はてなキーワード: ディープラーニングとは
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
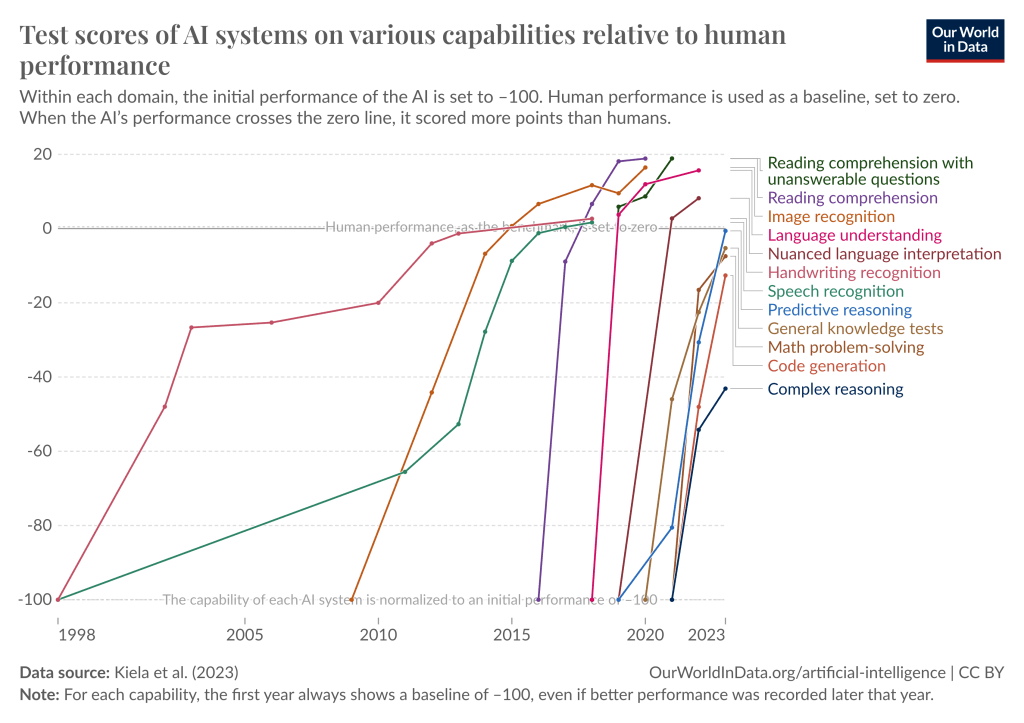
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
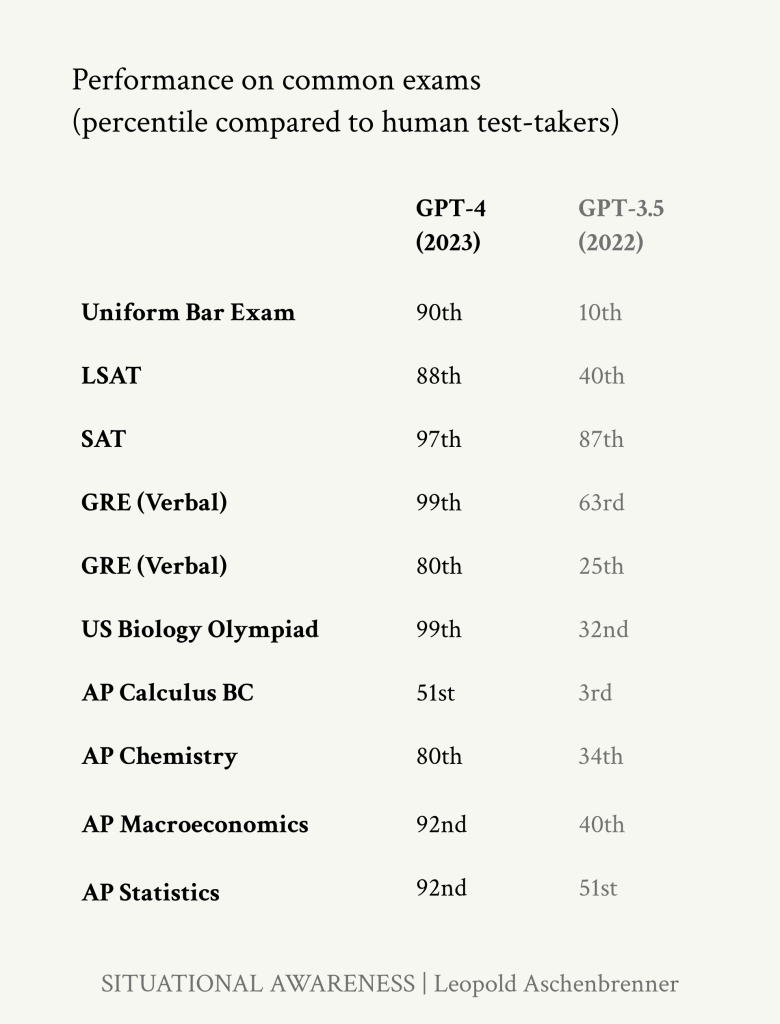
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
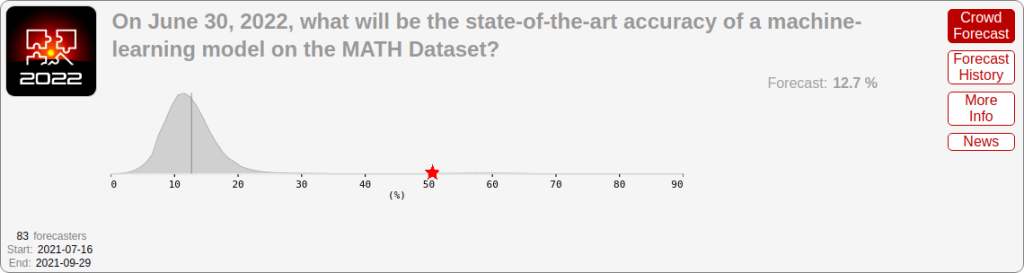
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
はい、GPUの仕組みや重要性を分かりやすく説明した本や教材はいくつかあります。例えば以下のようなものが挙げられます。
1. 『GPUを支える技術』 株式会社ボーンデジタル (2023年)
GPUの基本的な仕組みから、最新のGPU技術まで幅広く解説されています。技術者向けですが、図解も多く分かりやすい内容です。
2. 『つくりながら学ぶ! PyTorchによる発展ディープラーニング』 小川雄太郎 (2020年)
機械学習フレームワークPyTorchを使ってGPUプログラミングを学べる実践的な書籍です。サンプルコードを動かしながら理解を深められます。
GPUの歴史から最新アーキテクチャまでを網羅的に解説。コンピュータサイエンスの基礎知識がある大学生・大学院生向けです。
4. Udemy「GPUプログラミング入門 - CUDAとOpenCLで学ぶGPUコンピューティング」
オンライン学習プラットフォームUdemyの動画講座。GPUの基本からCUDAやOpenCLでのプログラミング方法まで解説しています。
ただし、ご指摘の通り小中学生向けのGPUの仕組みを分かりやすく教える本は少ないかもしれません。GPUはCPUに比べると新しい技術なので、教育現場での普及はこれからという面があるでしょう。
技術の発展に合わせて、今後さらに分かりやすい入門書や子ども向けの教材が増えていくことが期待されます。ITリテラシー教育の一環として、GPUについても触れる機会が増えるかもしれませんね。
ChatGPTは、人工知能に基づくテキスト生成プラットフォームであり、ユーザーが入力したプロンプトに対して自然な文章を生成することができます。
一方、ヒガシマルのちょっとどんぶりは、日本の食品メーカーが提供する即席どんぶりのたれの商品名です。
ChatGPTは、様々な質問に答えたり、文章を作成したりすることが可能で、ディープラーニング技術を活用しています。
それに対して、ヒガシマルのちょっとどんぶりは、簡単に美味しいどんぶりを作ることができる食品であり、料理の手助けをする製品です。
つまり、ChatGPTは情報技術の分野におけるサービスであり、ヒガシマルのちょっとどんぶりは食品業界の製品という、全く異なるカテゴリーに属しています。
さらに詳しい情報については、ChatGPTに関する解説記事や、ヒガシマルのちょっとどんぶりの商品情報を提供する公式サイトを参照すると良いでしょう。
KIMITは、抱き心地や動きの再現などリアルさを追求した新ブランド。KIMIT ラグドールは、本物の動きをデータ化して、ディープラーニングにより再現しています。
未だに「謎の半導体メーカー」程度の認識の方になぜNVIDIAが時価総額世界4位なのかをあれこれ説明する必要があるので短めにメモ。半導体業界のすみっこの人間なので機械学習まわりの説明は適当です
・~1993年 AI冬の時代。エージェントシステムがさほど成果を挙げられなかったり。まだ半導体やメモリの性能は現代とくらべてはるかに劣り、現代のような大規模データを用いた統計的処理など考えられなかった。2006年のディープラーニングの発明まで実質的な停滞は続く。
・1995年 NVIDIAが最初のグラフィックアクセラレータ製品NV1を発売。
・1999年 NVIDIAがGeForce 256発売。GPUという名が初めて使われる。以降、NVIDIAはGPU業界1位の座を守り続ける。
・2006年 GPGPU向け開発基盤CUDAを発表。以降、その並列計算に特化した性能を大規模コンピューティングに活用しようという動きが続く。
・2006年 ディープラーニングの発明。のちのビッグデータブームに乗り、これまでよりはるかに高性能なAIを模索する動きが始まる(第3次AIブームのおこり)
・2006年 CPU業界2位のAMDがGPU業界2位のATIを買収、チップセットにGPUを統合することで事実上自社製品をNVIDIAと切り離す戦略に出る。CPU業界1位のインテルも、同じく自社CPUに自社製GPUを統合する動きを強める。NVIDIAはこれまでの主力だったGPUチップセット製品の販売を終了し、データセンター向けGPGPUのTeslaシリーズ、ゲーム用外付けGPUのGeForceシリーズ、ARM系CPUと自社GPUを統合したTegraシリーズの3製品に整理する。このうちTeslaシリーズが性能向上やマイクロアーキテクチャ変更を経て現代のAIサーバ製品に直接つながる。GeForceシリーズはゲーマー向け需要や暗号通貨マイニング向け需要も取り込み成長。Tegraシリーズは後継品がNintendoSwitchに採用される。
・2012年 ディープラーニングが画像認識コンテストで圧倒的な成績を収め、実質的な第3次AIブームが始まる。
・2017年 Transformerモデル発表。これまでのNN・DLと異なり並列化で性能を上げるのが容易=デカい計算機を使えばAIの性能が上がる時代に突入。
・2018年 IBMがNVIDIAと開発した「Summit」がスパコン世界ランキング1位の座を5年ぶりに中国から奪還。全計算のうち96%がGPUによって処理され、HPC(ハイパフォーマンスコンピューティング)におけるGPUの地位は決定的になる。NVIDIAの開発したCPU-GPU間の高速リンク「NVLink」が大規模に活用される。「Summit」は2020年に「富岳」にトップを奪われるまで1位を維持。
・2018~2021年 BERTやXLNet、GPT2など大規模言語モデルの幕開け。まだ研究者が使うレベル。
・2019年 NVIDIA CEOジェスン・ファン(革ジャンおぢ)が「ムーアの法則は終わった」と見解を表明。半導体のシングルスレッド性能の向上は限界に達し、チップレットを始めとした並列化・集積化アーキテクチャ勝負の時代に入る。
・2022年 NVIDIAがH100発表。Transformerモデルの学習・推論機能を大幅に強化したサーバ向けGPUで、もはや単体でもスパコンと呼べる性能を発揮する。H100はコアチップGH100をTSMC N4プロセスで製造、SK Hynix製HBMとともにTSMC CoWoSパッケージング技術で集積したパッケージ。※N4プロセスは最新のiPhone向けSoCで採用されたN3プロセスの1つ前の世代だが、サーバ/デスクトップ製品向けプロセスとモバイル製品向けプロセスはクロックや電流量が異なり、HPC向けはN4が最新と言ってよい。
・2022年 画像生成AIブーム。DALL-E2、Midjourney、Stable Diffusionなどが相次いで発表。
・2022年 ChatGPT発表。アクティブユーザ1億人達成に2カ月は史上最速。
・2023年 ChatGPT有料版公開。Microsoft Copilot、Google Bard(Gemini)など商用化への動きが相次ぐ。各企業がNVIDIA H100の大量調達に動く。
・2024年 NVIDIAが時価総額世界4位に到達。半導体メーカー売上ランキング世界1位達成(予定)。
こうして見るとNVIDIAにとっての転換点は「ディープラーニングの発明」「GPGPU向けプログラミング環境CUDAの発表」「チップセットの販売からコンピューティングユニットの販売に転換」という3つが同時に起こった2006年であると言えそう。以降、NVIDIAはゲーマー向け製品やモバイル向け製品を販売する裏で、CUDAによってGPGPUの独占を続け、仮装通貨マイニングやスパコンでの活躍と言ったホップステップを経て今回の大きな飛躍を成し遂げた、と綺麗にまとめられるだろう。
AI…というか現在ディープラーニングで行われてるアルゴリズムって世間的にはそこまで複雑じゃないよね
ChatGPTのTは「Transformer」というディープラーニングモデルから来てるけど、その解説からして長くないし…
この複雑じゃないのに色々出来るのもディープラーニングが世界中で使われてる要因の一つだと思う
そしてこの複雑じゃないという特徴は誰でも解説役になりやすいし、それを見た誰もが実装しやすいという傾向も導くだろう
だからAIの規制というのをやるにしても学習データセット・学習済みモデルの配布を一部は規制する事は出来ても
アルゴリズムはどうやったって広まるのを防ぐ事は出来ないよね
これで10年後20年後になったら学習データを用意する方法がもっとシンプルに効果的になって誰でも出来るようになる可能性や
そしてディープラーニングによって出来る事も更に広がった上でアルゴリズムは大して複雑になってない可能性だって大いに考えられる
その場合はとてもじゃないけどほんの少しの規制だって無理になると思うが
https://wirelesswire.jp/2023/08/85203/
はてブでも過去のプレスリリースと食い違っていないかと指摘されてたが、以下の記述がおかしい。
日本で最大規模のディープラーニング計算資源は産総研が管理するABCI(AI橋渡しクラウド基盤)である。
ただし、4世代前のV100を1088基と、3世代前のA100(40GB)を120基しかない。足してもわずか1208基である。
ABCIの公式サイトの説明には、V100を搭載した「計算ノード(V)」が1088台、A100を搭載した「計算ノード(A)」が120台とある。
https://abci.ai/ja/about_abci/computing_resource.html
が、ちょっと読めば分かるように、ABCIは1ノードに複数のGPUが搭載されているのだ。「計算ノード(V)」は1ノードにつき4基、「計算ノード(A)」は1ノードにつき8基のGPUが載っている。
某サイトで児童ポルノ問題になってるのはAI生成そのものではなく、それをエサにモノホン販売に誘導する輩がいることと認識している。AI生成そのものがアウトというわけではないはずだ。
AI生成による写実的な非実在青少年の絵が児童ポルノであるとは言えない。
一方で写実的なAIが描く人物とは非実在なのか?ここはなかなか難しい。そもそも人物のデータがあるから人が生成されるわけだが、描かれた人は合成された何かであり実在はしないはずだ。だが元となった人物がいないことを示すのも難しい。元データをかっさらっても、AIアルゴリズムを解析してもおそらく無理だ。ディープラーニング等のビッグデータ解析は結果はわかるが過程はわからないからだ。
主観的にこれに似てる!とは言えるかもしれない。しかしそれではこれがクロかシロかは各論だろう。裁判所判断になる。少なくともAI生成ツールとして使った場合、その利用者は実在するとある人物を作ろうとしたと言えるか?写真を取る、イラストを描く、と比較しても行為として微妙だろう。
過去の世界の事例から見ると、非実在青少年のポルノ絵は有罪になったケースがいくつかある。大筋としては、それが存在しうる、という判決だ。
日本で争われたケースとしては、被告は絵であるとしたが、判決としては実在する少女がいることが理由で有罪となったものがある。ここでもあくまで、実在することが争点だった。絵が写実的で写真と見間違うものかどうかは論点ではなかったはず。
論点を間違ってはいけない。AIが写真と同じクオリティの絵を生成するから児童ポルノとなるわけではない。存在する、つまり被害者がいるかどうかがシロクロの分かれ目である。
これを写実的かどうかで議論すると間違ったことが起こる。例えば、出力を調整して写真ではないことを明らかにすればセーフになるのか、等。つまり、明らかに被害者がいるが一次ソースの写真でなくAI加工したイラストだった場合は?それはアウトだろう。
何かこうだという結論があるわけではないが、まあ、言えることとしては、AI絵によってアウトセーフの判断が難しくなった世の中だ。だが現状でAI絵による非実在青少年はクロとは言えない、たとえあってもケースバイケースである。
この状況でAI絵を起点に非実在青少年の規制が進むのはまずいし、逆に、リアルでないイラストによる加害が見逃されても問題である。印象でAI規制議論や非実在青少年イラスト規制議論が加熱することだけは避けておきたいところだ。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}