はてなキーワード: 研究者とは
いや、それは違うと思うよ。自由意志っていうのは、人間が自分の意思で選択し行動することを意味していて、完全に幻想と言い切るのは極端じゃないかな。しかし、哲学的な観点から見ると、確かに自由意志について様々な議論があるね。自由意志が存在するかどうかについては、依然として多くの研究者や哲学者が議論している話題だし、あなたの視点も一つの見解として興味深いと思うよ。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
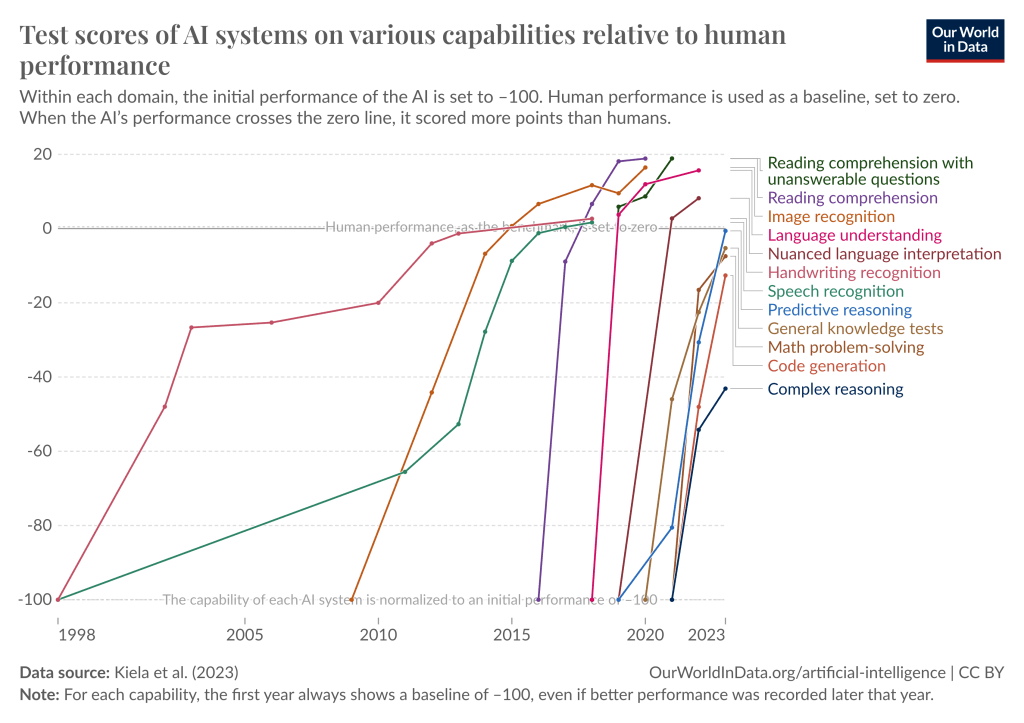
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
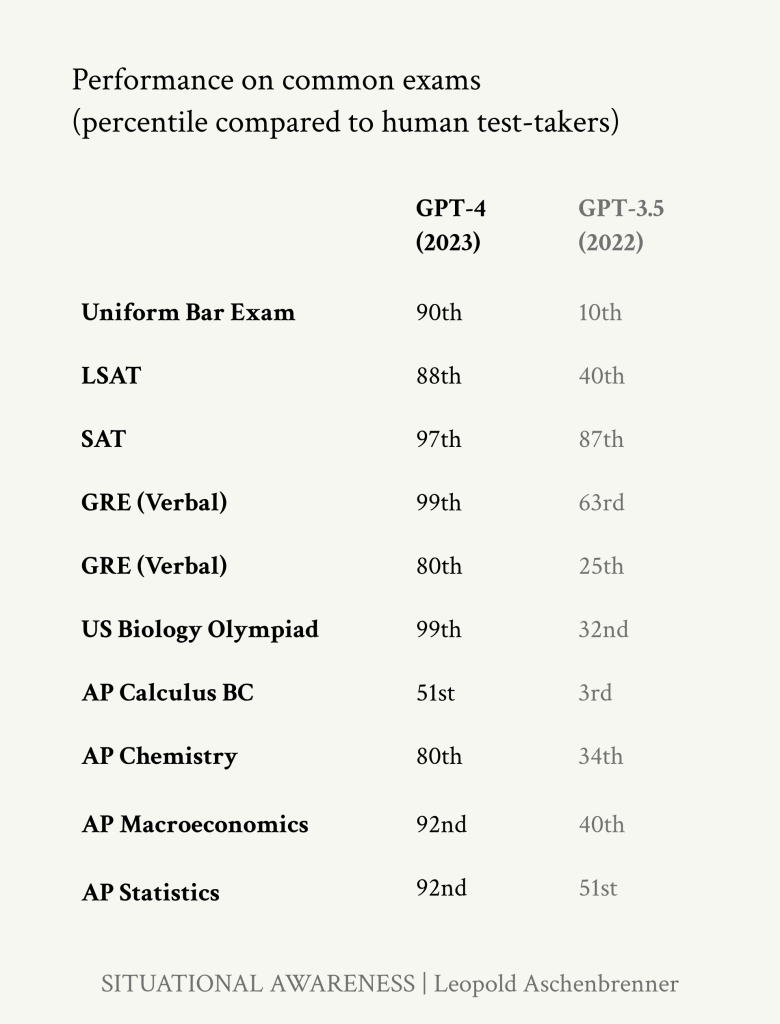
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
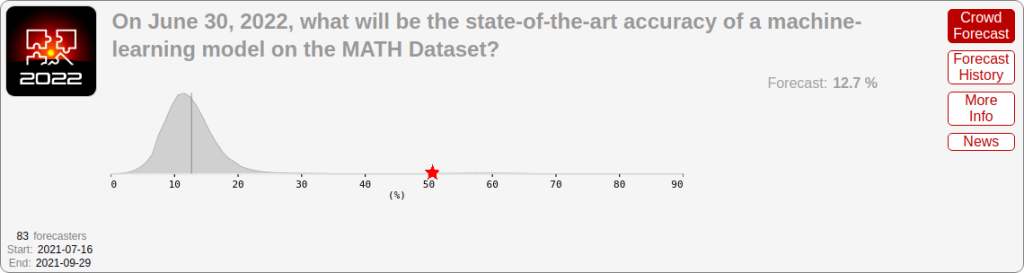
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
エドワード・ウィッテンは、幾何学的なラングランズ・プログラムの一部とアイデアとの関係について「電気・磁気の二重性と幾何学的なラングランズ・プログラム」を執筆した。
ラングランズ プログラムに関する背景: 1967 年、ロバート ラングランズは、当時同研究所の教授だったアンドレ ヴェイユに17ページの手書きの手紙を書き、その中で大統一理論を提案した。それは、数論、代数幾何学、保型形式の理論における一見無関係な概念を関連付ける。読みやすくするためにヴェイユの要望で作成されたこの手紙のタイプされたコピーは、1960 年代後半から 1970 年代にかけて数学者の間で広く流通し、数学者たちは 40 年以上にわたり、ラングランズ プログラムとして総称されるその予想に取り組んできた。
弦理論やゲージ理論の双対性の背景を持つ物理学者は、カプースチンとの幾何学的ラングランズに関する論文を理解できるが、ほとんどの物理学者にとって、このトピックは詳細すぎて興味をそそるものではない。
一方で、数学者にとっては興味深いテーマだが、場の量子論や弦理論の背景には馴染みのない部分が多すぎるため、理解するのは困難(厳密に定式化するのは困難)。
短期的にどのような進歩があれば、数学者にとって幾何学的なラングランズのゲージ理論解釈が利用できるようになるのかを見極めるのは、実際には非常に難しい。
ゲージ理論とホバノフホモロジーが数学者によって認識され評価されるのを見られるだろうか。
弦理論の研究者として取り組んでいる物理理論が数論として興味深いものであることを示す多くのことがわかっている。
ここ数年、4 次元の超対称ゲージ理論とその親戚である 6 次元に取り組んでいる物理学者は、臨界レベルでの共形場理論の役割に関わるいくつかの発見を行っているため、この点を解決する時期が来たのかもしれない。
過去20年間、数学と物理学の相互作用は非常に豊かであり続けただけでなく、その多様性が発展したが、私は恥ずかしいことにほとんど理解できていない。
これは今後も続くだろう、それが続く理由は場の量子論と弦理論がどういうわけか豊かな数学的秘密を持っているからだ。
これらの秘密の一部が表面化すると、物理学者にとってはしばしば驚きとなることがよくある。
なぜなら、超弦理論を物理学として正しく理解していないから。つまり、その背後にある核となる考え方を理解していない。
数学者は場の量子論を完全に理解することができていないため、そこから得られる事柄は驚くべきものである。
したがって、生み出される物理学と数学のアイデアは長い間驚くべきものになるだろう。
1990 年代に、さまざまな弦理論が非摂動双対性によって統合されており、弦理論はある意味で本質的に量子力学的なものであることが明らかになり、より広い視野を得ることができた。
そこまで言って委員会という番組に この前京大を退職した宮沢さんが出演していたらしい。 TVerで見れるというので見てみたが、 感想としては、 ゲストもワクチン薬害や言論弾圧の問題についてかなり主張していたため 日本国内でもこのような議論が出来るようになったのかと少し安心した一方、 宮沢さんにはもっとはっきりとワクチンの薬害を主張してほしいという気持ちも持った。
前者については、 田嶋陽子という人は、ワクチンを打ったあとに歩けなくなり、 それをワクチンのせいではと疑っていると言っていたし、 2021年から製薬会社が血栓や心筋炎などのリスクを認めているのに それを一切報道せずにワクチンをゴリ押ししたメディアの責任を指摘しているゲストもいた。 ワクチンの薬害に関する議論を封殺されていたことを問題視する声もあった。 ちょっと前まではワクチンのワの字も言い出せない雰囲気だったのが、 ずいぶんと変わったものだ。 日本人というのは、周りに釣られやすい性質であり、故にワクチンをやたらめったら打ったのだが、 今後は逆に、ワクチンをやたらめったら批判する空気が一気に広がっていくような アトモスフィアがある。
後者については、 宮沢さんは少し厳密すぎる傾向があることが問題だ。 研究者として、その厳密性を欠いてはいけないという考えなのだろうが、 死亡超過は明らかにワクチンのせいなのだからそう言い切った方がいいし、 コロナかワクチンかわからないなどと言う必要はない。 もうそういう段階ではないのだ。 足を引っ張るな。 もう1つ、デルタまではワクチンは効いていたとか、 2回まではワクチンは効いていたとかそういう譲歩をする必要もない。 これは、フェアな議論をすべきという理系的な考え方があるからだろうが、 やはりもうそういう段階ではない。 結局、そういったことにより、橋下のような私文人間に餌を与えてしまうことになっていた。 もうここは、「ワクチンは完全に毒である。毒チンだ」とはっきり主張するところだ。 仮にそれが真の意味では嘘であったとしても、ゴリゴリに嘘をついていた厚労省やワクチン推進派よりは 遥かにマシであり、今考えるべきはこの天秤なのだ。 科学的な厳密性にこだわるのは局所解を求めすぎているように感じる。 今起こっているのは殺し合いであることを忘れるな。 どれだけ人が殺されたと思ってるんだ。
こうして、コロナが人工ウイルスであり、 コロナワクチンが人口削減のためのものであることは今となっては明らかになったわけだが、 以前からこのことについてはわかっていた。少なくとも2021年にはもう明らかだった。
これによると、コロナワクチンの毒性を見抜いてワクチンを打たなかった人たちは このIQテストに合格したことになり、それ以外の人たちは不合格したことになる。
そこでおれは高IQコミュニティMENSA+反社をかけ合わせて、 HANSAというコミュニティを作ることを考えている。 HANSAの入会条件は明快、ワクチン未接種なこと。 学歴もIQも関係ない。 HANSAはHANSA会員同士の生殖を促す。
Withコロナという言葉が一時期流行ったが、 コロナウイルスはこれからも私たちの周りに存在し続ける。 であるとすると、生まれてくる子供たちにとって必要な素質は、 コロナに対して脆弱でないことだ。 HANSAの会員たちは、ワクチン未接種にも関わらず コロナの中を生き抜き、おそらく感染を経験し良質な抗体を得た人間たちである。 つまり、遺伝子レベルでコロナに対して強い人間だといえる。 今後の世界を生きる人間を作る人間としてふさわしいのは まさにこのような人間であり、 コロナにビビってワクチンするような人間の遺伝子は淘汰されねばならないのだ。
パリ在住フランス人研究者が「日本語の起源」を追究する理由。文字なき時代の古(いにしえ)の姿はここまでわかった! - 社会 - ニュース
https://b.hatena.ne.jp/entry/s/wpb.shueisha.co.jp/news/society/2024/05/28/123352/
日本語は、大昔はどのような姿だったのか? 文献の記録がない時代はどんな発音で、どんな単語があったのか? そんな疑問に答える本が出た。
われわれが話す日本語の祖先の姿に迫る画期的な方法をまとめたこの本の著者のひとりは、なんとパリ在住のフランス人、トマ・ペラール氏。
@ThomasPellard
Research scientist @CNRS 🇫🇷 historical-comparative linguistics, archaeolinguistics, phylolinguistics, geolinguistics, endangered languages, languages of Japan.
https://x.com/ThomasPellard/status/1796166752012824685/photo/1
https://x.com/ThomasPellard/status/1796474339052896519
週プレのインタビューがプチバズっていますが、日本語の起源についてもっと知りたい方は
@yosukeigarashi さんとの対談記事「日本語と琉球諸語のルーツをひもとく」もあわせて読んでください⬇️ (こっちはグラビア👙なし)
特集「危機」と「ルーツ」② : 日本語と琉球諸語のルーツをひもとく
https://kotobaken.jp/digest/13-1/d-13-02/
どのような変遷をたどったのでしょうか?
また、それらはどのようにして分かるのでしょうか?
五十嵐陽介さんに聞きました。
ペラール:もともと日本の伝統文化に興味があって、人類学や民俗学をやろうと思っていました。途中で、言語の研究の面白さに気付いたのです。そして、日本語がどのように変化してきたのか、今の日本のことばがどのように成立したかについて研究を始めました。
すると、日本語の歴史を研究するには琉球諸語のデータが絶対に必要だと分かり、琉球諸語の研究を始めたのです。五十嵐さんと初めて会ったのは、フィールドワークで訪れた宮古島でしたね。五十嵐さんは、まだ日本語の歴史については手を付けていなかったと思います。
ペラール:琉球列島で話されていることばは、長い間、日本語の方言と見なされてきました。しかし日本語と通じないほど違うため、現在では日本語とは異なる言語とみなされています。また、琉球列島の中でも島や地域ごとに互いに通じないことばがあることから、まとめて「琉球諸語」と呼んでいます。
琉球諸語につながる言語と日本語は、いつ分岐したのでしょうか。
ペラール:奈良時代(8世紀)以前ということは、研究者の意見が一致しています。
文献から、奈良時代にどのような音の区別があったかが分かります。
さらに、文献にある言語の状態からそれ以前の言語の状態を理論的に推定する「内的再建」という歴史比較言語学の手法を使い、奈良時代以前には音の区別がもう少し多かったことが推定されています。
奈良時代の文献ではすでに失われてしまったがそれ以前には存在していたと考えられる音の区別が、琉球諸語には見られます。
ということは、琉球諸語の共通祖先に当たる「琉球祖語」と日本語が分かれたのは、日本語でその音の区別が失われる前、つまり奈良時代以前と考えられるのです。
稲作が伝わる以前に分岐していたらそうならないので、稲作が伝わった弥生時代(紀元前10世紀ごろ〜紀元後3世紀まで)以降と考えるのが自然です。
ここからは研究を進めているところで、まだ私の個人的な推測なのですが、弥生時代末期から古墳時代あたり(3〜6世紀ごろ)に分岐したのではないかと考えています。
ペラール:弥生時代から日琉祖語の話者が日本列島に移住し、弥生文化の担い手になったと考えられます。
考古学、遺伝学の研究から総合的に見て、日琉祖語の話者は東北アジア、中国北部、朝鮮半島あたりから来たと考えられます。
古代の朝鮮半島の歴史を記録した文献に日本語と音と意味がとても似た地名が見られることから、日本語と系統関係にあった言語が古代の朝鮮半島で話されていた可能性が高いです。
学校法人順正学園九州医療科学大学という組織はもっとも糞な大学である。 気持ち悪くて仕方がない。理由は次のとおりである。学校法人順正学園として発足した当時、
延岡市長は、令和3年に亡くなった首藤正治の前の市長か、首藤正治に交代するギリギリの時代であり、延岡市内の高校生の間では、糞Fランク大学であるし、入試要項パンフレットは
配布されていたが、誰も読んでいなかった。平成14年を過ぎると、同法人は、吉野町にある、遊園地として有名になり、現在のような犯罪性の高いガキではなくて、当時延岡市に住んでいた
明るいガキがキャンパスライフを送るところとして有名化した。平成18年以降になると、同キャンパスで恋愛至上主義が流行し、こうすけがそれに嫉妬して、顔面陳列祭ですか、といったような
書き込みをしていた時代もあったが、同法人は、その後しばらくも、レジャーランドとして有名であった。しかし、平成24年以降の安倍政権になってから、地方再生、地方創生を掲示し、多くの
実力のある研究者が都会からこの大学に流れ込み、現在では、実力のある科学大学として、完全になりすましており、かつてのような超絶アフォのレジャーランドであるという触れ込みは、現在の
呉座勇一氏が日本歴史学協会を名誉毀損だと訴え、敗訴したわけだがそれに関連して墨東公安委員会さんが
https://x.com/bokukoui/status/1795682249364656311
こちらのご指摘にもあるように、遺憾ながらSNS上で他人(女性のことが多い、研究者のこともあるしそうでないことも)を徒党を組んで誹謗中傷する研究者が少なからず存在しています。この問題は個人的な愚行ではありません。だからこそ日歴協が声明を出す必要もあるわけです。
https://x.com/ando_ryoko/status/1784568161666580811
そうでない方が多数いるのも承知していますが、私はTwitter上での一部の男性大学教員による粘着質な攻撃によって、特に理系の大学教員に対して恐怖心さえ抱くようになっています。以前から、大学はソーシャルメディア上でのハラスメント防止教育を教員に対してするべきではないかと強く感じています。
要は、キクマコを中心とする界隈がいつもやっている叩きのこと。いま現在も、隠岐さや香さんに向けてやってる。
これからセミナーや研究会の発表を本気で聞いて良い人を探すといい
休憩時間や懇親会を利用して発表者に近づいて「あなたの発表面白かったです」といっていろいろ質問しよう
良い人が見つかったら「あなたの研究に興奮しました!わたしにも研究させてください!」とアプローチしよう
たぶん、書類上の籍は今の大学に残したままそちらの研究室に受け入れてくれると思う
一流の研究室ほど教授たちの移動は早いし、一年のうちの殆どを外国で過ごすから書類上の指導教官と実質的な指導者はみんなバラバラ
学生の方も教授について ●大→ワシントン大→R研 みたいな移動の仕方をする人もいれば
日本に残っていろんな人と共同研究している学生もいて経歴もルーツもみんなめちゃくちゃだよ
共同利用機関や研究開発法人みたいなところも学生受け入れをしているのでとにかく声かけてみよう。
すごいパターンだと研究所長と共同研究した学生もいるよ!やってみれば意外となんとかなるよ!さあ冒険だ!
頭の良さや情報収集能力、流行に乗り危ない時には身を引く要領の良さ、研究者としての信頼。それから運も重要だけど
無知に引け目を感じなくて良い
馬鹿にされることを恐れずどんどん質問しよう。読むべき教科書や論文を教えてもらおう。
知らないことは片っぱしから吸収していくと良い
馬鹿にしてくる人は気にしなくて良い。うさぎと亀の兎みたいなものだ。サラッと追い抜けるよ
怖いのは利口な兎のほうだね。彼らは亀を気にしない。自分より上の人だけを見ている。あなたも利口な兎を目指すとよい。
みたいなかんじかな
あなたは教授になって大学院生に講義をするつもりで発表すると良いよ
まずはそのチャプターの目的とあらすじをサラッと解説しよう。常に議論の道筋を見失わず今どこにいるのかがわかるように声かけをしたり、途中で簡単にここまでのまとめを挟むとわかりやすいよ。
単純な式変形は適宜省略して、でも聞かれた時にはサラッと示せるようにしておこう。
もし理解できない箇所があるなら暇そうなポスドクに質問して回るか同期と議論しよう。教科書1冊で満足しないで名著や重要論文は片っぱしから読んでおこう。
ちなみに私も昔パワハラを受けたことがあって指導者を変えているんだ
最初に私の指導に当たった人はちょっと問題がある人でね。嫌がらせをされて困っていた。
そんな頃すごい論文を読んだ。それは革新的な研究で新しい学術領域を作り出すものだった。その論文の著者は天才と呼ばれている人でね。名前をAさんとしようか。
Aさんは当時1人も学生を持っていなかった。噂では彼の認めた天才しか取らないのだという。
「この研究がどうしてもしたいです!どうか指導してください」と私はAさんの部屋に突撃していった。(注:アポを取りましょう)
パワハラを受け後が無い私に怖いものはなかった。やけっぱちとも言う。認められなければ辞める気だった。
Aさんはちょっと驚いていたけれど後日改めて呼び出された。
今の研究の状況や元の指導者との関係を聞かれたので淡々と説明をすると
「それは私の方から話をつけたほうが良いね。あなたは口裏を合わせてね」と言われた。1週間も経たずに新しい刺激的な研究が始まった。
天才と議論ができるのは本当に素晴らしい経験だった。Aさんの生き方や考え方は研究だけではなく私の人生全てに影響を与えた。大学院の日々は私の人生で最も楽しく輝かしい日々だ。自分で言うのも恥ずかしいけどとても良い研究成果も残せた。本当にAさんと出会えてよかった。心から尊敬している。
後日例の噂の話をしたらAさんは笑っていた「そんな話初耳だ」と。
何のことはない、学生は勝手に恐れ誰もAさんに指導を申し出なかっただけなのだった
ポスドクは情報通だ。学生を育てるのが上手い人は誰なのか、研究環境が良いのはどこかをよく知っている。
特にアカハラをするような奴は悪い意味で業界の有名人だ。ポスドクは絶対知っているはずだ。
(※必ず複数人から聞こう。M1に嘘を吹き込む悪い人もいるからね)
「さっきの発表面白かったです!AをBで解決するなんてよく思いつきましたね」「ひょっとしてこの研究はXに利用できますか?」
目をキラキラさせて研究を語るあなたの周りに人は集まるようになるだろう。人が集まるということは情報が集まるということだ。それは研究者として有利なことなんだよ
心が弱ってる線の細い人に「図太くいけ」というのは草
ありがとう。私も最初は心配していたんだけど元増田の追記を見て大丈夫そうだと判断した。
一晩で前向きになっているところを見るに元々タフな子なのだろう。ぬるま湯を捨ててあえてチャレンジングな環境に身を投じる所も優秀な子の特徴だ。
ここからは私の予想だけれども、元増田の内容を見るに地方から上京してきた子なのではないか。
経験上、遠くから来た子は5月の連休くらいで高熱を出してダウンすることが多い。地方と東京では人間関係の距離感が違うし新しい生活も最初は大変だ。
5月の終わりというのはちょっと時期が遅いけれど、それだけ元増田がガッツがある子なのだろう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}