はてなキーワード: レイテンシとは
今までだと命令やデータはキャッシュに乗るのが前提だったが、AIだと、AIモデルがGB単位なのでキャッシュにそもそも乗らない。
いかにキャッシュヒットさせるか、DRAMとのレイテンシを隠蔽するかだったが、キャッシュに乗らないので、メモリ帯域勝負になる。
GPUが汎用性があるので使われているが、ゲームだとテクスチャをVRAMに乗せておいて、演算した結果はモニター側へ出力すればよく、
なんだかんだ帯域は足りていたが、AIだとチップチップ間の帯域が足りない。
ニューラルネットワークの接続自体をFPGA的に切り替えるのも手だと思うがモデルが大きすぎる。
数年前は、TSP(Tensor Streaming Processor)と呼んでいたが、LPU(language processing unit)と名前を変えた?
数年前のチップをそのまま使い続けているか分からないが、同じならアーキテクチャは4年前のユーチューブを見るか、アスキーあたりの記事にある。
https://youtu.be/UNG70W8mKbA?si=9VFeopAiPAdn08i_
要は、コインパイラで変換が必要。なので提供されているLLMモデルが限られている。
PCIeボードが400万くらいらしいが、SRAMの容量が小さすぎて1ボードでは動かない。
DRAMのレイテンシがSRAMではないので早いのだ、という意見も見られてたが、
1チップのSRAM容量が小さすぎるので、チップチップ間、ボードボード間の通信レイテンシは必ずあるはず。
(数ヶ月前から性能上がっているのは、このあたりのチューニングのはず)
DRAMのレイテンシというが、これも今どきはレイテンシ気にしないように隠蔽するはず。
チームが小さすぎてハード作れなかった可能性もあるが・・・。DMACでチューニングしているか?
ボードにでかいDRAMが載せられるのであれば、そちらの方がボードボード間の通信時間より減るのでは?
GF使ったのは、おそらくAMD設計者が居たからでは。デザインルールどこ破れば性能でるかある程度わかってたとか。1GHzくらいなのは知見なしでやってるとそれくらいで上限くるのはそうだと思う。
チップの世代を更新するかはわからないが、兎にも角にも電力下げて、チップ大量に載せて、チップチップ間の通信時間を下げられるか。
現代くらいの技術レベル同士で数光年くらい離れたとこに電波通信可能な文明がある世界を描いたSFってある?
「三体 1」はわりと近いけど、あれは恒星間の征服戦争というシチュエーションを描くために三体人側にぶっとんだ惑星、ぶっとんだ技術を与えてるからちょっと違う。
どんなに科学が進歩しても超光速通信とか量子サイズの自立機械とかは不可能で、数万年オーダーをかけない限り恒星間を移動可能なものは実質的に情報だけみたい世界観。
仮に相手を支配下しても、そこから資源や土地などは得られないので相手文明を支配したり滅ぼしたりしようとする動機は基本的に存在しないので、
暗い森林で光を灯しても矢は飛んでこない。
まあその場合でも、宗教など利益を度外視した概念上の理由ならあるかもしれないが。
あと「計算資源」として見るなら、情報だけしかやりとりできなくても相手を支配する価値はあるかもしれない。実際そういう理由でクラックされているPCはいっぱいあるので。
BT音声って、圧縮・展開を行う以上はどっちみちレイテンシを完全にゼロにすることって論理的に不可能なのですよね?
どうがんばってもゼロにはできない遅延をなるべく小さくすることにムキになって努力するよりも、遅延はなくせない前提でそれを問題としないシステムを組むことを考えるほうが建設的という気がする。
ms単位で相互にインタラクションが必要なゲームでは遅延の避けられないデバイスを使うことじたいナンセンスと思う。ふつうにワイヤードを使ってくださいって思う。
でも動画視聴用途では、もう「映像の方をBTスピーカーの遅延にあわせて遅らせる調整」が普通なのでしょう?(僕が持ってる安物のモバイルプロジェクターにその機能がついてるくらいだから普通だと思う)。映画なんかを見る分には、絵と音のタイミングさえ合っていればよくて、ゲームのような「システムとの同時性」は求められないから、映像側を遅らせちゃえばいい。
もしこれを規格として一歩進めるならば、BT機器のプロパティに「この機器の平均遅延時間」みたいな項目を設けて、ホストはそれを元に映像の遅延時間を自動同期するとか。コーデックに関わらず遅延時間を固定しておく固定遅延モードとかがあると自動同期する場合にはきっと都合がいいだろうね。
単体の演算器の性能なんてクロック周波数が速くなっている現代だと数クロックの差なんてわからないだろう。
メモリーは社外の汎用品GDDRを使う以上、帯域やレイテンシは変わらない。
違いが出てくるとすると、どうやってメモリ間を隠蔽しているかというのが想像出来る。
データ待っている期間を出来るだけ少なくする、といった感じだ。
演算器を並列に多数動かすと配線抵抗などで電源がドロップする。
チューニングで性能上がっているのなら何処がボトルネックになりそうな所をあげているのか。
【追記】
夜中の勢いで書いたけど、やはり有線にしろった人多いよな
ワイヤレス一個で完結したいだけなんだがそういう要望はニッチすぎなのか
PUGBがでて大量の音ゲーがでてスポーツ中継をスマホで見られる時代になってもだいぶ経つのに、いまだ多くの人は有線で繋ぐしか満足行く体験はできないのか
---
音ゲーとか映画とか動画編集とかする人の多くが諦めているのが遅延問題
もはやスマホでこれらが完結する時代にあって、なぜかイヤホンは音質に力を入れるだけで遅延問題を真剣に対応したがらない
基本的にBluetoothでつなぐのだがそのコーデックによって差がある
現在主流の低遅延モデルはaptxAdaptiveという規格なんだけど、これが低遅延という割に全然遅れて声が聞こえてくる
というか、それよりも前にaptxLawLatencyというより低遅延をうたう規格があるにもかかわらず、そちらは近年あまり採用されていない
もともとaptxというコーデックがあって、それを低遅延にしたのがLL。高音質にしたのがHD。そのHDを低遅延にしたのがAdaptiveらしい
LLの遅延は基本40ms未満。これは30フレーム動画なら1フレーム強という感じ。これはまあ許容できる。
いっぽうのAdaptiveは50~80ms。これは30フレーム動画なら2~3フレーム
この差は結構でかくい上にトランスミッターによってはさらに遅延が生じる
ようはaptxLLくらいがギリギリ許容できる範囲なのに、それよりもレイテンシがある規格がはびこっていてワイヤレスイヤホンで聞くと動画と音がずれまくる
もちろんメーカーは理解しているんだろうけどあまり改善する気がないのはちょっとやばいよね
多分作ってる人たちは高音質さえ保ててればいいと思ってるんだろう
だからよりレイテンシの低い規格があるのに、新しいというだけでAdaptiveを使ってるんだろう
ちなみになんでこんな怒ってるかというと、10年使ってるヘッドホンが壊れかけているのでワイヤレスにしようと思ったら、あまりに求めているものがなかったからなんだ
ワイヤレスで低遅延モデル、という単純な要件を満たすものが驚くほど少ない
ガジェット系のさいちょう氏が勧めていたゼンハイザーのものがいいとは思うけど、眼鏡かけているので合わない可能性のあるヘッドホンは買いづらい
ではイヤホンにしようとするとこっちも数が少なすぎる、というかほぼ店じまいのような有様
Bluetoothオーディオの規格そのものは、大きく進化はしていませんでした。もともとは通話用としてスタートしたBluetoothオーディオですが、HSPというプロトコルから始まり、そして通話用としてHFPが登場しました。一方音楽用はA2DPが規定され、1.0、1.2、1.3とアップデートしてきましたが、基本的な部分は変わっていません。
Bluetoothのコアスペックに目を向けると、こちらは着実に進化してきています。バージョン4.0でLow Energyに対応しました。このLE技術をオーディオにも使えるのではないか……とWorking Group内でもずっと議論をしてきたのです
ここにもあるけど、Bluetoothの規格やイヤホンの進化に対して、データの運搬を担う箱としてのコーデック自体の進化が停滞しすぎなんだよな
完全ワイヤレスイヤホンが早く出すぎという意見もあるだろうけど、単純に業界が舐め腐ってるのが悪い
で、ようやく出始めたのがLEAudioというものらしいが、これはSonyのLinkBudsと専用スマホでしかいまだに実現していない
【レビュー】新規格『LE Audio』をLinkBuds SとXperia 1 IVでブロードキャスト共有接続に挑戦 低遅延伝送もテスト
おい、嘘だろ、今の時点での最善手がまだこのレベルかよ
確かに遅延は解消しているけど機器が少なすぎて熱心なオーディオマニアくらいしか注目していないし、もっといえばそのオーディオマニアは遅延なんてどうでもいい連中だぞ?
ワイヤレスなんて使わず電柱と高価なケーブルに投資するような連中だぞ?
個人的にInstinct MI300に注目しているのは、今後のコンピュータ構成はこうなるだろうな、というのを実現していることだ。
Ryzen Threadripperだとコア数が多いもののハード的なボトルネックがそこかしこにあるので使いにくいわけだが、
Instinct MI300は良さそうに見える。
現状のPCIeだと帯域が遅く、CPU側のDRAMから、GPUのVRAMにコピーするのはそれなりに時間がかかる。
ゲームだと局所性のあるデータを繰り返し使うのでキャッシュで逃れられるし、シーンの切り替えなどでデータ転送するといったことが出来る。
だがAI向けになるとVRAM容量以上(80GBとか)のデータに全てアクセスするので、メモリ転送レイテンシを隠蔽するだけのバッファとしての効果しか意味がなく、メモリ帯域が効いてくる。
Instinct MI300にHBM3が使われていて帯域は広い。レイテンシは大きいと思われるので、そこは気になるが。
CPUのクロックは微妙に速くなっているがシングルコアの性能はほぼ変わらない。
マルチコアになったとして、ThreadripperのようにIOダイを使って大きくしても、劇的に速くならない。
3D V-Cacheで積層してキャッシュを増やしても、アプリレベルでは劇的に速くなってない。
更に積層するのはあるかもしれないが、熱問題に対する解決策がないので出来ないでいる。
UCIe規格経由で複数のチップレットを接続するのが今後出てくると思うが、どれだけ専用の回路を搭載し利用するかで処理能力は変わるが、
Apple M1 UltraのようにProResの本数が増えても使いこなす人が居そうにないというのと似たことになりそうじゃないか。
GPUのように広帯域のHBM/GDDRと、データ依存性がない場合は処理能力高くなるが、
CPU側のメモリーとGPU側のメモリーとのコピーやらオーバーヘッドが合ったり、ゲームがAIの一部といった感じだし、
ゲームもベンチ上は数字が変わるが体感変わらねーなってのに金額が高くなるのもな。
ユニファイドメモリーにするとApple M1系のように性能でないしさ。
レイテンシは変わらないし、DDRの代わりになるものも出て来てない。
インテルがフォトニクスに注力してたり、日本の半導体戦略でもフォトニクスとしてが上がっていたりするが、
光は早いようで遅く、メリットだと低電力か発熱源の分散でしかない。
HPEがフォトニクスで先行していたが、処理能力というより、発熱源分散での設計のし易さアピールだった。
DPU(データ プロセッシング ユニット)、OPU(Optical Processing Unit)はスパコンやクラウドでは追加されるかもしれないが、
パソコンにはまだ遠そう。
DVDが不要になり5インチベイがなくなり、SATA SSDがなくなって2.5インチベイもなくなり、
ちょっとずつパーツ買って性能上げるなんてことはなくなって、全部とっかえ。
もう少しなんとかならないか。
CPUのクロックは微妙に速くなっているがシングルコアの性能はほぼ変わらない。
マルチコアになったとして、ThreadripperのようにIOダイを使って大きくしても、劇的に速くならない。
3D V-Cacheで積層してキャッシュを増やしても、アプリレベルでは劇的に速くなってない。
更に積層するのはあるかもしれないが、熱問題に対する解決策がないので出来ないでいる。
UCIe規格経由で複数のチップレットを接続するのが今後出てくると思うが、どれだけ専用の回路を搭載し利用するかで処理能力は変わるが、
Apple M1 UltraのようにProResの本数が増えても使いこなす人が居そうにないというのと似たことになりそうじゃないか。
GPUのように広帯域のHBM/GDDRと、データ依存性がない場合は処理能力高くなるが、
CPU側のメモリーとGPU側のメモリーとのコピーやらオーバーヘッドが合ったり、ゲームがAIの一部といった感じだし、
ゲームもベンチ上は数字が変わるが体感変わらねーなってのに金額が高くなるのもな。
ユニファイドメモリーにするとApple M1系のように性能でないしさ。
レイテンシは変わらないし、DDRの代わりになるものも出て来てない。
インテルがフォトニクスに注力してたり、日本の半導体戦略でもフォトニクスとしてが上がっていたりするが、
光は早いようで遅く、メリットだと低電力か発熱源の分散でしかない。
HPEがフォトニクスで先行していたが、処理能力というより、発熱源分散での設計のし易さアピールだった。
DPU(データ プロセッシング ユニット)、OPU(Optical Processing Unit)はスパコンやクラウドでは追加されるかもしれないが、
パソコンにはまだ遠そう。
DVDが不要になり5インチベイがなくなり、SATA SSDがなくなって2.5インチベイもなくなり、
ちょっとずつパーツ買って性能上げるなんてことはなくなって、全部とっかえ。
もう少しなんとかならないか。
ライトなコンピュータユーザを一切合切無視してギークがギークのため情報共有するためのエントリ。
感想ははてブへ、質問はトラバに投げれば誰かが答えるんじゃないか?(他力本願)
セキュリティの懸念があるけれど通常モードはセキュアを維持するため機能制限があるので制限開放のため開発者は初手でデベロッパーモードにするしかない。
利用途中でデベロッパーモードにするとストレージがファクトリーリセットされるので注意。
Webでエンタメを楽しんだりWebツールを中心に利用するのであれば、5万円未満の低性能機で必要十分。
この用途では実質的にタブレットPCのような運用へなりやすいのでフリップする2 in 1機やタブレット機がオススメ。
ただし、Webベースのゲームは楽しめるがAndroid Appレイヤーを用いたゲームは非常に厳しいので諦めたほうが良く、そこそこの負荷の掛かるAndroid Appツールも鈍足でストレスになるのでWeb版があるならそっちを使ったほうが良い。
Core i7クラスのCPUや16GB以上のワーキングメモリ、SSDストレージなど高性能機でChromeOSを使うとその分だけ快適になる。
Android Appレイヤーを用いたゲームも快適に動き、ウマ娘クラスの3DCGなAndroid Appゲームも高速に動く。
しかし、高性能機は空冷ファンを搭載していることが多く、高負荷を掛ければファンは唸るしウルサイ。
Google Play StoreにてAABパッケージがほぼ強制になったとは言え、開発段階でx86_64を意識しないと処理が非効率になりがちのようなので、Android Appレイヤーを中心に運用したいと思っているのであれば素直にARM機を探してきたほうが良い。
1つのIDEで開発をしクロスプラットフォーム対応することが流行っている昨今、自動でガベコレに頼っていてリソース管理経験に乏しい開発者はマジで底辺にしか漂流できないので覚えたほうが良いぞ。
それがWeb系のフロントエンドでもバックエンドでもそうだから底辺から脱したいのであれば覚えろ。
しっかりリソース管理できているChromebook向けビルドはアーキテクチャによらずサクサクなのでクロスプラットフォームなビルドはマジで開発チームの腕が如実に反映される。
ちなみにSnapdragon 8 Gen1なChromebookの公式発表は今のとこ無いのでAndroid Appレイヤーをブンブン回すのは難しい。
メーカーはもうちょっと頑張れ。
Chromebookの大半はタッチスクリーンディスプレイを搭載しているし、Android StudioでAndroidManifest.xmlを何も考えずに生成すると勝手にChromeOSをサポートするので結果的にChromeOSで動くAndroid App数が多くなるという現象が起きている。
Android Studioが雑なのかXcodeが厳密なのかは意見が分かれると思うけど、タッチパッドでiOS App操作というセンスがクソなのは万人が納得するところだと思う。
ARM系のSoCであればワンチャンいける可能性はあるものの、市場に出ているChromebookの大半はx86_64でGPSモジュールを積んでいないのでGPSを使おうと思うとBluetoothあたりでGPSレシーバを接続するしか無い。
当然A-GPSは使えないので精度がそこまでではないから期待し過ぎに注意。
Android AppレイヤーではUSB over MIDIが使えるのでDTMあたりに活用することは可能なものの、iOSと比較してレイテンシがそこそこ大きくDTMに活用しようと思うユーザは不満を持ってしまうかも知れない(ハードにもよるけど0.5msecくらいズレる)。
そもそも既存のAndroid AppなDAWはVSTやLV2などの外部プラグインに対応していないのでAUプラグインが使えるiOSのほうがDTMへ向くんじゃないだろうか?
ただし、DAW単体でDTMを完結するとレイテンシはほとんど気にならなくなるので絶対にAndroid AppでDTMが不可能というわけでもない。
Linuxレイヤー側でDTMをするのはレイテンシが大きすぎるしJackも上手く動作しないのでオススメできない。
ChromeOS向けマルチタスクへ対応していないとAndroid Appはフロントエンド(プライマリ)からフォーカスが外れてバックエンドへ行くとスリープする。
Android Appがスリープされることを考慮しておらず例外処理がされていないとAndroid Appはそのまま落ちる。
まぁAndroid Appがスリープされることを考慮しておらず例外処理がされていないとAndroid Appはそのまま落ちるっていう部分はAndroidスマホで実行しても同じなので正直に言ってスリープされることを考慮しないデバックってAndroid App開発者は何やってんの?とは思う。
ICT教育で日本中の学生がChromeOSを使うようになっているので、ゲームであれツールであれ何であれChromeOS向けのマルチタスクは考慮しておくとスリープしたり落ちたりするAndroid Appよりも支持されるのは間違いないのではないか。
LXC/LXDなのでDockerに慣れ親しんでる人にはわかりやすいかも?
デフォルトのイメージはChromeOS向けにカスタムされたDebian。
別のLinuxディストリビューションへ置き換えることも出来るが一部機能が制限される可能性がある。
ChromeOSで動作するGoogle日本語入力とは別にLinuxレイヤー側で日本語入力を用意する必要がある。
選択できるIMは幅広いのでMozcだろうがSKKだろうが漢直だろうが何でもイケる。
ただ特殊なものを選ぶとChromeOS側と齟齬が発生するのでfcitx-mozcあたりが無難っちゃ無難。
ChromeOSへマウントされたUSB機器、というかシリアル接続された機器はLinuxレイヤー上から認識しない。
見掛け上で接続されているハードのすべてはソフトで仮想接続されているだけなので、一部経路から上手く認識しなかったりする。
つまりLinuxレイヤーではUSB Pass Throughが使えないが、Android AppレイヤーではUSB Pass Throughが使えるということ。
Linuxレイヤーでゲームやろうと思ってもUSBゲームパッド動かないのでマウスとキーボードで完結できるFPSみたいなゲームしか上手くプレイできないぞ。
言うなればAndroid Appレイヤーでスクリーンキャプチャ系のアプリによってLinuxレイヤーで動くGUIアプリをキャプチャしようと思ってもキャプチャできず撮像は暗転している。
ChromeOSがホストでLinuxレイヤーとAndroid Appレイヤーはゲストなのでそりゃそうなんだけど気付かないとハマる。
LXC/LXD on LXC/LXDになるので面倒くさくなること請け合いだ。
どうしても仮想環境がChromebookに欲しいのであればKVMとかのほうが安定している。
ただしゲストOS上へ仮想環境を構築しているという前提は認識しておくべき。
つまりゲストOSの制限はKVMも引き継ぐ。
ただしこれはDockerが導入できないという意味ではない。
自分で解決する気概があるのならばDockerは便利に使える。
CLIツール系は普通に動くのでWeb開発であれば何も意識しないで普通にできる。
ただ、PSD形式みたいなもんは扱いにくいのでWebデザイナーは悲しい思いをするかも知れない。
GIMPやInkscapeなども動くけれどデザイナーはAdobe使いたいんじゃなかろうか?
Android App向けIDEのAndroid StudioはChromeOS向けが存在するのでAndorid App開発が可能。
しかしデベロッパーモードでなければエミュレータや実機デバックに制限が発生するので注意。
UnityやUEを使いたいところだけれど、Linux版のUnityやUEは不安定なのでゲーム向けIDEが欲しいのであればGodotがオススメだ。
ライセンスはMITなので商用利用だってイケる。
3Dのほか2Dゲームもいける上に、最近のIDEよろしくマウスでポチポチとUIを作れるし、軽量動作、物理演算、日本語ドキュメントまで揃っているので中高生もガンガン使える素晴らしいIDEだ。
浅い部分を触っているうちはYoutubeを観たり、プリインストールされているGoogle Play StoreからAndoird Appをインストールして使うみたいな気軽な運用ができる。
言ってしまえばライトユーザの視点ではノートパソコンの形をしたAndorid機がChromebookだと言える。
しかし一度Linuxレイヤーへ手を出すとUbuntuという何でもできるようになったLinuxディストリビューションが存在する中で、昔懐かしい複雑怪奇なLinuxディストリビューションを体験することとなってしまう。
ただ、Chromebookで何でもやろうとするからそうなるだけで、APTからIDEをインストールしてちょっとした開発をするなんて使い方であるならば業務利用でも意外となんとかなる・・・というか何も意識しないで使える。
そもそもHTTP使えるなら今どきの開発は何とかなるので、Chromebookへ対してギークがゴチャゴチャ言うのはほぼ間違いなく不満を言いつつDIYを楽しんでる。
Ubuhtuならばアレができるコレができると言うならば最初からUbuntu使えよって話。
ギークとは不便を見つけてゴチャゴチャ言う、そういう鳴き声の動物なのだ。
少なくともGoogle系エコシステムとしてのChromeOSは非常に完成度が高くなりつつある。
Googleアシスタントは元よりAndoridスマホとの連携もよく、ハードウェアへもそこそこの投資ができるのであれば多くのChromebookではUSIペンが使えるし、USBポートはUSB-Cだ。
そこそこのChromebookは多くの場合HiDPIなIPS液晶でありグレアなのは気に食わないが美しい。
デベロッパーモードにするとセキュアさは下がるが普通に使えばローリングリリースのアップデートを無償で得られ、Gentoo LinuxベースなChromeOSは潜在的なマルウェアの絶対数がそもそもWindowsやMacよりも少ないという利点がある。
Bluetoothイヤホン・ヘッドフォン・ヘッドセットも使えるし、NestスピーカーやNest Hub、Nest Camを持っているのであればGoogleアシスタントからのコントロールが容易なのは想像が付くだろう。Android AppレイヤーはGoogleのホームマネジメントアプリであるGoogle Homeも動く。
大胆にも憎きCapsLockキーをデフォルトで殺し、Everything Buttonキーとして独自キーバインドを与えたのも面白い。
もちろんこれは選択するハードによるものの指紋認証でロックを解除することまでできる。
Googleエコシステムへ浸かっていてGoogleへ個人情報を捧げられるのであればChromebookはアリな選択肢だと断言できる。
敢えて欠点を挙げるのならば、たった一言で欠点を表現することが可能だ。
「Chromebookじゃなくても別に良くね?」
そう、ギークがLinuxを使いたいのであれば別にChromebookじゃなくても良い。
というかギークは別にLinuxじゃなくともHaikuであろうが超漢字Ⅴだろうが喜ぶ生き物だ。OSは別になんだって良い。
このエントリは単にChromebookという新しい沼へギークの皆さんをご案内しているに過ぎないのだ。
| *21 | マザーボードのフェーズの話 - PC Watch | https://pc.watch.impress.co.jp/docs/news/1152140.html | 373849521 |
| *22 | PCエンサイクロペディア:第8回 PCのエンジン「プロセッサ」の歴史(2)~性能向上に勤しんだ486/Pentium世代 2. RISCのアーキテクチャに近づくPentium - @IT | https://atmarkit.itmedia.co.jp/fsys/pcencyclopedia/008procs_hist02/procs_hist04.html | 4701261286880018114 |
| *23 | トレンドの光るPCはハデなだけではつまらない ~【DIY PC 08】マザー&ケースの機能を活用して作るイルミネーションPC - PC Watch | https://pc.watch.impress.co.jp/docs/news/1148442.html | 372842665 |
| *24 | 【笠原一輝のユビキタス情報局】AMDのRyzen ThreadripperがIntelの危機感に火をつけた ~Intelの18コアのSkylake-X急遽投入の背景にあること - PC Watch | https://pc.watch.impress.co.jp/docs/column/ubiq/1062361.html | 347169693 |
| *25 | 【Hothotレビュー】待望の第12世代Coreついに発売! ベンチマークで見るその実力 - PC Watch | https://pc.watch.impress.co.jp/docs/column/hothot/1363614.html | 4710698281882741314 |
| *26 | 見れば全部わかるDDR4メモリ完全ガイド、規格からレイテンシ、本当の速さまで再確認 - AKIBA PC Hotline! | https://akiba-pc.watch.impress.co.jp/docs/sp/1231939.html | 4680749088087636034 |
| *27 | 新登場の32GBメモリモジュール、使えるチップセットは? : AKIBAオーバークロックCafe | http://blog.livedoor.jp/ocworks/archives/52098537.html | - |
| *28 | シングルチャネルおよびマルチチャネル・メモリー・モード | https://www.intel.co.jp/content/www/jp/ja/support/articles/000005657/boards-and-kits.html | 374335238 |
| *29 | 【特集】同じSSDでもこれだけ違う。SATAから第4世代PCIeまで速度差を検証 - PC Watch | https://pc.watch.impress.co.jp/docs/topic/feature/1386511.html | 4715121623230645378 |
| *30 | SSDの選び方:SLC、MLC、TLC、QLC、PLCの違いを解説 | ちもろぐ | https://chimolog.co/bto-ssd-slc-mlc-tlc/ | 369046698 |
| *31 | 消耗品と有寿命部品について : NEWS: ビジネスPC | NEC | https://jpn.nec.com/products/bizpc/info/pc/cosmable.html | 4668458216799596930 |
| *32 | M-DISC - Wikipedia | https://ja.wikipedia.org/wiki/M-DISC | 260312391 |
| *33 | PS5にみる物理メディアの終焉 - ITmedia NEWS | https://www.itmedia.co.jp/news/articles/2006/17/news056.html | 4687255935115670114 |
| *34 | 【特集】チャタってしまった10年物マウスが3,000円で完全復活! ~ドスパラ「マウスボタン故障修理サービス」に依頼してみた - PC Watch | https://pc.watch.impress.co.jp/docs/topic/feature/1160250.html | 4662344022334670305 |
| *35 | ロジクールのトラックボールマウスM570を自分でスイッチ交換修理した方法 - ネットの海の渚にて | https://dobonkai.hatenablog.com/entry/Logicool-m570-repair | 4680507411203374530 |
| *36 | マウスの左クリックがおかしくなったので分解修理した : トイレのうず/ブログ | https://1010uzu.com/blog/overhaul-mouse-failing-in-left-click | 304301040 |
| *37 | Logicool MX300 Optical Mouse M-BP82のメンテナンス | https://orz7.web.fc2.com/rat/log/mx300-optical-mouse-m-bp82.htm | - |
| *38 | 加水分解の止め方、ベタベタの除去 - 黒色中国BLOG | https://bci.hatenablog.com/entry/kasuibunkai | 4697762672020785762 |
| *39 | Mouse Roller Wheel Durable Optical Pulley Repair Parts for Logitech MX510 518 G400|Replacement Parts & Accessories| - AliExpress | https://www.aliexpress.com/item/1005003407488009.html | - |
| *40 | ASCII.jp:Windows 11にアップグレード可能なCPUは基本はやっぱり第8世代/Zen+以降になりそう? (1/2) | https://ascii.jp/elem/000/004/061/4061479/ | 4704977165657723746 |
| *41 | Microsoft、2022年にWindows 11の高速化に注力すると宣言 - iPhone Mania | https://iphone-mania.jp/news-420988/ | 4711489752449241922 |
| *42 | BIOSからUEFIへ BIOSはなぜ終わらなければならなかったのか:“PC”あるいは“Personal Computer”と呼ばれるもの、その変遷を辿る(1/4 ページ) - ITmedia NEWS | https://www.itmedia.co.jp/news/articles/2202/24/news067.html | 4715865033555686850 |
| *43 | マザーボードのCSM(Compatibility Supported Module)を有効にする方法(ASRock製マザーボード) | TSUKUMO サポートFAQ | https://faq.tsukumo.co.jp/index.php?solution_id=1316 | 4709334416996014018 |
| *44 | そうだ、グラフィックボードを増設しよう! でも、その前に... - ツクモ福岡店 最新情報 | https://blog.tsukumo.co.jp/fukuoka/2015/08/post_116.html | 298062585 |
| *45 | 【備忘録】mbr2gptコマンド実行後の回復環境消失の対応方法: YOSIの小さな旅の記し | http://kykyblog.air-nifty.com/blog/2021/09/post-802f79.html | - |
| *46 | Windows10/11でDiskPartコマンドを使用する方法 | https://www.diskpart.com/jp/windows-10/diskpart-windows-10.html | 4705642648092693218 |
| *47 | アライメント | https://www.pc-master.jp/mainte/aft-hdd.html | 4699883528408540354 |
| *48 | Windows 10 で Administrator ユーザーを有効にする方法 – ラボラジアン | https://laboradian.com/enable-administrator-on-windows10/ | - |
| *49 | Windows 10 は既定で OneDrive にファイルを保存する | https://support.microsoft.com/ja-jp/office/windows-10-%E3%81%AF%E6%97%A2%E5%AE%9A%E3%81%A7-onedrive-%E3%81%AB%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB%E3%82%92%E4%BF%9D%E5%AD%98%E3%81%99%E3%82%8B-33da0077-770c-4bda-b61e-8c8e8ca70ac7 | 4687214936939669538 |
| *50 | OneDriveのドキュメント・ピクチャ・デスクトップのバックアップ同期をやめる手順 | パソコンりかばり堂本舗 | https://ikt-s.com/onedrive-backup-skip/ | - |
| *51 | Windows8をインストールしたSSDの寿命を延ばす対策 | ZAKKINKS | https://zakkinks.com/windows8_ssd_hack/ | 168055874 |
| *52 | Windows10でSSDの寿命を延ばす対策【第一回】 | ZAKKINKS | https://zakkinks.com/windows10_ssd_optimization/ | 268597709 |
| *53 | Windows10でSSDの寿命を延ばす対策【第二回】 | ZAKKINKS | https://zakkinks.com/windows10_ssd_optimization2/ | 276446264 |
| *54 | 新しいコンテンツの保存先を変更する ( アプリのインストール先変更方法を例に ) | ドスパラ サポートFAQ よくあるご質問|お客様の「困った」や「知りたい」にお応えします。 | http://faq3.dospara.co.jp/faq/show/4557?site_domain=default | 369837603 |
| *55 | 一方、ふうえんさんちでは… SuperfetchとPrefetchについて~(1) | http://blog.phooen.com/blog-entry-39.html | 217075081 |
| *56 | windows10でAppData/Localを別ドライブへ移動する | ピースペース | https://nasu38yen.wordpress.com/2015/11/19/windows10%E3%81%A7appdatalocal%E3%82%92%E5%88%A5%E3%83%89%E3%83%A9%E3%82%A4%E3%83%96%E3%81%B8%E7%A7%BB%E5%8B%95%E3%81%99%E3%82%8B/ | 274477044 |
| *57 | mutaguchi on Twitter: "Win10のスタートメニュー、ショートカットファイルとの関係性が未だにいまいちわからん。ショートカットファイルを編集すると、スタートメニューから消滅したりするんだよなぁ。挙動が分からなくて困る。" / Twitter | https://twitter.com/mutaguchi/status/1298882977863270406 | - |
トラバ・コメ・ブクマしてくれた方々に感謝。人の興味を惹く内容を投稿できて良かった。
hoimin-densetsuさんのセルクマか
ブクマエントリのdata-entry-createdと件のブクマの日時分が一致してるが、濡れ衣だ。
Core第1世代(Nehalem)のつもりで書いたが、Core Duoとかもっと古いのを失念してたので本文修正。
電源は新品がいい
古い電源でもイケるのではと憶測してそれを実証してみたいと思わなければ、自分もきっとそうした。
旧PCのだいぶ後で、TV録画のために買った外付HDDが元。ケースが死んだので、中身をデータ用ドライブとして使っていた。
一体何にパソコンを使っていたのか
はてブと5chとTwitterとそれらの引用元を隅々まで読む作業、動画・漫画鑑賞、Paradoxゲーム、相場観察。
上記用途にしか使ってないので、他に良いPCを買うのは勿体なくてできなかった。
Socket7のM/Bとかその頃のPC雑誌とか、必要な人がいたら譲るんだが。
参考文献57まであって草
老眼の始まったアラフォーで、日本人学生で、増田ユーザで、最近10年ぶりに自作PCをしたという積集合が空でない可能性とは。
無欲ではなく最高の贅沢なんだろね
過ぎた吝嗇は強欲と執着の発露だとは思う。
他の人は言うのを遠慮してたのに。
生憎、数年前のRyzenショックを見逃す程度には、自作PC事情への関与が薄かった。
なんでブログで書かなかったの
完璧主義と自意識過剰と怠惰のせいでブコメすら継続的にできない性質なので。今回は衝動的に長文を書きたくなって投稿した。
多分友達になれる
支出を抑制しようとする情熱が収入を増大させる方に向かって欲しい人生だった。
古老の趣味やな
初老のおじさんに何てことを。
机の周りもめちゃくちゃ綺麗にしてそう
偏執狂は恐ろしく整備された部屋か恐ろしく汚い部屋かどちらかに住んでいるものだと思う。
そういう行為から抜け出せないならそうすることが許容される愛嬌は持ち合わせたいものだねと。
インテルやAMDなどのCPUと、NVIDIAなどのGPUとの間の接続はPCIeが速くなってきたとはいえ、
双方向にデータのやり取りが発生するような場合は帯域の狭さがネックになる。
ゲームのようにGPUに投げっぱなしにして、GPUとGPU側のメモリー、そしてディスプレイへの出力だけで閉じても大丈夫な場合は問題にならないが、
世の中そういうアプリケーションだけではない。
GPUカードが高くなっているのにも関わらず、CPU側のメモリーとGPU側のメモリーで似たようなデータをコピーしないといけないという、
なので、「M1 Ultra」のように、CPUとGPU間の帯域が大きく、ユニファイドメモリでCPUとGPUで共通のメモリーにアクセス出来るというのはメリットがある。
インターポーザを介して帯域は確保出来ているが、遠いメモリーへのアクセスへのレイテンシは防ぎ用がないので、
チューニングしようとするとインターポーザを介するメモリーアクセスが発生するかどうかは、プログラミングで気にする必要はあると想像する。
さすがのAppleも最先端プロセスを使う、予約していたTSMCのキャパを使い切る状態にしないといかず、数を出荷しないといかないのだろう。
良品選別したダイをインターポーザで接続して、出荷するチップ数を増やすというのは選択肢としてよかったのだろう。
トランジスタ数も多くなりすぎて、EDAツールで設計する時に必要になるシミュレーション時間も馬鹿にならないはずで、
タイミング検証が済、動くことが保証できている領域があるというのは、段階を踏んで設計するということでも合理的だ。
ただ機能面では、単純に倍になってしまっているため、ProResの本数が増えて、使い切るような状況があるのか?という不安はある。
「M1 Max」でそれなりにバランスを取っているわけで、「M1 Ultra」では多くなりすぎて使われない部分も出てくるだろう。
価格がそれなりに高いので、使われない部分があるというのは、あまり許してもらえないのではないだろうか。
インターポーザで接続する技術は確率出来たので、そこのIF周りは変更せずに「GPUだけ増やしたチップ」と「M1 Max」を接続する
といったのは考えられるが、数がでないといかず、そういうのを作れるかどうか。
他にデスクトップ向けだが低消費電力を売りにしているのは気になっている。
@kis (id:nowokay) さんの以下の記事についてです。
https://nowokay.hatenablog.com/entry/2021/09/25/042831
ブコメにもあるようにちょっと内容が雑というかわかりにくいせいで賛否両論になってしまっていて、もしかしたら近いうちにアンサー記事が出るかもしれませんが、自分自身の理解を助けるためにも言わんとしていることを推測しつつ、自分の認識もまとめておこうと思い書くことにしました。明らかに誤読してそうな箇所があれば、指摘してください。
まずは前提を書いておかないと論点がぼやけると思うのでいちおう。
その他の前提:
2000年代に入って関数型プログラミングが脚光を浴び始めたのは、コンピュータ資源が潤沢になりパフォーマンスをそれほど気にしなくってよくなったことが大きな理由ではないか、という認識があります。
関数型プログラミング言語の内部実装を読んだことがないので推測ですが、データを不変にするということはその都度メモリ領域を新たに割り当てることになり、そのオーバーヘッドがプログラムのパフォーマンスに影響を与えるので、パフォーマンス要件がをシビアな場合、どうしてもメモリ割り当てや計算効率を考えるとミュータブルにせざるをえないと思います。が、ウェブアプリケーションに限っていえば、データベースアクセスやネットワークアクセスのレイテンシが大きいので、そうした相対的に細かいオーバーヘッドを無視しても(大抵の場合は)問題にならなくなった、というのが「時代」の流れなんだという認識です。
いっぽうで別の観点もあって、REST API や FaaS が一般化して、関数単位で処理を分割し、アプリケーション外部に配置することが当たり前になってきた現状があり、マイクロサービスのようにアプリケーション自体もモジュールの一単位として考えると、アプリケーション内部のモジュール同士でも関数ベースでやりとりする形になっても不自然ではないと考えられます。
元記事にもありますが、RPC の派生(実装?)として生まれた Java の CORBA や Microsoft の DCOM みたいな振る舞い付きのオブジェクト(コンポーネント)を共有しようという世界観は廃れ、REST API のような単一の振る舞い(エンドポイント)とそれにひもづく JSON のようなデータ構造のみを受け渡すやり方が一般的になったアプリケーション間通信の潮流と、計算機資源が潤沢になって再度脚光を浴びた関数型プログラミングが、レイヤーの違いを飛び越えてひとつになろうとしているのではないか、と。
つまり、元記事に書かれている「時代に合ってない」というのは、「データ構造と振る舞いが一体となったオブジェクト」のような「なにか」は、そうした背景があるために、どこにも存在する必要がなくなってきているのではないか、と解釈しました。
なので、以下のコメントはちょっと論点がずれてると思いました。
はあ?「再利用する方法としてはWeb APIが主流」って、その中身をオブジェクト指向で設計することは、全く矛盾しません。 部品化の単位は、慣習や柵などで大きく変わります。オブジェクト指向とはほぼ無関係です。
https://b.hatena.ne.jp/entry/4708813645995359202/comment/suikyojin
なんでサービスとして外とやり取りする話とサービスの内部設計の話をごっちゃにしてんだ。なんか理解度が怪しくない
https://b.hatena.ne.jp/entry/4708813645995359202/comment/ssssschang
たしかに、アプリケーション単位とアプリケーション内部のモジュール単位とでその表現形式を合わせる必要はないんですが、元記事の言わんとしていることはこの一文に端的に表れていると思います。
ソフトウェアの記述をまとめるという視点では主にステートレスな関数を分類できれば充分で、データと振る舞いをまとめたオブジェクトというのは大きすぎる、システムを分割して管理しやすくするという視点ではオブジェクトというのはライフサイクルやリソース管理の視点が足りず小さすぎる、ということで、オブジェクト指向の粒度でのソフトウェア管理は出番がなくなっているのではないか、と思います。
「オブジェクト指向でなぜつくるのか」という本がありますが、「え、いまどきオブジェクト指向でつくらなくない?」っていつも思います。内容的には、もうほとんどはオブジェクト指向関係ないソフトウェア工学の紹介になっていますね。
当該書籍は読んだので後半はまぁわかるんですが、前半は「え、いまでもオブジェクト指向でつくるのが主流じゃないの?」って思ってしまいます(オブジェクト指向の定義が「データ構造と振る舞いが一体となったオブジェクトの集まりとしてソフトウェアを組織化すること」なのであれば)。
Joe Armstrong が "Why OO Sucks" を書いたのが2000年とのことなのですが、そろそろこうした議論は収束に向かってほしいと個人的には思います(とっくに収束していると感じている方もいらっしゃるでしょうけど)。
Apple M1の高性能の理由について、ネットはクソみたいな解説記事に溢れている。
技術に明るいはずのはてなーですら某AVライターの間違いだらけの記事に釣られて、300ブクマ超が集まっていて嘆かわしい。
それもこれも後藤センセーがいつまでたっても解説記事を書いてくれないせいではあるが、公開情報が少なすぎるせいでまともなライターほど記事を書けないのも理解できる。
違います。
そもそもM1はDRAMをSoC化/ワンチップ化していません。M1がやっているのはSiP(System in Package、複数チップをワンパッケージに組み込む)であって、eDRAMによるSoCとは全く異なるものです。
SiPとSoCはJavaとJavascriptくらいには違います。
違います。
HBM系のメモリを採用していたらメモリ帯域は大幅に向上しますが、M1は標準DDR系メモリをワンパッケージ化しているだけなので、帯域もレイテンシも変わりません。
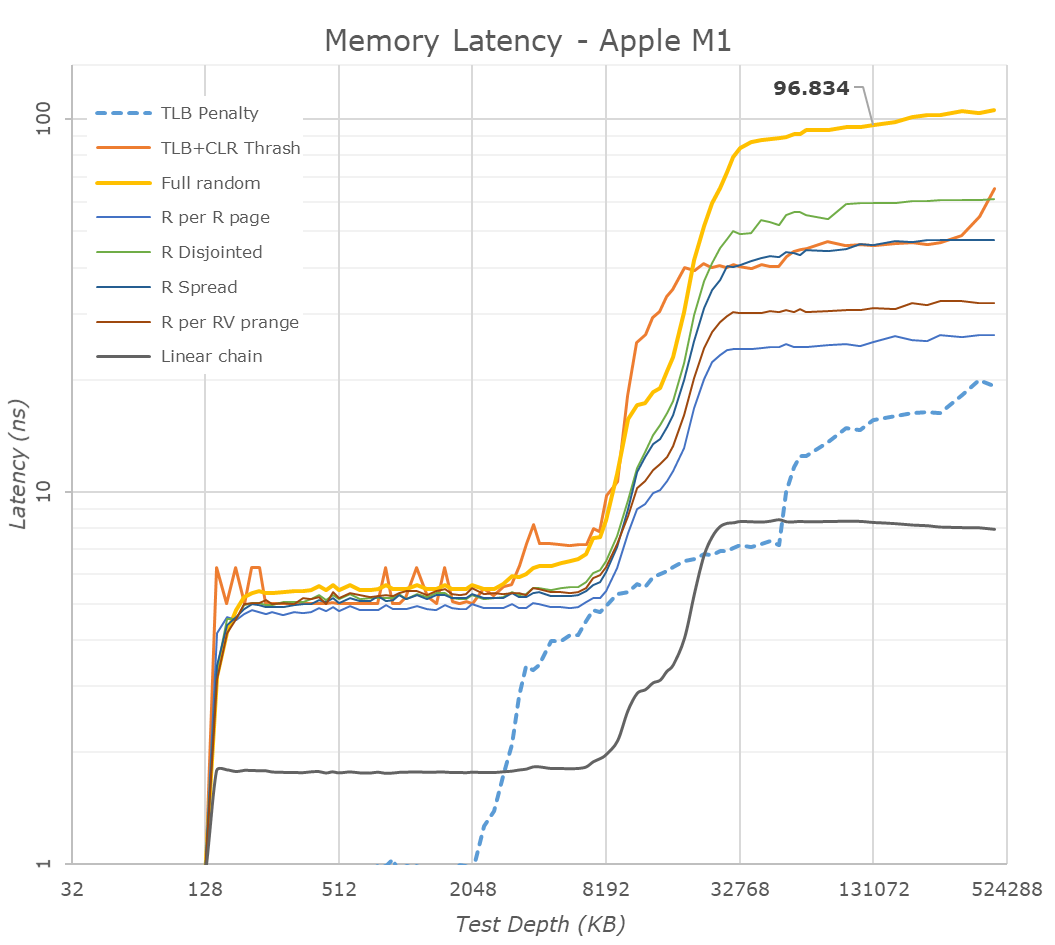
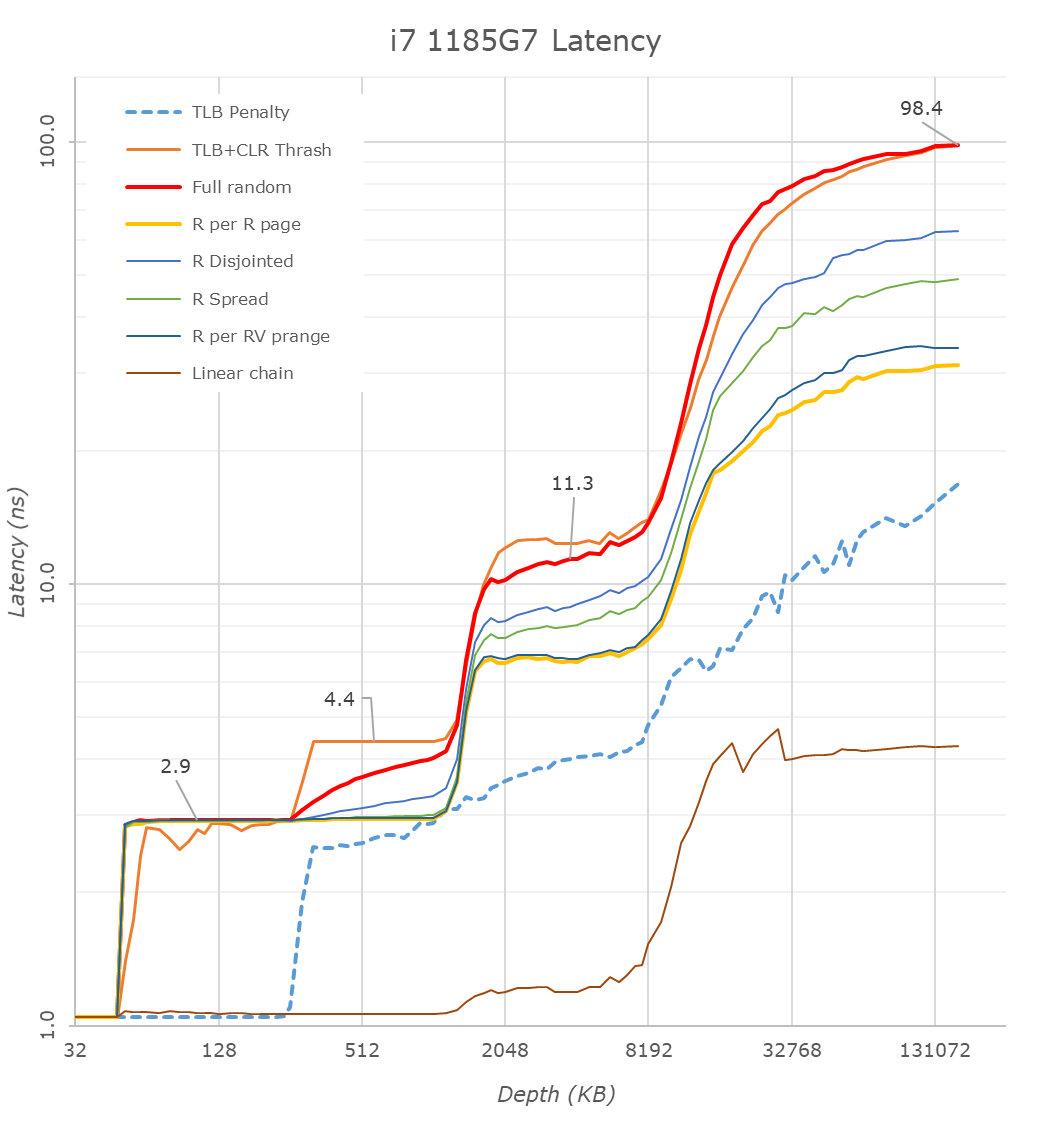
帯域はM1 MBPとIntel MBP(Ice Lake)でチャネル数同じ、前者はLPDDR4X-4266、後者はLPDDR4X-3733なのでメモリ帯域は14%しか向上していません。また、x86/x64最新世代のTiger Lake/ReniorはLPDDR4X-4266に対応しています。レイテンシはM1が96.8ns、Tiger Lakeが98.4nsでほぼ同等です。
Apple M1の実力を最新世代のIntel/AMD CPUと比較。M1が両者を大きく上回る結果ににあるように、SiP化によって消費電力の削減は期待できます。
違います。
SoC-DRAM間がマザーボード上で30cmあったとしても、電気信号の伝送にかかる時間は片道1nsです。仮にSiP化で物理的距離が1/100になったとしてもレイテンシ100usが98.02usになるだけで、CPUにとってDRAMが絶望的に遠いことに変わりありません。
違います。
まず、同一チップ上のCPUとGPUが同一のメモリーコントローラ/DRAMを共有するという意味では、Intelは2011年のSandy Bridge、AMDも2011年のLlanoからUMAです。一歩進んだメモリ空間の共有、コヒーレンシの確保という意味でも、AMDは2014年のKaveriから対応していて、この点においてM1に革新性はありません。
違います。
上記のSandy Bridge、Llanoの世代からかつてのノースブリッジがCPUに取り込まれたため、2011年以降のモバイルPC向け”CPU”のほぼ全てにはGPU/メモリーコントローラが含まれています。
かつてのサウスブリッジはIntelは今でもワンチップ化こそしていませんが、2013年のHaswellからMCMでワンパッケージ内には収められています。AMDは2014年のCarrizoからサウスブリッジ機能もCPUに取り込まれています。
この意味で、x86/x64のモバイルPC向け”CPU”は、かなり以前からSoCです。
違います。
NPUを活かせるアプリケーションは2020年現在では未だ限定的です。もしNPUの有無によってUXが決定的に改善されるなら、NPUありのSnapdargon 8cxを積むSurface Pro Xは同世代のSurface Pro 7よりずっと快適でなければなりませんが、そのような事実はありません。
違います。
CISC/RISCの論争は20年以上前に終わった話です。その後CISCはRISCの美点、RISCはCISCの美点を取り入れたので、現代のCPUはISAがCISCか/RISCかだけで性能が決定されることはありません。
歴史的経緯からx86/x64のデコーダが複雑になりがちなのは事実ですが、5W以下のローパワープロセッサの開発へ向かうIntelにあるように、ISAの差による消費電力増は10~20%のレンジで、さらに性能増によって相殺される分、電力効率の差としてはわずかです。
頑張って最適化してIPC上げたのと、スマホ由来の積極的なDVFS・クロックゲーティング・パワーゲーティングで浮いた消費電力を回しているからです。
気が向いたら書きます。
というか、
ASICやLSIを作ったことある人なら、当たり前すぎることなんだけど、
語弊があるどころかニュアンスが逆なんだよね。
開発者にとって楽になるどころか難しい方向に行くんだよね。
「フロントエンドのみArm命令に置き換えた形」という文言は、
「中身は前のまんまw」「命令セット入れ替えただけなんすわw」「命令デコーダをarm化したSparc64です。」という意味ではなくむしろ逆で、マイクロアーキテクチャが共通になるように、DDRとHBMの差分を見えなくしたりレイテンシを調整したりetc...して、ほとんど全部Verilogを書き直したってことなんだよね。
で、なぜそこまでしてマイクロアーキテクチャを共通化するかっていうと
LSIチップの検証って組み合わせパターンが天文学的数字すぎて分岐網羅とか全然できないんだよね。
ソフトウェア的な分岐網羅に換算したら0.1%となんじゃないかな。
そこでマイクロアーキテクチャを共通化してると、過去チップのLSIテストケースを流用できるわけなんだな。
エッジコンピューティングを使って低遅延を提供、って説明されてるけど、
エッジコンピューティングって事は結局のところ基地局から物理的に近い距離にサーバ配置するって事なわけで
逆にデータセンターなんかを利用しようとするなら基地局によっては近場に無い場合も多いわけで
低遅延が基地局によって使えなくなったりするよね。
どの基地局からも最低限のレイテンシを保証するところにDC建てまくるわけにもいかんだろうし。
MNOがakamaiやfastlyのようなCDNの真似事する感じになるのかな?
{kind=link}
{kind=link}