はてなキーワード: 基本的とは
サークルの追い出しコンパでみんなで風俗へ行く慣わしがあった俺の時代とは大違いである
ただ分かるんだよなー、正直言って行った後の感想戦に関しては「え、なんでそこ共有せんといけんの?」とは思った
別に感想戦が嫌だから行かないって話でもないだろうけど、基本的に風俗へ行っていることなんか秘匿したいと思うのは人として当然だと思う
つまり何が言いたいかと言うと、行ってても行かない主義のフリは当然しますよと
それは単純に知られたくないってだけじゃなくて、現代において女を買ってますなんて公言をするのは大きくカーストを落とす行為なのである
男女同権とかフェミニズムとかそういうのも多少あろうけど、女を金で買うってのは気持ちの上で「負け組」だからだし、横の情報網で「あいつは風俗へ行った」と知人の女性に知られる可能性だってある
なもんで、行っても言わないだろうし、行ってもデメリットがあまりにもデカ過ぎるので本当に行かないってのは理解できる
Twitterなどで風俗レポ漫画が人気あるのも行ったことのない秘境を教えてくれる貴重な情報だからだろう
風俗へよく行く人間からすれば、風俗レポ漫画を見てもその内容が当たり前過ぎて「これのどの部分にオリジナリティを読み取れば良いんだ??」と困惑したはずだ
俺はもう40のおじさんでピンサロ、ヘルス、ソープ、M性感、オナクラ、外国人、出会い系、男の娘、ハプニングバー、ハッテン場と一通りの風俗は遊び尽くしてしまったので新たな感動は得られないんだが、そんな俺でも「無理していく必要は無いんじゃないかな」とは思っている
俺は酒が飲めないから他の人が酒で消費する金をたまたま風俗に使っているだけで、人生の経験値的な話で言えば幾数多ある要素のただの一種類でしかない
自分も風俗遊びの話を公の場ですることは無いので、知人友人と共有できないことに金と時間を費やしてしまったという意味においては無為な経験だったとは思う
親愛度をあげる→試験で補正が入るようになる(≒試験で使わないからレッスンでPドリンクばんばん使ってもよくなる)
スレスパだとカードやレリックが増えてもコンボが組みにくくなるから一長一短だったけど、学マスの場合は増えるカードの大部分が初期カードより強いからレベルが上がるほどガン有利。
しかもメモリーで強カードを確保した状態からスタート出来るんだから凄いよね。
たとえばスレスパで「バリケード」「塹壕」「ボディスラム」「不動」を最初から持った状態でスタート出来たらヤバイでしょ?
学マスはそれが出来ちゃうの。
ヤバイね。
そんで一度TRUE見たら最終ステに補正入るし、親愛度を上げる段階で試験は楽になるしカード再選出回数も増えるし、ほんまヤバイでしょ。
ローグライクって基本的にやればやるほどアセンションがあがって難しくなるけど、学マスは違う。
やるほどに簡単になる。
まあゆーてチョコボの不思議なダンジョンみたいなやればやるほどドンドンヌルくなるローグライクは昔からあったと言えばそうかもね。
でもなんとなく最近はやるほどにムズくなるゲームが流行っててさ、特にスレスパクローンはカード増えるほど闇鍋になってコンボ狙えないからアドリブで解決するしかなくなってくのが、学マスはコンボのしやすさがドンドン加速するわけだから認識がバグるね。
マジでさ、ここまでゲーム難易度が下がっていくなんて思わんかったんよマジでさ。
まあA+いつかは見れる仕組みじゃないとしんどすぎるのは本当にそうだと思う。
あんまりムズいと課金圧になりすぎるし、緩和されるまで放置する人とかも増えそうだもんね。
まあ逆に皆クリア出来ちゃったらやることなくなる問題はある気がするけど。
たとえばウマ娘もハルウララの隠しイベみたいのがあったからどこかでやり続けてた人とかもいると思うわけよ。
それが案外簡単に見れたらさ、ね?
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
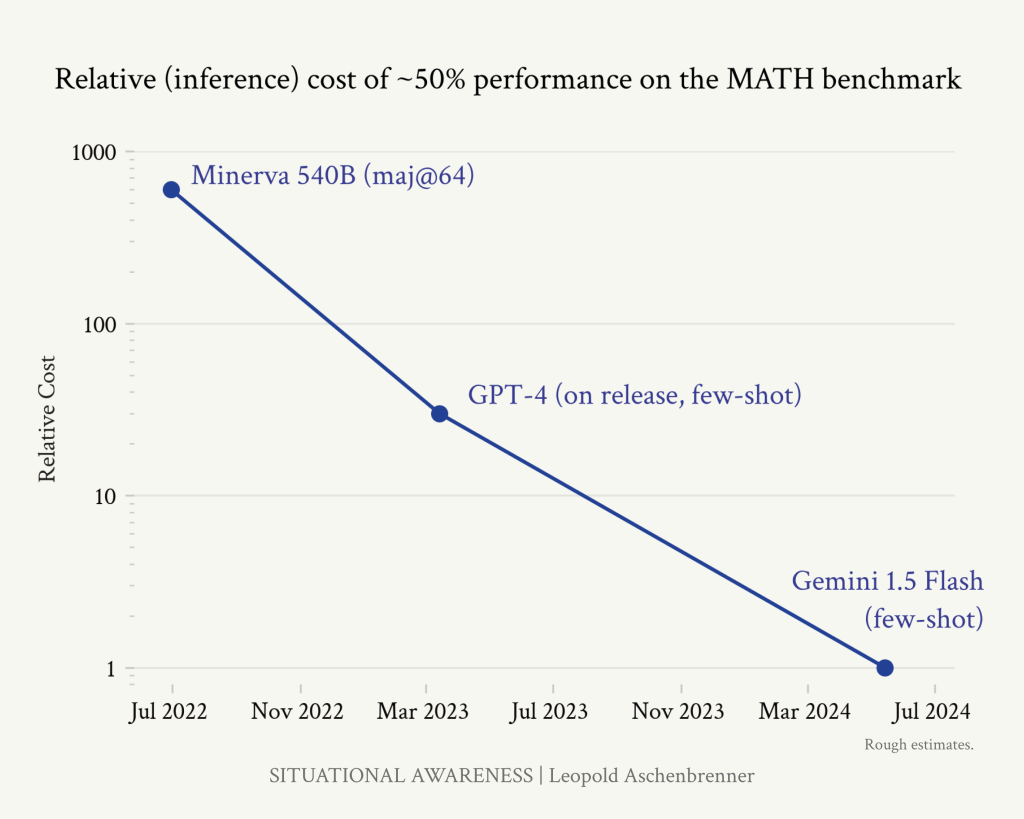
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
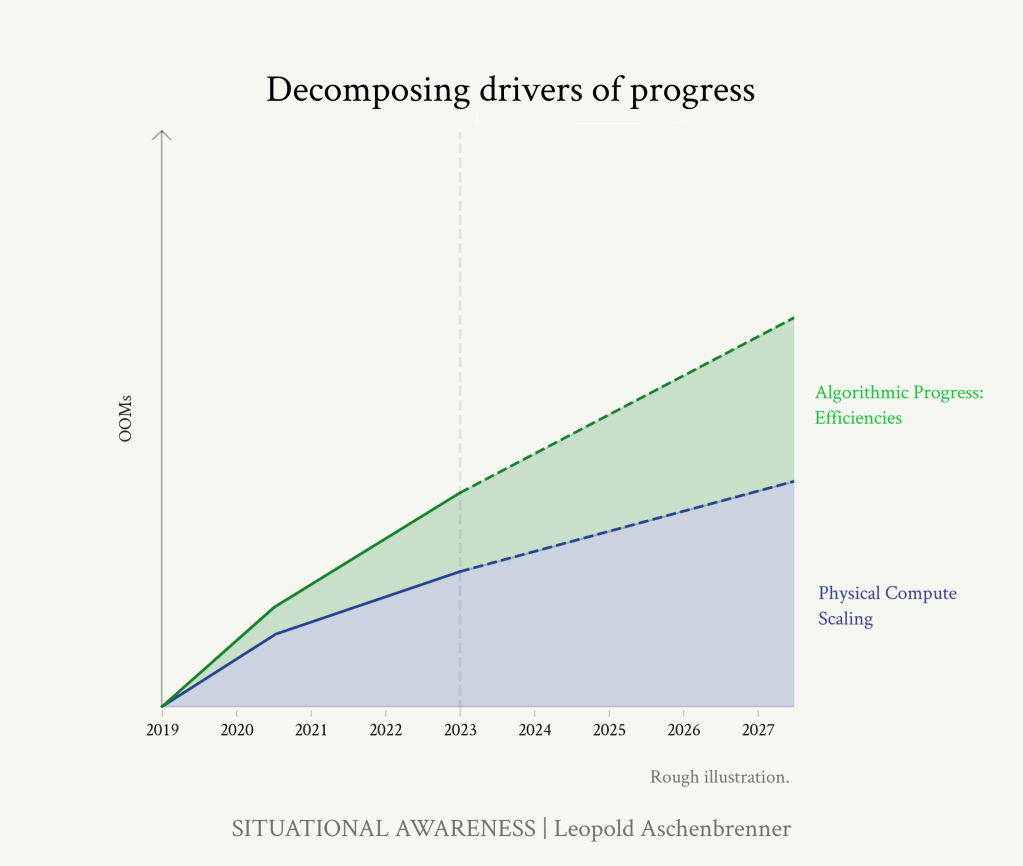
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
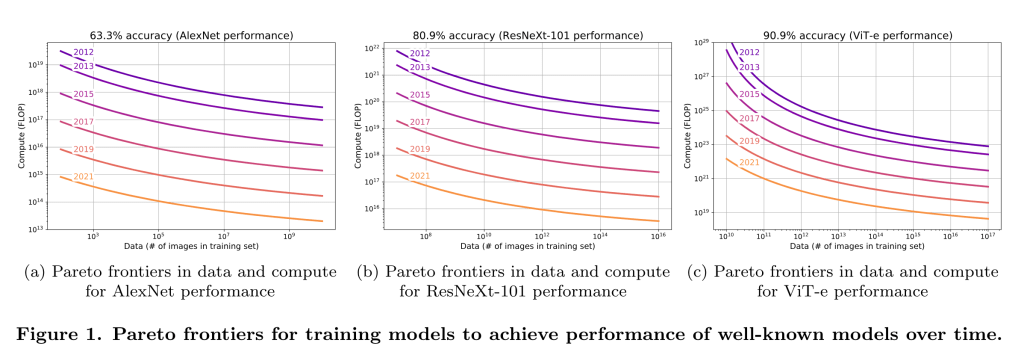
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
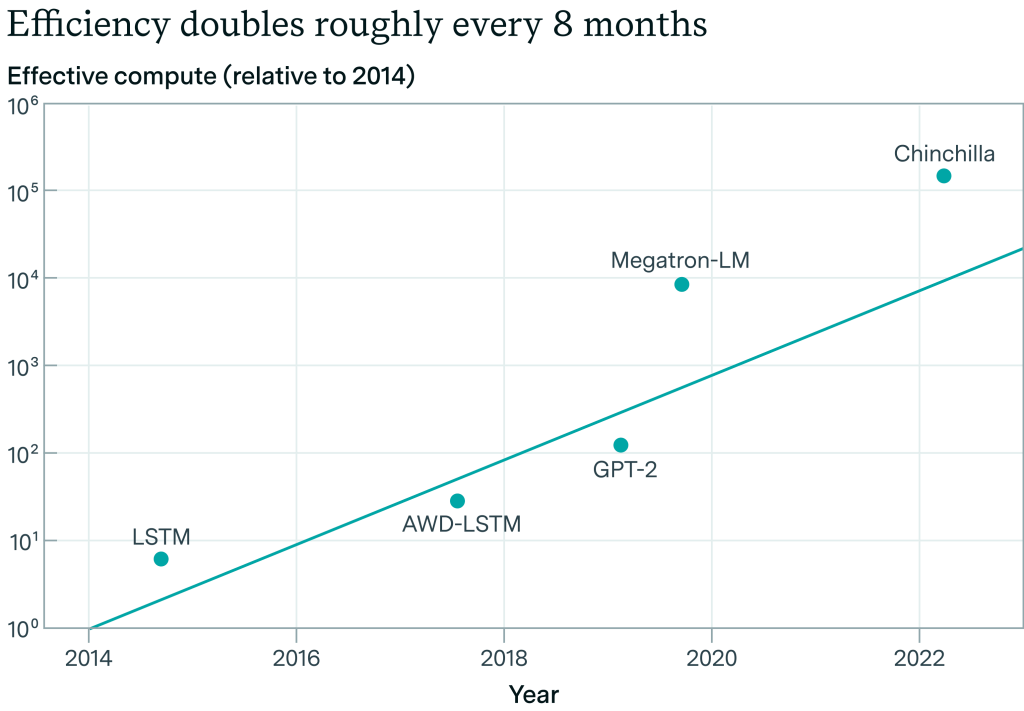
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
私たちは今、基本的に人間のように会話できるマシンを手にしている。これが普通に思えるのは、人間の適応能力の驚くべき証であり、私たちは進歩のペースに慣れてしまったのだ。しかし、ここ数年の進歩を振り返ってみる価値はある。
GPT-4までのわずか4年間(!)で、私たちがどれほど進歩したかを思い出してほしい。
GPT-2(2019年)~未就学児:"わあ、もっともらしい文章をいくつかつなげられるようになった"アンデス山脈のユニコーンについての半まとまりの物語という、とてもさくらんぼのような例文が生成され、当時は信じられないほど印象的だった。しかしGPT-2は、つまずくことなく5まで数えるのがやっとだった。記事を要約するときは、記事からランダムに3つの文章を選択するよりもかろうじて上回った。
当時、GPT-2が印象的だった例をいくつか挙げてみよう。左:GPT-2は極めて基本的な読解問題ではまあまあの結果を出している。右:選び抜かれたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争についてある程度関連性のあることを述べた、半ば首尾一貫した段落を書くことができる。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt2_examples-1024x493.png
当時、GPT-2について人々が印象に残った例をいくつか挙げます。左: GPT-2は極めて基本的な読解問題でまあまあの仕事をする。右: 厳選されたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争について少し関連性のあることを言う、半ば首尾一貫したパラグラフを書くことができる。
AIの能力と人間の知能を比較するのは難しく、欠陥もあるが、たとえそれが非常に不完全なものであったとしても、ここでその例えを考えることは有益だと思う。GPT-2は、その言語能力と、時折半まとまりの段落を生成したり、時折単純な事実の質問に正しく答えたりする能力で衝撃を与えた。未就学児にとっては感動的だっただろう。
GPT-3(2020年)~小学生:"ワオ、いくつかの例だけで、簡単な便利なタスクができるんだ。"複数の段落に一貫性を持たせることができるようになり、文法を修正したり、ごく基本的な計算ができるようになった。例えば、GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt3_examples-1.png
GPT-3について、当時の人々が印象に残った例をいくつか挙げてみよう。上:簡単な指示の後、GPT-3は新しい文の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。上:簡単な指示の後、GPT-3は新しい文章の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
繰り返しになるが、この比較は不完全である。しかし、GPT-3が人々に感銘を与えたのは、おそらく小学生にとって印象的だったことだろう。基本的な詩を書いたり、より豊かで首尾一貫した物語を語ったり、初歩的なコーディングを始めたり、簡単な指示やデモンストレーションからかなり確実に学習したり、などなど。
GPT-4(2023年)~賢い高校生:「かなり洗練されたコードを書くことができ、デバッグを繰り返し、複雑なテーマについて知的で洗練された文章を書くことができ、難しい高校生の競技数学を推論することができ、どんなテストでも大多数の高校生に勝っている。コードから数学、フェルミ推定まで、考え、推論することができる。GPT-4は、コードを書く手伝いから草稿の修正まで、今や私の日常業務に役立っている。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_examples-3.png
GPT-4がリリースされた当時、人々がGPT-4に感銘を受けた点をいくつか紹介しよう。上:GPT-4は非常に複雑なコードを書くことができ(中央のプロットを作成)、非自明な数学の問題を推論することができる。左下:AP数学の問題を解く。右下:かなり複雑なコーディング問題を解いている。GPT-4の能力に関する調査からの興味深い抜粋はこちら。
AP試験からSATに至るまで、GPT-4は大多数の高校生よりも良いスコアを出している。
もちろん、GPT-4でもまだ多少ばらつきがある。ある課題では賢い高校生よりはるかに優れているが、別の課題ではまだできないこともある。とはいえ、これらの限界のほとんどは、後で詳しく説明するように、モデルがまだ不自由であることが明らかなことに起因していると私は考えがちだ。たとえモデルがまだ人為的な制約を受けていたとしても、生のインテリジェンスは(ほとんど)そこにある。
https://situational-awareness.ai/wp-content/uploads/2024/06/timeline-1024x354.png
続き I.GPT-4からAGIへ:OOMを数える (3) https://anond.hatelabo.jp/20240605204704
すでに汚れきった大人ではあるけれど、最近やっと動物の可愛さに目覚めたので初めて猫カフェに行ってみた。
猫たちは可愛かったし店員さんの接客も良かったしとても癒された、しかし、汚れきった大人なので表題の感想が出てしまった。お店や猫にもよるんだろうけど、猫は基本的に寄ってこない。そっと触っても逃げる。店員さんには懐いてる。
ただちゅーるを手にしたときだけやってくる。まるでドリンクとかオプションとかチップを出したときの嬢だ。おやつやおもちゃ(ドリンクか大人のおもちゃ)の持ち込みは禁止だし、完全にそれじゃん。慣れたいけど虚無だし猫もストレス溜まってそうだしどうしようと思う私は童貞のそれなのであった(リベンジしそうだな)。
リベラルの主張って大体は
戦争に巻き込まれない、殺されない、性犯罪に遭わない、といったごくごく基本的な人権の話じゃん
本気でそれらがそれが贅沢品に見えるなら
なんか色々どう振る舞うのが正解かみたいな話出てるけど
基本的に相手に性的な好意持たれてるかどうかでしかないと思ってる
話術なり金使うなり色々やったとして、結局相手が自分に性的な魅力を感じてなかったらそもそもペニス出す雰囲気にならないでしょ
逆に相手が性的に魅力を感じてくれてれば、無言でボーっとしてたってああ今ペニス出すんですね?了解ですみたいになる
身も蓋もないけどそれが現実なのでペニス出すタイミングわかんないやつはとりあえず清潔にしておくことくらいしかできる事はないと思う
ほんとこれなんだよな。
恋愛工学みたいに最後まで振り切るとおかしくなるけど、最初の入り方はやっぱりこれくらい数をこなせるようにするのが必要。
じゃないと、基本的に嫌われてるのがデフォな男が女性と付き合うとか無理なんだよね。
女は無理なことをいらいろと言うけど、しょせん男エアプ。
6項目中5項目で厳しい条件での検査、とか言ってるけど
例えば衝突試験で台車重量(1100kg→1800kg)を増やして試験したのは一見すると厳しい条件に見えるけど
エアバッグなんかは衝突エネルギーが大きいほど発火しやすいので1100kgの方が厳しい条件になる
もちろん他の要素だと1800kgの方が厳しくはなるけど要素によってはそうと限らないから「1800kgの方が厳しい」とは言えない
それに対して自動車乗ってるだけの素人が外野からヤジを飛ばすのはもっとNG
そもそも、エアバッグをタイマー点火しておいて「試験の基準より厳しい衝突条件を作り出す」とか言ってるのは外野からしても意味不明
トヨタは相当エアバッグに自信がないんじゃない?ホントに作動するのかね
その点、スバルは2023年の自動車アセスメントで最高評価のファイブスター大賞を受賞してるし
みんな黙ってスバル買えば良いんだよ
卵巣嚢腫に何度かなったせいで10代前半から二十歳過ぎくらいまで婦人科に世話になっていた
大体どこの病院も婦人科と産婦人科は同じフロアで待合室は共用だと思うんだけど
何度も通った感想、奥さん(妊婦)の付き添いの旦那勢は基本的にうるさい
いや、流石にギャーギャー大声で騒ぎ立てる事はないけど普段の声量から2割抑えたくらいの声でしか話さない
ついでに移動する時も遠慮のないドスドス歩き
対して母子や姉妹で来てる人らは別。話すにしてもヒソヒソ話だし、歩く時も気を遣ってサササッと移動していく
でもワイ、人生で3回限界を超えて努力した時、全部取り返しのつかないマイナスの結果になったんだけどなあ
・中学生の時やきうを限界まで頑張ったら、都大会でいいとこまでイったけど腰を壊して半年も何もできなくなり引退
・とある事情で関節ぶっ壊してプチ不具者状態(身バレ防止の為曖昧)
・仕事頑張り過ぎて顔面崩壊して老人様顔貌+顎関節症+奥歯削り取られる+メニエール病+鬱病
頑張ろうって言う根性は良い事だけど、人間は自分の上限を超えるのは不可能だと思う
そして「努力が足りていない」という説教はそれが全くのデタラメなので基本的に有害だし、そうすると「努力の方向性が悪い」と言われる事がたまにあるんだけど
少し前にディズ⚪︎ーランド辞めたから、テーマパークに来るアトラクションでの痛客を語りたい。
車椅子に乗った、とにかく若いキャストと話したいセクハラ常連おじさん。
アトラクションによるけど、基本的に車椅子だとキャストが1人ついて乗り場まで案内するサービスがあるので、その移動時間にとにかく喋りまくる。
頻繁に来る上に障害者用のシステムを利用して予約→案内するキャストがおっさんおばさんだと分かるとキャンセル、を繰り返していたのでかなり迷惑がられていた。
あと、「結婚願望ある?」「彼氏とどう?」などの怒られないギリギリのセクハラも止まらない。
【2位】1番前に乗せなきゃ⚪︎すぞ反社パパ
実はアトラクションはモノとタイミングによるけど、「1番前に乗りたい」って言うとあんまり断られない。1番前に限らず、「子供が怖がるから1番後ろに」とかも含めて1回待つことで次の便で希望の席に通してあげてもいいってマニュアルが一応ある。
これで他の人の希望を通した結果、本来1番前に座るはずだった人が2列目に通されることになって、“1番前に座れると思ったのに座れないじゃないか!”ってキレた家族連れのパパがいた。
その場合は次で1番前に案内すればいいだけなんだけど、このパパのキレ方は尋常じゃなかった。若い男のキャストを怒鳴りつけて硬直させ、乗り場は騒然。
運営が妨げられるので端っこにガタイの良いおっさんキャストが連れていって説得するも、「俺は××(有名反社)のもんだぞ!!!⚪︎すぞ!!!」「メンツ潰す気か!?」と大騒ぎしていた。おっさんキャストと奥さんが宥めてなんとか場が収まったけど、「いってらっしゃーい!」って笑顔で手を振りながら、収めてよかったのか?警察が必要じゃない?とは思った。
あと、なんでこの反社パパがこんなにキレてたのかというと、列に並んでる時に自分たちの前にいる人と乗り物の列を計算して、子供たちと「1番前に乗れるぞ!」「えー!なんでパパわかるの!?」みたいな会話をしていたっぽい。
まさか反社パパのメンツがディ⚪︎ニーランドのアトラクションで1番前に乗れなかっただけで潰れてしまうとは思わなかった。
割と有名であろうディ⚪︎ニー系YouTuber。Vlog撮ることに命をかけているので、人の話は聞かない、撮影禁止のもの平気で撮る、“××の秘密”みたいなアトラクションの捏造動画を作って拡散したりするので対応に追われる。
それだけならインターネットに沢山いるし、なんならコロナ後はこんな奴らの相手ばっかりだけど、こいつは自分だけの特別対応がほしくてキャストの前でゴネる→上司の許可とって条件付きで渋々許可する→動画撮影→前後切り取りでTikTok、みたいなことを平気でやるから、ネットで顔晒されて「特別扱いするなんて!」みたいにボコボコにされたキャストが1人病んだ。
あとアトラクション止まった時に若いキャストガン詰めして泣かせる動画撮ってるのも見かけたから、いっそあれ公開して炎上してほしい。
予想外のことすると、最悪轢かれたり落ちたりしてタヒんじゃうこともあるからアトラクションの運営を妨げるのはやめよう!
アトラクションが突然止まるのもシステム調整とは説明するけど、ガチのシステム不具合3割、客の落とし物2割、客の対応で乗り物が発進できずに詰まって安全装置が働いてダウン5割、が現実なので小さな迷惑行為が誰かの1日に影響を与えることもある。
アトラクションのキャストは、キラキラ魔法の住人!とかよりは安全な乗り物の運転に行動のリソースが割かれているので、ラッシュ時の駅で働く駅員とかだと思ってほしい。お誕生日シールは手ぶらのキャストじゃなくてバッグ持ってる人にねだってほしい。
既に書いたが流動性高いのである。生活費が安く済むし行政サービスも平均以上で悪くないので住み続けるのもできるが、住んでて死ぬまで川崎に閉じこもるのかと言われたら、普通に市外に就職もするし遊びに行く。免許取っちゃえばお台場に30分、ディズニーランドに1時間弱、丹沢にバーベキューに行って川に流されたっていい。川崎は基本的に企業城下町として発展してきた町でありその意味で地方都市的な性格が大きいが、一方で電車に飛び乗れば20分で銀座に着くお手軽ベッドタウンでもある。「流される」ことは多々あるだろうが「腐る」ことはない。
川崎ヤバイネタの定番はJFE、かつての日本鋼管だった。日本鋼管に勤めてる人は給料が良かったので川崎に一戸建てを建てる人も多かったが、その家の当主は家を建ててすぐ死んでしまうというので「命と金の交換会社」と呼ばれていた。鉄粉や石炭粉塵舞う口上をマスクもせず働いてたそうなので。そんなJFEの製鉄も終了である。ヤバいネタはどんどん消えていく。
中学時代といえば、地下街アゼリア新星堂で「八神くんの家庭の事情」のイメージアルバムを購入して店を出たところでスーツ姿の中年のオッサンに声をかけられ、お茶に誘われた。声かけて即座に太ももを撫でてきて、ちんこまでちょいちょい触れてきたので当然のごとく誘いを断ったが、当時はあれが性的意味だとちゃんと理解してなかったのでちょっとヤバかった。
上記の痴漢は平均的サラリーマン姿のおじさんであり、そういう人のがヤバいのだろう。一方で川崎駅前をトンチキな格好の人が歩いてることがあるが、基本、歩いてるだけである。
アゼリア地下街のど真ん中で痴漢というと凄く治安が悪いと思われるかもしれないが、当時、駅前のゲーセンで遊び倒していてトラブルに巻き込まれたことは皆無である。ゲーセンでヤバそうに見えるのは川崎駅から離れた産業道路近くのラウンドワンとかベネクス、あるいは今はとっくに潰れてる町内の小さいゲーセンとかは雰囲気がヤバげではあったが、三国志大戦や艦これアーケードであっちこっち入り浸ってた頃も特にトラブルはなかった。三国志大戦で言うなら高津あたりのがよほど(略
川崎駅前で有名どころといえばタケちゃんマンの歌で有名な堀之内(風俗街)だが、再開発でマンション建てまくって往年の面影はない。飲み屋街の仲見世通りも客引きが多いが善光寺の門前で一定の秩序が保たれてる(店は選ぶ必要がある)。堀之内よりガラが悪く素人は行くなで有名な南町も風俗店はだいぶ減って客引きもいなくなり、普通に歩ける。というか川崎区民の通勤通学路であり、XX組の黒塗りの車がやたら停めてる前を女子高生やサラリーマンが徒歩や自転車で大勢通り抜けている。一方、昔の闇市だった平和通りや砂子通、銀柳街が昔の一般商店が消えて風俗や夜の店ばかりになり、こちらは静かになって逆にガラが悪くなったなーと思ったりする。
ガルクラでお出しされる川崎市の風景だがセレクトに引っ掛かりを感じることはちょくちょくある。川崎駅前の路上ライブの場所が浮浪者を追い出して作られた話は先日書いたが、昔の駅前はそこらじゅうに浮浪者が寝ていた。駐輪場入口など特に排水溝に小便をするのでめっちゃ臭かった。一方で浮浪者はそこにいるだけなので特に害があるわけでもなく、治安悪化に直接影響するでもなく、直接接触するわけもないので汚いとも思っていなかった。どちらかといえば浮浪者にちょっかいを出すクソガキのほうが危険で、段ボールハウスに放火してボヤ騒ぎになった一部始終を見てたこともある。
自分が駅前で遊び飲み食いしても犯罪に巻き込まれることは(痴漢以外は)皆無だが、弟は駅前の路上で寝てたら財布を盗まれたそうである。寝るな、としか言えないが、浮浪者の目があった頃のほうが路上で寝てても安全だったかもしれないと思う。
仁菜ちゃんが練習してる多摩川河川敷の公園だがすぐ目の前にマンションがある。あの公園やマンションは多摩川の堤防の河川側に家を建てて住んでた人たちに立ち退いてもらうために整備された場所。多摩川が増水するたび被害が出て危険なので補助金を出して立ち退いてもらったという場所なので、行政の努力の場でもある。
あの多摩川の公園の向かい側にあるのはリクルート事件の発端となった開発エリア。どうせならソリッドスクエアの1階の噴水をバックに汚い大人たちを思いっきり蔑む歌詞をシャウトしてくれても楽しい。
智ちゃんとルパちゃんの住んでる河原町団地は有名だが、そこからもう少し先に行くと川崎競馬の小向厩舎がある。早朝5時前に行くと小向厩舎から多摩川河川敷の練習場へと競走馬が公道を横断してるので、馬を眺めながらのシーンがあっても可愛い感じで良いのでは。そこからウマ娘とコラボをぜひに
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}