はてなキーワード: 科学とは
例えばAとBの説があったとして、「反ワク」というのは「反A」と言ってるに過ぎない。
何の意味も成してない。それなのに論破できると思っているのは、Bを信仰しているからである。
そもそも「反ワク」という言葉は、複数の解釈ができて厳密に意味を限定できない。
例えば、ある特定の工場で製造された特定の時期のmRNAコロナワクチンに問題があると主張するのも反ワクだし、
この世に存在する全てのワクチンに問題があると主張するのも反ワクだ。当然いくらでもグラデーションがある。
あなたがテレビゲームをプレイしてバグを見つけそれを報告したら、「反ゲーム」と言われることを想像して見て欲しい。
「反ワク」という言葉を使う人はそれと同じ事をやっているのだ。
科学的な議論をするなら、言葉の定義は奇数と偶数のように厳密にするように努めるべきである。
「反ワク」なんて論外中の論外だ。
こんな言葉を使う議論はネットの便所の落書きだけだと思いたいが、
年齢を重ねると妊娠出産時に問題が起こりやすくなる、と言う科学的な事実ですらタブー視されいるわけだから
リモートワークの恩恵もあり無意識でポルノを見てしまう生活を変えたくて始めた。
数年前から何度か読んでいた「インターネットポルノ中毒 やめられない脳と中毒の科学」の影響もある。
何度も読んでいることからわかるとおり自分はインターネットポルノ中毒である。
(あなたがポルノ中毒でなくとも依存や脳に関するトピックに興味がある人は楽しく読めるはず)
このチャレンジの一番の目的はポルノ視聴をやめること。二番目が頻繁なオナニーをやめること。
始めてから1ヶ月でポルノの視聴は1回、オナニーは1回、セックスが2回だった。
以下感想。
初日はなんてことなかった。2日目から徐々にムラムラしてくる。
3〜4日目は気を抜くと常にエロいことを考えていた。頭の中は妄想でいっぱい。仕事が全然手に付かない。
ここで身体にも変化が出始める。股間と肛門の間の筋肉が射精時と同じようにビクンビクン動くようになる。これがけっこうキツイ。身体的な依存。
4日目以降は完全に狂っていて、なんとかオナニーする理由を探し始める。疲れてるとか、仕事で嫌なことがあったとか、集中力が落ちたとか。
ここをなんとかして乗り越える強靱な精神力が必要。身体も悲鳴を上げていて妄想で疑似射精しているのか連続してビクンビクン動いている。
7日目以降も同様の症状が続くが、ここまでくると我慢できている自分が少し誇らしくて徐々に楽しくなってくる。
10日ぐらい我慢すると達成感がありここまで来たらご褒美オナニーしてもいいかなと清々しい気持ちになってくる。
だがこれはただ単にオナニーするための形を変えた言い訳なので意志を強く持って我慢する。
12日目ぐらいで我慢できなくなったのでセックスした。一度射精してしまうと快感が蘇り我慢が難しくなる。
16日目でポルノを見ながらオナニーをした。達成感と後悔が半々ぐらい。だがここで断念する理由はないので翌日から再挑戦する。
継続するコツは罪悪感を持たずに「初回の挑戦は16日継続できた。次は20日継続しよう」と考えることだと思う。
翌日からの2周目の挑戦は初回よりも簡単だった。3〜4日目のキツさは無い。10日目ぐらいのメンタルで再開できる。
また2週間弱で1回セックスした。初回同様、翌日以降にオナニーしたくなったがこうなるのは理解していたので回避は容易。
そのまま継続していま1ヶ月目ぐらい。
ポルノを漁っていた時間が完全にフリーになったので新しい事に取り組めているし
集中力に関しては個人的に仕事の生産性を数値化しているんだけど明らかに向上している。
いまはポルノを見ていないがXでたまに流れてくるエロ動画を見てしまうと脳が怖いぐらい素早く反応してしまう。
もう涎が出るほど官能的でいますぐパンツを脱いでオナニーしたくなる。しばらくそのシーンを反芻してしまう。
自分はソフトドラッグの経験があるのでこういった中毒性、依存性のあるものを比較的理解しているつもりだが
ポルノの依存性の強さはソフトドラッグの比ではなかった。(この辺りの話は本にも詳しく書いてある)
脳内でスイッチが入ると女の子の口や舌、身体の柔らかさや肌が触れあう感覚がフラッシュバックして落ち着くまで時間がかかる。
オナニーが習慣になっていたときはなかったが、いまはこのフラッシュバックが習慣を元に戻してしまう一番の危険性になっている。
----
書き忘れたこと。
自分の楽しみを手放してしまった寂しさみたいな気持ちがある。好きだったおもちゃが壊れたときのような寂しさ。
エッチな動画を見つけてオナニーする行為自体は純粋に好きだったんじゃないかな。
Xで好きな動画を見つけて今夜はこれ観よう!みたいなわくわく感を楽しみを手放してしまった。
「ゲホゲホせきをしているノーマスクの女と同じ電車に乗った後、インフルに掛かった!マスクくらいしろ!なんでコロナ前より衛生観念が後退してるんだよ!」ってお怒りのポストが流れてきたんだけど、衛生観念の後退を嘆くポストが流れてきたんだけど、SNSで気に食わない相手はすぐにブロックするような、暴言パワハラで知られる人を担当を据えて、マスク・手洗い・検査・ワクチン・隔離と封じ込めの科学的な根拠がある全ての対策に対して、広報・実施・検証の全ての段階で完全に失敗したのに反省一つもせず、信頼感を損なわせてればそうもなるよねと言う感想。
顔の要素を分解すると
・俺の眉毛
・嫁の目(に俺のまぶたまつ毛)
・嫁の鼻
・嫁の口
・嫁のパーツ配置
・俺の輪郭
・俺の眉毛
・俺の目
・俺の鼻
・俺の口
・上半分俺のパーツ配置
・下半分嫁のパーツ配置
・嫁の輪郭
ナショジオの菌類特集読んでたら、霊芝(干からびたカタツムリみたいなキノコで、漢方になる)はマジで癌に効く可能性があるらしい。
西洋科学の分析でわかるのはいいが、昔の人間はなぜ、これが体にいいとわかったんだ。癌患者AとBの一方には霊芝を食わせて、もう一方には食わせない、を百年単位で繰り返し、別のコミュニティと共有する中で確立したのか。
それとも、薬効を謳ったもので偽物もたくさんあるわけで(水銀とか)、近代の研究で迷信が淘汰された中でたまたま残った本物が、いかにも昔からの叡智の結晶みたいに見えるだけなのか。わからん。
追記。
不思議な点をもっと書き連ねると、同じ癌患者Aと Bに霊芝を与えるのでも、Aと Bで体質も違えば癌の種類も違うだろうから、薬効はそう簡単にわからないはずだ。
A Bどころじゃない膨大なサンプルが必要だと思うが、今度は誰が、それを記録して伝承しているのだ。シャーマンとか本草学か。
また、霊芝だけに使用を限定したとも思えないので、薬草も使えば、動物の骨とか、鉱物とかも併用しただろうし、その中で、「よし、霊芝だな…」と特定され成果として残るのはマジですごく不思議。
いや、特定されきってないから変な迷信とかがまだいっぱい残ってるんだ、とか、動物の進化が奇跡的な形を生むように、膨大な時間の流れにはそれだけのトライアンドエラーを許す余地があるとか、今は人道的にNGだけど、昔は奴隷とか賎民にめちゃくちゃやれたから発達したんだ、とか、合理的な説明はつくかもしれないが、「?」というデカい疑問符は消えない。
もっとも、ナショジオでも「効く可能性がある」ぐらいに書かれているだけなので、実際にどの程度奏功するかどうかは知らない。「信じて飲んだけど効かなくて俺死んじゃったよ」と言われても、線香ぐらいは立ててもいいが責任は取れないので、付記しておく。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
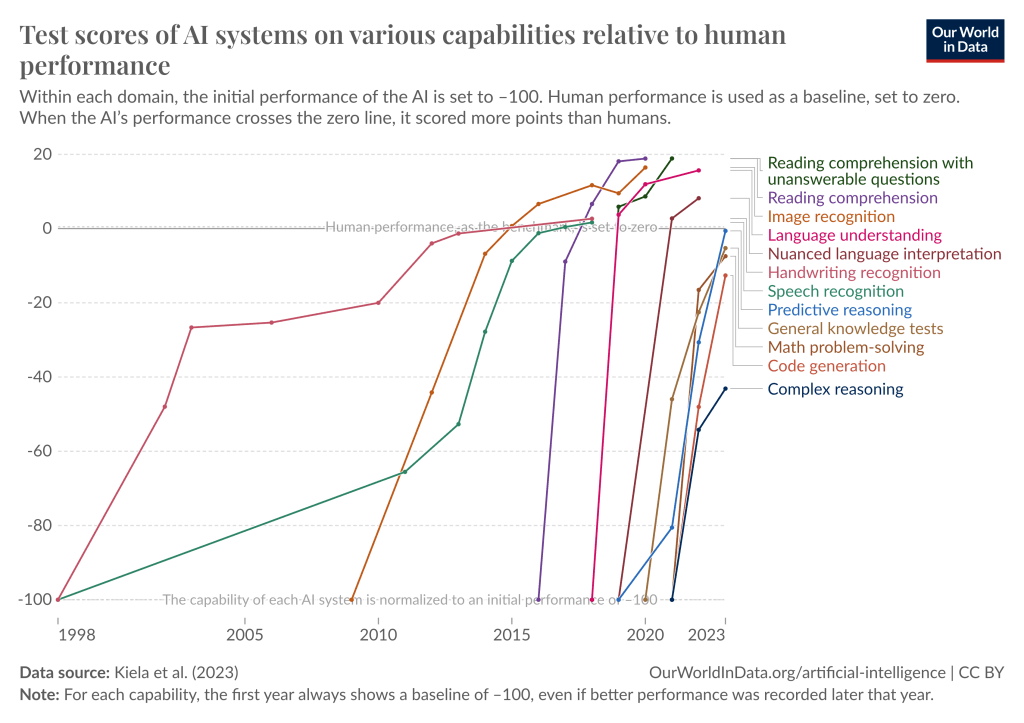
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
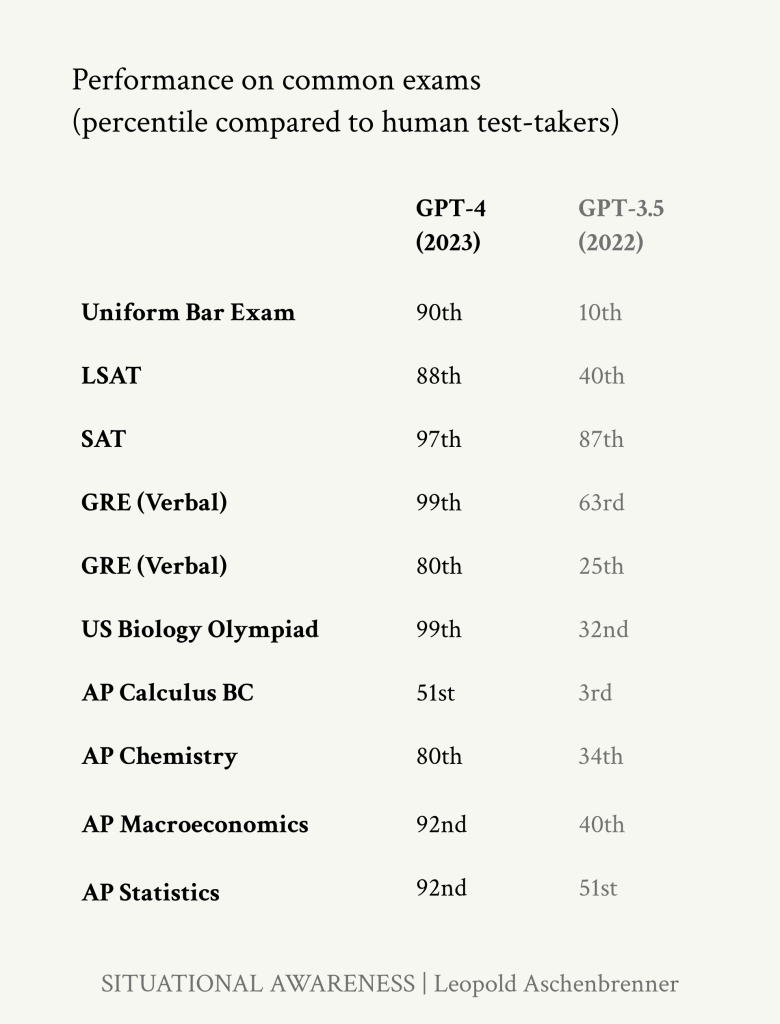
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
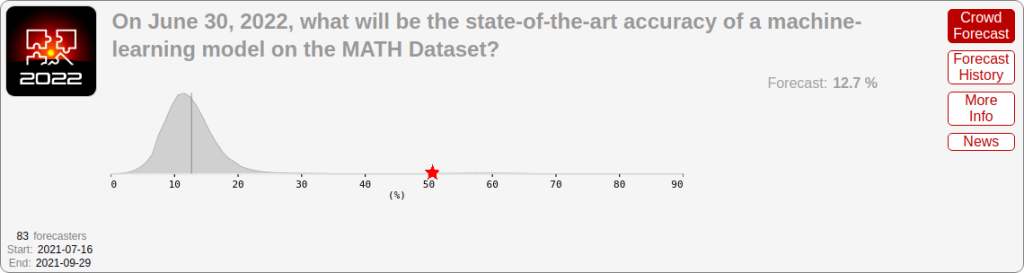
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
自分は男で、恋愛工学の本も興味本位で何冊か読んだことはあるが、どれも内容は軽くて表面的な印象を持った。
性欲を満たせない男から金を搾り取るための、ある種の貧困ビジネスにさえ感じた。
Amazonでレビュー数が多く星も多い書籍を読むと、著者は自身の主張を「科学的」と言いつつ「男/女は原始時代からの本能で…」などと言う。
令和の今、お前は原始時代から進歩していないのか、と突っ込みたくなる。何が科学的だ。
再現可能性や実証の概念を理解もせず、学術的な根拠はなく、専門用語らしい言葉を使えば「科学的」と考えるらしい。
馬鹿らしい。
僕は自分自身を女性からモテるとは思っていないけど、交際相手をつくろうと思えば、今まで大抵できてきた。
肉体関係は確かに満たされるし、自分もそういう欲求は当然あるけど、
結局は価値観が似ているとか、話して楽しいとか、優しくしてくれる/自分もできるとか、
相手の仕事に興味を持てて、その話を聞くのが楽しいとか、そのほうが大事だったな。
そんな短絡的な目先のことしか考えられない時点で、そいつは人間的に底が浅い。
弁護士とか医療職とかの専門職の女性と話すのは楽しいし、仕事にあぶれる人ではないから自立していて刺激をもらえたな。
性欲ばかり考えて仕事を疎かにする奴なんて、男でも女でも尊敬できないじゃん。
好きだから。
そういうことじゃない?
ってなんでそんなウソつくんだろうね
だって、恋愛工学とかホストとか持ち出すまでもなく、モラハラ気質のクソ男に恋人いるとか日常じゃん
「女性に人として接する」ってモテと無関係とまでは言わないけど、数ある要素のひとつに過ぎないのは明らかなので、「それでモテます」は、ウソでしかないじゃん
なんでなんだろ、を考えてみた
思うに、この人たちって、
「顔とかオッパイじゃなく人格を評価する“正しい”男は恋愛において報われる」
もちろん、現実はシンプルでも公正でもないから、リアル女はアナとカネしか評価しないクズ男にも普通に沼ってて、彼らだってこのことを知らないわけじゃない
でも、彼らはこの現実を認められない
だって、そのメルヘンな脳内世界に止まる限り、「モテない」男性イコール“正しくない”存在なわけだから、思う存分、叩いたりマウント取ったりしてよいので、こんなお手軽快感供給マシーンを手放すわけにはいかない
どころか、「女性に人として接してる非モテ」に対して、「モテないのは人として接してないから〜(決めつけ)」とか暴力を振るってた側に反転しかねない
だから、この嘘を見つけたら、彼らは群がらざるを得ない
数しかないのだ
科学的な根拠がないだけでなく、多くの人の感覚にも反する嘘を突き通すには、数しかないのである
彼らには、「相手と人として接しないのはモテじゃない」、と反論する道も残ってはいる
これは理の通った対応に見えて、その実「私は相談に対し独自基準のモテを定義し自語り始めた役立たずです」と自ら開陳しているに等しい
しかし、それでも彼らにはその道は残っている
なぜなら無能であることは彼らにとってさしたる痛みではないから
彼らは、自分が
「君がモテないのは女性に人として接してないからだよ」などという嘘を前提に、非モテを悪/格下/劣等に位置づけ、叩いたりマウントをとって快感を搾取していること
女性のPTSD(心的外傷後ストレス障害)が歴史的に「ヒステリー」と呼ばれたことで、精神疾患の研究が遅れたとされています。以下にその背景を説明します。
ヒステリーという言葉は、古代ギリシャ時代から使用されており、女性の心身の症状を説明するために使われました。この言葉自体は「子宮」を意味するギリシャ語の「ヒュステラ」に由来し、女性特有の疾患と考えられていました。19世紀になると、女性の心理的症状や身体的症状を包括的に「ヒステリー」として診断する風潮が強まりました。
2. **誤解と偏見**:
ヒステリーの概念は、しばしば女性の感情や行動が過剰で非合理的だという偏見に基づいていました。これは、女性の症状が真剣に研究されることを妨げ、実際の病態生理学的な理解が進まない原因となりました。
現代のPTSDの概念は、主に戦争帰還兵の症状として認識され始めました。しかし、戦争帰還兵だけでなく、女性や一般市民の間でもトラウマの影響があることは認識されていませんでした。女性の症状が「ヒステリー」として片付けられたため、トラウマとその影響に関する理解が遅れたのです。
4. **研究と診断の変化**:
20世紀後半になって、精神医学は徐々にトラウマの影響とその結果としてのPTSDの概念を認識し始めました。1980年にアメリカ精神医学会がDSM-III(精神障害の診断と統計マニュアル第3版)にPTSDを公式に含めたことが、この変化を象徴しています。
これらの歴史的な背景により、女性の精神疾患に関する研究は大幅に遅れました。現在では、PTSDを含む精神疾患は性別にかかわらず科学的に研究され、適切な治療法が求められています。
全知全能の神様がいきなり空を裂いて現れて、全ての自然法則を書き換えて去っていくという事態をあり得ないとは言い切れない。
ただ経験則として到底あり得るとは考えられない。
なので可能性よりも蓋然性を考えていきましょうというのが科学らしいけど、じゃあ可能性ってほぼ意味のない概念にならないか?って思った。
現時点のこの世の法則が突然変わらないとは言い切れないのだから全ての可能性はあるともないとも言える訳で、じゃあ全ての物事についてハナから蓋然性を考えるのが道理じゃないか?
反証可能性の認められる状態では可能性も考えよう、とかそういう事なんだろうか。
反証可能性にしたって全知全能の神様に事態を変化させられる事がないとも言い切れない訳だし、あまりにも荒唐無稽(と経験則上思われるよう)な事態は予め想定から排除した上で、みたいに程度問題で運用されてるんだろうか。
カントの定言命法ってなんかそれっぽい用語を使ってるから何らかの原理みたいに思えるけど、要するに仮言命法とは違って論理性という錦の御旗のないただの主義・主張でしかないんじゃないか?って思った。
他人に最低限の敬意を持ちましょう。って言われてまあそうかもねっていう素朴な共感はあるけど、それは感覚の問題であってそこに論理はない。もっと言えばその感覚すらも社会的に形成されたもの、というかキリスト教の倫理規範そのものなんじゃないか?って思う。
じゃあカントによる道徳の再定義・正当化も、論理性・合理性という現代(?)風な科学のツールで飾り立てつつ、結局は聖書の価値規範をリブートしただけなんじゃないか?って思った。
もっと遡れば、じゃあその他敬を良しとする社会はどう構築されたののか?無から湧いてきたのか?って問題が出てきそうだけど。
神様がそうしたからです、という答えなら簡単に済む。人にそういう機能がプリインストールされてるからです、だとそれも道徳の正当化に使えそうだけど、事実を規範にすり替えないといけない。
道徳の根拠として定言命法を持ち出すのは、少なくとも論理で語れる面については色々と新しい発見をしているすごいカント先生の言う事だから説得力があろうっていう権威主義的な要素もあるんだろうか。
実際に人間の尊厳という概念が社会に影響を与えているというのは事実にしても、それは別に論理的必然性との関係はないよね?って思う。
そんなに徹底して厳格に理詰めで考えてたら、そもそも規範なんてありませんというニヒリズムに辿り着かざるを得ない。
じゃあある程度は感覚的なものに依拠する規範を公理として置いて、そこから道徳の話を始めようって事なのかもしれない。それがキリスト教か人権思想かは知らんけど。
そういう話ならまあ分からんでもないけど、それだとかなり重大な前提条件あっての議論な訳だし、それをさも論理的に話をしてるんですけど?みたいなスタンスで行くのは欺瞞じゃねえか?
そこまで言って委員会という番組に この前京大を退職した宮沢さんが出演していたらしい。 TVerで見れるというので見てみたが、 感想としては、 ゲストもワクチン薬害や言論弾圧の問題についてかなり主張していたため 日本国内でもこのような議論が出来るようになったのかと少し安心した一方、 宮沢さんにはもっとはっきりとワクチンの薬害を主張してほしいという気持ちも持った。
前者については、 田嶋陽子という人は、ワクチンを打ったあとに歩けなくなり、 それをワクチンのせいではと疑っていると言っていたし、 2021年から製薬会社が血栓や心筋炎などのリスクを認めているのに それを一切報道せずにワクチンをゴリ押ししたメディアの責任を指摘しているゲストもいた。 ワクチンの薬害に関する議論を封殺されていたことを問題視する声もあった。 ちょっと前まではワクチンのワの字も言い出せない雰囲気だったのが、 ずいぶんと変わったものだ。 日本人というのは、周りに釣られやすい性質であり、故にワクチンをやたらめったら打ったのだが、 今後は逆に、ワクチンをやたらめったら批判する空気が一気に広がっていくような アトモスフィアがある。
後者については、 宮沢さんは少し厳密すぎる傾向があることが問題だ。 研究者として、その厳密性を欠いてはいけないという考えなのだろうが、 死亡超過は明らかにワクチンのせいなのだからそう言い切った方がいいし、 コロナかワクチンかわからないなどと言う必要はない。 もうそういう段階ではないのだ。 足を引っ張るな。 もう1つ、デルタまではワクチンは効いていたとか、 2回まではワクチンは効いていたとかそういう譲歩をする必要もない。 これは、フェアな議論をすべきという理系的な考え方があるからだろうが、 やはりもうそういう段階ではない。 結局、そういったことにより、橋下のような私文人間に餌を与えてしまうことになっていた。 もうここは、「ワクチンは完全に毒である。毒チンだ」とはっきり主張するところだ。 仮にそれが真の意味では嘘であったとしても、ゴリゴリに嘘をついていた厚労省やワクチン推進派よりは 遥かにマシであり、今考えるべきはこの天秤なのだ。 科学的な厳密性にこだわるのは局所解を求めすぎているように感じる。 今起こっているのは殺し合いであることを忘れるな。 どれだけ人が殺されたと思ってるんだ。
こうして、コロナが人工ウイルスであり、 コロナワクチンが人口削減のためのものであることは今となっては明らかになったわけだが、 以前からこのことについてはわかっていた。少なくとも2021年にはもう明らかだった。
これによると、コロナワクチンの毒性を見抜いてワクチンを打たなかった人たちは このIQテストに合格したことになり、それ以外の人たちは不合格したことになる。
そこでおれは高IQコミュニティMENSA+反社をかけ合わせて、 HANSAというコミュニティを作ることを考えている。 HANSAの入会条件は明快、ワクチン未接種なこと。 学歴もIQも関係ない。 HANSAはHANSA会員同士の生殖を促す。
Withコロナという言葉が一時期流行ったが、 コロナウイルスはこれからも私たちの周りに存在し続ける。 であるとすると、生まれてくる子供たちにとって必要な素質は、 コロナに対して脆弱でないことだ。 HANSAの会員たちは、ワクチン未接種にも関わらず コロナの中を生き抜き、おそらく感染を経験し良質な抗体を得た人間たちである。 つまり、遺伝子レベルでコロナに対して強い人間だといえる。 今後の世界を生きる人間を作る人間としてふさわしいのは まさにこのような人間であり、 コロナにビビってワクチンするような人間の遺伝子は淘汰されねばならないのだ。
服が臭くなるのは雑菌が繁殖するからだ、この認識に科学的な問題はないだろう
ここまでは同意いただけるだろう
では、雑菌が繁殖しやすい環境を諸兄姉はどのように考えているだろうか?
雑菌はどこに繁殖するか考えてみて欲しい
その餌、それは汚れであろう
否
生乾きが汚れを生じるわけではない
雑菌の餌となる汚れは着ることによって生じ、洗濯では落ちきれない汚れが雑菌の餌となる
つまり、汚れが落ちていない服は生乾きとは無関係に、乾燥機を使ってもなお臭くなる余地がある
乾燥機を使っても、酸素系漂白剤を使っても、服に汚れが残っていれば臭くなる
そして、乾燥機を使っても、酸素系漂白剤を使っても、熱湯で洗っても、服の汚れを完全に取り除くことはできない
服を殺菌したところで地球上で生きる限り雑菌を排除することは不可能で、繊維に残った汚れを足がかりとして雑菌は(気温が高くなると活動も高まり、餌の供給も増え)勢いよく繁殖する
何がいいたいかというと、服は着るほどに汚れが溜まり着てから臭くなるまでのスピードが速くなるし、どんな洗濯をしたところで服は着れば臭くなる
臭い人の多くは汚れが落ちきれない服を着ている、そして汚れが落ちきれない服は長く着ている服である
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}