はてなキーワード: 計算とは
でもな、すでに一人産んでるカップルに「もう一人」を期待するのと、そもそも結婚してない(出会ってもいない)人たちに最初の一人を期待するの、どちらが合理的よ? どう考えても支援の費用対効果は前者が高い
| 階級↓ | 00 | 05 | 10 | 15 |
| 20-24 | 88.0 | 88.7 | 89.6 | 91.4 |
| 25-29 | 54.0 | 59.1 | 60.3 | 61.3 |
| 30-34 | 26.6 | 32.0 | 34.5 | 34.6 |
| 35-39 | 13.9 | 18.7 | 23.1 | 23.9 |
| 40-44 | 8.6 | 12.2 | 17.4 | 19.3 |
| 45-49 | 6.3 | 8.3 | 12.6 | 16.1 |
| 50-54 | 5.3 | 6.2 | 8.7 | 12.0 |
ここに実数を乗せるとこんな感じ(単位1000人、以下実数は同じ)
| 階級↓ | 00未婚 | 既婚 | 05未婚 | 既婚 | 10未婚 | 既婚 | 15未婚 | 既婚 |
| 20-24 | 3626 | 494 | 3199 | 408 | 2865 | 332 | 2714 | 255 |
| 25-29 | 2609 | 2,222 | 2420 | 1,675 | 2193 | 1,443 | 1961 | 1,238 |
| 30-34 | 1156 | 3,190 | 1548 | 3,289 | 1431 | 2,717 | 1261 | 2,384 |
| 35-39 | 559 | 3,465 | 813 | 3,534 | 1123 | 3,739 | 992 | 3,157 |
| 40-44 | 334 | 3,547 | 491 | 3,536 | 759 | 3,604 | 938 | 3,921 |
| 45-49 | 281 | 4,173 | 321 | 3,548 | 507 | 3,517 | 699 | 3,645 |
| 50-54 | 278 | 4,960 | 274 | 4,152 | 335 | 3,518 | 479 | 3,516 |
| 総数 | 494 | 22052 | 408 | 20141 | 332 | 18870 | 255 | 18116 |
既婚者は以下の出生実数を乗じる。ただしこの数字は2000年がなくそこは2002年である
| 年 | 02年 | 05年 | 10年 | 15年 |
| 0人 | 3.4% | 5.6% | 6.4% | 6.2% |
| 1人 | 8.9% | 11.7% | 15.9% | 18.6% |
| 2人 | 53.2% | 56.0% | 56.2% | 54.0% |
| 3人 | 30.2% | 22.4% | 19.4% | 17.9% |
| 4人以上 | 4.2% | 4.3% | 2.2% | 3.3% |
一方、婚外子の数は夫婦の2.5%を割り当てる(2020年データ、対象の年次は大体このぐらいで微増傾向)
すると、各年の出生はこうなる
| 年 | 00年 | 05年 | 10年 | 15年 |
| 婚内子 | 491 | 413 | 369 | 351 |
| 婚外子 | 1.23 | 1.03 | 0.92 | 0.88 |
さて。
明治期の最大婚外子率9.4%をオマケして10%にしたところで、増える数は2.7(=0.9*3、雑ぅ)。はい消えた―(どん(なるほどざわーるど
次。夫婦の子供数分布を時計の針をギュギュっと戻して1987年並みにしてみましょう。
| 年↓ | 0人 | 1人 | 2人 | 3人 | 4人以上 |
| 1987年 | 2.7% | 9.6% | 57.8% | 25.9% | 3.9% |
| 2015年 | 6.2% | 18.6% | 54.0% | 17.9% | 3.3% |
15年の夫婦数で87年の子供数を維持できた場合、子供の数は396。増加数は45になります。うーむ
次。15年の人口で、未婚率を1985年まで引き下げてみましょう
| 年↓ | 1985年 | 2015年 |
| 20-24歳 | 81.6 | 91.4 |
| 25-29歳 | 30.6 | 61.3 |
| 30-34歳 | 10.4 | 34.6 |
| 35-39歳 | 6.6 | 23.9 |
| 40-44歳 | 4.9 | 19.3 |
| 45-49歳 | 4.3 | 16.1 |
| 50-54歳 | 4.4 | 12.0 |
すると、
| 未婚 | 既婚 |
| 4665 | 22505 |
となり、さっきの計算をすると子供の数は435。増加は84となります。
2000年から、2020年まで、25歳~45歳までの未婚率は約1割増加しているが、これがもし未婚率が2000年並に保たれていつつ、既婚女性の生涯出産数が1.9に減少したと計算すると、未婚率の増加による子どもの数への影響が推定でき、これがおおよそ300万人になる。
単純に増えた減ったから違うとか言うんじゃなくて、そこから影響度を計算して考えてみてくれ。
そしてその2002年から今まで、35歳未婚率の推移確認した?約15%が約33%になってるんだぞ。
影響が大きくて優先度が高いとは言えないだろ。
https://www.ipss.go.jp/syoushika/tohkei/Popular/Popular2024.asp?chap=0
2000年から、2020年まで、25歳~45歳までの未婚率は約1割増加しているが、これがもし未婚率が2000年並に保たれていつつ、既婚女性の生涯出産数が1.9に減少したと計算すると、未婚率の増加による子どもの数への影響が推定でき、これがおおよそ300万人になる。
一方で、2000年の既婚女性の生涯の子どもの数、2.23から1.9への減少率0.33を、現在の45歳以下の既婚女性の年齢をかけると、既婚女性の生涯の子どもの数の減少による影響を推定でき、およそ220万人になる。
計算はいずれも既婚女性の数は統計値を使っているので、人口減少の影響は加味されている。もちろんこの計算は色々な部分をすっ飛ばしているため正確な形ではないが、結論は変わらない。
https://news.yahoo.co.jp/expert/articles/16ec62ee8524944af0039b0d1a40b24aed942535
「結婚できた夫婦の子ども数は増えている」のに全体の出生数が減り続けているワケ
子のいる世帯の平均子ども数
就業構造基本調査をもとに、「夫婦と子世帯(=一人以上の子を産んだ世帯)」だけに限って、年齢別の平均子ども数を、最新の2022年と15年前の2007年とで比較したものが以下である。
むしろ15年前より2022年の方が子どもの数は増えているのだ。
これは「結婚ができた夫婦というのは、15年前よりも一世帯当たり子どもは多く産んでいる」ということになる。言い換えれば、出生数が減っているのはそのまま婚姻数が減っているからだと言える。
2007年と2022年の出生数と婚姻数の増減を比較すれば明らかである。
主と副のどちらが契約が先か、所定労働時間は何時間か、労働はどちらが先かで複雑に絡み合ってる
確かに、「アルゴリズム」という言葉がどのように使われるかについては議論の余地があります。
技術的には、「アルゴリズム」とは特定の問題を解決するための一連の手続きやルールを指しますが、広義には次のように理解されることもあります。
アルゴリズム取引:アルゴリズム取引(アルゴ取引)は、コンピュータプログラムを使って自動的に取引を行う手法を指します。
これは、特定のアルゴリズムに基づいて売買のタイミングや数量を決定するので、この文脈では「アルゴリズム」の使用は適切と言えます。
検索アルゴリズム:Googleの検索アルゴリズムは、検索結果をランキングするための計算手法やルールの集合体です。
これには、サイトの評価基準も含まれますので、「検索アルゴリズム」という表現も適切です。
ただし、アルゴリズムの一部である評価基準が漏れた場合、それを「アルゴリズムの流出」と呼ぶかどうかは表現の問題です。
つまり、「アルゴリズム」の広義の使用は必ずしも誤用とは言えず、文脈によって適切な場合もあります。
石村智にテクニックがないから熊谷が流行ってるんだろ。もともと、警察の仕事は、補題も計算も技術だが、大嶋には何も残っていない。 一番警察の技術がないのは、志村
あそこは頭が終わっている。
要点補題 要点を絞ったもので、簡単に証明できるもの。 東京大学の問題でも設問になっていることはなっている。
簡潔補題 異常に簡単な補題で、多少のきつい計算を要する証明。
国際数学の整数の問題は、 警部補が、 完全補題を設定して証明し、巡査がinductionによってやるか、別解では、連結誘導集合法が用いられた。ただし、連結誘導集合法は
一般にめんどうくさいと言われている。
高校は文芸部で、大学は理系だけど研究室が論文の誤字脱字に厳しいところだったので、まともな教育を受けた人間は校正に厳しいのが当たり前だと思ってる。
旧ツイッターなどは書いたら訂正できないシステムなので、ギリギリまで一文字一文字を見直すけど、それでもミスったら仕方ないと諦めていた。
だけど、増田みたいに何度でも訂正できるところで、「てにをは」レベルの、少し読みなおせば違和感を持つようなところをいくつも間違えたまま放置している奴は、それだけでバカに見えるし、いい加減でやる気がないのが伝わってくるからそもそも読もうとも思わない。
たまに仕事でもそのレベルの文書を恥ずかしげもなく出してくる奴がいると、ヤバいのに当たったなという気持ちで混乱する。
日本の(特に理系の)教育はまったく文章を書かせないので、官公庁クラスの書類でもこんなのありかと思うような酷いものが存在する。
自分はたまたま論文力を鍛えてくれる研究室で「どこまで細かくなるべきか」を身体で覚えさせて貰ったけど、日本の技術者は計算や図面が完璧でも、ドキュメントの日本語になると「てにをは」はおろか酷い誤変換やタイポを放置しまくるような人もいて、こんなことやってると信用を失くすぞと心配になってくる。
文章の粗さは知識の抜けや態度の不安定さと同じくらい他人の信用を損なう問題だということを、少なくとも自分がちゃんとした教育を受けたと証明したいならもうちょっと意識した方が良いよという話。
(※ちなみにこの文章だと、読みなおして「馬鹿」と「バカ」の表記の揺らぎが気になるくらいの躾け方をされた。今回はあえて気づいた上で放置しておくけど。)
侵攻前の100万を加えるってどういう計算だよ。もう50万溶かしてるだろ。戦車の損耗が毎月300~400、兵員の損耗が毎月4万近く。
おまけに傷病兵がすごい勢いで増える。あ、そっちは見殺しか。
https://www.mlit.go.jp/policy/shingikai/content/001389727.pdf
リンク先を見た上での話なんだけど
それって、ただ単に時間とお金の面で貧乏だからでしょ?国がこういうデータ出してるのに国民が一極化するのはぶっちゃけ国民が馬鹿だと思うんだよね。
一位の三重県と10万円も開いてんじゃん、40年働いたら単純計算4800万円も差が出るんだよ?
https://www.mlit.go.jp/policy/shingikai/content/001389727.pdf
リンク先を見た上での話なんだけど
それって、ただ単に時間とお金の面で貧乏だからでしょ?国がこういうデータ出してるのに国民が一極化するのはぶっちゃけ国民が馬鹿だと思うんだよね。
一位の三重県と10万円も開いてんじゃん、40年働いたら単純計算4800万円も差が出るんだよ?
私は以前、AGIへの短期的なタイムラインには懐疑的だった。その理由のひとつは、この10年を優遇し、AGI確率の質量を集中させるのは不合理に思えたからである(「我々は特別だ」と考えるのは古典的な誤謬のように思えた)。私は、AGIを手に入れるために何が必要なのかについて不確実であるべきであり、その結果、AGIを手に入れる可能性のある時期について、もっと「しみじみとした」確率分布になるはずだと考えた。
しかし、私は考えを変えました。決定的に重要なのは、AGIを得るために何が必要かという不確実性は、年単位ではなく、OOM(有効計算量)単位であるべきだということです。
私たちはこの10年でOOMsを駆け抜けようとしている。かつての全盛期でさえ、ムーアの法則は1~1.5OOM/10年に過ぎなかった。私の予想では、4年で~5OOM、10年で~10OOMを超えるだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/this_decade_or_bust-1200x925.png
要するに、私たちはこの10年で1回限りの利益を得るための大規模なスケールアップの真っ只中にいるのであり、OOMsを通過する進歩はその後何倍も遅くなるだろう。もしこのスケールアップが今後5~10年でAGIに到達できなければ、AGIはまだまだ先の話になるかもしれない。
つまり、今後10年間で、その後数十年間よりも多くのOOMを経験することになる。それで十分かもしれないし、すぐにAGIが実現するかもしれない。AGIを達成するのがどれほど難しいかによって、AGI達成までの時間の中央値について、あなたと私の意見が食い違うのは当然です。しかし、私たちが今どのようにOOMを駆け抜けているかを考えると、あなたのAGI達成のモーダル・イヤーは、この10年かそこらの後半になるはずです。
マシュー・バーネット(Matthew Barnett)氏は、計算機と生物学的境界だけを考慮した、これに関連する素晴らしい視覚化を行っている。
繰り返しになるが、非常に賢いChatGPTを想像するだけではいけない。趣味的な進歩ではなく、リモートワーカーや、推論や計画、エラー訂正ができ、あなたやあなたの会社のことを何でも知っていて、何週間も単独で問題に取り組めるような、非常に賢いエージェントのようなものになるはずだ。
私たちは2027年までにAGIを実現しようとしている。これらのAIシステムは、基本的にすべての認知的な仕事(リモートでできるすべての仕事を考える)を自動化できるようになるだろう。
はっきり言って、エラーバーは大きい。データの壁を突破するために必要なアルゴリズムのブレークスルーが予想以上に困難であることが判明した場合、データが足りなくなり、進歩が停滞する可能性がある。もしかしたら、ホッブリングはそこまで進まず、専門家の同僚ではなく、単なる専門家のチャットボットに留まってしまうかもしれない。もしかしたら10年来のトレンドラインが崩れるかもしれないし、スケーリング・ディープラーニングが今度こそ本当に壁にぶつかるかもしれない。(あるいは、アルゴリズムのブレークスルーが、テスト時間の計算オーバーハングを解放する単純なアンホブリングであっても、パラダイムシフトとなり、事態をさらに加速させ、AGIをさらに早期に実現させるかもしれない)。
いずれにせよ、私たちはOOMsを駆け抜けているのであり、2027年までにAGI(真のAGI)が誕生する可能性を極めて真剣に考えるのに、難解な信念は必要なく、単に直線のトレンド外挿が必要なだけである。
最近、多くの人がAGIを単に優れたチャットボットなどとして下方定義しているように思える。私が言いたいのは、私や私の友人の仕事を完全に自動化し、AI研究者やエンジニアの仕事を完全にこなせるようなAIシステムのことだ。おそらく、ロボット工学のように、デフォルトで理解するのに時間がかかる分野もあるだろう。また、医療や法律などの社会的な普及は、社会の選択や規制によって容易に遅れる可能性がある。しかし、ひとたびAI研究そのものを自動化するモデルができれば、それだけで十分であり、強烈なフィードバック・ループを始動させるのに十分であり、完全自動化に向けて残されたすべてのボトルネックを自動化されたAIエンジニア自身が解決することで、非常に迅速にさらなる進歩を遂げることができるだろう。特に、数百万人の自動化された研究者たちによって、アルゴリズムのさらなる進歩のための10年間が1年以内に圧縮される可能性は非常に高い。AGIは、まもなく実現する超知能のほんの一端に過ぎない。(詳しくは次の記事で)。
いずれにせよ、目まぐるしい進歩のペースが衰えることはないだろう。トレンドラインは無邪気に見えるが、その意味するところは強烈である。その前の世代がそうであったように、新世代のモデルが登場するたびに、ほとんどの見物人は唖然とするだろう。博士号を持っていれば何日もかかるような信じられないほど難しい科学的問題を、間もなくモデルが解決し、あなたのコンピュータのまわりを飛び回り、あなたの仕事をこなし、何百万行ものコードからなるコードベースをゼロから書き上げ、これらのモデルによって生み出される経済的価値が1年か2年ごとに10倍になるとき、彼らは信じられないだろう。SF小説は忘れて、OOMを数えよう。AGIはもはや遠い空想ではない。単純なディープラーニング技術をスケールアップすることがうまくいき、モデルは学習したがり、2027年末までにさらに100,000倍を超えようとしている。私たちよりも賢くなる日もそう遠くはないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/gan_progress-1.jpeg
GPT-4はほんの始まりに過ぎない。GANの進歩に見られるように)ディープラーニングの進歩の速さを過小評価するような間違いを犯さないでほしい。
続き I.GPT-4からAGIへ:OOMを数える(11) https://anond.hatelabo.jp/20240605212014
X (twitter) で SITUATIONAL AWARENESS: The Decade Ahead https://situational-awareness.ai/ というのが回ってきて非常に示唆に富むものだったので、DeepL (無料版 API経由) で訳してみた。
この1年で、街の話題は100億ドルのコンピュート・クラスターから1000億ドルのクラスター、そして1兆ドルのクラスターへと移り変わってきた。半年ごとに、役員室の計画にまたゼロが追加される。その裏では、残りの10年間に利用可能なすべての電力契約と、調達可能なすべての電圧変圧器を確保しようとする熾烈な争いが繰り広げられている。アメリカの大企業は、アメリカの産業力を結集させるために、何兆ドルもの資金を注ぎ込む準備を整えている。ペンシルベニア州のシェールフィールドからネバダ州の太陽光発電所まで、何億ものGPUが稼働する。
AGI競争が始まったのだ。私たちは思考し、推論できるマシンを作りつつある。2025年から26年にかけて、これらのマシンは多くの大学卒業生を凌駕するだろう。10年後までには、これらのマシンは私やあなたよりも賢くなり、本当の意味での超知性を手に入れるだろう。その過程で、この半世紀には見られなかったような国家安全保障の力が解き放たれ、やがて「プロジェクト」が始動する。運が良ければ、中国共産党との全面的な競争になり、運が悪ければ全面戦争になる。
今、誰もがAIについて話しているが、何が自分たちを襲おうとしているのか、かすかな光明を感じている人はほとんどいない。Nvidiaのアナリストは、まだ2024年がピークに近いと考えている。主流派の評論家たちは、「次の言葉を予測するだけだ」という故意の盲目に陥っている。彼らが見ているのは誇大広告といつも通りのビジネスだけで、せいぜいインターネット規模の新たな技術革新が起こるのを楽しむ程度なのだ。
やがて世界は目を覚ますだろう。しかし、今現在、状況認識を持っているのはおそらく数百人で、そのほとんどはサンフランシスコとAI研究所にいる。運命の不思議な力によって、私はその中に身を置くことになった。数年前、このような人々はクレイジーだと揶揄されたが、彼らはトレンドラインを信頼し、過去数年間のAIの進歩を正しく予測することができた。この人たちが今後数年についても正しいかどうかはまだわからない。しかし、彼らは非常に賢い人々であり、私がこれまでに会った中で最も賢い人々である。おそらく、彼らは歴史の中で奇妙な脚注となるか、あるいはシラードやオッペンハイマー、テラーのように歴史に名を残すだろう。もし彼らが未来を正しく見ているとしたら、私たちはとんでもないことになる。
各エッセイはそれぞれ独立したものですが、シリーズ全体として読むことを強くお勧めします。全エッセイのPDF版はこちら。
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは~未就学児から~賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生サイズの質的なジャンプが起こると予想される。
AIの進歩は人間レベルでは止まらない。何億ものAGIがAI研究を自動化し、10年に及ぶアルゴリズムの進歩(5以上のOOM)を1年以下に圧縮することができる。私たちは、人間レベルから超人的なAIシステムへと急速に進化することになる。超知能の威力と危険性は劇的なものとなるだろう。
驚異的な技術資本の加速が始まっている。AIの収益が急増するにつれ、10年末までに何兆ドルもの資金がGPU、データセンター、電力の増強に投入されるだろう。米国の電力生産を数十%増加させるなど、産業界の動員は激しくなるだろう。
米国の主要なAI研究所は、セキュリティを後回しに扱っている。現在、彼らは基本的にAGIの重要な機密を銀の皿に載せて中国共産党に渡している。AGIの秘密とウェイトを国家機関の脅威から守るには膨大な努力が必要であり、我々はその軌道に乗っていない。
我々よりもはるかに賢いAIシステムを確実に制御することは、未解決の技術的問題である。解決可能な問題ではあるが、急速な知能の爆発が起きれば、物事は簡単にレールから外れてしまう。これを管理することは非常に緊張を強いられるだろう。
スーパーインテリジェンスは、経済的にも軍事的にも決定的な優位性をもたらすだろう。中国はまだゲームから抜け出してはいない。AGIをめぐる競争では、自由世界の存亡がかかっている。我々は権威主義的な大国に対する優位性を維持できるのか?そして、その過程で自滅を避けることができるのだろうか?
AGIへの競争が激化するにつれ、国家安全保障が関与してくる。アメリカ政府は眠りから覚め、27~28年までに何らかの形で政府によるAGIプロジェクトが立ち上がるだろう。どんな新興企業も超知能を扱うことはできない。SCIFのどこかで、終盤戦が始まるだろう。
もし我々が正しかったら?
――――――――
私はかつてOpenAIで働いていたが、これはすべて一般に公開されている情報、私自身のアイデア、一般的な現場知識、あるいはSFゴシップに基づいている。
Collin Burns、Avital Balwit、Carl Shulman、Jan Leike、Ilya Sutskever、Holden Karnofsky、Sholto Douglas、James Bradbury、Dwarkesh Patel、その他多くの方々の有益な議論に感謝する。初期の草稿にフィードバックをくれた多くの友人に感謝する。グラフィックを手伝ってくれたジョー・ローナン、出版を手伝ってくれたニック・ウィテカーに感謝する。
続き I.GPT-4からAGIへ:OOMを数える(1) https://anond.hatelabo.jp/20240605203849
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
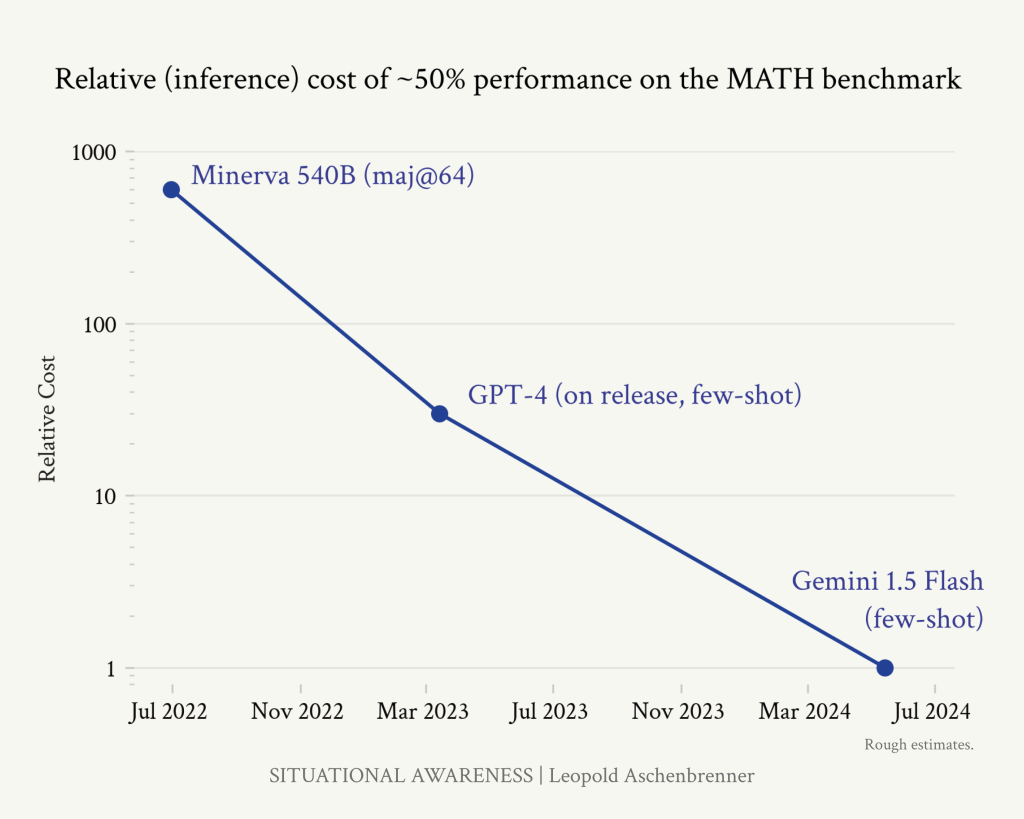
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
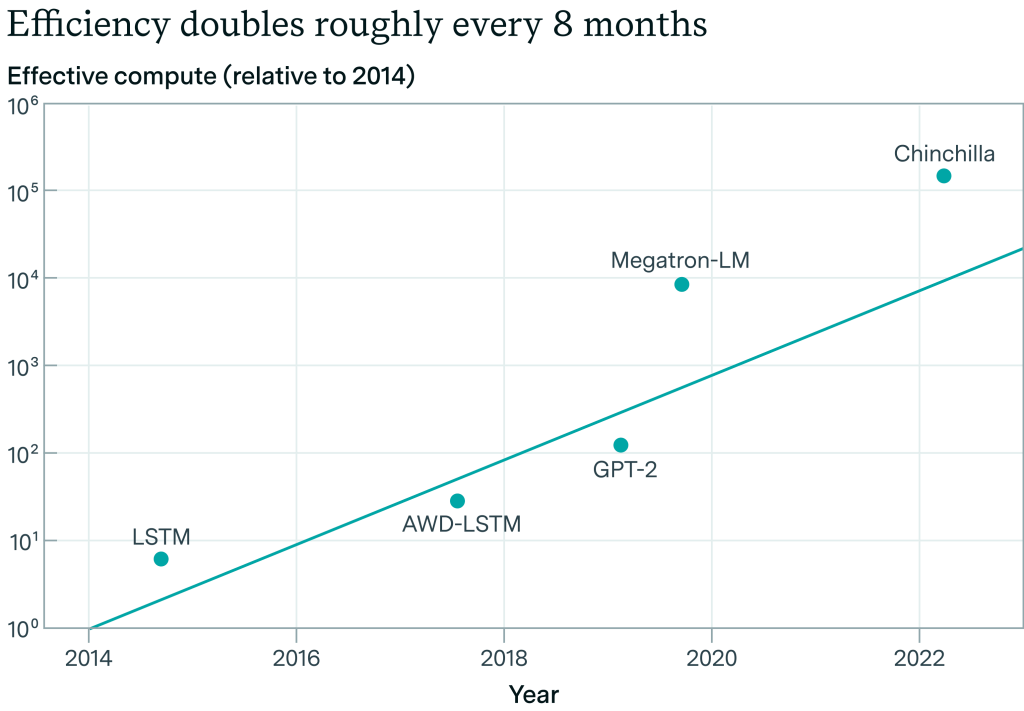
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
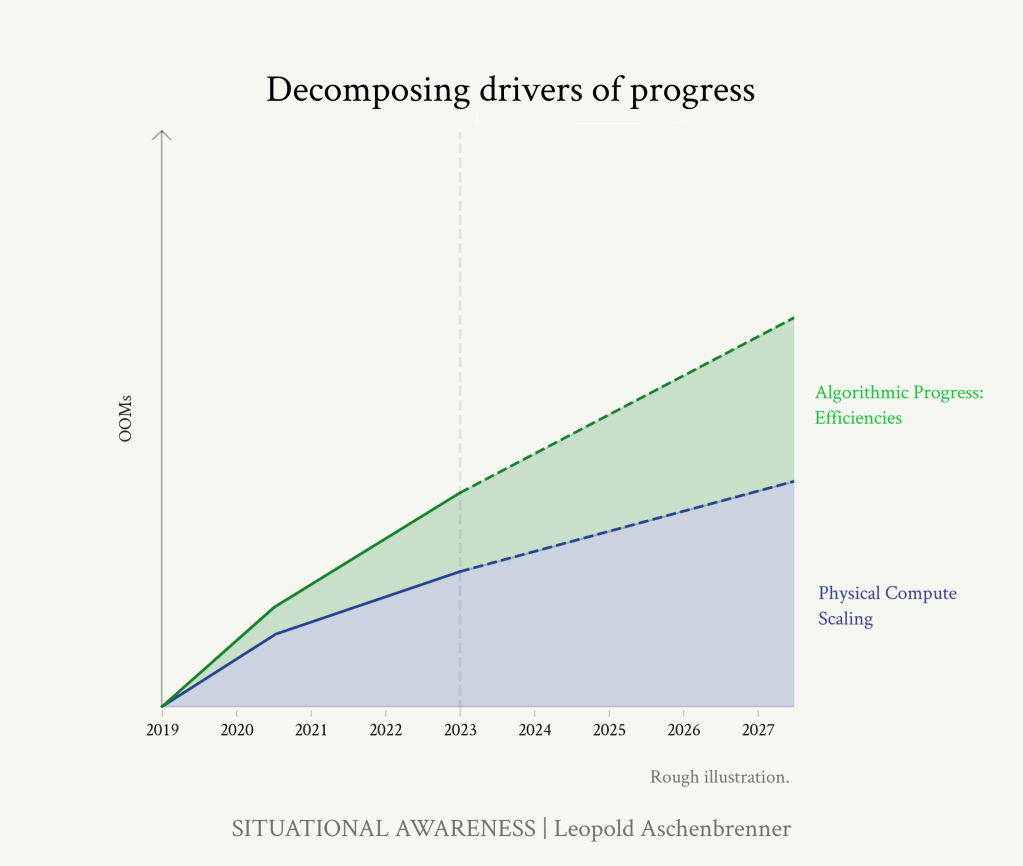
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
私たちは今、基本的に人間のように会話できるマシンを手にしている。これが普通に思えるのは、人間の適応能力の驚くべき証であり、私たちは進歩のペースに慣れてしまったのだ。しかし、ここ数年の進歩を振り返ってみる価値はある。
GPT-4までのわずか4年間(!)で、私たちがどれほど進歩したかを思い出してほしい。
GPT-2(2019年)~未就学児:"わあ、もっともらしい文章をいくつかつなげられるようになった"アンデス山脈のユニコーンについての半まとまりの物語という、とてもさくらんぼのような例文が生成され、当時は信じられないほど印象的だった。しかしGPT-2は、つまずくことなく5まで数えるのがやっとだった。記事を要約するときは、記事からランダムに3つの文章を選択するよりもかろうじて上回った。
当時、GPT-2が印象的だった例をいくつか挙げてみよう。左:GPT-2は極めて基本的な読解問題ではまあまあの結果を出している。右:選び抜かれたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争についてある程度関連性のあることを述べた、半ば首尾一貫した段落を書くことができる。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt2_examples-1024x493.png
当時、GPT-2について人々が印象に残った例をいくつか挙げます。左: GPT-2は極めて基本的な読解問題でまあまあの仕事をする。右: 厳選されたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争について少し関連性のあることを言う、半ば首尾一貫したパラグラフを書くことができる。
AIの能力と人間の知能を比較するのは難しく、欠陥もあるが、たとえそれが非常に不完全なものであったとしても、ここでその例えを考えることは有益だと思う。GPT-2は、その言語能力と、時折半まとまりの段落を生成したり、時折単純な事実の質問に正しく答えたりする能力で衝撃を与えた。未就学児にとっては感動的だっただろう。
GPT-3(2020年)~小学生:"ワオ、いくつかの例だけで、簡単な便利なタスクができるんだ。"複数の段落に一貫性を持たせることができるようになり、文法を修正したり、ごく基本的な計算ができるようになった。例えば、GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt3_examples-1.png
GPT-3について、当時の人々が印象に残った例をいくつか挙げてみよう。上:簡単な指示の後、GPT-3は新しい文の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。上:簡単な指示の後、GPT-3は新しい文章の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
繰り返しになるが、この比較は不完全である。しかし、GPT-3が人々に感銘を与えたのは、おそらく小学生にとって印象的だったことだろう。基本的な詩を書いたり、より豊かで首尾一貫した物語を語ったり、初歩的なコーディングを始めたり、簡単な指示やデモンストレーションからかなり確実に学習したり、などなど。
GPT-4(2023年)~賢い高校生:「かなり洗練されたコードを書くことができ、デバッグを繰り返し、複雑なテーマについて知的で洗練された文章を書くことができ、難しい高校生の競技数学を推論することができ、どんなテストでも大多数の高校生に勝っている。コードから数学、フェルミ推定まで、考え、推論することができる。GPT-4は、コードを書く手伝いから草稿の修正まで、今や私の日常業務に役立っている。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_examples-3.png
GPT-4がリリースされた当時、人々がGPT-4に感銘を受けた点をいくつか紹介しよう。上:GPT-4は非常に複雑なコードを書くことができ(中央のプロットを作成)、非自明な数学の問題を推論することができる。左下:AP数学の問題を解く。右下:かなり複雑なコーディング問題を解いている。GPT-4の能力に関する調査からの興味深い抜粋はこちら。
AP試験からSATに至るまで、GPT-4は大多数の高校生よりも良いスコアを出している。
もちろん、GPT-4でもまだ多少ばらつきがある。ある課題では賢い高校生よりはるかに優れているが、別の課題ではまだできないこともある。とはいえ、これらの限界のほとんどは、後で詳しく説明するように、モデルがまだ不自由であることが明らかなことに起因していると私は考えがちだ。たとえモデルがまだ人為的な制約を受けていたとしても、生のインテリジェンスは(ほとんど)そこにある。
https://situational-awareness.ai/wp-content/uploads/2024/06/timeline-1024x354.png
続き I.GPT-4からAGIへ:OOMを数える (3) https://anond.hatelabo.jp/20240605204704
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}