーケストレーションサービスであり、コンテナの実行環境ではない。
ECSの月間稼働率は99.99%であることがSLA として保証。
デプロイするコンテナイメージ、タスクとコンテナに割り当てるリソースやIAMロール、Cloud Watch Logsの出力先などを指定する。
指定した数だけタスクを維持するスケジューラーで、オーケストレータのコア機能にあたる要素。サービス作成時は起動するタスクの数や関連づけるロードバランサーやタスクを実行するネットワークを指定。
2種類ありECSとFargateがある。 Fargateに絞って書く
Fargateとは
コンテナ向けであるためEC2のように単体では使用できず、ECSかEKSで利用する
サーバーのスケーリング、パッチ適用、保護、管理にまつわる運用上のオーバーヘッドが発生しない。これにより、アプリ開発に専念できるようになる
・コンテナごとにENIがアタッチされるため、コンテナごとにIPが振られるため起動に若干時間がかかる
ECR
・App Runner
利用者がコードをアップロードするだけでコードを実行できるサービス。AWS側で基盤となるコンピューティングリソースを構築してくれるフルマネージドサービス。
App Runner
2021年5月にGA(一般公開)となったサービス。プロダクションレベルでスケール可能なwebアプリを素早く展開するためのマネージドサービス。Githubと連携してソースコードをApp Runnerでビルドとデプロイができるだけでなく、ECRのビルド済みコンテナイメージも即座にデプロイできる。
ECSとFargateの場合、ネットワークやロードバランシング、CI/CDの設定などインフラレイヤに関わる必要があり、ある程度のインフラ知識は必要になる。App Runnerはそれらインフラ周りをすべてひっくるめてブラックボックス化し、マネージドにしていることが特徴である。
ECS Fargateを利用した場合のコスト、拡張性、信頼性、エンジニアリング観点
【コスト】
EC2より料金は割高。ただし、年々料金は下がってきている。
【拡張性】
デプロイの速度 遅め
理由1 コンテナごとにENIが割り当てられるため。ENIの生成に時間がかかる
理由2. イメージキャッシュができないため。コンテナ起動時にコンテナイメージを取得する必要がある。
タスクに割り当てられるエフェメラルストレージは200GB。容量は拡張不可。ただし永続ストレージの容量が必要な場合はEFSボリュームを使う手もある。
割り当て可能リソースは4vCPUと30GB。機械学習に用いるノードのような大容量メモリを要求するホストとしては不向き
【信頼性】
Fargateへのsshログインは不可。Fargate上で起動するコンテナにsshdを立ててsshログインする方法もあるが、セキュアなコンテナ環境にsshの口を開けるのはリスキーである。他にSSMのセッションマネージャーを用いてログインする方法もあるが、データプレーンがEC2の時に比べると手間がかかる。
しかし、2021年3月にAmazon ECS Execが発表され、コンテナに対して対話型のシェルや1つのコマンドが実行可能となった。
Fargateの登場からしばらく経過し、有識者や経験者は増え、確保しやすい。
多数のユーザーに使ってもらう
CI/CDパイプラインを形成し、アプリリリースに対するアジリティを高める
各レイヤで適切なセキュリティ対策(不正アクセス対策、認証データの適切な管理、ログ保存、踏み台経由の内部アクセス)を施したい
2章まとめ、感想
AWSが提供するコンテナサービスにはいくつかあり、なかでもFargateというフルマネージドなデータプレーンがよく使われている。ホスト管理が不要でインフラ関連の工数を削減できる一方、EC2より料金が高く、起動に若干時間がかかるのが難点である。
3章
この章では運用設計、ロギング設計、セキュリティ設計、信頼性設計、パフォーマンス設計、コスト最適化設計について述べている。
Fargate利用時のシステム状態を把握するためのモニタリングやオブザーバビリティに関する設計、不具合修正やデプロイリスク軽減のためのCI/CD設計が必要である。
モニタリングとは
システム内で定めた状態を確認し続けることであり、その目的はシステムの可用性を維持するために問題発生に気づくこと
オブザーバビリティとは
オブザーバビリティの獲得によって、原因特定や対策の検討が迅速に行えるようになる
・cloud watch logs
・Firelens
AWS以外のサービスやAWS外のSaaSと連携することも可能
Firehoseを経由してS3やRed shift やOpenSearch Serviceにログを転送できる
fluent bitを利用する場合、AWSが公式に提供しているコンテナイメージを使用できる
- ソフトウェアやライブラリの脆弱性は日々更新されており、作ってから時間が経ったイメージは脆弱性を含んでいる危険がある。
- 方法
脆弱性の有無はECRによる脆弱性スキャン、OSSのtrivyによる脆弱性スキャン
継続的かつ自動的にコンテナイメージをスキャンする必要があるため、CI/CDに組み込む必要がある。しかし頻繁にリリースが行われないアプリの場合、CICDパイプラインが実行されず、同時にスキャンもなされないということになるため、定期的に行うスキャンも必要になる。
cloud watch Eventsから定期的にLambdaを実行してECRスキャンを行わせる(スキャン自体は1日1回のみ可能)
Fargateの場合、サービス内部のスケジューラが自動でマルチAZ構成を取るため、こちらで何かする必要はない。
・障害時切り離しと復旧
ECSはcloud watchと組み合わせることでタスク障害やアプリのエラーを検知できるうえに、用意されてるメトリクスをcloud watchアラームと結びつけて通知を自動化できる
ALBと結びつけることで、障害が発生したタスクを自動で切り離す
AWS内部のハードウェア障害や、セキュリティ脆弱性があるプラットフォームだと判断された場合、ECSは新しいタスクに置き換えようとするその状態のこと。
Fargateの場合、アプリはSIGTERM発行に対して適切に対処できる設定にしておかなくてはならない。そうしておかないとSIGKILLで強制終了されてしまう。データ不整合などが生じて危険。
ALBのリスナールールを変更し、コンテンツよりもSorryページの優先度を上げることで対処可能
自動でクォータは引き上がらない
cloud watch メトリクスなどで監視する必要がある。
パフォーマンス設計で求められることは、ビジネスで求められるシステムの需要を満たしつつも、技術領域の進歩や環境の変化に対応可能なアーキテクチャを目指すこと
利用者数やワークロードの特性を見極めつつ、性能目標から必要なリソース量を仮決めする
FargateはAutoscalingの利用が可能で、ステップスケーリングポリシーとターゲット追跡スケーリングポリシーがある。どちらのポリシー戦略をとるかを事前に決める
既存のワークロードを模倣したベンチマークや負荷テストを実施してパフォーマンス要件を満たすかどうかを確認する
・スケールアウト
サーバーの台数を増やすことでシステム全体のコンピューティングリソースを増やそうとする概念。可用性と耐障害性が上がる。既存のタスクを停止する必要は原則ない。
スケールアウト時の注意
・Fargate上のECSタスク数の上限はデフォルトでリージョンあたり1000までであること。
ECSタスクごとにENIが割り当てられ、タスク数が増えるごとにサブネット内の割当可能なIPアドレスが消費されていく
Application Autoscaling
Cloud Watchアラームで定めたメトリクスの閾値に従ってスケールアウトやスケールインを行う
CPU使用率が60~80%ならECSタスク数を10%増加し、80%以上なら30%増加する、という任意のステップに従ってタスク数を増減させる
指定したメトリクスのターゲット値を維持するようなにスケールアウトやスケールインを制御する方針
--
この本は5章まであるが、4章と5章はハンズオンであるため、文字としてまとめるのは1から3章に留める。
1章
【コンテナとは】
他のプロセスとは隔離された状態でOS上にソフトウェアを実行する技術
コンテナにはアプリの稼働に必要となるランタイムやライブラリを1つのパッケージとして全て含めることができる。そうすることでアプリの依存関係をすべてコンテナ内で完結できる。
全ての依存関係がコンテナ内で完結するため、オンプレでもクラウドでも起動する。
ステージング環境でテスト済みのコンテナイメージをプロダクション環境向けに再利用することで、ライブラリ差異による環境ごとのテストに必要な工数を削減できる。
サーバー仮想化では、仮想マシンレベルでリソースを分離し、ゲストOS上でアプリが起動する。つまり、アプリだけでなく、ゲストOSを動かすためのコンピューティングリソースが必要。
一方コンテナは、プロセスレベルで分離されてアプリが稼働する。OSから見ると単に1つのプロセスが稼働している扱いになる。
【Dockerとは】
アプリをコンテナイメージとしてビルドしたり、イメージの取得や保存、コンテナの起動をシンプルに行える。
イメージ(アプリケーションと依存関係がパッケージングされる。アプリ、ライブラリ、OS)
レジストリに保存
【Dockerfileとは】
このファイルにコマンドを記述することで、アプリに必要なライブラリをインストールしたり、コンテナ上に環境変数を指定したりする。
1章まとめ、感想
コンテナの登場により、本番・開発環境ごとに1からサーバーを立ててコマンドや設定ファイルを正確に行い、環境差異によるエラーをつぶしていき...というこれまでの数々の労力を減らすことができるようになった。
2章
ECSとEKSがある。
オーケストレーションサービスであり、コンテナの実行環境ではない。
ECSの月間稼働率は99.99%であることがSLA として保証。
デプロイするコンテナイメージ、タスクとコンテナに割り当てるリソースやIAMロール、Cloud Watch Logsの出力先などを指定する。
指定した数だけタスクを維持するスケジューラーで、オーケストレータのコア機能にあたる要素。サービス作成時は起動するタスクの数や関連づけるロードバランサーやタスクを実行するネットワークを指定。
2種類ありECSとFargateがある。 Fargateに絞って書く
Fargateとは
コンテナ向けであるためEC2のように単体では使用できず、ECSかEKSで利用する
サーバーのスケーリング、パッチ適用、保護、管理にまつわる運用上のオーバーヘッドが発生しない。これにより、アプリ開発に専念できるようになる
・コンテナごとにENIがアタッチされるため、コンテナごとにIPが振られるため起動に若干時間がかかる
ECR
・App Runner
利用者がコードをアップロードするだけでコードを実行できるサービス。AWS側で基盤となるコンピューティングリソースを構築してくれるフルマネージドサービス。
App Runner
2021年5月にGA(一般公開)となったサービス。プロダクションレベルでスケール可能なwebアプリを素早く展開するためのマネージドサービス。Githubと連携してソースコードをApp Runnerでビルドとデプロイができるだけでなく、ECRのビルド済みコンテナイメージも即座にデプロイできる。
ECSとFargateの場合、ネットワークやロードバランシング、CI/CDの設定などインフラレイヤに関わる必要があり、ある程度のインフラ知識は必要になる。App Runnerはそれらインフラ周りをすべてひっくるめてブラックボックス化し、マネージドにしていることが特徴である。
ECS Fargateを利用した場合のコスト、拡張性、信頼性、エンジニアリング観点
【コスト】
EC2より料金は割高。ただし、年々料金は下がってきている。
【拡張性】
デプロイの速度 遅め
理由1 コンテナごとにENIが割り当てられるため。ENIの生成に時間がかかる
理由2. イメージキャッシュができないため。コンテナ起動時にコンテナイメージを取得する必要がある。
タスクに割り当てられるエフェメラルストレージは200GB。容量は拡張不可。ただし永続ストレージの容量が必要な場合はEFSボリュームを使う手もある。
割り当て可能リソースは4vCPUと30GB。機械学習に用いるノードのような大容量メモリを要求するホストとしては不向き
【信頼性】
Fargateへのsshログインは不可。Fargate上で起動するコンテナにsshdを立ててsshログインする方法もあるが、セキュアなコンテナ環境にsshの口を開けるのはリスキーである。他にSSMのセッションマネージャーを用いてログインする方法もあるが、データプレーンがEC2の時に比べると手間がかかる。
しかし、2021年3月にAmazon ECS Execが発表され、コンテナに対して対話型のシェルや1つのコマンドが実行可能となった。
Fargateの登場からしばらく経過し、有識者や経験者は増え、確保しやすい。
多数のユーザーに使ってもらう
CI/CDパイプラインを形成し、アプリリリースに対するアジリティを高める
各レイヤで適切なセキュリティ対策(不正アクセス対策、認証データの適切な管理、ログ保存、踏み台経由の内部アクセス)を施したい
2章まとめ、感想
AWSが提供するコンテナサービスにはいくつかあり、なかでもFargateというフルマネージドなデータプレーンがよく使われている。ホスト管理が不要でインフラ関連の工数を削減できる一方、EC2より料金が高く、起動に若干時間がかかるのが難点である。
3章
この章では運用設計、ロギング設計、セキュリティ設計、信頼性設計、パフォーマンス設計、コスト最適化設計について述べている。
Fargate利用時のシステム状態を把握するためのモニタリングやオブザーバビリティに関する設計、不具合修正やデプロイリスク軽減のためのCI/CD設計が必要である。
モニタリングとは
システム内で定めた状態を確認し続けることであり、その目的はシステムの可用性を維持するために問題発生に気づくこと
オブザーバビリティとは
オブザーバビリティの獲得によって、原因特定や対策の検討が迅速に行えるようになる
・cloud watch logs
・Firelens
AWS以外のサービスやAWS外のSaaSと連携することも可能
Firehoseを経由してS3やRed shift やOpenSearch Serviceにログを転送できる
fluent bitを利用する場合、AWSが公式に提供しているコンテナイメージを使用できる
- ソフトウェアやライブラリの脆弱性は日々更新されており、作ってから時間が経ったイメージは脆弱性を含んでいる危険がある。
- 方法
脆弱性の有無はECRによる脆弱性スキャン、OSSのtrivyによる脆弱性スキャン
継続的かつ自動的にコンテナイメージをスキャンする必要があるため、CI/CDに組み込む必要がある。しかし頻繁にリリースが行われないアプリの場合、CICDパイプラインが実行されず、同時にスキャンもなされないということになるため、定期的に行うスキャンも必要になる。
cloud watch Eventsから定期的にLambdaを実行してECRスキャンを行わせる(スキャン自体は1日1回のみ可能)
Fargateの場合、サービス内部のスケジューラが自動でマルチAZ構成を取るため、こちらで何かする必要はない。
・障害時切り離しと復旧
ECSはcloud watchと組み合わせることでタスク障害やアプリのエラーを検知できるうえに、用意されてるメトリクスをcloud watchアラームと結びつけて通知を自動化できる
ALBと結びつけることで、障害が発生したタスクを自動で切り離す
AWS内部のハードウェア障害や、セキュリティ脆弱性があるプラットフォームだと判断された場合、ECSは新しいタスクに置き換えようとするその状態のこと。
Fargateの場合、アプリはSIGTERM発行に対して適切に対処できる設定にしておかなくてはならない。そうしておかないとSIGKILLで強制終了されてしまう。データ不整合などが生じて危険。
ALBのリスナールールを変更し、コンテンツよりもSorryページの優先度を上げることで対処可能
自動でクォータは引き上がらない
cloud watch メトリクスなどで監視する必要がある。
パフォーマンス設計で求められることは、ビジネスで求められるシステムの需要を満たしつつも、技術領域の進歩や環境の変化に対応可能なアーキテクチャを目指すこと
利用者数やワークロードの特性を見極めつつ、性能目標から必要なリソース量を仮決めする
FargateはAutoscalingの利用が可能で、ステップスケーリングポリシーとターゲット追跡スケーリングポリシーがある。どちらのポリシー戦略をとるかを事前に決める
既存のワークロードを模倣したベンチマークや負荷テストを実施してパフォーマンス要件を満たすかどうかを確認する
・スケールアウト
サーバーの台数を増やすことでシステム全体のコンピューティングリソースを増やそうとする概念。可用性と耐障害性が上がる。既存のタスクを停止する必要は原則ない。
スケールアウト時の注意
・Fargate上のECSタスク数の上限はデフォルトでリージョンあたり1000までであること。
ECSタスクごとにENIが割り当てられ、タスク数が増えるごとにサブネット内の割当可能なIPアドレスが消費されていく
Application Autoscaling
Cloud Watchアラームで定めたメトリクスの閾値に従ってスケールアウトやスケールインを行う
CPU使用率が60~80%ならECSタスク数を10%増加し、80%以上なら30%増加する、という任意のステップに従ってタスク数を増減させる
指定したメトリクスのターゲット値を維持するようなにスケールアウトやスケールインを制御する方針
{kind=link}
{kind=link}