はてなキーワード: クロックとは
Apple M1の高性能の理由について、ネットはクソみたいな解説記事に溢れている。
技術に明るいはずのはてなーですら某AVライターの間違いだらけの記事に釣られて、300ブクマ超が集まっていて嘆かわしい。
それもこれも後藤センセーがいつまでたっても解説記事を書いてくれないせいではあるが、公開情報が少なすぎるせいでまともなライターほど記事を書けないのも理解できる。
違います。
そもそもM1はDRAMをSoC化/ワンチップ化していません。M1がやっているのはSiP(System in Package、複数チップをワンパッケージに組み込む)であって、eDRAMによるSoCとは全く異なるものです。
SiPとSoCはJavaとJavascriptくらいには違います。
違います。
HBM系のメモリを採用していたらメモリ帯域は大幅に向上しますが、M1は標準DDR系メモリをワンパッケージ化しているだけなので、帯域もレイテンシも変わりません。
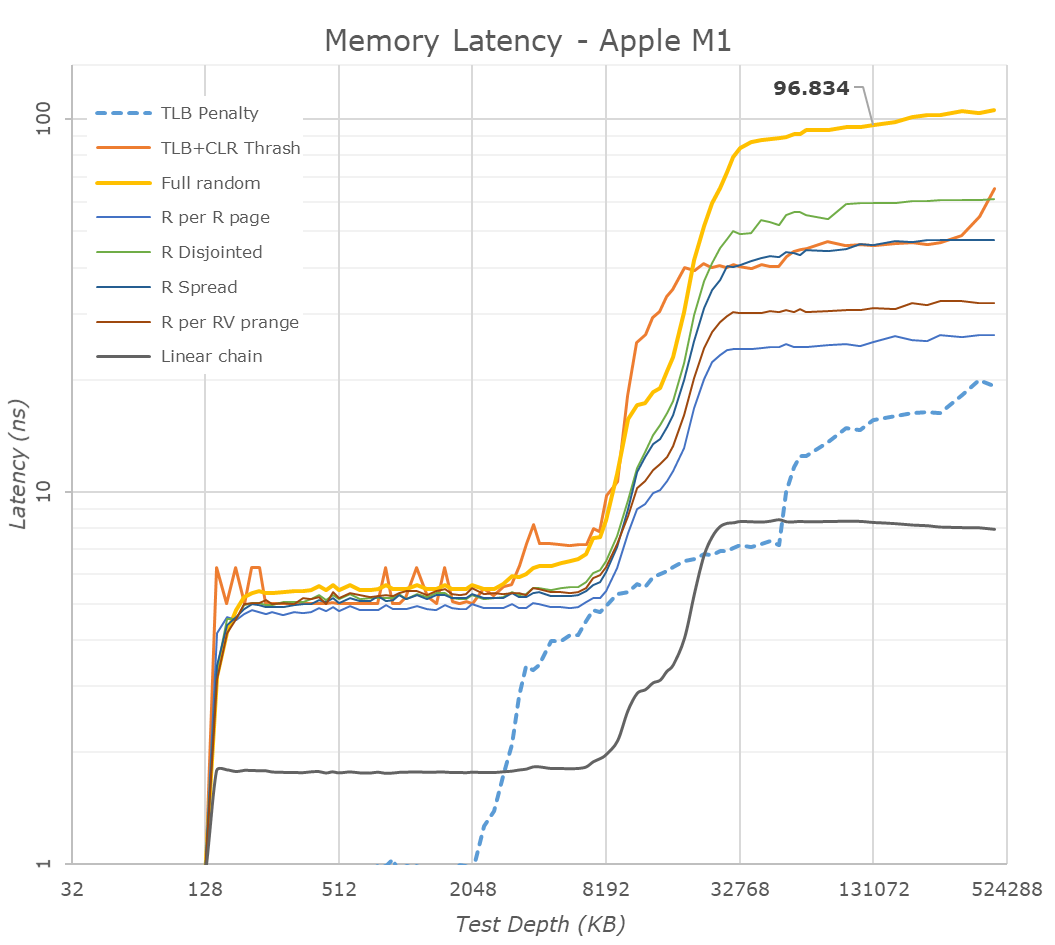
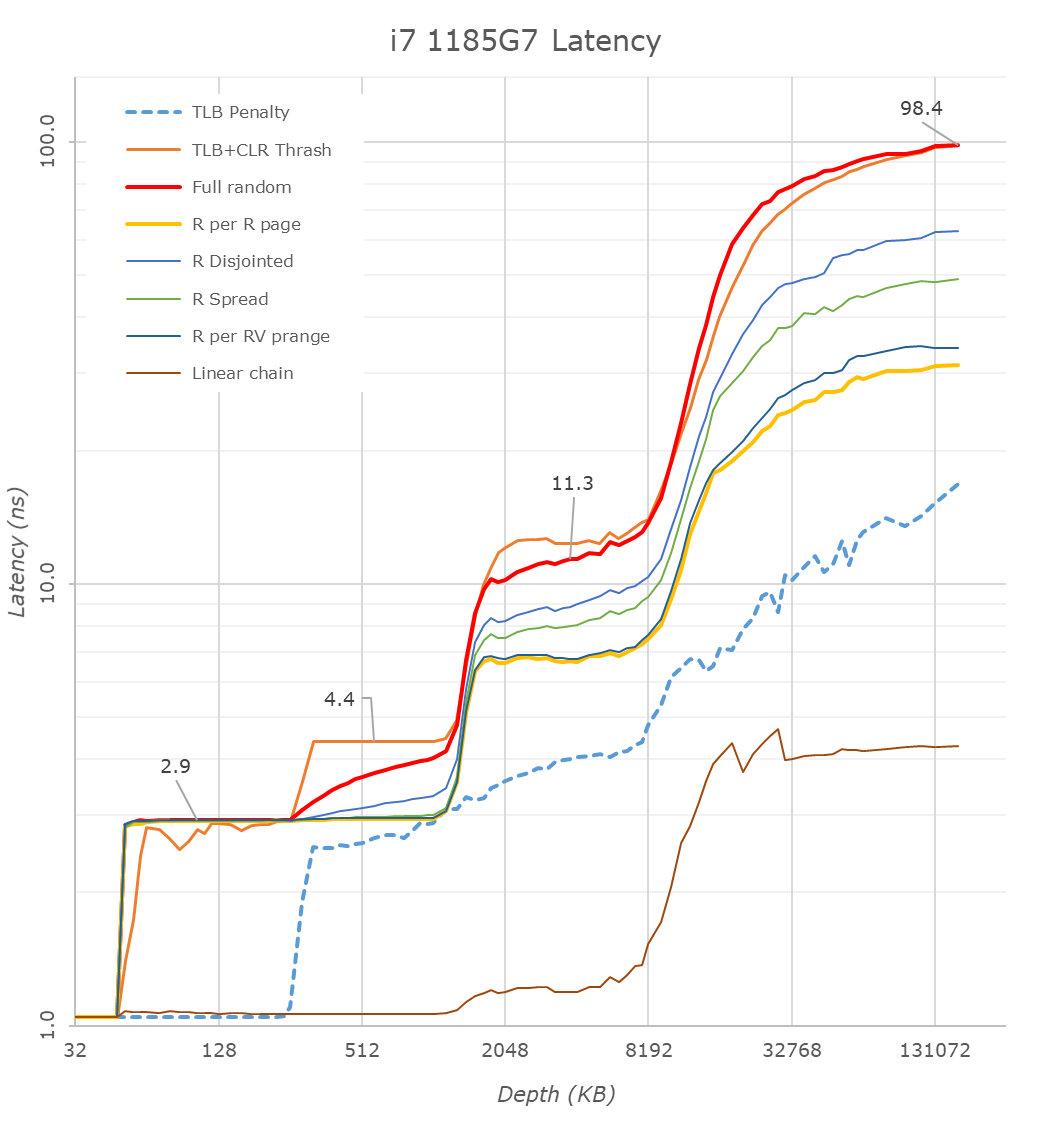
帯域はM1 MBPとIntel MBP(Ice Lake)でチャネル数同じ、前者はLPDDR4X-4266、後者はLPDDR4X-3733なのでメモリ帯域は14%しか向上していません。また、x86/x64最新世代のTiger Lake/ReniorはLPDDR4X-4266に対応しています。レイテンシはM1が96.8ns、Tiger Lakeが98.4nsでほぼ同等です。
Apple M1の実力を最新世代のIntel/AMD CPUと比較。M1が両者を大きく上回る結果ににあるように、SiP化によって消費電力の削減は期待できます。
違います。
SoC-DRAM間がマザーボード上で30cmあったとしても、電気信号の伝送にかかる時間は片道1nsです。仮にSiP化で物理的距離が1/100になったとしてもレイテンシ100usが98.02usになるだけで、CPUにとってDRAMが絶望的に遠いことに変わりありません。
違います。
まず、同一チップ上のCPUとGPUが同一のメモリーコントローラ/DRAMを共有するという意味では、Intelは2011年のSandy Bridge、AMDも2011年のLlanoからUMAです。一歩進んだメモリ空間の共有、コヒーレンシの確保という意味でも、AMDは2014年のKaveriから対応していて、この点においてM1に革新性はありません。
違います。
上記のSandy Bridge、Llanoの世代からかつてのノースブリッジがCPUに取り込まれたため、2011年以降のモバイルPC向け”CPU”のほぼ全てにはGPU/メモリーコントローラが含まれています。
かつてのサウスブリッジはIntelは今でもワンチップ化こそしていませんが、2013年のHaswellからMCMでワンパッケージ内には収められています。AMDは2014年のCarrizoからサウスブリッジ機能もCPUに取り込まれています。
この意味で、x86/x64のモバイルPC向け”CPU”は、かなり以前からSoCです。
違います。
NPUを活かせるアプリケーションは2020年現在では未だ限定的です。もしNPUの有無によってUXが決定的に改善されるなら、NPUありのSnapdargon 8cxを積むSurface Pro Xは同世代のSurface Pro 7よりずっと快適でなければなりませんが、そのような事実はありません。
違います。
CISC/RISCの論争は20年以上前に終わった話です。その後CISCはRISCの美点、RISCはCISCの美点を取り入れたので、現代のCPUはISAがCISCか/RISCかだけで性能が決定されることはありません。
歴史的経緯からx86/x64のデコーダが複雑になりがちなのは事実ですが、5W以下のローパワープロセッサの開発へ向かうIntelにあるように、ISAの差による消費電力増は10~20%のレンジで、さらに性能増によって相殺される分、電力効率の差としてはわずかです。
頑張って最適化してIPC上げたのと、スマホ由来の積極的なDVFS・クロックゲーティング・パワーゲーティングで浮いた消費電力を回しているからです。
気が向いたら書きます。
メモリー上で直接演算ができる、レジスターを持っているスタックマシンという謎なものもさることながら
どうせSIMDでXMMレジスターが15本もあってHyper Threadも対応していることなので
すっ
すっ
とん
っていう機能も欲しいです。すでにあるそうなので使い方がんばって覚えるけれど ベンチマークがまだ不安定100nanoぐらいなんですが・・・たぶんスタックの切り替え間違えている気が
場合によっては8Mのキャッシュも16このスレイブスレッドごとすべて
すっ
すっ
とん
って切り替えてほしいの マスターから見ると16本はスレイブスレッドだからマスタースレッドが切り替わるとスレイブ16スレッドも全部切り替わるから
しかも今はAVX512ぐらいがありましてASCIIだと64文字ぐらいが1クロックで比較演算できる時代になっておりまして
マルチコアでコア番号がわかってればこんなもんただのヘテロプロセスだから大したことはないんだけど
単精度と倍精度の違いは、単純にはシングルコアとデュアルコア。クロック数が速くなるわけではないが、計算量は2倍になる。
これに対して、ターボブーストというのはクロック数酢の物が上がるので計算速度が上がってる。FLOPSの増加にも色々あるのでFLOPSが増加したからと行ってブーストなのか、コア数を増やしたのかの違いが重要になる
まぁ 4クロックはしょうがない。4回掛け算であれば、先行入力もきたいしやすい。実質2クロックには成る 1クロックめが演算終わる頃には4クロック目は どう考えても1次キャッシュにある
あとはストリームでながせばよい。ややRISCではあるが、行列より動画再生支援スロットのほうがわれらがつかう。3x4=12程度のロスはしかたがない。
動画再生支援 すっ トン 1クロック化作戦 予測分岐 といえば 予測分岐なんだけど
あの どこに配線してるの? なんか こう スタックミシン?っていう こう 時間と 空間を 同時に指定しろ ぐらいの騒ぎなんじゃ・・・ロイドーー説明
あの 博士 スタックしない スタックマシーンは スタックマシーンですか?
Intel選手 魔王様とヨシヒコ様がたたかっているとはいえ すごいことをいいだしたーーーー
Intel選手は 大丈夫 さぁ パナソニック選手・・・どうやって対応するか?
さぁ
Google先生のレジスター対応 スタックマシンもかなりひどいけど
あのー ちょっとそこ行く 本AKB48 大島優子さん 撮影上仕方ないとはいえ 技術スタッフ なにげに いいよ とかいってるけど これ ひどくね?
{kind=link}
{kind=link}