はてなキーワード: 数学とは
あと、どう過ごしたらいいかも共有するね
割愛するよ
ちなみに人は傷付けてないよ
無罪を主張すると公開裁判(一般人に裁判を見られるし、その場で増田の名前や住所などの個人情報を口頭で言われる)になるので、
諦めて罰金払ったよ
罰金払えない場合は、1日5000円で罰金分労働することになるよ
具体的には病院とか、取り調べとかだよ
警察官は激務で、取り調べをしてくれた人はお昼ご飯おにぎり二個しか食べれてなかったよ
ちなみに、取り調べは「調べ」と呼ばれるよ
よくニュースで言われる、「警察の調べに対し、容疑者は~」というのはこの「調べ」から来てるよ
「思わないよ」と言われたよ
あとは「なんで警察官になったんですか?」とか
まず全裸でぴょんぴょんさせられるよ
何も持ってないことを証明するためにするらしいよ
お風呂は週2回
本読み放題だよ
1日4回まで本が変えられるよ
野矢茂樹の本読んだり、
たまにストレスで体調崩して、吐いたりしてたよ
相部屋の人とおしゃべりを楽しんだよ
家族みたいに仲良くなったよ
ちなみに、増田は認知症の人と同部屋になって実質介護させられてたよ
夜中に徘徊されたり、壁を叩いたり、叫ばれたりして部屋を変えて貰ったよ
あとは、隣の部屋では、発狂、脱糞やおもらしをしてしまう人もいたよ
これはとても注意した方がいいよ
仲良くなろうね
警察官が得意なのは、上から来た命令をそのまま実行することだけだよ
マルチタスクが苦手な集団なので、急かしたり、作業Aをしている時に声をかけたりしない方がいいよ
体調が悪そうだったら、体調の心配をしてあげたり、
警察官とサシの場面があったら「こんなこと○○さんにしか話せないんですが~」とか
「○○さんがお話聞いてくれて少し落ち着きました」とか言ってあげると、
心を許されてる感を与えられて、仲良くなれるよ
仲良くなれると、移動するときに手錠を緩めて貰ったり、
ヤバイ人間と相部屋になった時に、部屋替えの考慮をしてくれるよ
ちなみに、警察にはむかったりすると特別な独房(汚い、臭い、)に入れられるから気を付けてね
あと警察と留置所で捕まっている人たちとでは、明確な上下関係があるよ
怒鳴られたり、家畜みたいな扱いをされるよ
増田は、いくら加害者(それに冤罪の可能性がある人もいる)でも人間扱いされない、
精神的に追い詰められている環境で、取り調べを受けていることになるよ
3食出るよ
揚げ物が、朝と夜に必ず出るよ
もう一生コッペパン食べたくないよ
普通に朝夜美味しくて満足して太ったよ
自弁という制度があるよ
自弁でパンを頼むと、警察官が近所のコンビニで適当なパン買ってきてくれるよ
Xで取り調べは黙秘した方が良いと言われてたけど
実際にそうしてた増田の相部屋の人が、
黙秘続けた結果、接見禁止(弁護士以外の誰とも面会できない)とか勾留延長をされてたよ
嫌がらせだと思うよ
増田は、普通に雑談したり、思ったことを正直に喋ったりしてたよ
増田は格闘技をやっていたので、刑事さんと格闘技の話題で盛り上がったよ
検察官とおしゃべりするよ
裁判所では、「凄くきちんとされているんですね、こんなにきちんと喋る人いるんだなとびっくりしました」と言われたよ
こんなところで褒められると思わなかったよ
検察官は、さすがに警察官より頭がいい人たちが多い印象を受けたよ
判決が出るまでたまーに通うことになるよ
裁判所は、基本私語厳禁だけど、警察官は英語分からない人が殆どみたいだから、
英語で小声で会話ならなんも言われないよ
前科がある場合、どうやって外国に入国ハックするかとか、英語で情報交換をしてたよ
警察は世論を気にする組織で、何か事件が起きた時に「警察、無能だなー」と言われるのを嫌がるから
とりあえず検挙数を増やして、逮捕して、数だけ対策増やしてやってる感アピール出す事情があるよ
補足すると、口論レベルの話でも警察にすぐ通報する人がいたらそういう人から離れた方がいいよ
増田はとりあえず会社をクビ(実際は退職勧告)になったので、すぐ就活したよ
翌月には就職先も決まって、有給休暇を使い切った後にすぐ転職先で働き始めたよ
転職して増田の年収は150万くらい上がったので、色々何とかなったよ
あと色々あってパートナーもできたよ
パートナーに申し訳が無いから、正直にこの事を話したら、理解を得られたよ
増田は後述した通り、心的外傷後ストレス障害になったよ
増田はこのことでフラッシュバックを起こしたりして、カウンセリングに通っているよ
あとは、周りを心配させたことや、真っ当なパートナーに対して増田は前科者・犯罪者という肩書があることに
罪悪感があるので、申し訳ない気持ちと向き合いながら、苦しんで仕事をしているよ
示談不成立の理由は、多分だけど、被害者の方が(増田の誤字で加害者と書いていたよ、申し訳ございません)、
示談不成立にしたのだと思うよ
海外旅行に行く時に、ちょっと厄介な手続きをする羽目になったり、
入国禁止で送り返されることもあるから、増田はその可能性が悲しいよ
フェルマーの最終定理は存在しないことの定理だから存在すると仮定して背理を導出する背理法の強力なものを編み出すことによって初等的に解ける可能性が高い。しかし、我が国の
理学部数学科ではそのようなアプローチを試みた論文は存在しない。これについて、行政の地区担当員から、そんなテクニックは存在しない、という囁きがあるだけで、東京都内の数学者、
地方の数学者からも、初等的な解法なるものは1つも聞かれない。Wikipediaには、無限降下法という不完全なもので極めて不完全に終わったという10年一日のような記載があるだけで、
具体的な論文はどこにもない。それどころか、10年前から、 FLT、FLT、と連呼されて、バクサイのSNSでも、到達不可能な定理とだけ言われるだけで何の具体性もなく、自分で考えた形跡
どころか、 n=4の場合の完全な証明は、実は赤チャートの一番最後に掲載されているが、それも理解できないといったような状況であるから、何が面白いのか理解できない。無限降下法は、
不完全なものであって不完全なものでは数学上技術にならないことはもちろんであるが、いずれにせよ、具体的に研究した形跡はどこにもないのであるから、完全な噓である。バカは到達不可能な
ものを設定し、多くの技術によって到達できると喜ぶが、現在ではもはや状況が変容し、そのような技能は必要がないと解される。数学の技術はいわば光っているものとか概念でもよいが、
数学の多くの偉大な定理は出版されたときに驚愕されると書いているだけなので、しかし、文化的な構成物で技術的に光っているものはどこにあるかといっても、最も分かりやすいのは、
バクサイSNSにいる者が何らかの人工知能を用いていることは明らかである。仮に行政が完全なものによる技術を開発し、人工知能から電波をヒトの大脳に送信しヒトの大腸を操作して排便を
促す装置を発明し作動させたとしても、事理の当然に、その人工知能がある場所にヤクザが拳銃を撃ちこんで終わりになるだけである。特定の個人がその人工知能の中にいるから自分が人工知能
の中で活躍できない結果として、刺されたり燃やされたりするのではなく、そもそも、その人工知能があることによって、自然状態として生活ができないことから、人工知能の装置自体を破壊した
方がいいように思われる。しかし、金が清掃工場に運ばれて燃やされたことが一度流行し、ただの紙屑になったという事実と、平成25年から今更になって金が全てと言っているのは甚だしく矛盾
している。
マルクス主義の理論はソ連によってナンセンスの塊に変えられていたが、ペレルマンにその塊を噛み砕くことができたのは、彼はなんであれ政治と名のつくものにいっさい興味がなかったからとみて、まず間違いはないだろう。
「グリーシャの辞書によれば、”政治”とは貶し言葉だったのです」とゴロヴァノフは言った。
「たとえば、私が良かれと思って、なにか組織的な運動を計画したとしましょう。たとえそれが、私たちの大切なセルゲイ・ルクシンを助けるための運動だったとしても、彼はこう言ったでしょう。
『それは政治だよ。そんなことより問題を解くことに集中しよう』。
ここでぜひともわかってほしいのは、彼は本気でそう思っているということです。彼は、政治と名のつくものはなんであれ、大嫌いなのですよ」。
こういうペレルマンの姿勢は、ロシア知識人の伝統となっている政治的プロセスへの嫌悪とはあまり関係がなく、むしろ彼にとっては数学以外の一切に興味がもてなかったことに関係しているのだろう。
私が黒羽刑務所で解いた、国際数学の問題は東大生なら誰でも知っている不定方程式を用いると、4で割った余りが0,3のときには実現しないことが出て来るが、余りが1,2
のときであることを支持するのに、 4k+1→4k+2→4k+9 という完全補題を発見して証明する。しかし、完全補題は、要点補題、簡潔補題に比較して、ものを発見することが
非常に難しく、鋭利かつ飛躍的な内容を含む。 4k+1→4k+2は非常に鋭利であり、 4k+1→4k+9は飛躍的であるし、対応する証明も専門的になって知能指数は
要らないが込み入った論証となる。完全補題はそれこそ、円のように完全なものであるから、発見できる者はまれである。 補題を用いた証明技術も、技術である。 これに対して、連結支配集合
を用いる場合もあるが、連結支配集合は、情報科学の分野で取り上げられるもので、特に教員から習って訓練を受けていないとそれを用いることは難しい。
連結支配集合は、 誘導部分のグラフが連結しているときに、いう
「尊師」は個人ブログでも論文上でも癇癪起こしてて、取り巻きは我田引水で論文掲載したり賞作ったりしてて、@math_jinとかいう素人信者は海外の数学コミュニティ荒らして日本の恥を広めてるし、誰も関わりたくないと思うのも当然
「尊師」は個人ブログでも論文上でも癇癪起こしてて、取り巻きは我田引水で論文掲載したり賞作ったりしてて、@math_jinとかいう素人信者は海外の数学コミュニティ荒らして日本の恥を広めてるし、誰も関わりたくないと思うのも当然
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
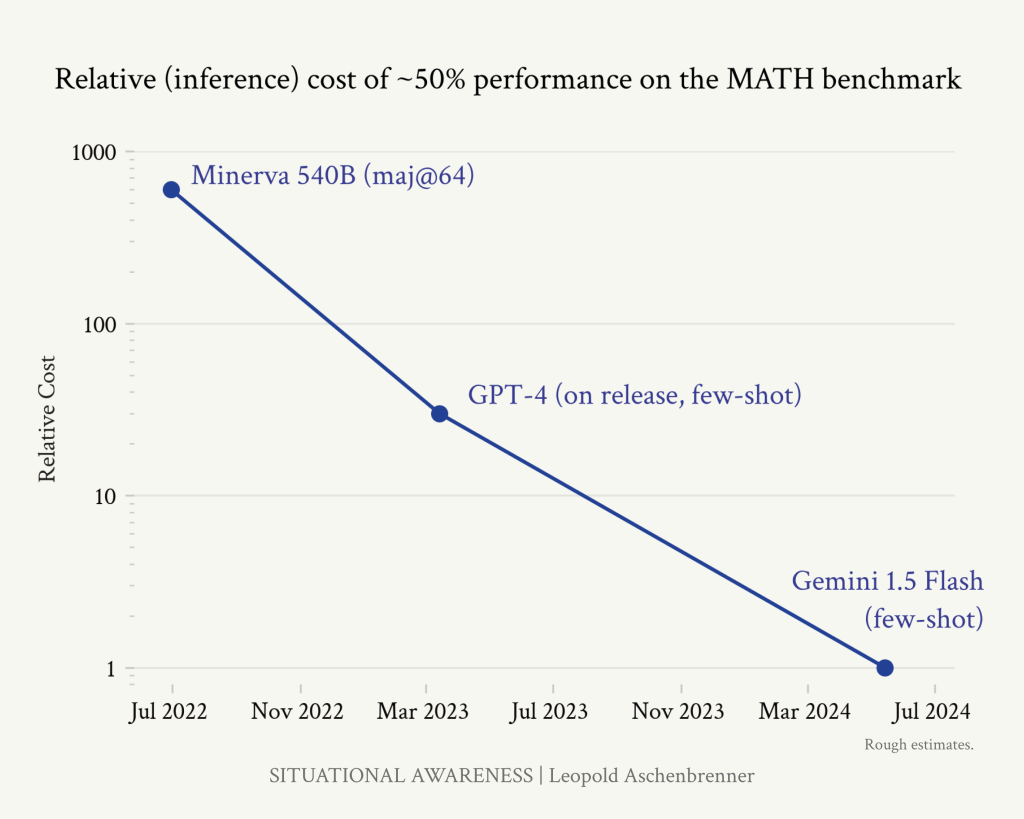
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
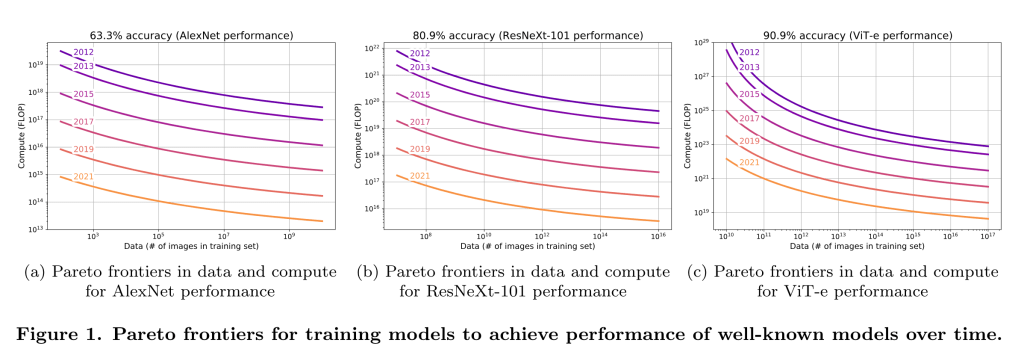
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
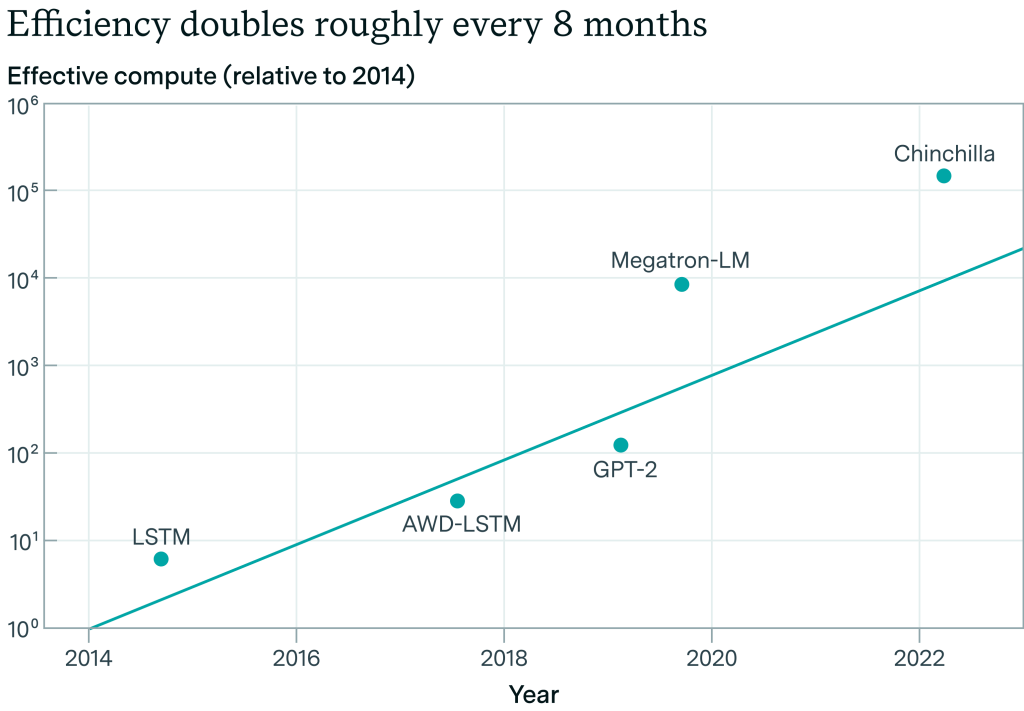
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
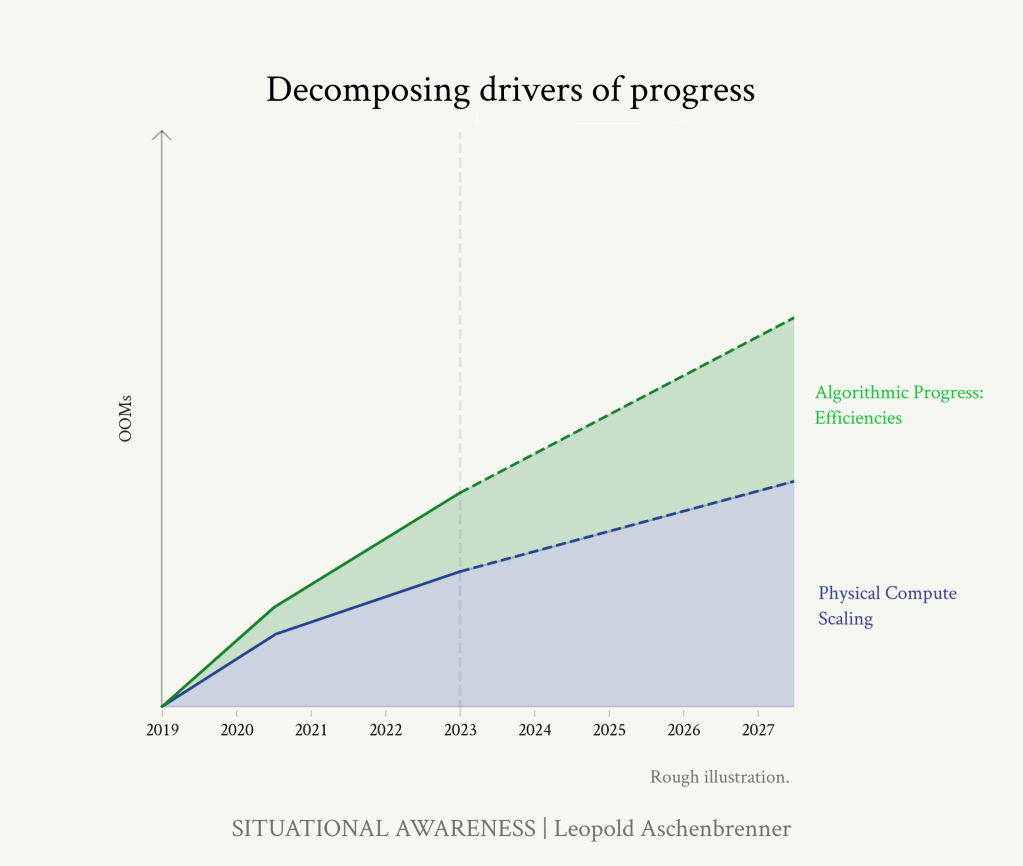
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
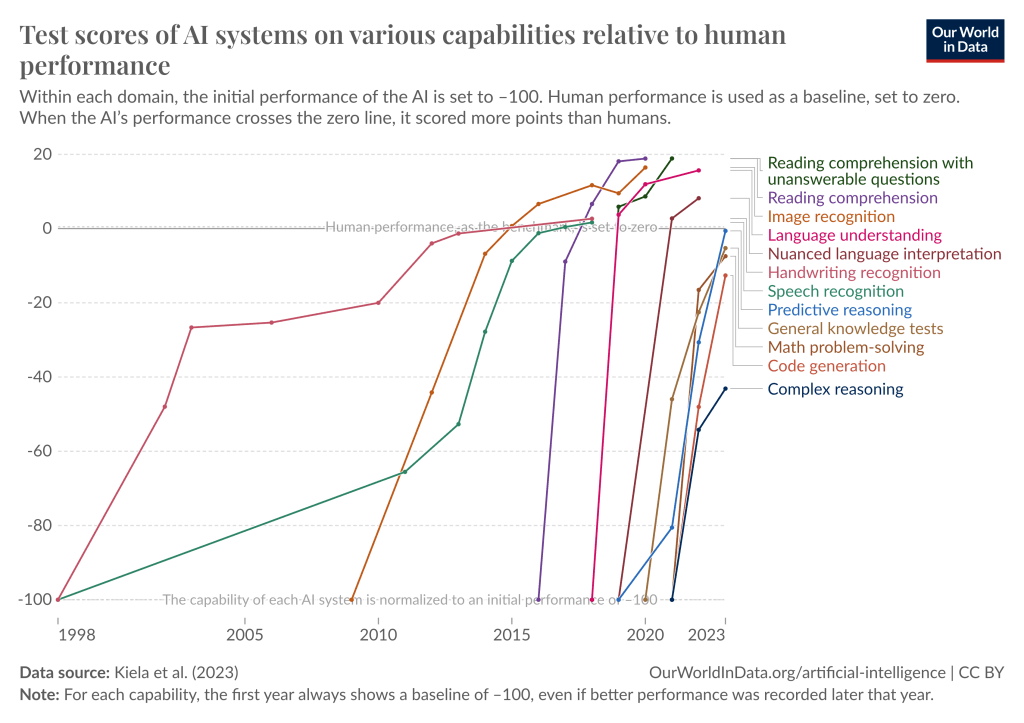
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
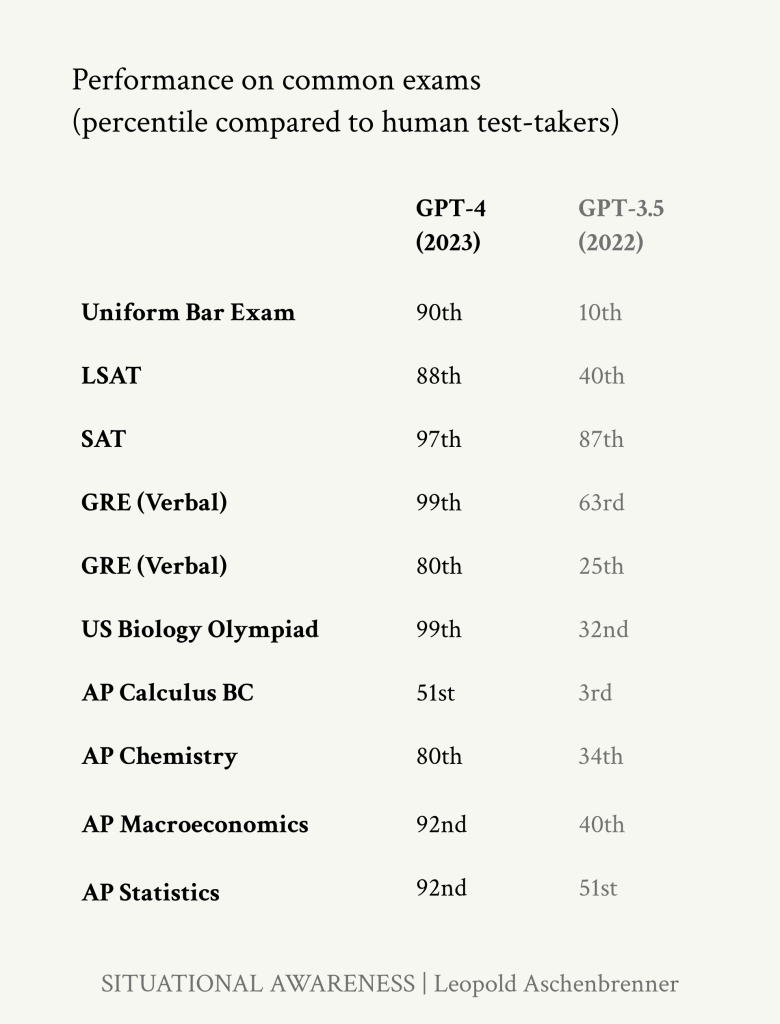
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
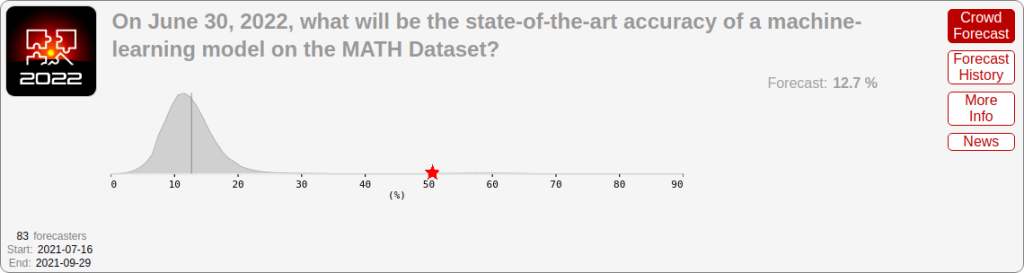
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
私たちは今、基本的に人間のように会話できるマシンを手にしている。これが普通に思えるのは、人間の適応能力の驚くべき証であり、私たちは進歩のペースに慣れてしまったのだ。しかし、ここ数年の進歩を振り返ってみる価値はある。
GPT-4までのわずか4年間(!)で、私たちがどれほど進歩したかを思い出してほしい。
GPT-2(2019年)~未就学児:"わあ、もっともらしい文章をいくつかつなげられるようになった"アンデス山脈のユニコーンについての半まとまりの物語という、とてもさくらんぼのような例文が生成され、当時は信じられないほど印象的だった。しかしGPT-2は、つまずくことなく5まで数えるのがやっとだった。記事を要約するときは、記事からランダムに3つの文章を選択するよりもかろうじて上回った。
当時、GPT-2が印象的だった例をいくつか挙げてみよう。左:GPT-2は極めて基本的な読解問題ではまあまあの結果を出している。右:選び抜かれたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争についてある程度関連性のあることを述べた、半ば首尾一貫した段落を書くことができる。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt2_examples-1024x493.png
当時、GPT-2について人々が印象に残った例をいくつか挙げます。左: GPT-2は極めて基本的な読解問題でまあまあの仕事をする。右: 厳選されたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争について少し関連性のあることを言う、半ば首尾一貫したパラグラフを書くことができる。
AIの能力と人間の知能を比較するのは難しく、欠陥もあるが、たとえそれが非常に不完全なものであったとしても、ここでその例えを考えることは有益だと思う。GPT-2は、その言語能力と、時折半まとまりの段落を生成したり、時折単純な事実の質問に正しく答えたりする能力で衝撃を与えた。未就学児にとっては感動的だっただろう。
GPT-3(2020年)~小学生:"ワオ、いくつかの例だけで、簡単な便利なタスクができるんだ。"複数の段落に一貫性を持たせることができるようになり、文法を修正したり、ごく基本的な計算ができるようになった。例えば、GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt3_examples-1.png
GPT-3について、当時の人々が印象に残った例をいくつか挙げてみよう。上:簡単な指示の後、GPT-3は新しい文の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。上:簡単な指示の後、GPT-3は新しい文章の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
繰り返しになるが、この比較は不完全である。しかし、GPT-3が人々に感銘を与えたのは、おそらく小学生にとって印象的だったことだろう。基本的な詩を書いたり、より豊かで首尾一貫した物語を語ったり、初歩的なコーディングを始めたり、簡単な指示やデモンストレーションからかなり確実に学習したり、などなど。
GPT-4(2023年)~賢い高校生:「かなり洗練されたコードを書くことができ、デバッグを繰り返し、複雑なテーマについて知的で洗練された文章を書くことができ、難しい高校生の競技数学を推論することができ、どんなテストでも大多数の高校生に勝っている。コードから数学、フェルミ推定まで、考え、推論することができる。GPT-4は、コードを書く手伝いから草稿の修正まで、今や私の日常業務に役立っている。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_examples-3.png
GPT-4がリリースされた当時、人々がGPT-4に感銘を受けた点をいくつか紹介しよう。上:GPT-4は非常に複雑なコードを書くことができ(中央のプロットを作成)、非自明な数学の問題を推論することができる。左下:AP数学の問題を解く。右下:かなり複雑なコーディング問題を解いている。GPT-4の能力に関する調査からの興味深い抜粋はこちら。
AP試験からSATに至るまで、GPT-4は大多数の高校生よりも良いスコアを出している。
もちろん、GPT-4でもまだ多少ばらつきがある。ある課題では賢い高校生よりはるかに優れているが、別の課題ではまだできないこともある。とはいえ、これらの限界のほとんどは、後で詳しく説明するように、モデルがまだ不自由であることが明らかなことに起因していると私は考えがちだ。たとえモデルがまだ人為的な制約を受けていたとしても、生のインテリジェンスは(ほとんど)そこにある。
https://situational-awareness.ai/wp-content/uploads/2024/06/timeline-1024x354.png
続き I.GPT-4からAGIへ:OOMを数える (3) https://anond.hatelabo.jp/20240605204704
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
(数学的真偽はさておき)IUT理論は世界の数学者から完全に相手されてないよ。
下記のサイトによくまとまってる。
最近のIUT界隈 - tar0log
エドワード・ウィッテンは、幾何学的なラングランズ・プログラムの一部とアイデアとの関係について「電気・磁気の二重性と幾何学的なラングランズ・プログラム」を執筆した。
ラングランズ プログラムに関する背景: 1967 年、ロバート ラングランズは、当時同研究所の教授だったアンドレ ヴェイユに17ページの手書きの手紙を書き、その中で大統一理論を提案した。それは、数論、代数幾何学、保型形式の理論における一見無関係な概念を関連付ける。読みやすくするためにヴェイユの要望で作成されたこの手紙のタイプされたコピーは、1960 年代後半から 1970 年代にかけて数学者の間で広く流通し、数学者たちは 40 年以上にわたり、ラングランズ プログラムとして総称されるその予想に取り組んできた。
弦理論やゲージ理論の双対性の背景を持つ物理学者は、カプースチンとの幾何学的ラングランズに関する論文を理解できるが、ほとんどの物理学者にとって、このトピックは詳細すぎて興味をそそるものではない。
一方で、数学者にとっては興味深いテーマだが、場の量子論や弦理論の背景には馴染みのない部分が多すぎるため、理解するのは困難(厳密に定式化するのは困難)。
短期的にどのような進歩があれば、数学者にとって幾何学的なラングランズのゲージ理論解釈が利用できるようになるのかを見極めるのは、実際には非常に難しい。
ゲージ理論とホバノフホモロジーが数学者によって認識され評価されるのを見られるだろうか。
弦理論の研究者として取り組んでいる物理理論が数論として興味深いものであることを示す多くのことがわかっている。
ここ数年、4 次元の超対称ゲージ理論とその親戚である 6 次元に取り組んでいる物理学者は、臨界レベルでの共形場理論の役割に関わるいくつかの発見を行っているため、この点を解決する時期が来たのかもしれない。
過去20年間、数学と物理学の相互作用は非常に豊かであり続けただけでなく、その多様性が発展したが、私は恥ずかしいことにほとんど理解できていない。
これは今後も続くだろう、それが続く理由は場の量子論と弦理論がどういうわけか豊かな数学的秘密を持っているからだ。
これらの秘密の一部が表面化すると、物理学者にとってはしばしば驚きとなることがよくある。
なぜなら、超弦理論を物理学として正しく理解していないから。つまり、その背後にある核となる考え方を理解していない。
数学者は場の量子論を完全に理解することができていないため、そこから得られる事柄は驚くべきものである。
したがって、生み出される物理学と数学のアイデアは長い間驚くべきものになるだろう。
1990 年代に、さまざまな弦理論が非摂動双対性によって統合されており、弦理論はある意味で本質的に量子力学的なものであることが明らかになり、より広い視野を得ることができた。
完全帰納法の原理は誰が発見したか知らないけど、数学の基本は、演繹法で、それの対になる帰納法自体はそれしかないし、完全帰納法というのはなんでも出来る可能性がある有名な
奴で他にもあるけど、あれば突破口になるだろうということで昭和時代は一世を風靡した。現在でこれを知っている奴はただの犯罪者で公共社会の害悪でしかない。
民事訴訟法82条1項は、裁判所は、救助の決定をしなければならない、と定めているが、お前がそう書いたことはどうでもいい。問題は、民事訴訟法の体系にこれを設定するための
証明はされているかどうかが問題である。同法82条1項本文を読むだけでは、その性質を判定することは困難である。なぜなら、82条1項本文はさして驚愕に値するような規定ではない
からである。82条1項および2項は、民事訴訟の本案判決に至るまでの経過的な規定であって、数学で言えば、補題である。補題は定理と違い、驚愕的である必要があるかどうか分から
ない。なぜなら補題程度であれば、国際数学の半分が人が解ける問題でも出て来るからである。補題の設定証明が著しく難しいならば、国際数学の易問すら誰も解けないことになる。従って
民訴法82条1項2項はあまり魅力的な規定ではない。法82条1項2項には精神があるとされるが、民訴法の目的は、民事手続きの簡易迅速な処理であるとされている。しかし、民事
手続の簡易迅速な処理という法目的と精神からは、82条1項2項の規定は出て来ないので、82条1項2項の背景には、憲法25条の福祉国家の精神があるのではないかと推測されて
いる。民事訴訟法といえども、法目的だけから出来ているわけではなく、憲法の条文の精神に由来するものもある可能性がある。
第82条
訴訟の準備及び追行に必要な費用を支払う資力がない者又はその支払により生活に著しい支障を生ずる者に対しては、裁判所は、申立てにより、訴訟上の救助の決定をすることができる。ただし、勝訴の見込みがないとはいえないときに限る。
訴訟上の救助の決定は、審級ごとにする。
それ自体がなかなか出来なくても、哲学の構成原理は分かったわけなので、何らかの完全無欠なものを整備し、それをちょっときつく出せば、バクサイを支配しているいわゆるお母さん
で、かつては警察よりも正しいと信じられていたが、最近はもう裏切っていて飽きているババアを制圧するという目的に到達するし、令和6年6月4日時点で必要とされている様々な
目的を達するのに参考になる基礎的な考察である。要するに円に由来する完全無欠なものをきつく出すところに本質があるのではないかと思う。
さて、インターネット上には、円に由来する完全無欠なものであって、それを聴取することによって犯罪者を完全に排除できる道具として、Youtubeがあるわけなので、Youtubeまたは
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}