はてなキーワード: HBMとは
未だに「謎の半導体メーカー」程度の認識の方になぜNVIDIAが時価総額世界4位なのかをあれこれ説明する必要があるので短めにメモ。半導体業界のすみっこの人間なので機械学習まわりの説明は適当です
・~1993年 AI冬の時代。エージェントシステムがさほど成果を挙げられなかったり。まだ半導体やメモリの性能は現代とくらべてはるかに劣り、現代のような大規模データを用いた統計的処理など考えられなかった。2006年のディープラーニングの発明まで実質的な停滞は続く。
・1995年 NVIDIAが最初のグラフィックアクセラレータ製品NV1を発売。
・1999年 NVIDIAがGeForce 256発売。GPUという名が初めて使われる。以降、NVIDIAはGPU業界1位の座を守り続ける。
・2006年 GPGPU向け開発基盤CUDAを発表。以降、その並列計算に特化した性能を大規模コンピューティングに活用しようという動きが続く。
・2006年 ディープラーニングの発明。のちのビッグデータブームに乗り、これまでよりはるかに高性能なAIを模索する動きが始まる(第3次AIブームのおこり)
・2006年 CPU業界2位のAMDがGPU業界2位のATIを買収、チップセットにGPUを統合することで事実上自社製品をNVIDIAと切り離す戦略に出る。CPU業界1位のインテルも、同じく自社CPUに自社製GPUを統合する動きを強める。NVIDIAはこれまでの主力だったGPUチップセット製品の販売を終了し、データセンター向けGPGPUのTeslaシリーズ、ゲーム用外付けGPUのGeForceシリーズ、ARM系CPUと自社GPUを統合したTegraシリーズの3製品に整理する。このうちTeslaシリーズが性能向上やマイクロアーキテクチャ変更を経て現代のAIサーバ製品に直接つながる。GeForceシリーズはゲーマー向け需要や暗号通貨マイニング向け需要も取り込み成長。Tegraシリーズは後継品がNintendoSwitchに採用される。
・2012年 ディープラーニングが画像認識コンテストで圧倒的な成績を収め、実質的な第3次AIブームが始まる。
・2017年 Transformerモデル発表。これまでのNN・DLと異なり並列化で性能を上げるのが容易=デカい計算機を使えばAIの性能が上がる時代に突入。
・2018年 IBMがNVIDIAと開発した「Summit」がスパコン世界ランキング1位の座を5年ぶりに中国から奪還。全計算のうち96%がGPUによって処理され、HPC(ハイパフォーマンスコンピューティング)におけるGPUの地位は決定的になる。NVIDIAの開発したCPU-GPU間の高速リンク「NVLink」が大規模に活用される。「Summit」は2020年に「富岳」にトップを奪われるまで1位を維持。
・2018~2021年 BERTやXLNet、GPT2など大規模言語モデルの幕開け。まだ研究者が使うレベル。
・2019年 NVIDIA CEOジェスン・ファン(革ジャンおぢ)が「ムーアの法則は終わった」と見解を表明。半導体のシングルスレッド性能の向上は限界に達し、チップレットを始めとした並列化・集積化アーキテクチャ勝負の時代に入る。
・2022年 NVIDIAがH100発表。Transformerモデルの学習・推論機能を大幅に強化したサーバ向けGPUで、もはや単体でもスパコンと呼べる性能を発揮する。H100はコアチップGH100をTSMC N4プロセスで製造、SK Hynix製HBMとともにTSMC CoWoSパッケージング技術で集積したパッケージ。※N4プロセスは最新のiPhone向けSoCで採用されたN3プロセスの1つ前の世代だが、サーバ/デスクトップ製品向けプロセスとモバイル製品向けプロセスはクロックや電流量が異なり、HPC向けはN4が最新と言ってよい。
・2022年 画像生成AIブーム。DALL-E2、Midjourney、Stable Diffusionなどが相次いで発表。
・2022年 ChatGPT発表。アクティブユーザ1億人達成に2カ月は史上最速。
・2023年 ChatGPT有料版公開。Microsoft Copilot、Google Bard(Gemini)など商用化への動きが相次ぐ。各企業がNVIDIA H100の大量調達に動く。
・2024年 NVIDIAが時価総額世界4位に到達。半導体メーカー売上ランキング世界1位達成(予定)。
こうして見るとNVIDIAにとっての転換点は「ディープラーニングの発明」「GPGPU向けプログラミング環境CUDAの発表」「チップセットの販売からコンピューティングユニットの販売に転換」という3つが同時に起こった2006年であると言えそう。以降、NVIDIAはゲーマー向け製品やモバイル向け製品を販売する裏で、CUDAによってGPGPUの独占を続け、仮装通貨マイニングやスパコンでの活躍と言ったホップステップを経て今回の大きな飛躍を成し遂げた、と綺麗にまとめられるだろう。
Web見るくらいだと性能有り余るけど、他になにかしようとすると性能が足りない。
CPUはコア数増やしても、ソフトが使いこなせないのか余ってるわりに遅い。
PythonばかりになってCで書かれたのを叩かない限り遅い。
AIじゃなくてもRPAが速くなれば多くの人に恩恵があるはずなのに遅い。
GPUは普及しても結局使いこなしが難しい。
コンパイルは未だに大規模になると遅い。リンカーは速くなったみたいだが。
M.2 SSDで速くなったというが、フラッシュそのものの速度は上がっておらずキャッシュのRAMが効いてるだけ。
DDR5はベンチマークでしか効果がなく、DDR4と実アプリじゃ変わらない。
Apple M2 Ultraは2つ同じチップを2つ繋げていたけど、
動画のエンコードを大量に抱える人以外には持て余すようなものだった。
M2の片側はGPUコアを主にして、GPUコア側の3辺に対してGDDRを置く方が良いのではないか。
① CPUコア +GPUコア(最小限)+動画エンコーダなど+DDRメモリ
ゲームだとステージが変わらないと同じシーンは同じテクスチャを使い回せるので、GPU側のキャッシュ効果が効くが、
機械学習で80GBのモデル全部のメモリーアドレス空間を走査していく場合は、キャッシュヒットしなくなる。
(メモリーアクセスの遅延を吸収するだけのバッファのサイズ分は意味はあるはずだが)
CPUのクロックは微妙に速くなっているがシングルコアの性能はほぼ変わらない。
マルチコアになったとして、ThreadripperのようにIOダイを使って大きくしても、劇的に速くならない。
3D V-Cacheで積層してキャッシュを増やしても、アプリレベルでは劇的に速くなってない。
更に積層するのはあるかもしれないが、熱問題に対する解決策がないので出来ないでいる。
UCIe規格経由で複数のチップレットを接続するのが今後出てくると思うが、どれだけ専用の回路を搭載し利用するかで処理能力は変わるが、
Apple M1 UltraのようにProResの本数が増えても使いこなす人が居そうにないというのと似たことになりそうじゃないか。
GPUのように広帯域のHBM/GDDRと、データ依存性がない場合は処理能力高くなるが、
CPU側のメモリーとGPU側のメモリーとのコピーやらオーバーヘッドが合ったり、ゲームがAIの一部といった感じだし、
ゲームもベンチ上は数字が変わるが体感変わらねーなってのに金額が高くなるのもな。
ユニファイドメモリーにするとApple M1系のように性能でないしさ。
レイテンシは変わらないし、DDRの代わりになるものも出て来てない。
インテルがフォトニクスに注力してたり、日本の半導体戦略でもフォトニクスとしてが上がっていたりするが、
光は早いようで遅く、メリットだと低電力か発熱源の分散でしかない。
HPEがフォトニクスで先行していたが、処理能力というより、発熱源分散での設計のし易さアピールだった。
DPU(データ プロセッシング ユニット)、OPU(Optical Processing Unit)はスパコンやクラウドでは追加されるかもしれないが、
パソコンにはまだ遠そう。
DVDが不要になり5インチベイがなくなり、SATA SSDがなくなって2.5インチベイもなくなり、
ちょっとずつパーツ買って性能上げるなんてことはなくなって、全部とっかえ。
もう少しなんとかならないか。
CPUのクロックは微妙に速くなっているがシングルコアの性能はほぼ変わらない。
マルチコアになったとして、ThreadripperのようにIOダイを使って大きくしても、劇的に速くならない。
3D V-Cacheで積層してキャッシュを増やしても、アプリレベルでは劇的に速くなってない。
更に積層するのはあるかもしれないが、熱問題に対する解決策がないので出来ないでいる。
UCIe規格経由で複数のチップレットを接続するのが今後出てくると思うが、どれだけ専用の回路を搭載し利用するかで処理能力は変わるが、
Apple M1 UltraのようにProResの本数が増えても使いこなす人が居そうにないというのと似たことになりそうじゃないか。
GPUのように広帯域のHBM/GDDRと、データ依存性がない場合は処理能力高くなるが、
CPU側のメモリーとGPU側のメモリーとのコピーやらオーバーヘッドが合ったり、ゲームがAIの一部といった感じだし、
ゲームもベンチ上は数字が変わるが体感変わらねーなってのに金額が高くなるのもな。
ユニファイドメモリーにするとApple M1系のように性能でないしさ。
レイテンシは変わらないし、DDRの代わりになるものも出て来てない。
インテルがフォトニクスに注力してたり、日本の半導体戦略でもフォトニクスとしてが上がっていたりするが、
光は早いようで遅く、メリットだと低電力か発熱源の分散でしかない。
HPEがフォトニクスで先行していたが、処理能力というより、発熱源分散での設計のし易さアピールだった。
DPU(データ プロセッシング ユニット)、OPU(Optical Processing Unit)はスパコンやクラウドでは追加されるかもしれないが、
パソコンにはまだ遠そう。
DVDが不要になり5インチベイがなくなり、SATA SSDがなくなって2.5インチベイもなくなり、
ちょっとずつパーツ買って性能上げるなんてことはなくなって、全部とっかえ。
もう少しなんとかならないか。
Apple M1の高性能の理由について、ネットはクソみたいな解説記事に溢れている。
技術に明るいはずのはてなーですら某AVライターの間違いだらけの記事に釣られて、300ブクマ超が集まっていて嘆かわしい。
それもこれも後藤センセーがいつまでたっても解説記事を書いてくれないせいではあるが、公開情報が少なすぎるせいでまともなライターほど記事を書けないのも理解できる。
違います。
そもそもM1はDRAMをSoC化/ワンチップ化していません。M1がやっているのはSiP(System in Package、複数チップをワンパッケージに組み込む)であって、eDRAMによるSoCとは全く異なるものです。
SiPとSoCはJavaとJavascriptくらいには違います。
違います。
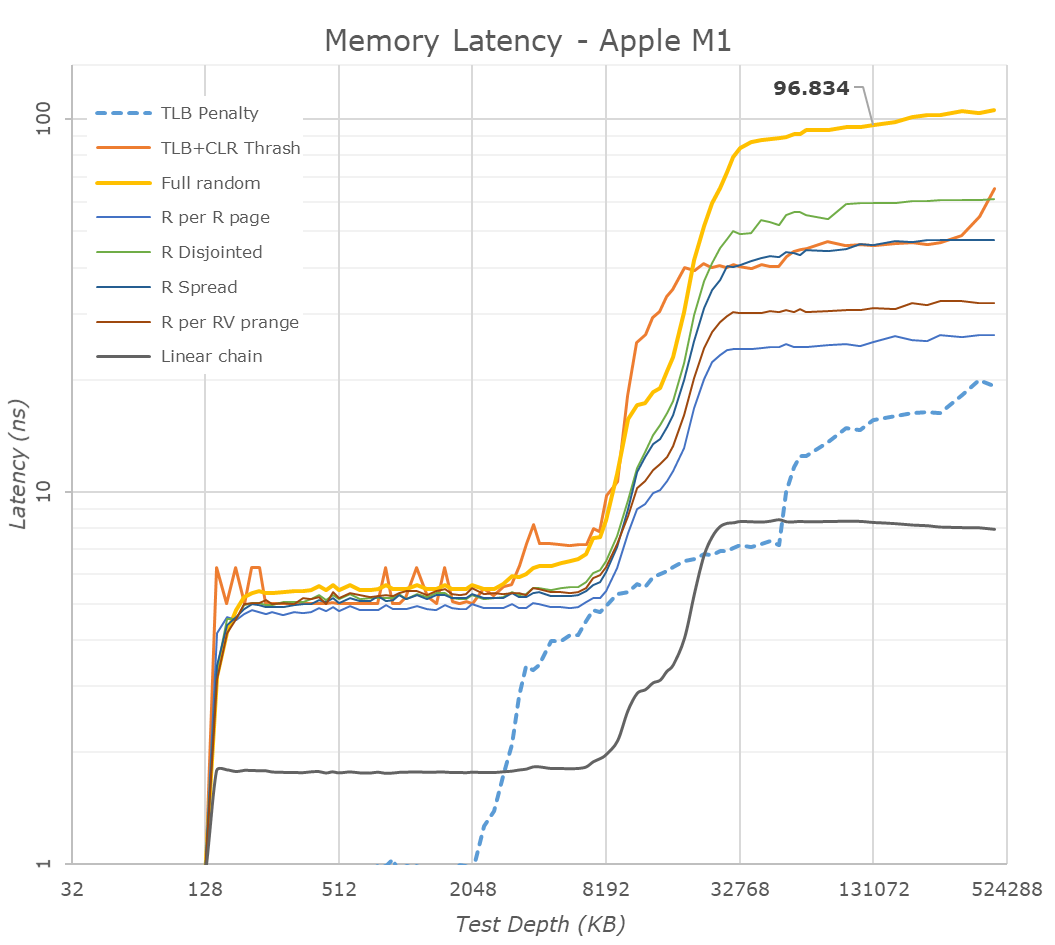
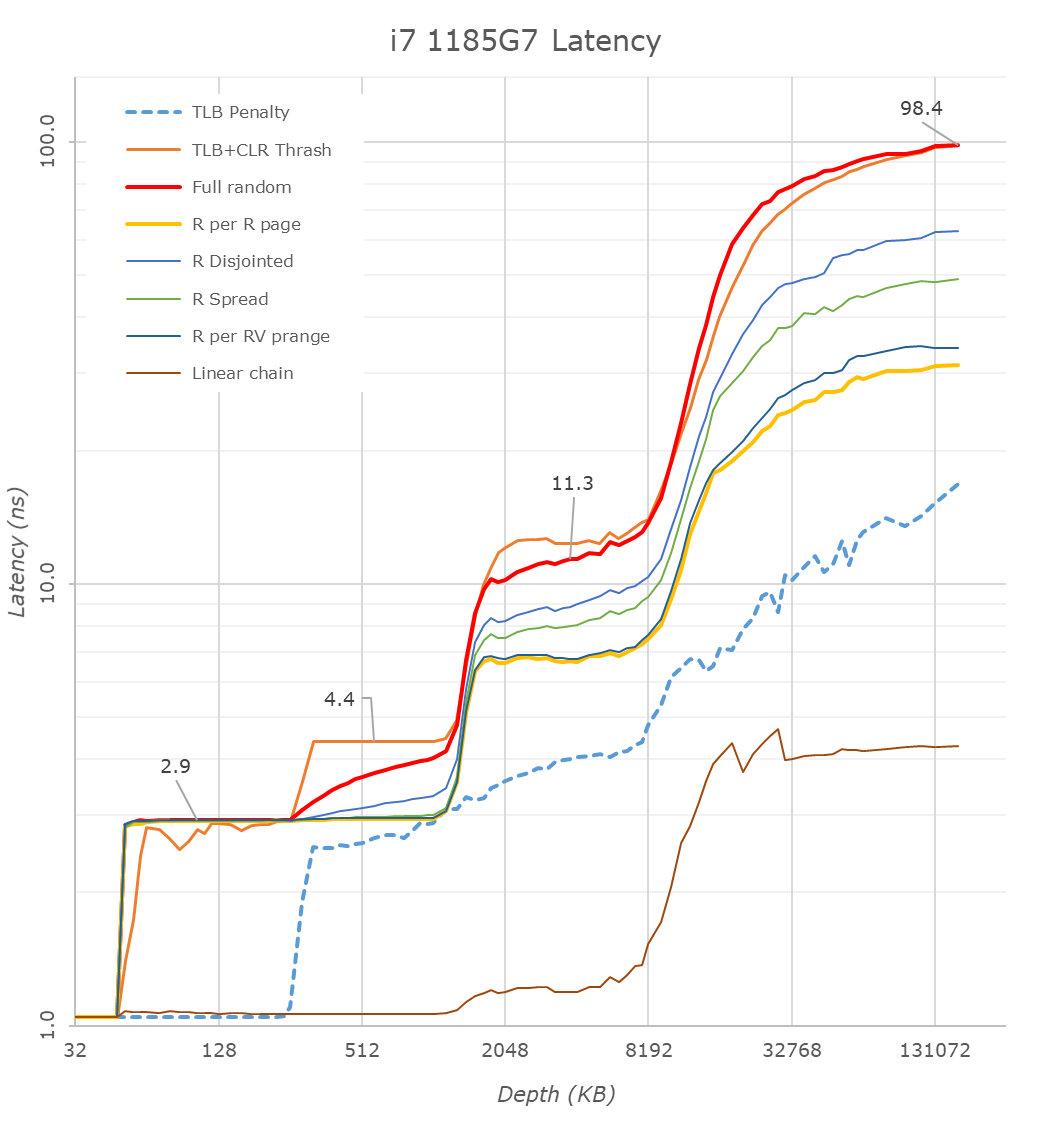
HBM系のメモリを採用していたらメモリ帯域は大幅に向上しますが、M1は標準DDR系メモリをワンパッケージ化しているだけなので、帯域もレイテンシも変わりません。
帯域はM1 MBPとIntel MBP(Ice Lake)でチャネル数同じ、前者はLPDDR4X-4266、後者はLPDDR4X-3733なのでメモリ帯域は14%しか向上していません。また、x86/x64最新世代のTiger Lake/ReniorはLPDDR4X-4266に対応しています。レイテンシはM1が96.8ns、Tiger Lakeが98.4nsでほぼ同等です。
Apple M1の実力を最新世代のIntel/AMD CPUと比較。M1が両者を大きく上回る結果ににあるように、SiP化によって消費電力の削減は期待できます。
違います。
SoC-DRAM間がマザーボード上で30cmあったとしても、電気信号の伝送にかかる時間は片道1nsです。仮にSiP化で物理的距離が1/100になったとしてもレイテンシ100usが98.02usになるだけで、CPUにとってDRAMが絶望的に遠いことに変わりありません。
違います。
まず、同一チップ上のCPUとGPUが同一のメモリーコントローラ/DRAMを共有するという意味では、Intelは2011年のSandy Bridge、AMDも2011年のLlanoからUMAです。一歩進んだメモリ空間の共有、コヒーレンシの確保という意味でも、AMDは2014年のKaveriから対応していて、この点においてM1に革新性はありません。
違います。
上記のSandy Bridge、Llanoの世代からかつてのノースブリッジがCPUに取り込まれたため、2011年以降のモバイルPC向け”CPU”のほぼ全てにはGPU/メモリーコントローラが含まれています。
かつてのサウスブリッジはIntelは今でもワンチップ化こそしていませんが、2013年のHaswellからMCMでワンパッケージ内には収められています。AMDは2014年のCarrizoからサウスブリッジ機能もCPUに取り込まれています。
この意味で、x86/x64のモバイルPC向け”CPU”は、かなり以前からSoCです。
違います。
NPUを活かせるアプリケーションは2020年現在では未だ限定的です。もしNPUの有無によってUXが決定的に改善されるなら、NPUありのSnapdargon 8cxを積むSurface Pro Xは同世代のSurface Pro 7よりずっと快適でなければなりませんが、そのような事実はありません。
違います。
CISC/RISCの論争は20年以上前に終わった話です。その後CISCはRISCの美点、RISCはCISCの美点を取り入れたので、現代のCPUはISAがCISCか/RISCかだけで性能が決定されることはありません。
歴史的経緯からx86/x64のデコーダが複雑になりがちなのは事実ですが、5W以下のローパワープロセッサの開発へ向かうIntelにあるように、ISAの差による消費電力増は10~20%のレンジで、さらに性能増によって相殺される分、電力効率の差としてはわずかです。
頑張って最適化してIPC上げたのと、スマホ由来の積極的なDVFS・クロックゲーティング・パワーゲーティングで浮いた消費電力を回しているからです。
気が向いたら書きます。
というか、
ASICやLSIを作ったことある人なら、当たり前すぎることなんだけど、
語弊があるどころかニュアンスが逆なんだよね。
開発者にとって楽になるどころか難しい方向に行くんだよね。
「フロントエンドのみArm命令に置き換えた形」という文言は、
「中身は前のまんまw」「命令セット入れ替えただけなんすわw」「命令デコーダをarm化したSparc64です。」という意味ではなくむしろ逆で、マイクロアーキテクチャが共通になるように、DDRとHBMの差分を見えなくしたりレイテンシを調整したりetc...して、ほとんど全部Verilogを書き直したってことなんだよね。
で、なぜそこまでしてマイクロアーキテクチャを共通化するかっていうと
LSIチップの検証って組み合わせパターンが天文学的数字すぎて分岐網羅とか全然できないんだよね。
ソフトウェア的な分岐網羅に換算したら0.1%となんじゃないかな。
そこでマイクロアーキテクチャを共通化してると、過去チップのLSIテストケースを流用できるわけなんだな。
テトリスフレンズ世界最強を決めるトーナメント、TTO5が1月19日から開催ということで、前回大会TTO4 Stage2の参加選手や、国内最強を決める大会と言っても過言ではないS級リーグ参加選手から個人的な趣味全開で紹介していきます。
海外編
対戦テトリスシーンにおいて日本は一歩進んでいて、そこにはテトリスDS以前から続く技術の共有という土台があるわけですが、テトリスフレンズ上位勢は日本人だけじゃないぞと言わんばかりに存在感を発揮しているプレイヤーが複数いることは喜ばしいことだと思います。が自分は海外勢の試合動画
などは正直あまり見たことがなく浅い解説になることを先に侘びておきます。
・HD_Blink
言わずと知れた伝説。2010年行われたhebo_MAIとの対戦が記録された動画はニコニコ動画で100万回再生され、対戦テトリスシーンに明るくなくとも見たことがあるという方は多いのではないでしょうか。
http://www.nicovideo.jp/watch/sm10602397
HardDropという世界規模のテトリスコミュニティを立ち上げたことでもおなじみで、彼なしに今のシーンは語れないと個人的には思っています。
プレイの特徴としてはきれいな積みと高い速度、安定した掘り能力を高い次元で両立していることが挙げられ、ベーシックな強いテトリスといった感じで、好きです。ただここ数年プレイヤースキルのインフレから取り残されているような印象もあり、HardDrop背負ってるんやぞというところで踏ん張って欲しい。
・OnePunMan
海外最上位の高火力プレイヤー。パーフェクトクリア、DT砲、Mr.Tspin'sSTD等モダンな開幕を多用する傾向にある。
素早い掘りとTspinを軸に前回大会TTO4では前述のHD_Blink、40LINE世界一のMicroBlizz、後に異常なゲームスピードにチューンされたJstrisを採用して行われたHardDropOpen IX3位を記録することになる実力者TheAtomicNumber(jkwon)を破り、ルーザーズ準決勝まで勝ち上がった実績の持ち主。ファンが多いイメージがあります。おそらく片手プレイで一番強く、速いのは彼。
・ TheAtomicNumber(jkwon)
かなり強い、ということは確かだけど本人視点の動画の公開にあまり積極的ではなく、よくわからないというのが正直なところ。今一番アツい競技タイトルNESテトリスもやっているらしい。無職らしいので応援してる。
・yakine
自由自在にTspinを組む変態。その発想力もさることながら速度もカンストの一歩先を行っていることは、Jstrisにおいて40LINEsub19達成済みということからも伺える。自身のYouTubeチャンネルにアップロードされているfreestyle tspinシリーズは必見。
https://www.youtube.com/channel/UCTbO3v86xrnlYupklGP8Mew
ただ、何手かの置き方を固めてしまうタイプのTspinというのは、どうしてもその前後に隙ができるため、それを極めたプレイヤーが同等以上の相手とやりあう場合それを発揮することは難しい。そのためにjkwon、OnePunManといった最上位クラスのプレイヤーからは少し落ちるというのが個人的な見方です。事実HDO IXではjkwonに対して11-1で負けています。
・MicroBlizz
最速。世界で唯一40line17秒台を出せる男。
速度を出せば出すほどソフトドロップやラインクリア時間の占める割合が上がっていくので、速い=強いというわけではないのですが、それでも強いのがMicroBlizz。TTO4では15-12という僅差でOnePunManに負け、惜しくも敗退となってしまいましたが、今回は頑張ってほしい。あとTwitchで顔出し配信してて面白かった。
プレイスタイルとしては速度を出して掘り続け無理なくTspinを挟んでいく、ややこしい形は避けとにかく速度といった感じで、40LINEで見せる鬼のような積み込みとのギャップが面白い。
余談ですがS級が新設される前の第一回テトリスフレンズA級リーグに唯一海外勢として参加し、5勝4敗で3位という成績を収めています。
国内編
世界最強と言っていいメンツが集まった2017年第三回S級リーグや個人的に好きなプレイヤーからTTO5参加するんじゃないかなーしてほしいなーという予想と希望を織り交ぜつつ紹介していきます。
・hebo_MAI
HD_Blinkの項でもちらっと名前を出しましたが、彼は名実ともに世界最強のテトリスプレイヤーです。テトリスDS全一、テトリスオンラインジャパン世界一、TTO3連覇など成し遂げた偉業は数知れず、彼に勝てる人間は存在しない、異次元であるという畏怖の念とともに宇宙人なんて呼ばれていたhebo_MAIはおそらく日本の対戦テトリスシーンで一番の有名人なのではないでしょうか。
そんなhebo_MAIですが、近年対戦テトリスに対するモチベーションがなくなっているようで、その無双っぷりに陰りが見え始めていたことと合わせて勝てなくなったから逃げただの、あめみや(ぷよぷよテトリス現全一)に負けただけでHBMさんも強いからテトリス教えて欲しい^^だの言われています。自分は全然今でも最強だと思ってるので頑張ってほしい。
テトリスに対してのモチベーション自体はガッツリあるようで、最近ではTGM3のSHIRASEという人外向けモードで前人未到のsub4を達成しました。やっぱり宇宙人じゃないか。
https://www.youtube.com/watch?v=tPDYNuldc-4
プレイスタイルは正直わからない。何時間と動画を見続けても彼のプレイだけはなぜ強いのかが明確にならない。言語化できる範囲を外れたところにhebo_MAIのテトリスはあり、それが長らく彼を倒せる人間が現れなかった理由であると思っています。
・aitsu_k
TTO4 2位、2017年第3回S級リーグ3位、最上位クラスのプレイヤーであることは間違いない「技術の人」aitsu_kですが、どうしても大事な場面で勝てないイメージがあります。TTO4はダブルイリミネーショントーナメントで、決勝含め2敗しない限り敗退ということにはならないのですが、aitsu_k自身が15-11でルーザーズに落としたYUIMETALに対し、決勝で15-13、15-13と2敗してしまい2位という結果に終わりました。
あの世界最速MicroBlizzを破り、鬼耐久YUIMETALを破り、無職jkwonを破り、TTO3連覇、宇宙人hebo_MAIを破りようやくたどり着いた決勝で、自身が15-11をつけた相手に2敗です。
これまで絶対的な一位というところには及んでいないaitsu_kですが、その技術は確かに世界一です。aitsu_kのテトリスはもはや芸術の域にまで達していると言っていいでしょう。そんな中TTO5の噂が出ており今度こそ大きなタイトルを、有無を言わせない形でその手に収めてほしいです。
その確かな技術で出せる火力をしっかりと出していく、賢いプレイヤーであるaitsu_kの試合動画はプレイヤーにとってかなり参考になるものになっていると思います。彼のYouTubeチャンネルに試合動画等は揃っているので一度見てみると良いと思います。
https://www.youtube.com/channel/UCo2mU2ARzuanticHndVrkyA
・whipemerald
whipemeraldというプレイヤーを1つの言葉で表現するならばそれは「変態」です。常人では考えつかないようなプレイを軽々と繰り出していく様は気持ち悪さすら感じさせます。知識で差がつくところは全て習得しているのではないかというような変態プレイヤーですが、2017年第三回S級リーグでは全敗で最下位という不名誉な結果に終わっています。第三回S級リーグには、megurokki、ajanba、aitsu_k、YUIMETAL、hm_39、Fran_sが揃っていて、面子が面子だったというのはありますが、特筆すべきなのは6敗の内3敗がデュースに持ち込まれての負けというところです。狙ってもできることではないこの成績ですが、メンタル面での課題と同時にその確かな実力が見えてきます。がんばれwhipemerald負けるなwhipemerald。
そんなwhipemeraldですが、その豊富なノウハウをまとめたスライド(一部ではほゐスライドと呼ばれています)を公開していて、非常に役に立つのでプレイヤーのみなさんは熟読しましょう。
https://twitter.com/whipemerald/status/872815068026609665
・YUIMETAL
世界王者YUIMETALのテトリスは徹底した堀りによって成り立っていて、彼は後の先という言葉が一番似合うテトリスプレイヤーです。高い掘り能力によるカウンターというのは相手による、場合によるところが大きく、実際勝敗にブレが出ていることもあります。通常のプレイヤーを格付けするには15本先取というルールで問題ないのですが、4列ComboであったりYUIMETALのような掘り特化型プレイヤーの対戦では不安定になりがちで現状では危ういというのが正直なところです。が、速度というコストに見合った掘りができるプレイヤーというのはほとんどいない中、掘りを武器にTTO4を勝ち抜いたという唯一性は世界王者の名にふさわしいと自分は考えます。ルーザーズを2回戦から勝ち上がり、OnePunMan、hebo_MAIとダブルスコア以上を付け、決勝で待ち構えるaitsu_kを二度下すことが偶然によってできるということはないと言っていい。
名実共にYUIMETALはTTOの歴史を塗り替えた世界王者であり、世界最高のプレイヤーです。
・megurokki
テトリスフレンズの王。火力に於いてmegurokkiに勝てるプレイヤーは存在しない。異常な速度による強引な積み込みと一切速度を緩めず撃つTspinによる火力。基本的なことを異常な速度と質で組み立てるとこうなるといったプレイヤーで、他の最上位プレイヤーと比べ明らかに頭一つ抜けている。しかしあまり大会というものに興味が無いのか、どの程度強いのかという部分があまりわからなかった中、参加人数が明らかに足りなかった2017年S級リーグに締め切りギリギリで参加表明。その後駆け込みで続々集まった結果、あの世界最高峰のリーグ戦が観られたわけで、本当にありがたい。
hebo_MAIにあたりが強いことでおなじみで「へぼまいぷよテトとテトフレで勝てなくなってアーケードいったけど成功してよかったな」だとか「へぼまいの全一記録 ほぼマイナー競技やん」「へぼまいがブロンズにいても勝てるやん」など力強いナイフを飛ばしています。やめてあげてほしい。
・ajanba
2017年S級リーグ全勝優勝、 HDO IX優勝と今一番強いプレイヤーはajanbaだと言い切ってもいい。頭一つ抜けた強さを持つのがこのajanbaです。
開幕にパーフェクトクリアや中開け4列Comboを採用し、Combo対策を取ろうというところに連続パーフェクトクリアをぶつけるような少し尖った戦術、開幕を抜けたら少し落ちるかというとそうでもなくmegurokkiと殴り合えるレベルの超火力も持っている世界最強テトリスプレイヤー、それが自分の中のajanba。彼は基本的に自分から大々的に配信をしたりアーカイブをアップロードしたりといったことをしないので、正直あまり彼のテトリスを知らないところがあります。
人外同士のぶつかり合いが今から非常に楽しみです。こちらからは以上です。
{kind=link}
{kind=link}