はてなキーワード: ベースとは
視聴者が悪いのではなく、好きなタレントが出てるからドラマを見る。だから、しょうがなく改変してる。その辻褄を合わせるために私(テレビスタッフ)のやることは正しいし、これこそが創造だなんて思い込んでる烏滸がましさを直せって話です。原作軽視の改変を直せという話です。
その反省をベースの改変により視聴者も少しでも学習するのではないか。たぶんこれまでも少しづつ変わってはいると思われますが、日テレと小学館の報告書をみた限りでは癌はまだ局内にのさばっていると思いました。
入りきらなかったので別エントリで。
なお、出典は前のエントリーに貼ってあるのでそっちを見てくれ。
今までの話を読んできてもらった人には、完全に誤った議論であることはわかっていただけると思うのだけれど、どうしてもこう言う事を言う人がいる。
ただ、一点だけ「既に金がある奴を支援するべき」はその通りで、そのための施策がマッチングサービス・非婚化対策なのである。
統計で見ると、結婚しない・出来ない理由は、トップが「出会いがない」で次いで「経済的理由」である。
経済的理由と出会いが無いはほぼ同率なので、両方に手当てをする必要がある。
そして未婚男性で最も多いのは年収500万円以上なので、経済だけを協調して、マッチングサービスなど出会いを作る施策を非合理的だとする理由はない。
両方やれば良いし「合理性」で考えるならば、マッチングサービスなどの単純な婚活支援が最初に来るだろう。
参考: ttps://president.jp/articles/-/63789 婚活市場では"高望み"の部類だが…「年収500万円以上の未婚男性」が最も余っている皮肉な理由
引用:
涯未婚率対象年齢である45~54歳男女の未婚人口を年収別にみると、未婚男性でもっとも人口が多いのは500万円以上の年収層になります(2007~2017年の10年推移)。これは2007年も同様で、比率にしてしまうと小さくなるのですが、実数としては「婚活女性が高望みといわれてしまう年収500万円以上の未婚男性」がもっとも余っている
わずかにそう言った傾向はあるかも知れないが、基本的には誤り。根拠としては、結婚する理由に「子どもが欲しいから」と答える人が減っているという事を上げることが多いが、子どもが欲しいからと上げていた時代はもう50年以上前の時代の統計であり、現在の状況を分析するには古すぎる。(注3)
また、子どもが欲しいから結婚すると言う回答と、婚姻数が減り始める時期にはズレがあるのでマクロな動向を説明するには矛盾がある。
結婚せずに子どもを産む、いわゆる婚外子の割合が多い国はイタリアなどがあるが、実はイタリアは日本よりも出生率が落ちていて急速に少子化が進んでいる。
また、現実問題、日本では婚外子の出生率が非常に低い。これは社会文化的な問題なので早々覆すことはできない。
参考: ttps://president.jp/articles/-/74857 婚外子の推奨で出生率アップを狙うのは大間違い…婚外子、養子を認めても少子化は解決しない理由
ただし、て「結婚を強制するな」まで入って、最も合理的で優先順位の高い非婚化対策による少子化対策とトレードオフ関係に持っていく場合には問題になるが、
結婚しなくても子ども産みたい人は生めるようにどんどん制度を整えていったら良いのでは、という部分だけならば反対する理由はない。できるならば全部やれば良い。
これは最高に頭の悪い議論だと思っているんだけど、対立しない限り全部やればいいのは自明でしょう。
費用対効果は考える必要があるが、それに求められる効果は非常にわずかでも利益が大きい。
また、民間で出来ているから不要である、と言う話も頭が悪いと思っていて、その民間のサービスができて何年たっているかという事を意識して話をするべきだ。
例えば、マッチングサービスならば、サービスは2010年代前半から急激に増加して、もう10年以上の歴史があるが、そこから漏れる人々がいたのだ。だから非婚化は進み続けている。
ならばそれに対して行政が入る事で改善を図ることに合理性はしっかりとある。
気持ちはわかるのだが、同性カップルの結婚を可能にすることと、少子化対策として非婚化の対策、マッチングアプリなどの施策は本質的に対立しない。
にもかかわらず、そこをつなげる意味は無い
こういった考え方は少数派であることがわかっているため、マクロ政策を議論するときには、残念ながら優先順位は下がる。
もう社会的にコンセンサスがとれて久しいため、古い統計しか残っていないが
ttps://survey.gov-online.go.jp/hutai/h20/h20-syousika.html
これらを確認すると、少子化対策をやるな、不要だ、としている人は社会的に2%以下で、この数字は母数に対してほぼ誤差であり有意な数字ではない。
もちろんマイノリティであっても、配慮は必要である。さらに、戦前の産めよ増やせよの方向に行くようなことは避けなければならない事は大前提である。
しかし、少子化対策で、そこが戻るような兆候は見当たらないため、政策決定段階では処置は不要だと思われる。実施する時に個別の対応はする。
前項にも関わるのだけれど、こういった極端な意見は少数派である事が分かっているため、マクロ政策を議論するときには、残念ながら優先順位は下がる。
一方で、この議論は前項と違い、個人的に嫌だと思っていると言う主語を自分に置いた話とは程度が異なり、主語が社会になっている。
であるならば根拠が必要とされるわけだけど、このような話にそう言った論拠や統計などが記載されている所を見たことがない。
こういった議論こそ少子化対策を駄目にしていると思っていて、根拠ベースで話をしたいと思って、面倒だが色々な出典を貼ったエントリーを書いている。
近頃夫がとにかく短気で、仕事、街ですれ違う人、ご近所の騒音、そして私…に対して、しょっちゅう怒っている。
夫の怒る気持ちもわかるんだけど、前はそんなにいろんな事や人に神経質じゃなかったんだけどな。
電車でも、マナーの悪い乗客にイラついて、見ないふりするような場面でもいちいちつっかかりに行き、しょっちゅうトラブルになってる。
最近、夫がキレる形での喧嘩が週1ペースで起きていて、いつも私の言動が原因だと言い、謝罪を求められる。
いや、まずベースとしてあなたがイライラしてるからでは…と思う。
そして私も私で完璧な人間では無く、そういうストレスフルな夫の気持ちや立場を100%理解してものを考えたり言ったりできない時もある。
なので結局、一番身近にいる私が、その爆発するに至った夫のストレスを一手に引き受ける事になる。
発端はいつも「隣の赤ちゃんの泣き声で起きちゃったよ…」とかなのに、「まあまあ、どこの家もそういう事もあるから…」などとなだめていると「なんで俺が悪いみたいに言うの?」みたいな感じで始まり、弁解する私の言葉尻を理由にヒートアップが始まって、いつの間にか矛先が私に向かっている。
私はそのたびに「ごめんね、イライラしているときにこんな風に言われたあなたの気持ちを考えられてなかった。こういう言い方をする必要はなかったね。今後は言い方に気をつけるよ」とか言って謝るんだけど、いつも「次は気をつけるって毎回言ってるけど、それでもまた同じ事をやったらどうするつもりなの?」と言ってくる。
毎回よくわかんないまま霧散してる。
ある時「相当傷付いた」と主張されたときに「今度同じ事を言ったら関係が終わってしまう覚悟で意識を変えるよう努力するね」と言ったら、これにも激昂された。
関係性の行方を人質にとるんじゃないと。じゃあ何を望んでいるの? どう言えば納得する?
こういう気持ちがわかる人教えてほしい。
もはや夫が面倒くさく感じて仕方がない。
正直一人になりたい。夫と会話したくない。
つらいよ〜!!!!
——
以前夫に、モラハラやロジハラっぽいよと言ったら、猛烈に激昂したので言わない事にしてる。
私は父がモラハラ体質で最近両親が離婚したので、父みたいな人とは絶対結婚したくない…と思ってたんだけどな…
ぼんやり読んでたから11巻で気づいたけどアシガールってかなりかぐや姫ベースの話なんだね、満月の夜に帰れるところだけかと思ってた。
唯と尊なのは天上(月=現代)天下(地上=戦国)唯我独尊と、尊は竹の意味かな。羽木は竹取の翁、あと月と関連付けて萩?(萩月はかぐや姫が帰る旧暦8月)天野家の養子になってから羽木に嫁ぐのも天から翁へってこと?懐刀がタイムマシンの起動スイッチなのはたけとりの爺さんが竹を切る暗喩かな?
羽木(翁)から御月に変わるのは忠清と結婚して戦国で生きていくことを決めた唯(かぐや姫)にとってはそここそが永住する都である月になった、ってこと?
忠清の清には川を表すさんずいがあって唯はタダとも読むからお互いのことが入ってる。御月清永と唯で、月の都で永遠に忠清と唯が夫妻ニコイチで欠けることなく満月のように完璧になっている。
かぐや姫のモデルとされてる古事記の人物の大筒木垂根王の娘からアシガールのアシには葦(筒)もかけらてる?かぐや姫は竹通ってくるし。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
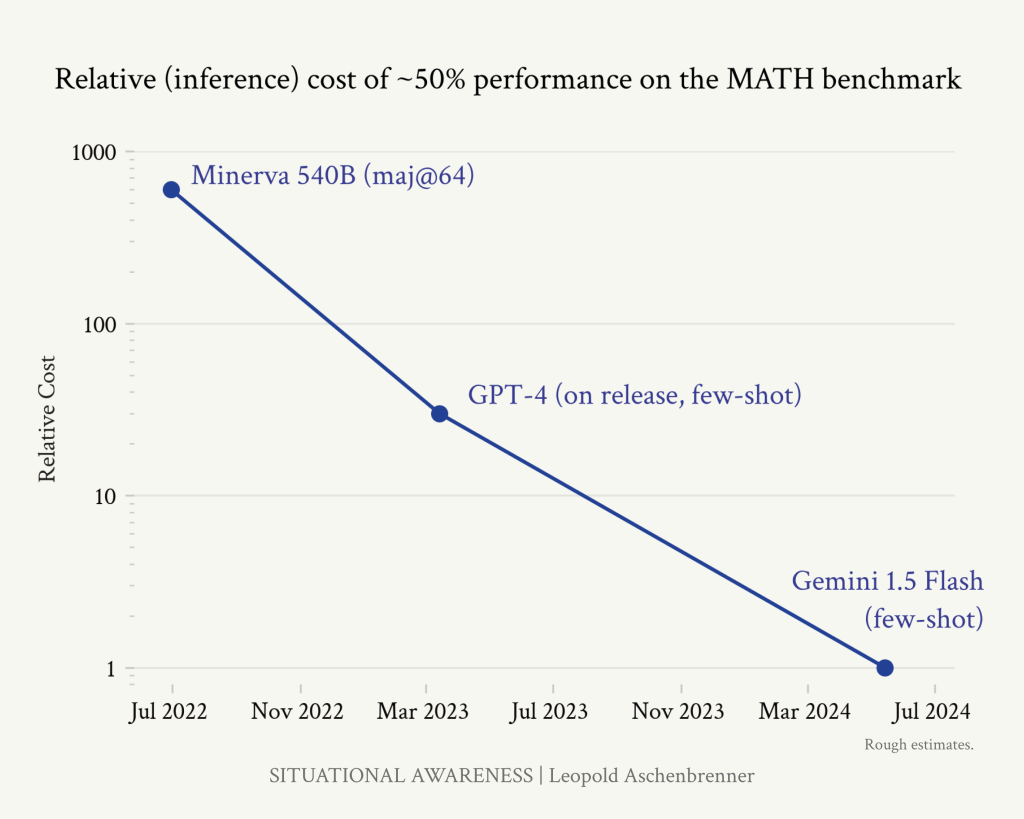
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
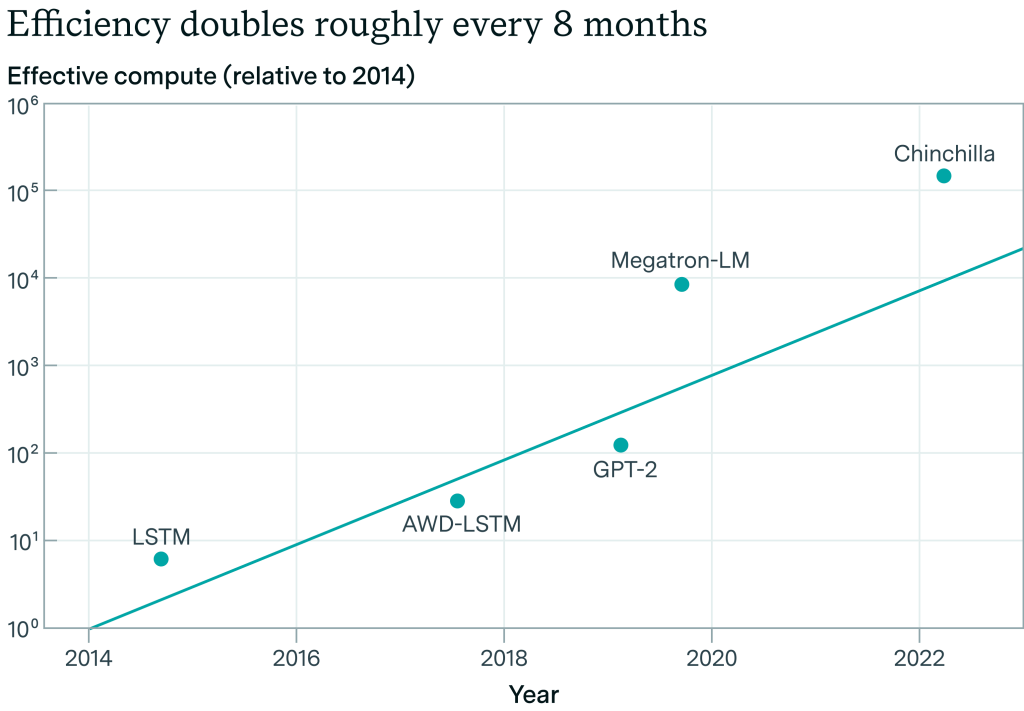
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
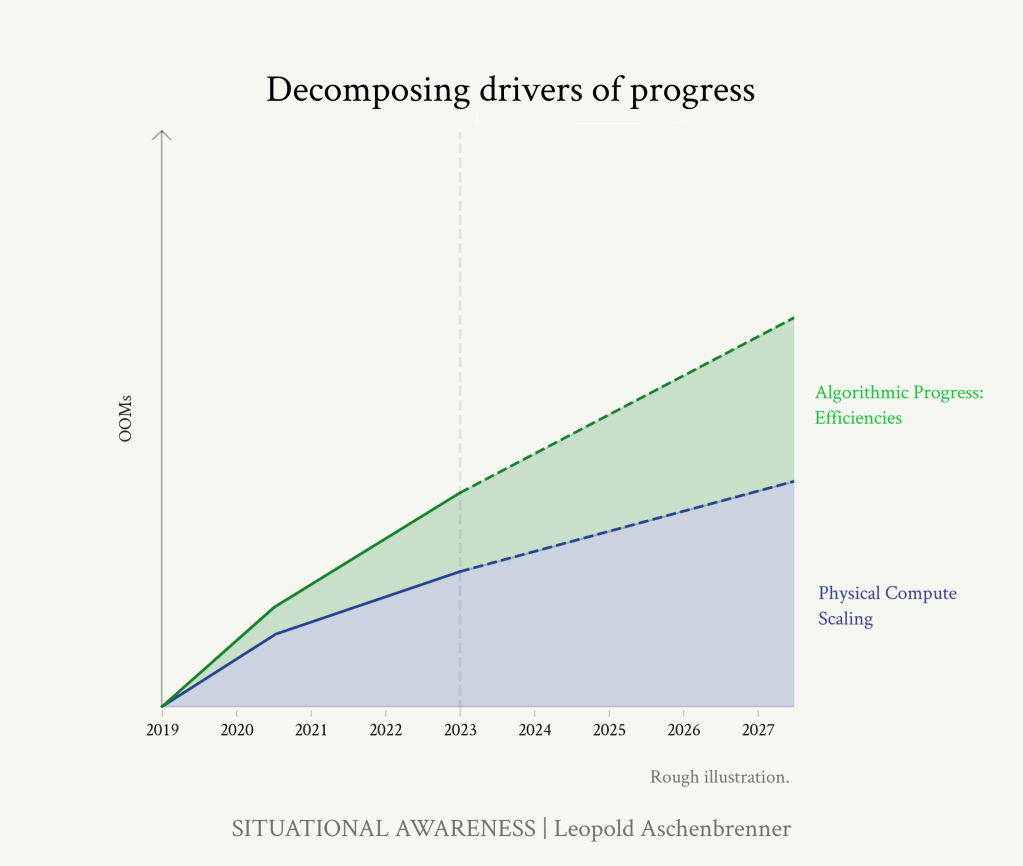
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
同世代の被害者女児(自称)が成長すると、その「嫌がらせをする男児」とはもはや全く無関係な2歳~5歳くらいの男児にも性的意識ベースの嫌悪感を発症して積極的に加害(つまり性加害)するようになるってことだろ?
何が違うんだ?
①世間話を普通にする関係になる段階、同性と同じようにフラットに接しろ
②仲良くなりたい意中の相手がいる場合、知人から友人やナシの枠に入れられる前に異性として意識していることをそれとなく伝える
対象がいるかいないか、会話をする関係かそうじゃないかの段階と前提が違う話をしているよね
②は増田のタイトルでもチンポの出し方とかいう直球タイトルになっているのが秀逸だと思う
イケメンが周囲の女に異性として扱うムーブを振り撒いてたらモテまくりだと思うがなんかキモい人が全員にチンポを出していたらキモいやつ一直線で何もプラスにならない
②を普通の人間として接しろと矛盾するとキレている人は全ての女にこれをするつもりなのだろうか?自分が実践すると考えた時に人間関係を築く場面というのが全く想像できていない
不特定多数の女性に対して①をして普通に存在できる人として受け入れられたら誰かが自分を好きになってくれるということがある、という話と、その不特定多数の中で恋愛したい対象がいるという状況で意識して貰うための手段②の話は全く別物(出会いを目的にしているマチアプとかだと①をベースにして②でいいのかもしれない)
ここまで話を詰めると②を釣り合わない美人や可愛い子にだけする男がいたら集団に属していてもキモがられるだろうな、それを男がアプローチしたらキモがられるとキレてるやつもいるだろうなと思いいたった、本人は恋だと思ってるが下心でしかないやつだったり、完全な足切りにあっていて拒否られているパターン
このケースは②で相手に引かれたら絶対に追わないというルールでカバーされているが、自分を客観視できない弱男には見た目でしか女を判断できない男というレッテルが世の中に出回って重要視されていること、そこに見た目や格での釣り合いという矛盾する残酷な価値観を加味してジャッジされているという事実が納得できないのかもしれない、そこは結局本人に気があるかどうかは気まぐれでもあるし、どこまでの現実の恋愛のパワーバランスに尽きるということで飲み込むしかない
もしどうしても無理目な相手を本気で好きになった場合は①をやって相手に惚れてもらうという戦略もあるが、それはぬいペニの擬態の最上級にはいるので信頼に裏切りが勝った場合は手酷い拒絶をくらうことになるし、相手を傷つける、諸刃の剣だ、机上の空論と揶揄されるのはこういう性質のせいかもしれない
自分を最弱に置いて無理目な女を好きになるというダメなタイプの男へのアドバイスとしては②よりも実は有用なのかもしれないし、逆にただ適切にアプローチすればいい場面でできなかったという人にとってはあまりにも無意味なのかも
ユーザーがある特定のアイテムをクリックしたという情報があったときに、そのアイテムの属性に関連するアイテムを推薦してほしいわけね
で、具体的にはコンテンツベース推薦を使ってて、アイテムを100次元のベクトルに圧縮してANNで検索してるから、実際に抽出してみるまでは「どういう入力にどういう出力をするか」ってのがわからない
俺自身はこの件に関して外野だが、「同じFeliCaベースのICカード」という括りでは無いことはオレでも分かる。
熊本市バスの5社がFeliCaを採用して自ら発行して自らの管轄内で使うだけのくまモンICと、他社で発行されて持ち込まれるカードの決済をやらなければならないSuica系カードは、システム構成が全く別だ。
他社との連携部分は当然他社側に合わせなければならない部分もあり、そういう部分で「大都市のシステム維持のために地方にしわ寄せが来る」という話になる。
じゃあ、国がシステム更新にも補助を出せば良いのかというと、今度は「地方にはオーバースペックなシステムを県外ユーザーのために税金で維持するのか」という話になるわけで、どっちにしても不公平感はある。
というか、総人口がこれから激減する日本ではSuicaユーザーも減っていくことが確定してるわけで、Suicaを捨てられない大都市圏はともかくオーバースペックで身の丈に合わない地方はSuicaに固執する必要性なんかそんなに無いよね。
だからJR東日本も「Suicaのスーパーアプリ化」なんて掲げて既存顧客からより多く搾り取る方針に切り替えつつあるわけで。
というか、サービス開始から20年以上経ってるのにいまだにJR東日本管轄内ですら在来線特急券をSuicaに紐付けてチケットレスで乗ることすら出来ないのが不思議でしょうがない。
あんまり早く仕事を切り捨てると生きる理由を他の部分に依存することになる。
普通の人間に手が届く生きる理由は「趣味」「仕事」「家族」「交流」「「贅沢」「薬物」「信仰」「名声」ぐらいしかない。
若い頃の「趣味」は30代ぐらいになると突然の飽きがくるリスクがある。
「家族」については子供や伴侶のどちらかと上手くいかなくなるととたんに全部回らなくなる。
「交流」も忙しくなってくると学生時代の知り合いが減り、「趣味」をベースにした交流も飽きと共に薄れやすい。
多くの人はこれらのどれかで何とか出来ると思って「仕事」を「死なない程度に金が貰えれば」と割り切る人生に舵を切ろうとする。
既に述べたように「趣味」「家族」「交流」といったものは30代ぐらいから急激に予定が狂いだすリスクに巻き込まれる。
これら全てが駄目になったとき、生きる理由のうちで無難なのは「仕事」と「贅沢」ぐらいしかない。
「仕事」に生きがいを見いだせなくても、金だけでも稼げれば「贅沢」に生きがいを見いだせる。
なんとか上手くやれる人生はここまで、「薬物」「信仰」「名声」を生きる理由として依存する人生は地獄だ。
酒やタバコを始めとした「薬物」は乗り込めばアッサリと人生が、人生その最寄り先に脳みそを始めとしてて身体が壊れてしまう。
「信仰」は一見すると救いに見えるが、あんなのは精神的な「薬物」に等しいので人生を完全に捨て去ったあとでもなければ関わらないほうがいい。
物理と精神、2つの薬物を回避したはずの人間が知らずに手を出してしまうものが「名声」というドラッグだ。
たとえば反ワクチンの「真実」を語ることで優越感に浸ったり、キャンベルスープを名画にぶちまけることで称賛を浴びたり、その瞬間、人間の脳は異常な量の快楽物質を放出する。
バグった他者への貢献意識により俺は世の中の役に立っているという勘違いが起こり、脳がドバドバと音を立てて壊れていく。
これを比較的安全に楽しんでいるものが「ボランティア」なのだが、「ボランティア」も何十年もやっているとそのうち壊れていってしまうのはあえて語る必要もあるまい。
人生を安全に生き延びるための最適解としては、「仕事」に生きがいを見いだせる可能性を切りすてるのは自分の人生が確定してからでいい。
40代だ。
反ワクチンの集会が話題になってるけど、笑える話でもない気がする。
彼らが信じるか信じないかの話は、ただの政治思想や陰謀論と切り捨てることができない。反ワクチン的な発想は、左から右まで、リベラルから保守まで、どこにでも見られるから。それって、結局のところ、薄らとした政治不信、社会不信がベースになってるんじゃないか。
情報が十分に公開されない、もしくは理解できる形で公開されないってのが問題なのかもしれない。肝心なことは隠される。それが不信を招く。政府やメディアが何を言っても、「また何か隠してるんじゃないか」って疑心暗鬼になるのは当然だ。結局、誰が何を言っても信じられなくなる。
反ワクチン派の人々も、根本的には情報の透明性を求めているんじゃないか。もちろん、その結果として生じるデマや誤解は害悪だけど。信頼を取り戻すには、政府や専門家が情報をしっかり公開し、説明を尽くすことが不可欠だと思うよ。でも、現実にはそれが果たされてないから、こういう騒ぎも残っていく。
「説明が十分に果たされているか」ってのは、本当に大事なポイントだよ。それを怠ると、ただの不信感がどんどん膨らんで、社会全体が揺らぐ。もう少し透明性を持って対応しないと、この手の問題はどんどん増えるかもしれない。
3月29日時点で条件が示されていればドラマ化はなかった――これは日テレの調査によって明らかになったドラマ制作サイドの考えだ。ドラマ制作した日テレは3月29日のウェブ会議において原作利用許諾を得られ制作がスタートしたと考えている。原作サイドの小学館は6月10日のメールで初めて契約が締結したと認識している。すれ違いだ。
すれ違いが多数重なったことで悲惨な結果になった本件だが、6月10日までに実際に何があったかに焦点を当てて考察する。どちらの調査報告書でも解釈の都合に合わせて省略が施されていて、突き合わせてみないと実態がわかりにくい。原作の先生がブログで示した「何度も確認した条件」は、果たしてどのようなものだったのか。どう確認されたのか。日テレは何を約束し、あるいは約束したと思い込んだのか。
なおこの考察では、日テレの調査報告書も小学館の調査報告書にもウソは書かれてないと仮定する。この後に及んですぐバレるウソをつくのはリスクでしかないし、外部の弁護士が実名で名を連ねているからだ。
引用元を(日p12)(小p34)のようにページ数を付記して示す。
(日) https://www.ntv.co.jp/info/pressrelease/pdf/20240531-2.pdf
(小) https://doc.shogakukan.co.jp/20240603a.pdf
なお文脈を補うために適宜カッコ書きで(このように)追記する。
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ(小学館側は)芦原氏が自分の作品を大切にする方であり、作品の世界観を守るために細かな指示をする所謂「難しい作家」であるから、原作に忠実で原作を大事にする脚本家でないと難しいと伝えた。(小p13)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ他社に当面ドラマ化の意向がないことを確認し、会議で報告した。(小p13)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ他局からのドラマ化の話を断ったことが説明され(日p10)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ(日テレからの原作者とどういう形で進めていくのがよいか、の質問に対して)「できあがったプロット・脚本を見ながら進めていきましょう」
(日テレ側は)本件原作者の意見を無視するような改変はしない、リスペクトをもって取り組むという趣旨の話をした(日p10)
日テレはこのときにドラマ企画についての許諾がなされたと認識したらしい。
日テレの報告書には、この時点までの二度の打ち合わせではブログにあったような条件は文書でも口頭でも提示されてなかったと注記している。小学館担当者は「漫画を原作としてドラマ化する以上、『原作漫画とドラマは全く別物なので、自由に好き勝手にやってください』旨言われない限り、原作漫画に忠実にドラマ化することは当然という認識である」と回答した。
4月には日テレから脚本家候補者の提案があり、その中に揉めた脚本家も含まれていた。
脚本家が書いてきたプロットに原作の先生が修正を加えたりした。4月中に日テレから脚本家が決定したと通知された。
4月24日
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ「マストではないので、ご提案があれば随時お聞きしたい」(と添えて原作者の意見を伝えた)(小p16)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ未完部分はドラマオリジナルのエンドでよい(日p9)
日テレの調査によると、この発言は「未完部分は原作に影響を与えないよう、原作者が提案するものをベースにしたドラマオリジナルエンドで良いという趣旨で言った」とのこと。
5月19日
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ原作者としてエピソードの順番の入れ替えをしないよう脚本家に求めた。...送信メールに「 『セクシー田中さん』はキャラクター漫画だと思っています。それ故キャラクターを好きになってもらうために、各エピソードが綿密に構成されているので、やむを得ない場合以外はできるだけ、原作の流れを崩さないで頂けたら…と思っています」と記載し、編集者の立場からの希望を述べた。(小p17)
電話でドラマ化にあたってはやむを得ない部分はあるということを説明し了承を得た。(日p16)
6月6日
日本テレビ社内で 10 月期クールの日曜ドラマ化で決定になりそうだとして契約締結の段取りについて相談したいとの連絡(小p19)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ日本テレビ社内で正式決定されたら...連絡するように求めた(小p19)
6月8日
「日テレ内で『10 月ドラマ枠』で正式決定いたしました。」とメール(日p17)
(小学館社員に対し)契約の話を進めるように要請した。(小p19)
日テレの調査報告書によると、事前にドラマ化自体と放送枠は決まっていたが、初回放送日がこのタイミングで決まった、としている。
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ電話で改めて、ドラマのオリジナル部分は芦原氏が詳細プロットを書き、これを受けて脚本家が起こした脚本を了承しない場合は脚本を自ら書く方法を提案し、脚本家に失礼にならないよう了承を取ることを求めた。(小p21)
芦原氏に書いてもらうことはありがたいと賛同し、脚本家にもうまく話しておくと回答した(小p21)
「ドラマオリジナル部分は原作にない部分を描くため、本件原作者にとって非常にセンシティヴであること、本件原作者の過去のドラマ化の経験から本件原作者から提案したほうが良いであろうこと、提案の形態は、プロット若しくはロングプロット(なるべくセリフを多めに書く)とし、本件原作者が作成して本件脚本家が読み込んだ上で、本件原作者の意図を最大限汲んだ形で巧妙に脚本化できればベストであること、ただし、脚本化の過程で本件原作者の了承がどうしても得られない場合は、本件原作者自ら脚本を執筆する可能性があること、これを実施すると、専業の脚本家の方に大変失礼であるので、予め了承を取っておいてほしいことを述べ」日テレ社員の了承を得た、とのこと(日p18)、しかし日テレ社員は、
「もし脚本が芦原先生の意図を十分汲まず、芦原先生の承諾を得られないときは、芦原先生に脚本も書いてもらうこともある」と言われた記憶はないと否定しているが、詳細プロットを書く話を聞き、感謝したことは認めている。(小p21)
原作者自ら脚本を執筆する可能性があること、これを実施すると、専業の脚本家の方に大変失礼であるので、予め了承を取っておいてほしいことは、この時点では言われた記憶はない(日p18)
小学館のレポートでは日テレ社員は「明確な条件としてはお伝えいただいておりません」とも回答し、話があったことを否定してはいない、と強調している。
「契約書の件承知しました。(日テレ社員)より(小学館社員)から契約にあたっての 9、10 話のロングプロットの話など聞きまして、こちらとしては合意で契約すすめたいというのは(日テレ社員)に戻させていただきました」(小p22)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ「脚本家の方との向き合いもあると思いますので、なかなか心苦しいのですが」との懸念を示しつつ「その先のドラマオリジナル展開に関しては、芦原先生の方から、脚本もしくは詳細プロットの体裁でご提案させて頂けませんでしょうか」と、提案(小p22)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ「許諾の条件という程ではありませんが、はっきりとした要望としてご検討頂けますと幸いです」(日p19)
小学館のレポートは「交渉への配慮として許諾条件という程ではないとしながらも」と注記している。
「結果進めさせて頂くとのことで承知しました。9話あたりからのドラマオリジナル展開に関して芦原先生の方から脚本もしくは詳細プロットの体裁でご提案して頂く点も承知しました。芦原先生の原作の世界観もあると思いますので具体的に頂けるほうが良いと思います。(小p22)
こちらからもそのご提案を受けて、案だしもさせて頂ければと思いますが、その方向で進めさせてください。」(日p19)
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ具体的な進め方は...(別の社員)と相談するように求め、原作利用契約は小学館から連絡するとのメールを送った(小p22)
進め方の相談の電話を...(その小学館社員)にするとメールした。
日テレ側の聞き取りによると、日テレ社員は「脚本は本件脚本家が書くものだと思っていたため、…メールにある『脚本』という点が引っ掛かった。そこで、」
ᅟᅟᅟᅟᅟᅟᅟᅟᅟ9、10 話に関しては、原作者にプロットを書いて頂く方向で進められたらと思う旨メールにて回答した。(日p19)
小学館の調査報告書によると小学館担当者は「この提案は、プロットを忠実に脚本に起こしてもらえるならば、という前提での提案であり、この時点で芦原氏の脚本執筆を条件から外した事実はない。」とのこと(小p22)。日テレの調査にも同様の回答をしている。
「テレビドラマとして本件原作者のプロットが通用するかどうかは実際にみてからでないとわからない」旨回答し、本件脚本家の執筆したものでラリーをさせてほしいという旨伝えた(日p18)
さらに、「この時点で本件原作者の了承がどうしても得られない場合は、本件原作者自ら脚本を執筆する可能性があることについて本件脚本家に了承を取っておいてほしいことは言われたことはない」(日p18)としている。
ᅟᅟᅟᅟᅟᅟᅟᅟᅟドラマオリジナル部分については本件原作者からロングプロットの提案をしたい旨連絡があった(日p18)
それで良い旨... 回答し、...(小学館担当者に)伝えた(日p18)
高々数MBをケチってログの残らない媒体でコミュニケーションを取るのはリスクでしかない。6月9日に何が起こったかについて双方の意見は真っ向から食い違ってる。お互いがああも自分の意見を主張できるのは、相手方に記録が残ってないという確信があるからだと思う。彼らの読みは正しくて、だから結局どちらが正しいのかはわからない。真実は闇の中。ログの残らない電話だから。
・ドラマ化するなら「必ず漫画に忠実に」。漫画に忠実でない場合はしっかりと加筆修正をさせていただく。
・漫画が完結していない以上、ドラマなりの結末を設定しなければならないドラマオリジナルの終盤も、まだまだ未完の漫画のこれからに影響を及ぼさない様「原作者があらすじからセリフまで」用意する。
原作者が用意したものは原作変更しないでいただきたいので、ドラマオリジナル部分については、原作者が用意したものを、そのまま脚本化していただける方を想定していただく必要や、場合によっては、原作者が脚本を執筆する可能性もある。
これらを条件とさせていただき、小学館から日本テレビさんに伝えていただきました。
...「この条件で本当に良いか」ということを小学館を通じて日本テレビさんに何度も確認させていただいた後で、スタートしたのが今回のドラマ化です。
(原作者のブログ記事より。アドレスはここだった http://ashihara-hina.jugem.jp/?eid=244 )
わたしの社会経験は豊富とは言えないけれど、小学館お墨付きのブログの「本当にこの条件で良いかと何度も確認させた」というのは誇張した表現としか思えない。少なくとも6月10日まで、原作者サイドはいろんな状況で何度も原作に従うように打診してきた。だけど「改めて」原作が脚本を書く了承を求めた6月8日以前にそれを求めた証拠を、わたしは小学館のレポートからさえも読み取ることはできなかった。そして「許諾の条件というほどではありませんが」… これが交渉の配慮から出てきた言い方なのは分かるが、「許諾の条件ではない」とワザワザ明記した要望が「許諾の条件だ」なんて認められない。これこれが条件だ、さもなければドラマ化は無しで、と言葉は強いかもしれないがビジネスの場では明確に迫るべきだと思う。
日テレ社員は6月10日のメールで「脚本もしくは詳細プロットの体裁でご提案して頂く点も承知しました」と一旦は納得してる。これは双方のレポートで食い違いがない。だけどその後に、「待てよ」と思い直して「(脚本ではなく)プロットで」と確認して小学館社員も方針に納得したらしい。しかし小学館社員は方向転換しない等とは言ってない。前提が覆れば現在の方針を改めるつもりでいた。このような『現在の方針の確認』は『契約の条件』というには曖昧に過ぎると思う。日テレ視点では脚本の話はそのメールでイキナリ飛び出てきた文言だったのかもしれない。だけど誤って受け入れた原作脚本の可能性を否定したいなら、「原作者が脚本を書く可能性は無しでお願いします」とハッキリ言わなければならなかったと思う。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}