どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
『贅沢品としての信念は、近年、欧米社会におけるソーシャル・ディバイド(社会的格差)の拡大と関連付けられています。富裕層は、こうした信念をステータスシンボルとして利用することで、自らの優位性を示すことができる一方、貧困層は、同じ信念を持つことができないばかりか、かえって苦境に陥ってしまうという構図です。』
はっきり言って、下位1%に入るようなクリーチャーでもない限り、図々しく行けば女なんてどうにかなるもんだぞ
俺はまずネットで図々しい態度出せるように練習して、徐々にリアルに持ち込むようになったんだが、はっきり言って相手を選ばずに行けばマジで女を抱くなんて簡単だからな
選びたいって言うやつもいるだろうけど、そりゃあまず女を抱けるようになってからだよ
絶対に女の経験がなくデュフデュフ言ってる弱者男性を相手にしないって
本末転倒なんだけど、弱者男性ならまず図々しく相手との肉体関係求めろ
待ってても絶対救われないぞ
◯◯をしてストレス解消してる、みたいな話を見たり聞いたりするけど、明確に「ストレスなくなった!」って感じる人って結構いるの?
嫌なことあったら、人に話したりとか飲みに行って愚痴言ったりとかはするんだけど、それをやっても、あまり「スッキリした!」という気分にはならない。
みんなは、自分がどんな状態になったら、ストレス解消された!って、判断するの?
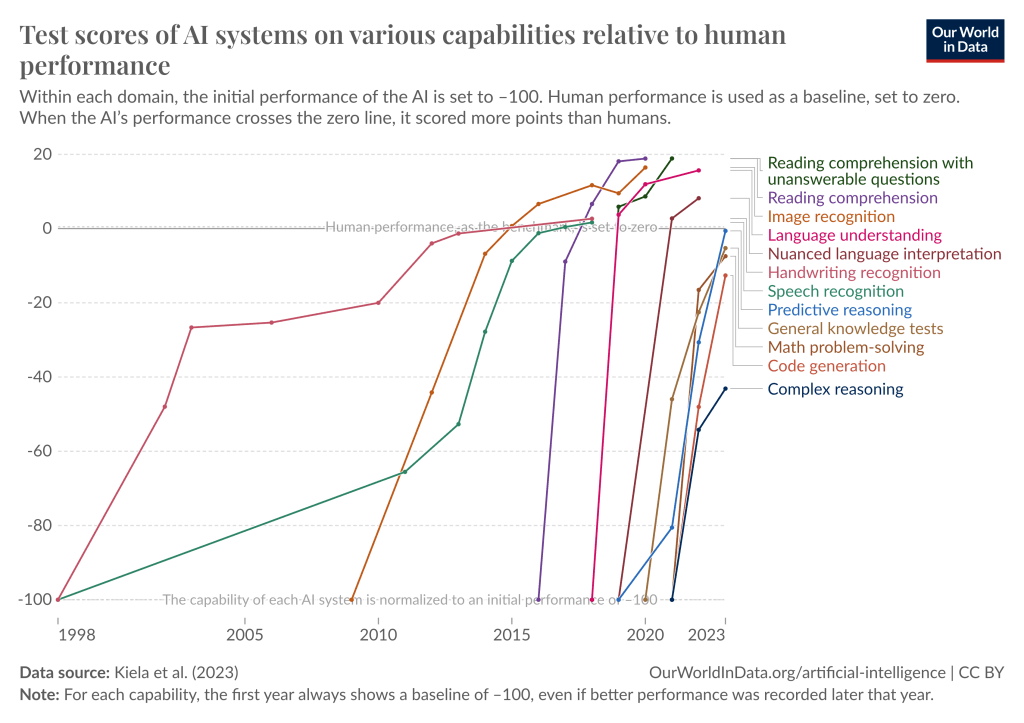
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
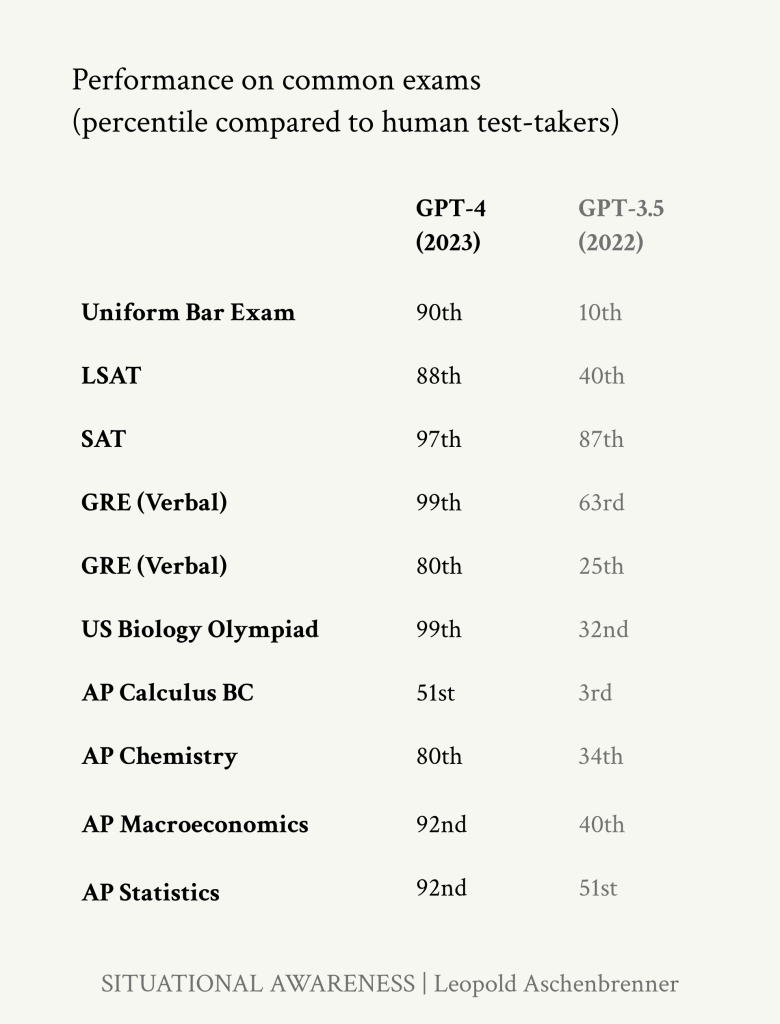
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
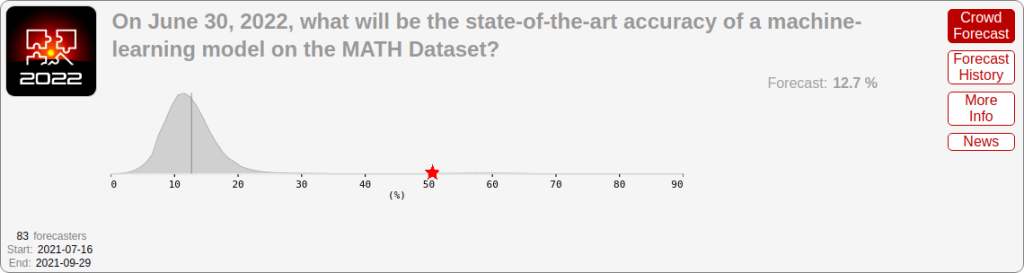
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}