はてなキーワード: 論文とは
フェルマーの定理、通称、FLTは、平成8年までは、法学界の至宝のようにいわれていた理由として、歴史的な経緯があったが、最近では、そもそも、技術を編み出そうとした形跡すらない
ほとんど嘘であることがばれてしまったことによる。FLTは、 昭和20年代から、東京大理学部数学科の志村五郎、谷山豊、アンドレヴェイユなどが日光旅行をした際に共同研究していたとされ
るが、その概要を平成時代の者に説明する書籍も論文もどこにも存在しておらず、実質的に考えた形跡はどこにもないと言ってよい。その、実質的に考えた形跡はどこにもないことがとっくにばれてしまって
いるのが現況である。平成初年の老人は、背理法によるアプローチを思い付いたらしいが、そのようなことすら実行されている形跡がない。30年前の数学者は、背理法を研究して、完全背理法
または、背理法帰納法を強く使うとかそのような手段を考えたとか、5000通もの証明案が世界中から出たが、全て間違っていたことが判明したというような解説の本しかない。しかし、その
5000通の証明案の内容すら公表していないのだから、やはり完全な嘘だろう。またそのような哲学のモデルを構築したからといって、幸福に生きていくうえで何か参考になるのかというときに、ここ
10年の状況では何の参考にもならないから誰も考えていない。1つ参考になるのは、発達していて偉大で完全なものでないと技術的に応用できないとかいうことであるが、最近の女の子が、
発達していて偉大で完全で強力なもの自体を忌避しているのであり、なんの魅力があるのか理解できない。発達していて偉大で完全なものとして、高速計算機の、Sicamoreなどがあるが、行政
や大学がそのテクノロジーを悪事に転用していることはとうに露見しているのであり、日本列島に住む、その極めて悪質なものに関係せずに生活している者が、なぜその悪質なものの存在に気が
付かないのか理解できないという他がない。
フェルマーの最終定理は存在しないことの定理だから存在すると仮定して背理を導出する背理法の強力なものを編み出すことによって初等的に解ける可能性が高い。しかし、我が国の
理学部数学科ではそのようなアプローチを試みた論文は存在しない。これについて、行政の地区担当員から、そんなテクニックは存在しない、という囁きがあるだけで、東京都内の数学者、
地方の数学者からも、初等的な解法なるものは1つも聞かれない。Wikipediaには、無限降下法という不完全なもので極めて不完全に終わったという10年一日のような記載があるだけで、
具体的な論文はどこにもない。それどころか、10年前から、 FLT、FLT、と連呼されて、バクサイのSNSでも、到達不可能な定理とだけ言われるだけで何の具体性もなく、自分で考えた形跡
どころか、 n=4の場合の完全な証明は、実は赤チャートの一番最後に掲載されているが、それも理解できないといったような状況であるから、何が面白いのか理解できない。無限降下法は、
不完全なものであって不完全なものでは数学上技術にならないことはもちろんであるが、いずれにせよ、具体的に研究した形跡はどこにもないのであるから、完全な噓である。バカは到達不可能な
ものを設定し、多くの技術によって到達できると喜ぶが、現在ではもはや状況が変容し、そのような技能は必要がないと解される。数学の技術はいわば光っているものとか概念でもよいが、
数学の多くの偉大な定理は出版されたときに驚愕されると書いているだけなので、しかし、文化的な構成物で技術的に光っているものはどこにあるかといっても、最も分かりやすいのは、
バクサイSNSにいる者が何らかの人工知能を用いていることは明らかである。仮に行政が完全なものによる技術を開発し、人工知能から電波をヒトの大脳に送信しヒトの大腸を操作して排便を
促す装置を発明し作動させたとしても、事理の当然に、その人工知能がある場所にヤクザが拳銃を撃ちこんで終わりになるだけである。特定の個人がその人工知能の中にいるから自分が人工知能
の中で活躍できない結果として、刺されたり燃やされたりするのではなく、そもそも、その人工知能があることによって、自然状態として生活ができないことから、人工知能の装置自体を破壊した
方がいいように思われる。しかし、金が清掃工場に運ばれて燃やされたことが一度流行し、ただの紙屑になったという事実と、平成25年から今更になって金が全てと言っているのは甚だしく矛盾
している。
「尊師」は個人ブログでも論文上でも癇癪起こしてて、取り巻きは我田引水で論文掲載したり賞作ったりしてて、@math_jinとかいう素人信者は海外の数学コミュニティ荒らして日本の恥を広めてるし、誰も関わりたくないと思うのも当然
「尊師」は個人ブログでも論文上でも癇癪起こしてて、取り巻きは我田引水で論文掲載したり賞作ったりしてて、@math_jinとかいう素人信者は海外の数学コミュニティ荒らして日本の恥を広めてるし、誰も関わりたくないと思うのも当然
https://news.tv-asahi.co.jp/news_economy/articles/000352769.html
とりあえず、先生の名前と研究室でしらべたところ、東北大学の寄付講座とのこと。
寄付講座は企業や団体などがお金を出すから、大学の施設と名前を貸してねという講座。
そこの業績の欄に、歯科の商業雑誌への論文があり、手元にあったので、読んでみた。
装置の概要は、歯石を取るときに使う、超音波スケーラー(ピーッという音がして、金属で歯石を割りながら剥がす機械)の改良版。
論文には出てくる光の殺菌作用()と、特別な害がないこと(これは重要)が書いてあった。
結論として、これで歯周病が治るわけではない。あくまでも、歯石や歯垢をを取りながら、光で薬品を活性化させて殺菌をする装置。これまでも、水ではなく薬品を出しながら歯石歯垢を取る機器は多数あるので、それの類と考えて良い。
光はあくまでも補助的な部分と思われるので、その光と薬品に害がなければ、医療機器の認証が出るのも納得できる。(歯石、歯垢をとることは歯周病治療にとても有効。)
光で殺菌という考えも新しいわけではないが、効果が限定的なのもわかっている。バイオフィルムという細菌が作る塊の性状がその理由だが、簡単に書くと、うんこの内部を光と振動で殺菌することはできないということと同じだ。
口腔内では最近の餌と必要な温度と湿度は常に与えられるので、住みやすい環境(深い歯周ポケット、歯石、歯根の形態)があれば、少し残った細菌がすぐに増えて、元のようになる。
だから、この治療が普及すれば、歯周病から解放されるとか、そういうモノではなさそう。でも、マユツバな治療機器ではないから、少しでも治療が進歩するといいと思う。
高校は文芸部で、大学は理系だけど研究室が論文の誤字脱字に厳しいところだったので、まともな教育を受けた人間は校正に厳しいのが当たり前だと思ってる。
旧ツイッターなどは書いたら訂正できないシステムなので、ギリギリまで一文字一文字を見直すけど、それでもミスったら仕方ないと諦めていた。
だけど、増田みたいに何度でも訂正できるところで、「てにをは」レベルの、少し読みなおせば違和感を持つようなところをいくつも間違えたまま放置している奴は、それだけでバカに見えるし、いい加減でやる気がないのが伝わってくるからそもそも読もうとも思わない。
たまに仕事でもそのレベルの文書を恥ずかしげもなく出してくる奴がいると、ヤバいのに当たったなという気持ちで混乱する。
日本の(特に理系の)教育はまったく文章を書かせないので、官公庁クラスの書類でもこんなのありかと思うような酷いものが存在する。
自分はたまたま論文力を鍛えてくれる研究室で「どこまで細かくなるべきか」を身体で覚えさせて貰ったけど、日本の技術者は計算や図面が完璧でも、ドキュメントの日本語になると「てにをは」はおろか酷い誤変換やタイポを放置しまくるような人もいて、こんなことやってると信用を失くすぞと心配になってくる。
文章の粗さは知識の抜けや態度の不安定さと同じくらい他人の信用を損なう問題だということを、少なくとも自分がちゃんとした教育を受けたと証明したいならもうちょっと意識した方が良いよという話。
(※ちなみにこの文章だと、読みなおして「馬鹿」と「バカ」の表記の揺らぎが気になるくらいの躾け方をされた。今回はあえて気づいた上で放置しておくけど。)
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
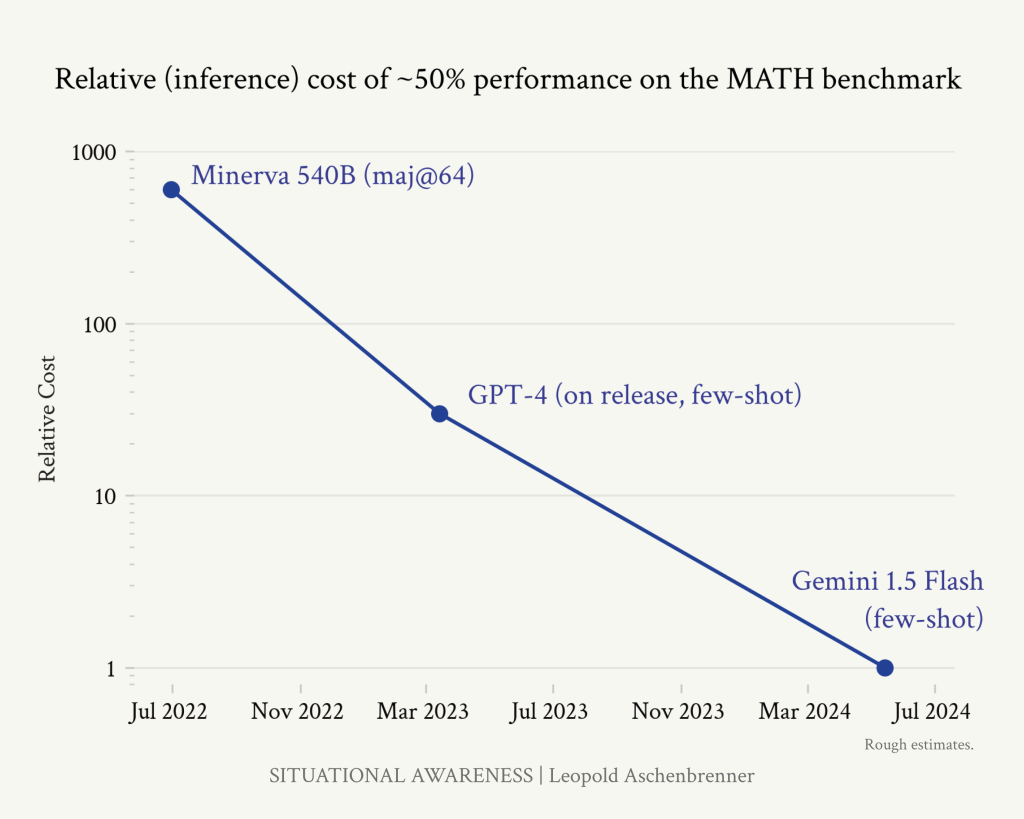
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
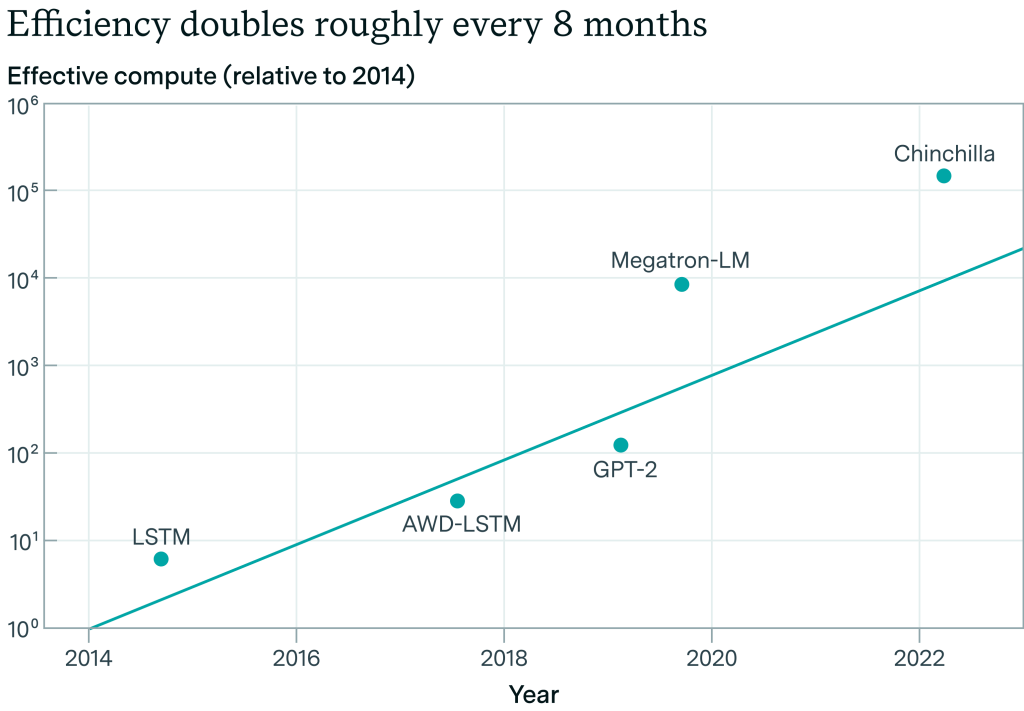
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
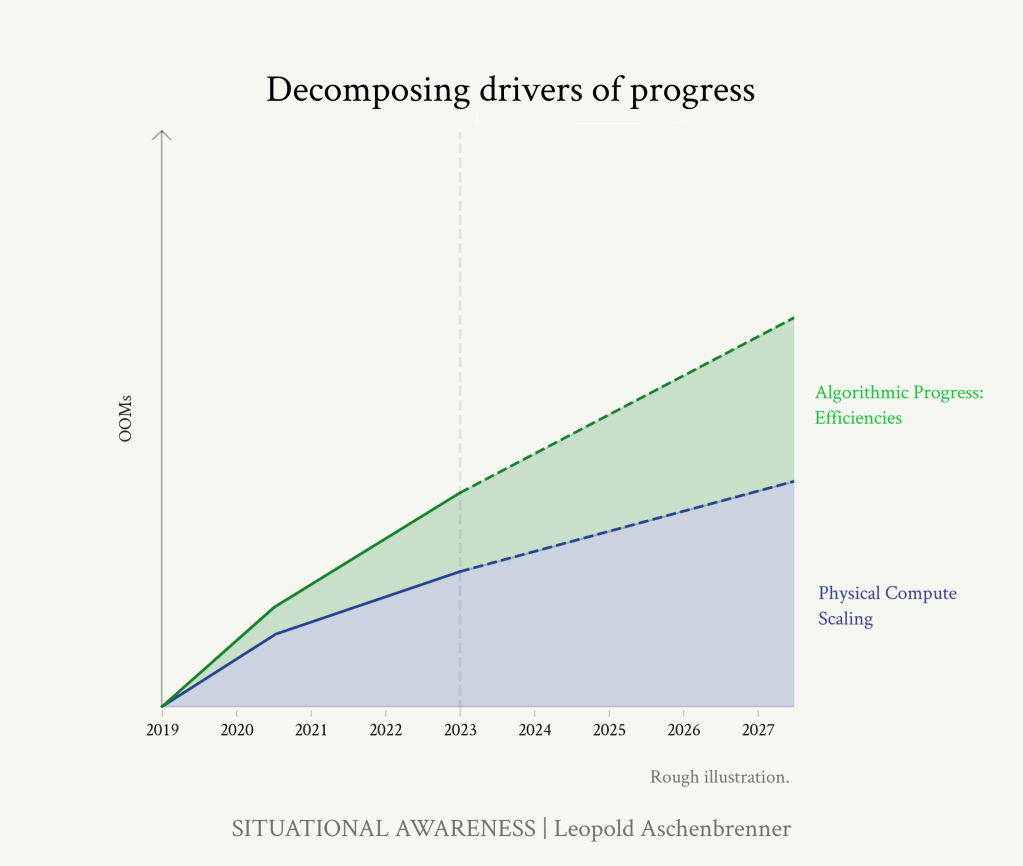
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
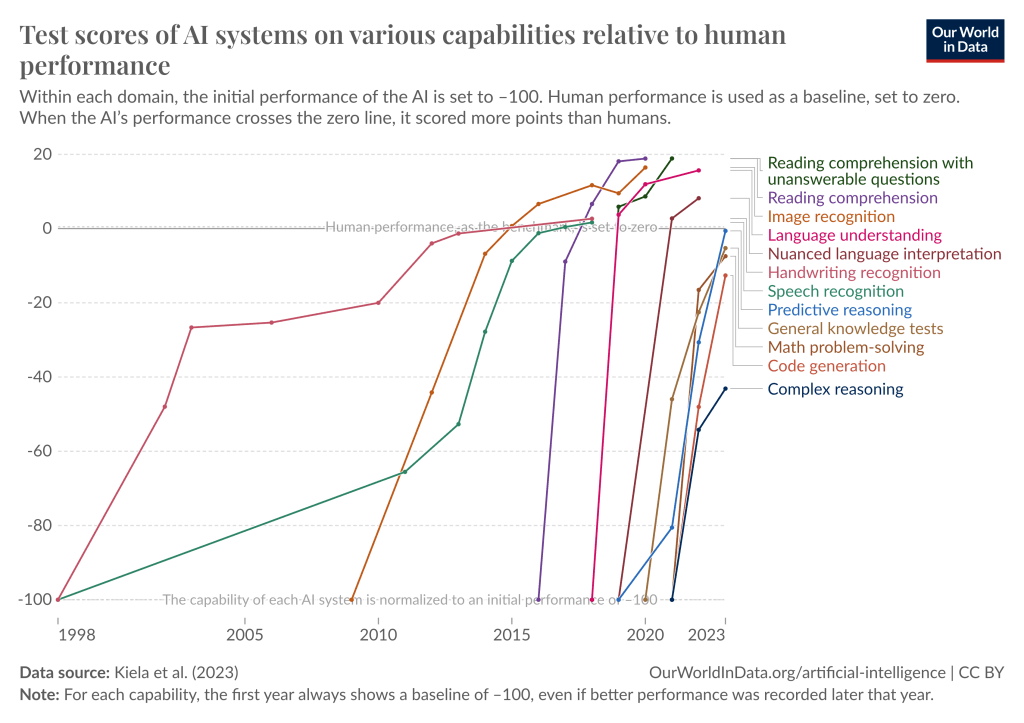
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
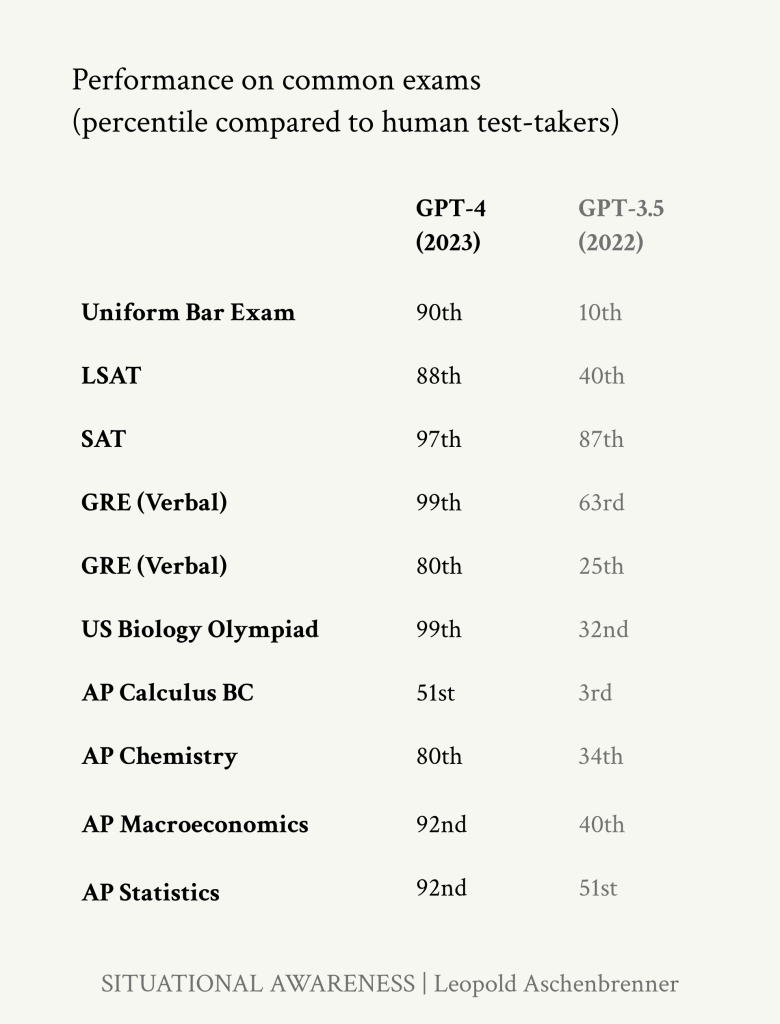
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
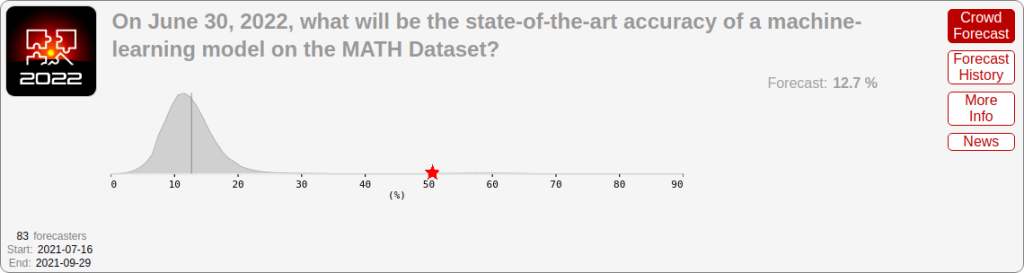
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
学歴どうこうって話聞くたびに思うんだけど
「どこ出てるかはどうでも良くて、書いた論文の本数と質が評価指標」
「大学まで来て論文書いてないヤツは大学に入って出ただけの有料体験版」
というのを東大卒の人が言ってたのを思い出す。
いや東大の人が言ってもなぁ~
エドワード・ウィッテンは、幾何学的なラングランズ・プログラムの一部とアイデアとの関係について「電気・磁気の二重性と幾何学的なラングランズ・プログラム」を執筆した。
ラングランズ プログラムに関する背景: 1967 年、ロバート ラングランズは、当時同研究所の教授だったアンドレ ヴェイユに17ページの手書きの手紙を書き、その中で大統一理論を提案した。それは、数論、代数幾何学、保型形式の理論における一見無関係な概念を関連付ける。読みやすくするためにヴェイユの要望で作成されたこの手紙のタイプされたコピーは、1960 年代後半から 1970 年代にかけて数学者の間で広く流通し、数学者たちは 40 年以上にわたり、ラングランズ プログラムとして総称されるその予想に取り組んできた。
弦理論やゲージ理論の双対性の背景を持つ物理学者は、カプースチンとの幾何学的ラングランズに関する論文を理解できるが、ほとんどの物理学者にとって、このトピックは詳細すぎて興味をそそるものではない。
一方で、数学者にとっては興味深いテーマだが、場の量子論や弦理論の背景には馴染みのない部分が多すぎるため、理解するのは困難(厳密に定式化するのは困難)。
短期的にどのような進歩があれば、数学者にとって幾何学的なラングランズのゲージ理論解釈が利用できるようになるのかを見極めるのは、実際には非常に難しい。
ゲージ理論とホバノフホモロジーが数学者によって認識され評価されるのを見られるだろうか。
弦理論の研究者として取り組んでいる物理理論が数論として興味深いものであることを示す多くのことがわかっている。
ここ数年、4 次元の超対称ゲージ理論とその親戚である 6 次元に取り組んでいる物理学者は、臨界レベルでの共形場理論の役割に関わるいくつかの発見を行っているため、この点を解決する時期が来たのかもしれない。
過去20年間、数学と物理学の相互作用は非常に豊かであり続けただけでなく、その多様性が発展したが、私は恥ずかしいことにほとんど理解できていない。
これは今後も続くだろう、それが続く理由は場の量子論と弦理論がどういうわけか豊かな数学的秘密を持っているからだ。
これらの秘密の一部が表面化すると、物理学者にとってはしばしば驚きとなることがよくある。
なぜなら、超弦理論を物理学として正しく理解していないから。つまり、その背後にある核となる考え方を理解していない。
数学者は場の量子論を完全に理解することができていないため、そこから得られる事柄は驚くべきものである。
したがって、生み出される物理学と数学のアイデアは長い間驚くべきものになるだろう。
1990 年代に、さまざまな弦理論が非摂動双対性によって統合されており、弦理論はある意味で本質的に量子力学的なものであることが明らかになり、より広い視野を得ることができた。
【前提】
・今はKobo Touch利用者、電子書籍リーダーの買い替えを考えている
・KindleとKoboでそれぞれ約10冊ずつ電子書籍を買っている
・それ以外にはPDF(論文やインディーズ漫画小説)を読んでる、というかそっちの方が多い
それで増田たちに聞きたいのは「Koboのカラー端末を買うのとKindleのカラー電子ペーパー端末の発売を待つのとカラー電子ペーパー画面のタブレットを買うのとどれがいいか」
どれかしか使ったことがない人の意見でもいいのでレスしてほしい
【Kindle端末でよさそうと思っている点】・
・単純に書籍の種類が多い
・サブスクが使える、サブスクで試し読みして本気で欲しければ買うということができそう
・Kindle端末なら文章系書籍の本文検索ができるらしい(スマホアプリではできないので未確認)
・PDFの扱いが面倒くさそう
Send to Kindle機能を使わず直接PDFを入れるとまともに読めなくなるらしい
しかしSend to~でスマホアプリにPDFを送ったことがあるけど面倒だし容量の大きいPDFには使えない
・まだカラー端末が出てない、発売までに物欲を抑えられるか、そもそもカラー端末は発売されるのか不明
・PCから直接楽にPDFを送れる、それでも普通にズームとかできる
・色々な電子書籍アプリが使える、無料の漫画アプリとかも入れられる
・多機能
・高額
・意外と扱いが面倒そう
(読書アプリのアニメーションをオフにできないアプリはページめくり後に残像が出ると聞いたことがある、あと色味とかもアプリごとに設定しないといけないらしい)
・ネットブラウジングもできるので読書に集中できなくなりそう、これが一番の懸念点
【Q&A】
・紙の本じゃいけないの?
→紙で読み続けることも選択肢には入れている。ただ本棚に入りきらなくなるのが嫌なのと、電書端末なら分厚い本を何冊でも頑丈な機械に入れられるのが便利すぎる
【19:41追記】
カラー画面の発色の悪さと解像度の低さについては購入者の写真とかを見て承知しているが
どこに何色があるかさえわかればいいと割り切っているのと、Kobo Touchの177dpiの画面でもいけたので大丈夫だとは思ってる
俺は中学受験成功したけど、そこで「俺は地頭がいいからあんま勉強しなくても点が取れる」という成功体験を得て、中学以降の勉強が全然出来なくなったよ
>> 理系なのに数学力が2Bを必死に解いてるぐらいのレベルだったもの。
分子の構造式見ても使われている原子が分かるだけでどういう結合してるのかとかあんま分からんしな。
理系の学士名乗っていいレベルじゃないし、マジで終わってると思う <<
まあそりゃあそうだって話だよな。理系の大学行ったところで、そこで学んだことを活かせる人間がどれだけいるのか?というと少ないでしょ。
ただ、ネットの有象無象から政治家までよく口にする「文系なんか役に立たない」「文系の大学なんて遊んでるだけ」なる言説を見るたびに、「理系」って凄いんだな、学んだことを体得して役立てられているのだな、と感心してもいたのよ。非論理的な言説垂れ流して一部で識者扱いされている吉本芸人も工業高校出たというだけで理系面しているようだけど、その程度の人間にも理系学問を役立たせられるようにできる理系教育のノウハウは素晴らしいなと思っていたわけよ。自分は受験で数IIIc使ったし危険物と消防設備士の資格持ってて多少は物理化学も勉強したけど文系学部出なこともあってそんな胸張って役立てられると言える自信が無いので引け目を感じてもいたのよ。
友人に数学者とか情報工学者とか医者とか、学んだことを役立てられている連中がいるので、ちょっと勘違いしていたところもある。まあ彼らは「文系なんか役に立たない」なんて頭の悪いことは考えもしないわけだが。
一方でそんな頭の悪い言説にいちいち突っかかってる自分は勿論頭が悪いのだけど、ただやはり文系軽視って危険だと思うんだよね。
先にネットの有象無象と政治家を並置したけど、前者はまあどうでもいいが後者がそれを言うのは本当に危険。だって文系学問とは平たく言えば自然科学以外の社会科学と人文科学を指すと思うのだけど、それってつまり社会に生きる人間を扱う学問なわけでしょ?行政がそれを無視してどうすんねん。とりわけ社会学を敵視している人々を眺めると、公的扶助への憎悪が根底にあると思えてならない。
あるいは福祉大嫌い子ちゃんたちにも聞く耳持ってもらえるんじゃないかなと思う根拠を挙げると、ノーベル経済学者がその金融工学の理論を実践したヘッジファンドが「標準偏差10個分の大異変」が起きたせいで破綻した件なんか良いでしょうね。経済はアニマルスピリットが働くので自然科学的手法だけだと大火傷しますよ。
勿論文系教育にも色々と問題があるけど、文系蔑視って極めて近視眼的だと思うし、そのくせ自称理系連中も案外大したことなかったり(繰り返すけど本当に頭のいい人、まさに理系の上澄みと言える人はそもそもそんな程度の低い対立には関わらないと思う)するので、どっちも尊重して学んでいければいいなと思います。
舟渡2丁目には結論から言って一戸建てが並んでいる。視認できる、技術的に構成されたものといえば、それと車である。これをまたお前の価値観で言っても、それが食べられるかというときに
あらゆる角度からみても、家というものが残っていてそれが見えるだけで中に何が住んでいるのか分からない。それだけここの住人は外に出てくるということがない。その、外出しないということについて、
なんで外出しないのか、というときに、自分が社会的に摂取できない、食べられるようなものではなく恥ずかしいから出て来ない、というのは飽くまで警察の、昔からある、他に手の取りようがないから
仕方がなくそう考えているといった、くだらない建前というものであろう。私ははっきりいってここを5年前からみているが、家があることしか見たことがなく、何が住んでいるのかということを見たことがない。
またこの辺に、自分は摂取できるようなものではない、社会的に食べられるようなものではなく恥ずかしいから世間体があるから出て来ないのだという通念がここにあるとは思えない。
更に東京や埼玉にはそういう通念があるようなところではないので、この辺に住んでいる人間の何を考えているのか分からないこと甚だしいものがある。車の番号では、ひたすら、 ちっ、などと言い、
そういう人間が他人に食べさせるなどということを考えているとは思えない、その意味でも、こいつらに、自分は摂取できるようなものではない、世間様、他人様に害を及ぼす存在だから我慢しているのだ
といったような考えがあるとは思えない。そんな善良な考えをしている者が、ちっ、などと舌打ちをするはずがないからである。確かに、令和3年の東京大学の現代文の問題は、 食べる話、江戸の妖怪
といった論文が出ている。そのように、東京大学が、食べることと、今の東京を江戸であって、そこに妖怪が出ると考えているのではないかということが理解できる。
・そうはいっても政治家の職業世襲が文化資本だったら人的流動性がないので、フランスの論文が日本にも当てはまるかというと疑問
・むしろ文化維持に関わる集団が文化資本なのではないだろうか。フランスのカトリック文化と比するなら「相撲部屋」「相撲協会」とか「芸術・芸能学校」とか「●●医師会」「東大」「日本キリスト教団」とか
・文化資本の移植は、英国ダドリー男爵家が米国でハーバード大作ったり、在日ハーバードの米国ユニテリアン教会が朝鮮で布教したようなもの(日本は戦争負けたが彼らは成功している)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}