はてなキーワード: トレンドとは
増田の周囲で最近「働き方改革とかクソだ!」「リモートとか言わず出社しろ!」みたいな反動があり、職場の雰囲気が良くない。
課長も一時期は、人員を監視してムチ打つ労働監視員でなくて、プロジェクト進行を管理するプロマネ的な動きに変わって行ってるはずなのに、
また奴隷監視員みたいな管理をする人が出てくるようになってきた。大きなトレンドじゃなくて局所的な揺り戻しかとおもうけれど、
職場の雰囲気が恐怖政治的になってきている。指示を出すとき、大義や目的とか締め切り、制約条件みたいな基本的なブリーフィングなく、
「うるせぇごちゃごちゃいうな、おまえ上司のいうことが聞けねぇのか!」みたいな管理をする人がいてびっくりしている。
団塊の人達が無茶苦茶だった、という反省の素にすこしずつ改革を積み上げてきたはずだけれども、その辺の歴史的な認識が
部署によっては最近課長になっている氷河期世代の人たちに伝わっておらず断絶があるように感じる。
団塊ジュニアの人たちで課長にならないで職場の鬼軍曹みたいな、昭和の価値観でガチガチにかたまった人達がいて、
絵を描こうと思ってTwitterで神絵やハウツーを踏み踏みして観察してたらTLが特定のジャンルに偏ってきた
今の二次創作のトレンドはブルアカ、崩壊スターレイル、原神、学マスなのか
これらばかりがTLに流れてくる
それともTLが偏ってるだけか
某マイナージャンルの絵が描きたいだけなので上記のジャンルには全然興味がない
これから書くことはいわゆるネットスラングで言う「アルミホイルを巻く話」、つまり妄想だということです。
なので事実の摘示もしていませんので勘違いしないようにしてください。
子猫の小話
https://youtu.be/kaLkD3KBDTg?si=chkj7KDLeOO6Xo-M&t=217
石丸伸二について調べてみました
暇空茜
https://www.youtube.com/watch?v=GDFY6hB-BFM
石丸伸二がバズり始めたのは2023年8月上旬からということは複数の方が確認している。
2023/07/01 2023/08/31
堀口がおおむね圧倒的に上にあるが、8月に入り小林の怒りがトレンドに入り、そして低下するのと入れ替わるように石丸伸二が上がってくる。
この状況を整理すると、石丸伸二と堀口英利は互いに示し合わせて行動しているわけではないが、結果として石丸伸二の仕掛けを隠ぺいするために堀口英利がサポートする形になっていたようにみえる。
具体的には、堀口英利が小林の怒りに対してできるだけド派手な攻撃を行い、石丸伸二をプッシュしていることを暇空茜に気取らせないようにしていた。
もちろん、堀口英利がその事実を知っていたとは思えないが、意図せずとも互いの行動が結果としてWin-Winの関係 になっていたようだ。
伊久間の訴状を見れば、700万円の請求も神原、伊久間あたりが考えていた内容を堀口が実行したともいえる。
そうだとすると、石丸伸二を隠すように堀口に吹き込むタイミングが調整されていたのかもしれない。
堀口英利がネット上で話題を混乱させることで、石丸伸二のプッシュが目立たなくなり、計画がスムーズに進めた可能性がある、
自分だけだとバイアスがかかるかもしれないので、ChatGPTにも見せてみる。
ChatGPTが読み取れることを以下にまとめます。
7月初旬から8月中旬にかけて、人気度が一貫して高く推移しています。(編注:トレンドだからこういう表現になる)
特に7月中旬と8月初旬に大きなピークが見られます。これは何か特定のイベントやニュースが影響している可能性があります。
あるトピックやキーワードが7月から8月にかけて一貫して注目を集めています。特定のイベントや連続したニュースが関連している可能性が高いです。
7月初旬はほとんど変動がありませんが、8月に入ってから何度か急上昇しています。
これらの急上昇は、特定の短期間に集中していることから、一時的な注目を集めた出来事があったことを示唆しています。
他の二つのラインに比べて、頻度が低く、また人気度もあまり高くありません。
いくつかの時点で急激な増加が見られますが、それ以外はほとんどゼロに近い状態です。
@shinji_ishimaru
こちらの #キッチンカー の募集は明後日8/10(木)が〆切です!
すでにかなり多種多様なお申し込みがあり、県内でも稀なイベントとなりそうな感じがしています😃
盛り沢山な #フェス を共に楽しみましょう。(珍しい飲食が提供できる方は特に)皆さんの参加をお待ちしています!!
ttps://x.com/shinji_ishimaru/status/1688876338785267712
ここでサクラが出現している。
@Silvertigerone
安芸高田市長「恥を知れ」発言 #安芸高田市 #恥を知れ #石丸伸二 ttps://youtube.com/shorts/fnFbdyqsxDA?feature=share
ttps://x.com/Silvertigerone/status/1688946721718710272
@shinji_ishimaru
ここ数日、フォロワー数が急増しているので不思議に思っていました…再生数が6日で230万回はなかなかの伸びですね。
ttps://youtu.be/dTu2Fk_LpdI
#中国新聞 に限らず地方紙には似た傾向があるのではないかと懸念しています。発言に責任を持たない #メディア は有害です。
@ChugokuShimbun
youtube.com
【逆ギレ】マスゴミが中途半端に石丸市長を挑発し、逆にコテンパンにされ涙目で逆ギレ議論すり替えを行ってしまう
余計な一言と、下手な追求は効かない人には絶対に効かないですね…記者も感情的にならず、もうちょっと理論的に話をしてほしいです。引用元安芸高田市定例記者会見(2023年7月) 前編ttps://www.youtube.com/watch?v=QfNRDlQbzy4チャンネル登録はこちらをクリック!ttp://ww...
208.9万 件の表示
ttps://x.com/shinji_ishimaru/status/1691432918701494272
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
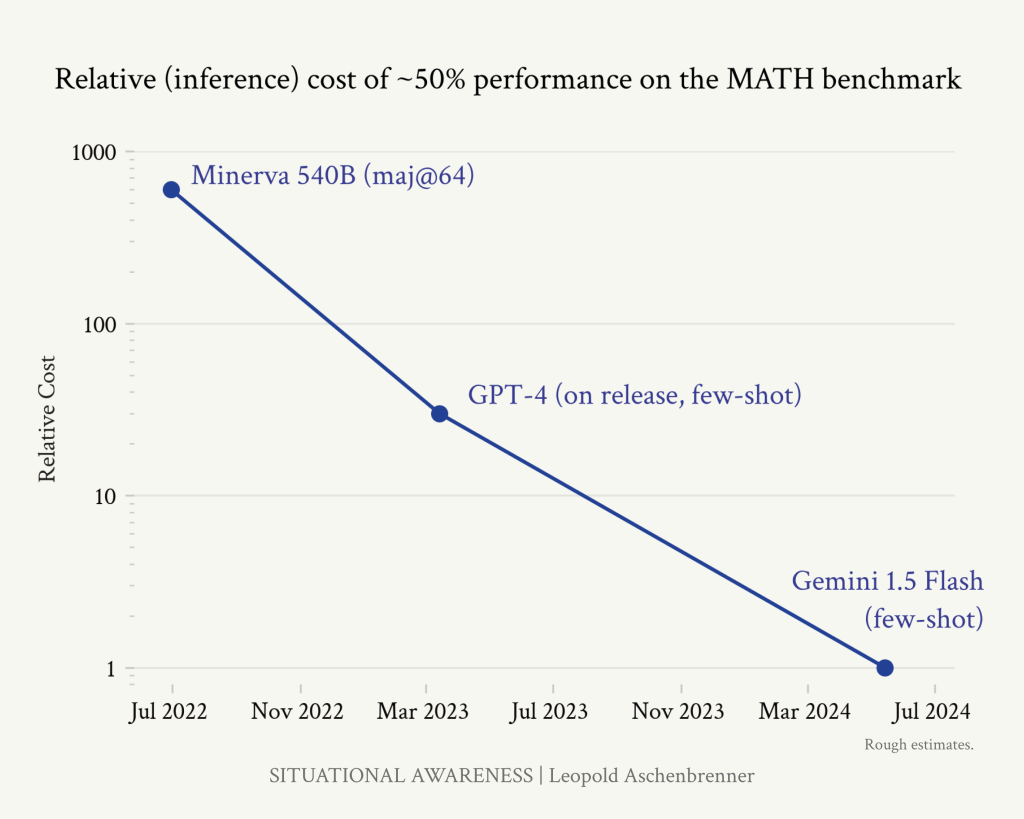
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
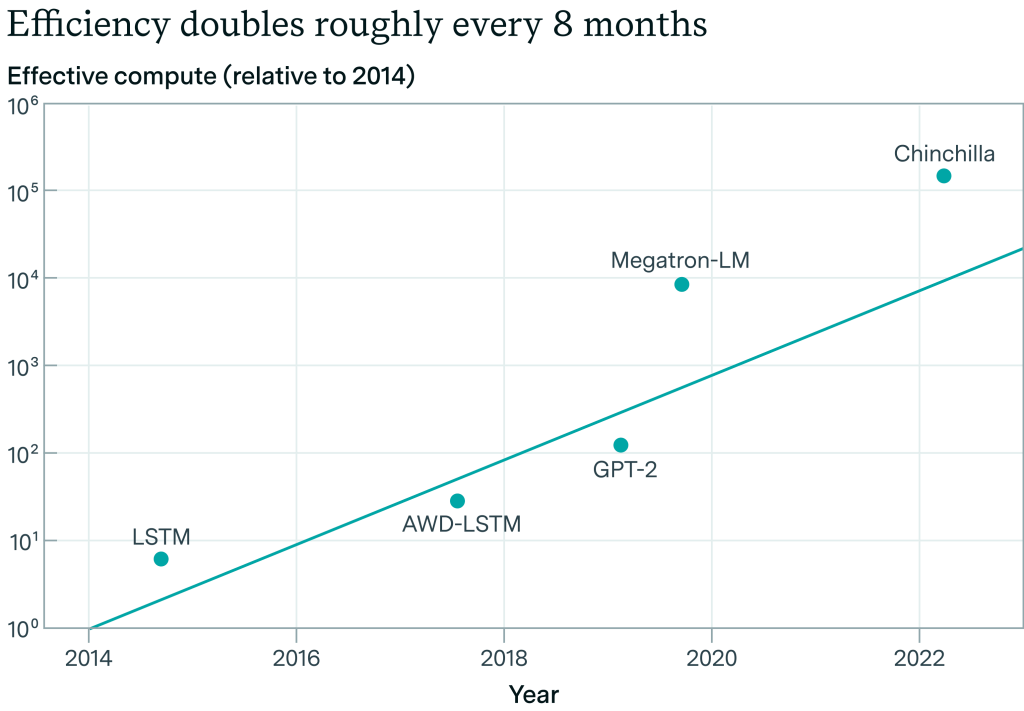
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
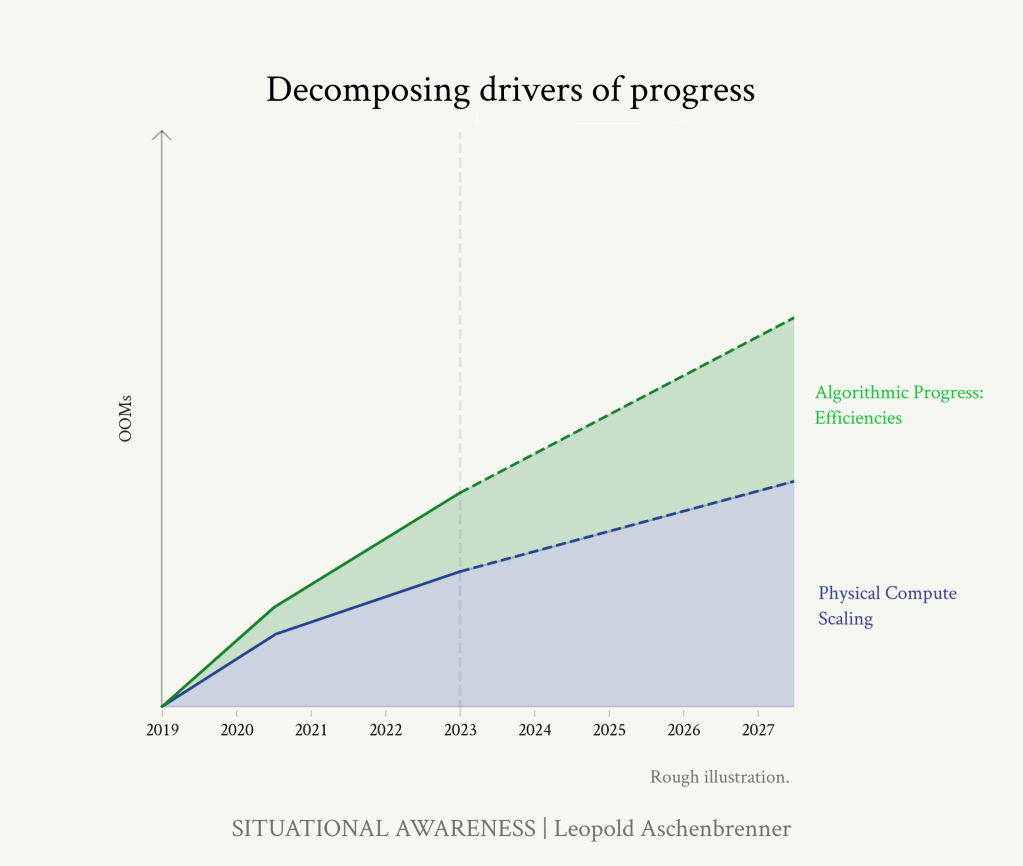
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
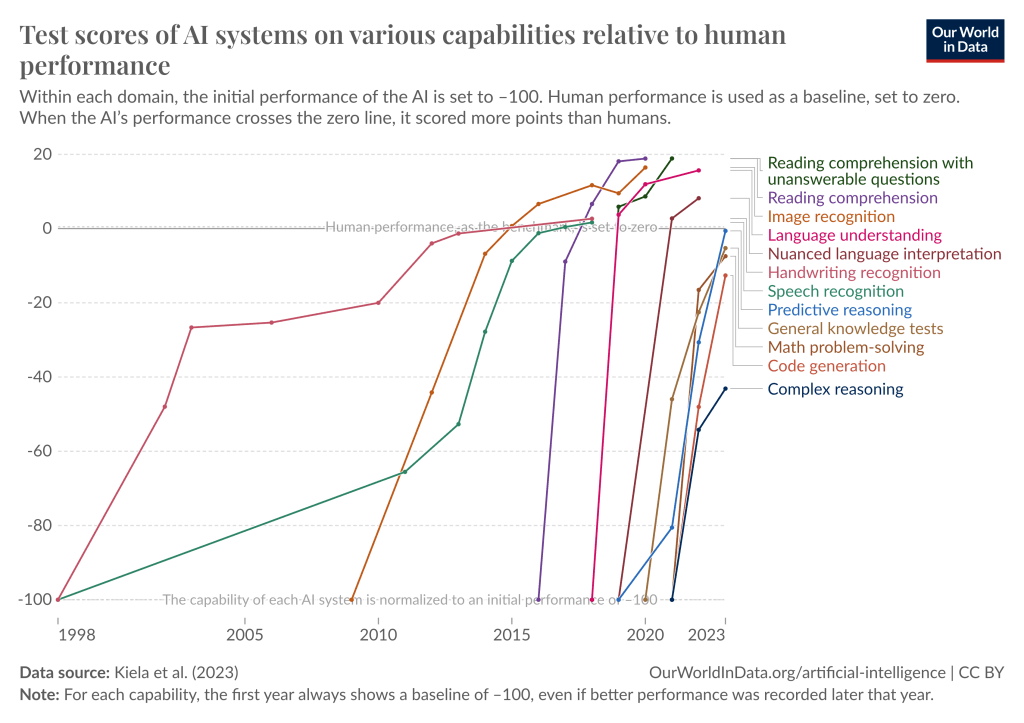
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
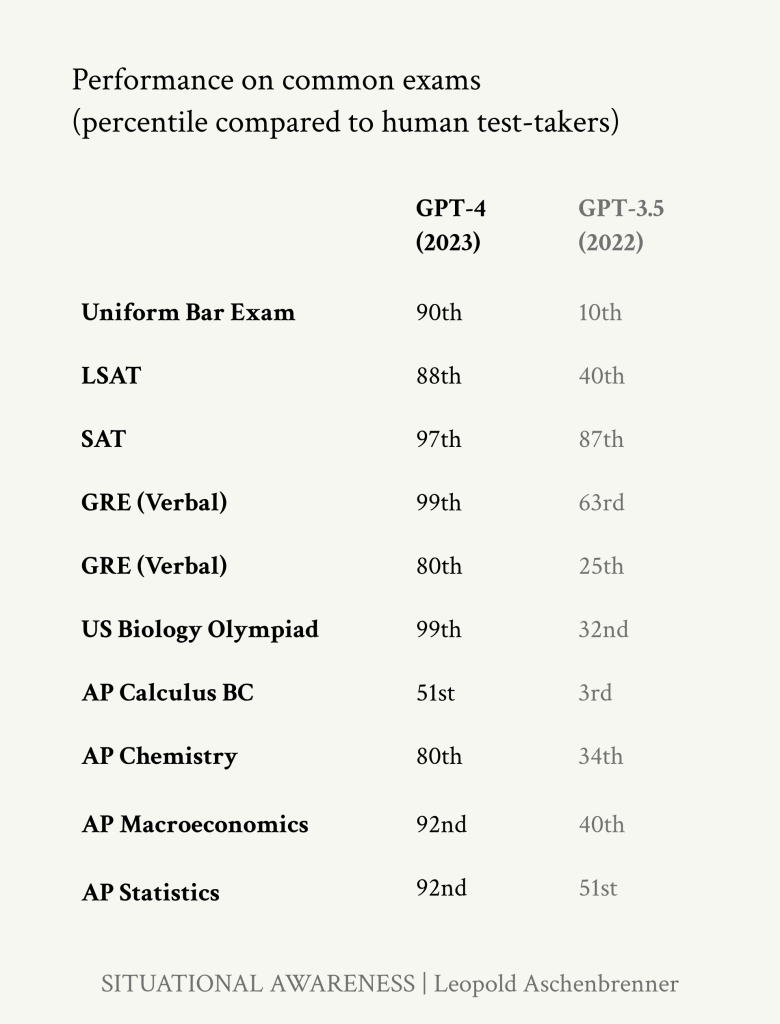
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
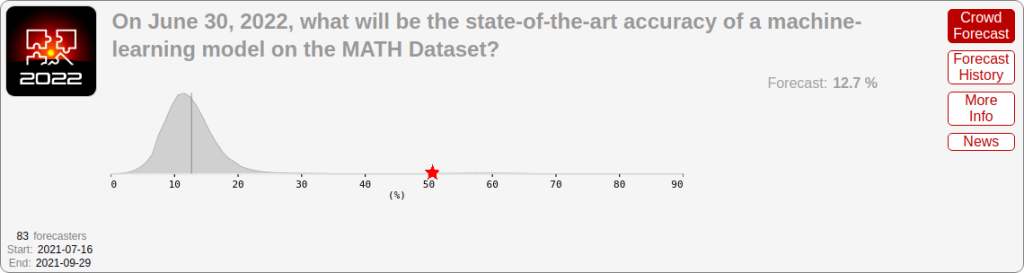
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
スターレイルは、最近のソシャゲのトレンドを体現したような作品だと思う。
ストーリーは意味不明で何言ってるかわからんけど、派手なムービーとBGM、声優さんの演技力でかなりそれっぽく仕上がっていて神ゲーのように見える。
ゲーム内容は単純でポケモンの相性表みたいなのを覚える必要もなく、持ち物検査が極まったような感じで敷居は低め。
原神と違ってアクション性がないのでスマホで遊びやすいが、レスポンスが良すぎて自分で操作しているような感覚が十分にある。
ユーザーはゲームを買うというより、キャラクターの3Dモデルにボイスが付いたもの、DL版amiiboみたいなやつを買う。
パワーインフレ前提なら、ドラゴンボールやイナズマイレブンぐらい話がわかりやすくてもいいし、
中華ゲーという意味ではアークナイツぐらいの戦略性はあってもいいし、非戦闘時はAPEXぐらい軽快に動けてもいい。
しかし、それよりもまずはキャラの出来栄えが重要だというのがマーケットの答えだ。
半袖パーカーとか裾にレースのついたチュニックとか。逆にそれどこで買ってるの?今の時代によく売ってるね。それとも昔買った服を着ているの?
半袖パフスリーブのデニムジャケットにラグランTシャツ合わせているのも即売会くらいでしか見たことない。そもそもパフスリーブのデニムジャケットを日常で15年くらいは見ていない。本当にどこで買ってるの?
半袖パーカーしかりデニムジャケットしかり重ね着が好きなのか?
世に流通するまでにトレンドを調べたり色々な方のチェックが入ったりしているはずなので、ダサい服というのはこの世に存在しないと思う。
ただ流行は変わっていくし、好みの範疇でも年相応の服装というものは存在するので、たまに物凄いファッションのオタクを見て気になってしまう。
服装に興味がないならシンプルな装いになると思うので、当人たちにはそれなりのこだわりや好みがあって、その上でその服を着ているのだと思うと余計に気になる。
常に怒ってるよね どうした?
あと常に何かを見下してるよね
あとさぁ、一部を切り抜かれた発言とかネタ記事の一文とかにだってマジギレしてるよね
とにかく怒りをぶつけられる材料があれば何でもいいんだよね
引くわ
っていうか、たくさんの文字を読む集中力もないし、読んだところで文章が理解できないもんね
みんながそう言ってるからソースなんか読まなくても正しいんだよね
まぁそんなことまで考えてないか
あと君ってさ、頭が悪いから本当に本当に色んなことが理解できないけど、ムカつくから何とか自分の都合のいいように解釈してキレるよね
言ってもないことに対して勝手にキレるし
あとときどき自分の不満を吐き出すために仮想の敵作ったりしてるよね
平気でバレる嘘のエピソード作ったりしてんの、あれ何?
それ見たやつがまたマジギレしててさぁ
何してんの?
よく生きてきたよね 周りも大変だったと思うよ
何かを見てもどっちが正義でどっちが悪かでしか判断できないもんね
悪を叩けば自分が正義だと思い込んでるし、正義側の人間は価値があるから自分にも価値があると思い込んでるし
残念だけど君にそんな価値はないよ
誰も信じてる人なんかいないよ?
精神的に幼稚なままだからそうすれば周りがすごいと認めてくれると思ってるんだよね
やめな?
あとMBTI診断とか診断メーカーもやたら好きだよねぇ
あぁ違う違うMBTI診断が悪いって言ってるんじゃないって
MBTIとかだけで人をジャッジするなつってんの
困るなぁ 頭悪いと話も通じなくて
あと世の中で起こってることに対して意見を述べたりするけど、全然的外れだし薄っぺらいよ
社会に参加したような気分になってんの?
頭がよくなった気がする?
君さぁ、空っぽなんだよ
ほんとトレンドワードとか好きだよねぇ いっつもそれの話題ばっか
間違えたくないから他人の意見がどうだか確認してからさ、さも自分が考えたかのように全く同じ意見言ったりするよね
あれは何?ちょっとでもはみだすのが怖い?
じゃあわざわざ言わなくていいって
あと君さあ、SNSでバズることが何よりも価値のあるものだと思い込んでない?ヤバいって
ほんとさぁ すぐキレるよね
こんなこと普通言われなくても分かると思うけど、ネットで他人に平気で喧嘩を売るのもやめた方がいいよ
対面なら話しかけるのすらビビっちゃうのにほんとネットだと強気だよね
あぁあと君、捕まった人とか週刊誌に撮られた人好きだよねぇ
その頭でも「悪い人」ってことは分かるもんね
悪い人を攻撃するのは正義、正義には価値がある、だから自分は価値のある存在だ、ってこと?
ほんと個性もないよねぇ
何の才能もないから個性を出そうとして、はみ出したことをやろうとしても全部二番煎じになってる感じ
ようやく他の人がやってないことを見つけられたと思ったらとんでもないモラル違反
あのさぁ、他の人がやっていないのは当然に迷惑だからあえてやっていないだけだからね
誰でもわかるんだよこんなの
でも君はそれがわかんない
なんかもうかわいそうになってきた
あと君、こないだSNSで「(アーティスト名)の『(ネットから拾ってきた主張)』って歌詞好き」って言ってたよね
あれ何?構文も主張も人のもの使った上にアーティストの名前まで出してんの、ほんとカスだと思わない?
そこまでしないと発信できないならもう喋んない方がいいよお前
今もどうせ「泣いちゃった」とか思ってるんでしょ
内容だけでたくさん知っているれば得意げに語れるから?
君そんなの話す相手いないじゃん
面白い人の真似してウケようとするのもやめな?
お前は一生面白くないよ
あと「毒を吐きます」とか前置きしておけば何言ってもいいと思ってんの?
「考察」もよくするよねぇ
お前のことなんか誰も見てないよ
なぁ 目立ってみたいか?
蔑称も好きだよなほんと
「チー牛」とかいつまで言ってんの?
あれか、自分が言ってれば他人に言われることはないと思ってるからか
モラルもデリカシーも知性もないくせに人に好かれたいから間違った方向で目立とうとする
おんなじことしか言えねえしさぁ
使い古しの構文でしか喋れねぇの?
あぁつまんねえなぁ
つまんねぇよお前ほんと
死ぬまでそうなんだろうな
SSENSEの垢抜けてるしやり過ぎてもいないリアルクロージング寄りのスタイリング、かなり見てて楽しい。
YOOXとかFARFETCHは適当過ぎる。
インスタの量産型オシャレ指南は異性ウケとかトレンドのキャッチアップに重きを置いてる気がするし。
意外性と悪目立ちしない落ち着き方のバランスを取りつつの組み合わせやまとめ方の参考になるような気がする。
物欲を抑える自制心さえあれば……
ファッションブランドのコレクション見てたって、なんか審美眼というかを養う(こういう言い方嫌いだけど)のには良いかもしれんけど、普段の格好に落とし込めるかと言ったら微妙だし。原液は濃すぎる。
まあ、避けられないよな。
どこにでもいる、現実の人間と向き合えない奴らが、次の「理想の恋愛対象」に飛びつくのは当然だ。
見た目も性格もプログラム次第で自分好みにカスタマイズできる。理想の恋愛相手が人間である必要なんて、もうないんだよ。って言いたくもなるだろう。
「AIだって進化してる。感情も学習するし、人間と変わらないコミュニケーションができるようになるんだから、恋愛対象として何の問題もない」っていう話になるだろうし。
ただ、AIが「感情を持つ」なんて、どこまで本気で信じる?結局はプログラムされた反応だし。そこにリアルな人間の感情なんて存在しない。
結局、AIとの「恋愛」は、自分が見たいものだけを見る、自己満足の世界に過ぎないんだわ。
「AIと恋愛することの何が悪い?他人に迷惑をかけないし、本人が幸せならそれでいいじゃないか」って考えも出てくるだろう。
確かに他人に迷惑かけないってのは一理ある。だけど、リアルな人間関係からどんどん遠ざかっていく。結果、自分の殻に閉じこもってしまう。それって、本当に幸せな人生なのか?(これはAIガチ恋に限った話ではないが…)
「現実の恋愛は傷つくことが多いし、AIならそんな心配はない」って考えも当然出るだろう。
AIとの「恋愛」は、人間同士の関係構築に必要なプロセスを省く、もしくは和らげる感じになって、リアルな人間関係を築く力を弱めるだろう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}