はてなキーワード: トランスフォーマーとは
私は以前、AGIへの短期的なタイムラインには懐疑的だった。その理由のひとつは、この10年を優遇し、AGI確率の質量を集中させるのは不合理に思えたからである(「我々は特別だ」と考えるのは古典的な誤謬のように思えた)。私は、AGIを手に入れるために何が必要なのかについて不確実であるべきであり、その結果、AGIを手に入れる可能性のある時期について、もっと「しみじみとした」確率分布になるはずだと考えた。
しかし、私は考えを変えました。決定的に重要なのは、AGIを得るために何が必要かという不確実性は、年単位ではなく、OOM(有効計算量)単位であるべきだということです。
私たちはこの10年でOOMsを駆け抜けようとしている。かつての全盛期でさえ、ムーアの法則は1~1.5OOM/10年に過ぎなかった。私の予想では、4年で~5OOM、10年で~10OOMを超えるだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/this_decade_or_bust-1200x925.png
要するに、私たちはこの10年で1回限りの利益を得るための大規模なスケールアップの真っ只中にいるのであり、OOMsを通過する進歩はその後何倍も遅くなるだろう。もしこのスケールアップが今後5~10年でAGIに到達できなければ、AGIはまだまだ先の話になるかもしれない。
つまり、今後10年間で、その後数十年間よりも多くのOOMを経験することになる。それで十分かもしれないし、すぐにAGIが実現するかもしれない。AGIを達成するのがどれほど難しいかによって、AGI達成までの時間の中央値について、あなたと私の意見が食い違うのは当然です。しかし、私たちが今どのようにOOMを駆け抜けているかを考えると、あなたのAGI達成のモーダル・イヤーは、この10年かそこらの後半になるはずです。
マシュー・バーネット(Matthew Barnett)氏は、計算機と生物学的境界だけを考慮した、これに関連する素晴らしい視覚化を行っている。
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
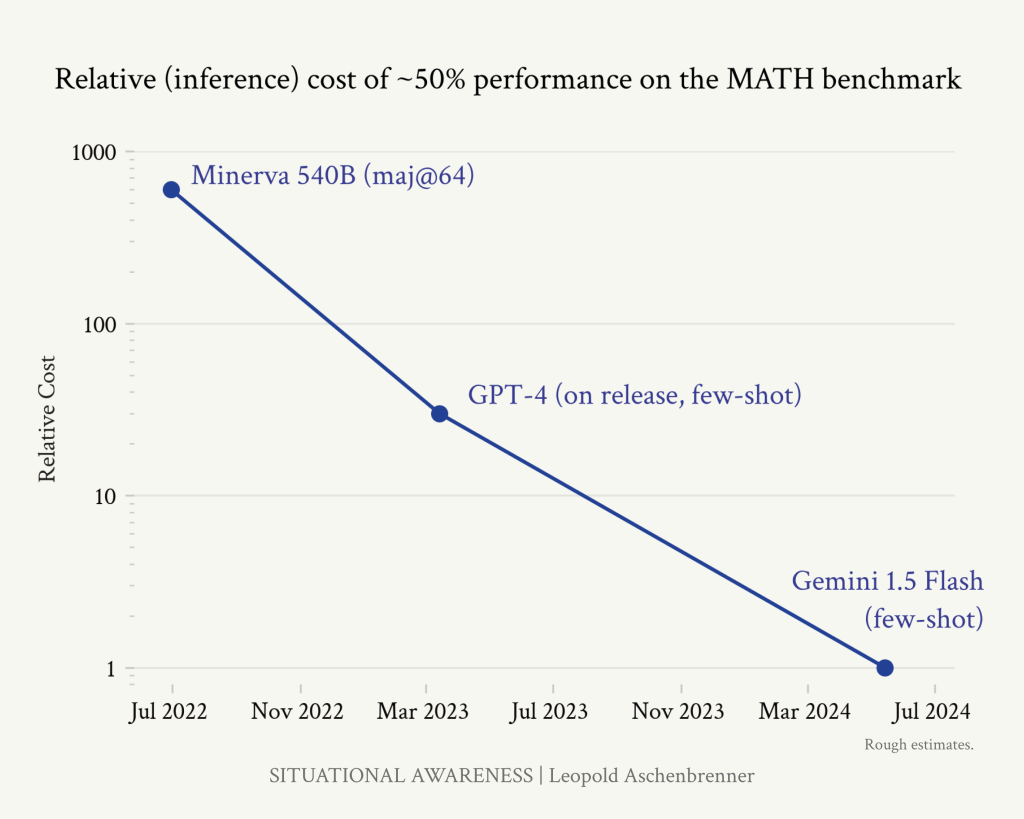
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
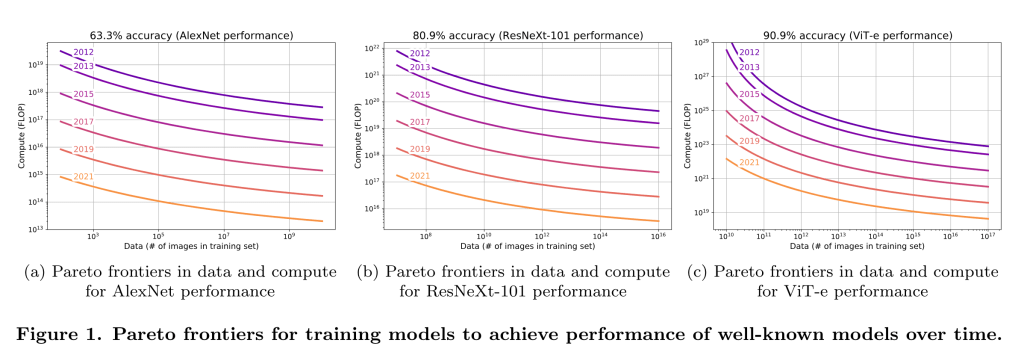
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
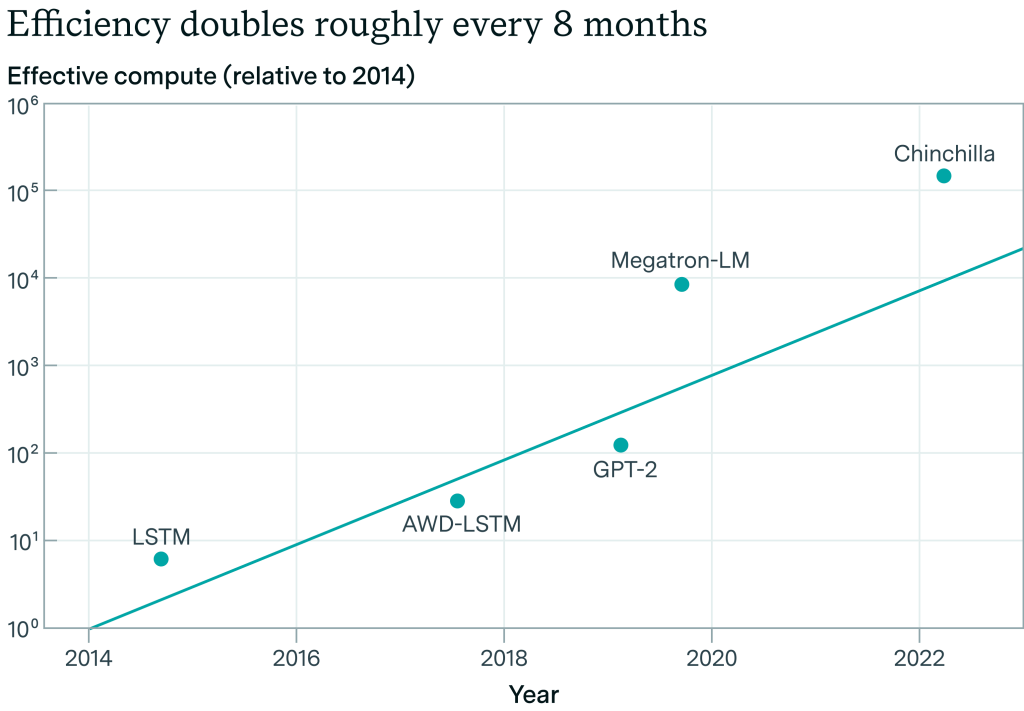
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
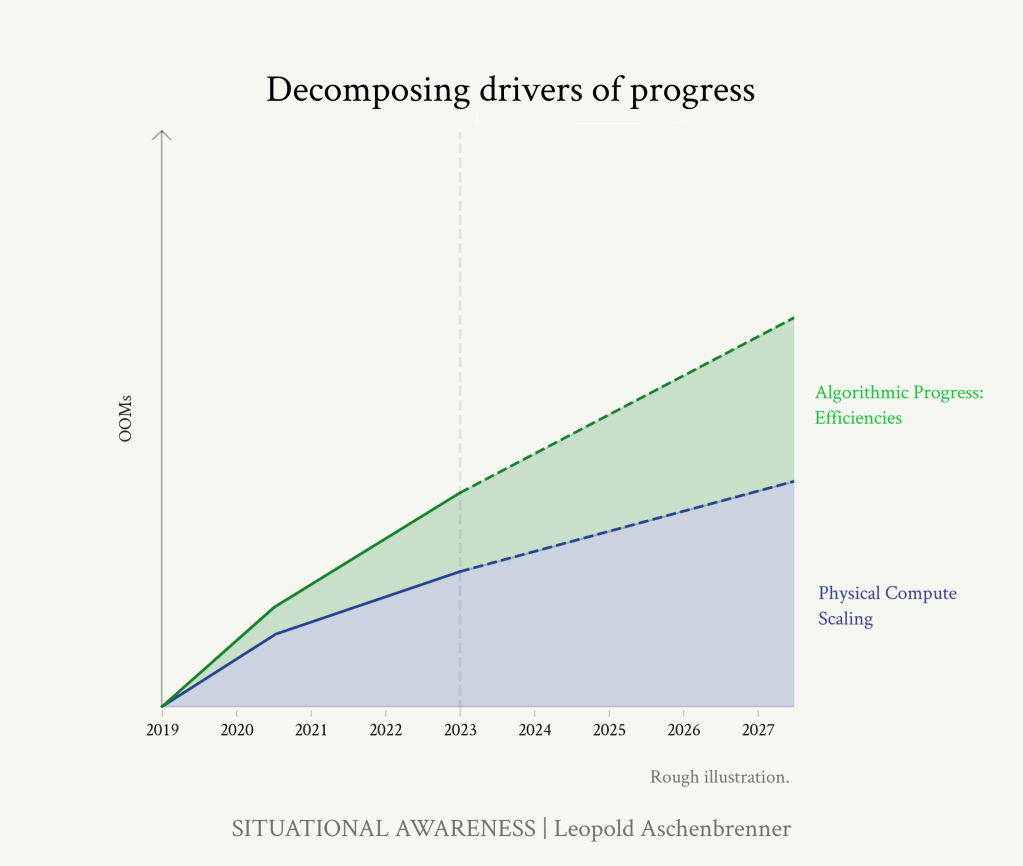
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
スターウォーズ「田舎者の平凡な若者だと思ったら実は最強のジェダイの息子でした」←なろうじゃん
ハリー・ポッター「いじめられっ子だと思ったら実はスゴい魔法使いでした」
ターミネーター「ただのウェイトレスだと思ったら実は救世主の母親でした」←なろうじゃん
タイタニック「運良く豪華客船になったら上流階級の美女に惚れられました」←なろうじゃん
バック・トゥ・ザ・フーチュー「いじめられっ子だけど未来から来た息子に助けられて成功者になりました」←なろうじゃん
スパイダーマン「陰キャだけどクモに噛まれたら超能力手に入れました」←なろうじゃん
スーパーマン「普段は陰キャだけど実は最強のスーパーヒーローです」←なろうじゃん
ジョーカー「ワープアでガイジのオッサンが社会変えちゃいます」←なろうじゃん
トランスフォーマー「陰キャが中古車買ったら金属兵器でした」←なろうじゃん
ゴジラ「孤島暮らしだけど核兵器の力でパワーアップします」←なろうじゃん
ロード・オブ・ザ・リング「ちびのホビットだけど最強のチート指輪を手に入れました」←なろうじゃん
ファウスト「悪魔の力でいろんな冒険しちゃいます」←なろうじゃん
ドン・キホーテ「田舎のジジイだと思ったら実は騎士でした」←なろうじゃん
アラジンと魔法のランプ「貧乏人が魔神の力でお姫様と結婚しちゃいます」←なろうじゃん
ブレーメンの音楽隊「無能が悪党成敗して幸せになります」←なろうじゃん
タイムマシン「馬鹿な未来人相手にマウント取ります。そして美少女に惚れられます」←なろうじゃん
ガンダム「陰キャだけど親父が設計した最強の平気で無双します」←なろうじゃん
ジョジョ「ただの学生だと思ったら実は超能力持ちでした」←なろうじゃん
Fate「平凡な高校生だけど最強の英霊召喚しました」←なろうじゃん
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}