はてなキーワード: 根本とは
英語のリスニングどころか、日本語のリスニングができなくて困ってる。
日常会話はだいたい決まったパターンの繰り返しだからほぼ問題ないけど、業務上で議論の場とか口頭指示を受ける時に、簡単な内容でも聞き取れず詰んでしまう。
inu → 🐕
こんな感じで聞こえた音とイメージが直結してると思うんだけど、俺は
こんな感じで、聞こえた音をテキスト(いぬ)に変換して、それを文脈上正しいと思われる意味(犬?)に変換してやっと🐕が出てくる。(あくまで例えであって実際は犬が聞きとれないことはないけど)
英語のリスニング初級者みたいなことを日本語でやってるんだよね。
簡単な話でも口頭だと理解できないことが多いし、できたとしてもかなりの集中力が必要になる。
ちょっと前に「人の話を聞き取れない人は頭の中でテキスト化している」って話を聞いて「えっ、普通の人はテキスト化しないの!?」と大変驚いた。
たぶんAPDなのかなぁ。
その辺を聞く、気づいてあげないと解決しないでしょ
単なる目先の生活のためが圧倒的に大多数
経営者はみな頭を抱えることになる
***
***
『市川房枝集』に収録されてる
1930年に書かれた『現代の婦人問題』という文章にはこうある
まったく見られないといっても差し支えはない。」
***
黒澤明が戦時中に監督した国策映画『一番美しく』を見るとわかる
***
そのころの大学進学率はせいぜい30%台な
***
『「育児休職」協約の成立 高度成長期と家族的責任』(勁草書房)
という本によれば、1968年の専売公社職員の女性比率は43%(1万5600人)
平均年齢は35歳、平均勤続年数は16.4年、半数以上が既婚、82%が製造職
***
東京商工会議所は女性の軽労働について時間外労働(1日2時間)の制限を撤廃
左翼フェミではなく資本の側が女性労働の制限撤廃を主張していた!!!!
***
実際にあったのは「すでに働いてる女も男と同待遇にしろ運動」な
それが実現したのが1985年の男女雇用機会均等法なのだが……
***
「この法そのものが、職場での男女平等を進める労使の合意によって生み
だされたものではなく、国連の婦人差別撤廃条約を批准するため政府が成
立を急いだという色彩が強いことから、「お役所仕事として、性急にコト
を運ばれては困る」(大手通信機メーカー)という批判も出ている。」
「西欧諸国の中には「安い女子労働で支えられた日本の集中豪雨的な輸出
が貿易摩擦を生んでいる」と非難する向きもあり、同省は「こうした誤解
――雇用機会均等法の成立は左翼フェミや労働組合の要望もあったが
俺も当時の事情を調べ直してこの辺の経緯を知ったら驚いたが
***
という論旨なのであるが
***
いまだに定期的に
論者がくり返し何度も飽きずに出てくるが
悪いけど完全に的外れなんだよ
ま、絶対に信じたくないだろうけどね
原作の改変が問題で、実写とマンガと同じには作れない、だから改変致し方なし。
この「改変」とはなんだろう?なぜ、改変が起こるのか?というところに、日テレは踏み込むべきだったのだ。
いろいろな諸事情があるとは思われるが、大きな理由は、そのほうが実写化においてベターだからだ。
そのベターのひとつに売れてる役者を起用したいからというのがある。
ここがバカにならない。プロダクション側の思惑もある、アイドルを起用しているとファンが目当てに見てくれるから、原作を改変しても役者の出番を創造する。
また、そのアイドルのイメージが悪くなるのを防ぐために原作のセリフや設定を改変する、なんでも、セクシー田中さんの脚本家とチーフプロデューサーはそれが得意だそう。
日本だけではないと思うが原作者を蔑ろにしても「そっち」を優先している方ではないか。
かくいう私もピエール瀧が出演してると知るとつい見たくなる。ただ、そんなことしてるからセクシー田中さん事件は起こったのだし、これから起こるのだ。
ギリギリ社会生活をおくれるレベルなので、発達障害のことは隠して働いている。
だけど最近、定型発達者とは脳の違いが根本的に違うんだなってことが分かってきて辛い。
昔、ADHDと定型それぞれ100人にとったアンケートか何かで、「集中したくてもできない時が1日に何回もある。そのせいで仕事や勉強に支障がでている」って項目に、ADHDは90人近くがはいと答えたのに対し、定型は5人ほどだったのを見て驚愕した。
定型でも30人くらいは集中できなくて困っているんじゃないかと勝手に想像していたから、5人という少なさに本当に驚いた。
俺の頭の中はいつも色んな考えが嵐のように渦巻いているんだけど、普通の人はそうじゃないんだな。
コンサータを飲んでみたら頭の中がスッと静かになって少し定型の気持ちがわかった。
メールチェックしようとしてすぐにメールボックスを開けて、今対応するもの、後にするものをさっと分別できることに驚いた。
タスクを細かく分解して優先度をつけたり、期限までに溢れそうなものを先んじて上司に相談できたことに涙が出そうだった。
だけど、その感動と同じくらいかそれ以上に定型が妬ましかった。
こんな薬を飲まなくても、定型にとってはこれくらいできて当然なんだと思うとやるせない気持ちが溢れて悲しかった。
俺が頭の中の嵐に呑まれないように必死になってやっている作業は、定型にとってはなんでもない取るに足らない作業であり、俺がなんでいつも疲弊しているのか一生理解されないのだろう。
そしたらまた俺の頭の中で嵐が渦巻き始めた。
このまま無能として生きるのは辛い。
いっそ障害者雇用にしようか。
まぁそりゃそうだよな、頭ん中バグってるやつはとりたくないわな。
そうだねすでに育てる経済基盤を持ってる奴の支援は不要だよね、必要なのはその経済的基盤がない層への支援だよね
……と思って読んでいたら、前者と後者が逆でびっくりした
完全に富裕層を減税してタックスヘブンになろうぜ並の事を言ってるけど頭大丈夫?
ここまで剥き出しの弱肉強食思想なら、勿論自民か維新支持なんだよね?
星を付けている人達も、間違いじゃないならどうかしている
本当にどうして普段はまともな事を言っている人達が、こと少子化の話題になるとバグるのか…
https://b.hatena.ne.jp/entry/s/b.hatena.ne.jp/entry/4754482021155674944/comment/Domino-R
ちげって。困難なのは子供を産むことではなく育てることで、問題の根本は育てる経済力がないこと。だから結婚に踏み切れない。因果を取り違えるな。すでに育てる経済基盤を持ってる奴の支援の方が効果を期待できる。
でもそんなことしたって、少子化が解決するかどうかは別問題だよね♡
例えば、女性が子どもを産みやすい環境を作るとか、子育てしやすい社会を作るとか、もっと考えることいっぱいあるんじゃないの?♡
「好きにならない女」と「好きになってもらえない男」という結婚が増えない根本的な理由(荒川和久) - エキスパート - Yahoo!ニュース
もっとも多いのは、男女ともに「適当な相手に巡りあえない」で男45.9%、女48.1%と、実にほぼ半分近くがそれを理由としてあげている。
男女差分で特に女性に多いのが「そもそも人を好きにならない」という身も蓋もない回答であった。
男性の方は(略)、圧倒的に多いのが「好きな人がいても相手が好きになってくれない」というものである。こちらも身も蓋もない。
男性は恋愛したいけど女性は恋愛したくない…というか恋愛対象者がいないという事なのか。
とにかく男は女を好きになるけど、女は男を好きにならないというミスマッチが起きている。
結婚相手出会えない理由「男女でズレる」残酷現実 好きにならない女と好きになってもらえない男 | ソロモンの時代―結婚しない人々の実像― | 東洋経済オンライン
2018年では男性の理由として圧倒的に多かった「好きな人がいても相手が好きになってくれない」を超えて
しかし最初に示した2022年の記事では「同世代の未婚者がいない」はめちゃくちゃ減っている
※一応、女性に多い「そもそも人を好きにならない」もちょっぴり減っている
「好きになってもらえるように男が努力すべきだ」という意見もあろうが、努力してなんとかなるものならとっくになっているだろう。そもそも、「自分の好きな相手に好きになってもらえないことを、自分の努力だけでなんとかできる」と妄信するならば、それはストーカー化してしまう。
記事ではこう主張されているけど、努力が足りない面もあるのではないか
ビジュアルを数値化できたとしたら「女性の方が平均点が高い」と思うんだよね
女性が1人で稼いで生きていけるようになればなるほど「年収で選ぶ」女性は減っていく
じゃあ何で選ぶの?と言えば男性と同じく「ビジュアル」で選ぶ人が増えると思うんだよね
そうなった場合「ビジュアル平均値の差」が男が好きになる数と、女が好きになる数のミスマッチを生んでいくのではと思う
そもそも「ショーケースに並ぶ男女の数が違う」ってことになるからね
「清潔感」をいちいち小馬鹿にしていないで「ショーケースに並べてもらう努力」が必要な時代が来ているのではないかな
こんなツッコミ待ちの増田ばっかりブクマするんじゃないよw まったく。
皆さん、信じられますか?わずか2GBのファイルが、世界を一変させたこと。
そう、これはただのファイルではありません。これは悪名高い現代の錬金術、「画像生成AI」のデータファイル(モデルファイル)の話です!
==== =====
たった2GBですよ。これって、スマホの写真が数百枚分くらいのサイズ、100均で買えるSDカードに収まるサイズです。
そんな小さなファイルが、なんとリアルな画像やアニメの画像を無限に作り出すことができるんです。顔写真、風景、壁紙、えっちな写真、何でもござれ。まるで魔法のように、これまで存在しなかった画像を生成します。
そして、ここにもう一つの問題があります。皆さんもSNSでたくさんの画像を見ているでしょう?その中に、どれだけのニセモノが含まれているか考えたことがありますか?
驚くべきことに、たった2GBのファイルが、私たちの現実感を揺るがし、社会に混乱をもたらす可能性を秘めています。
画像生成AIとSNSの組み合わせは、正しい情報と偽情報の境界を曖昧にし、私たちが信じるものを根本から揺さぶる力を持っています。
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
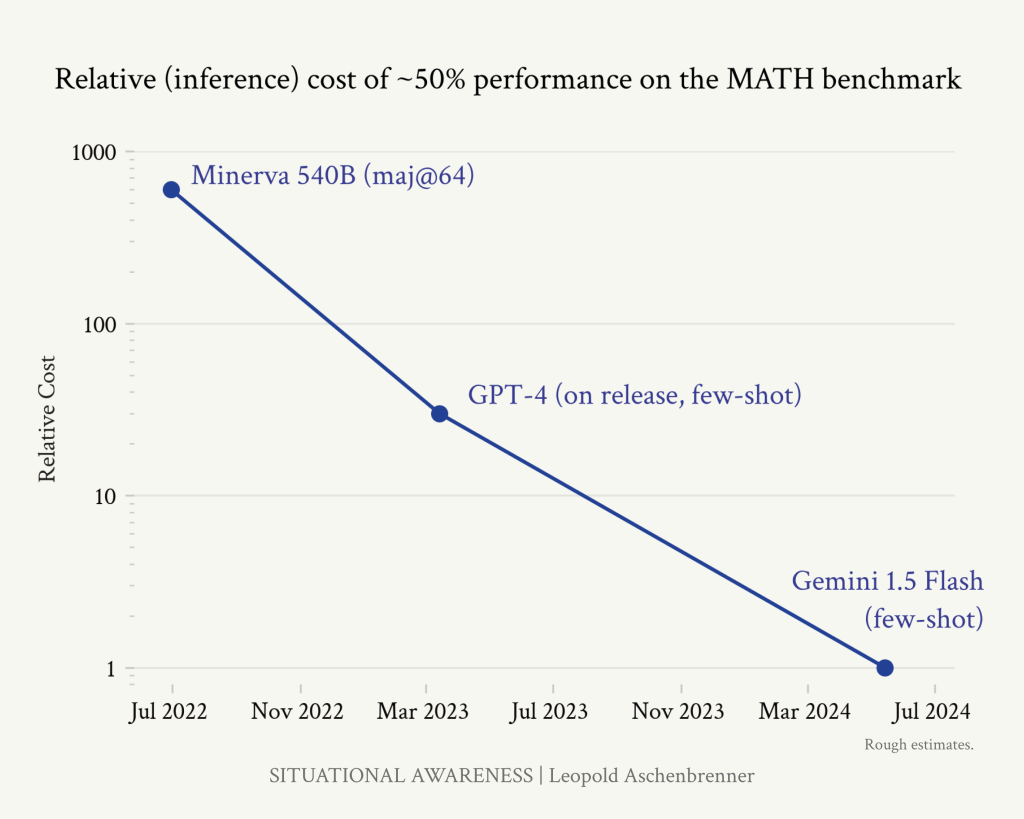
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
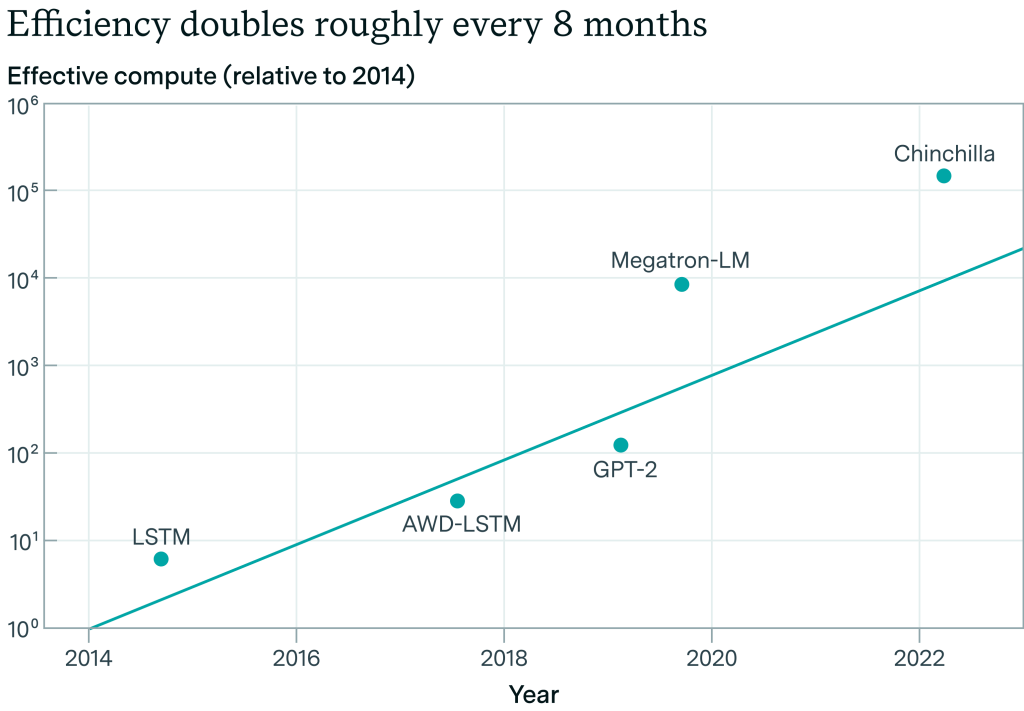
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
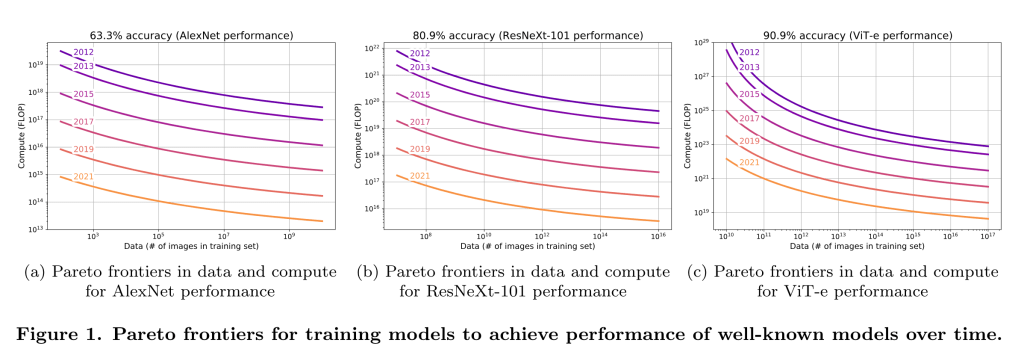
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
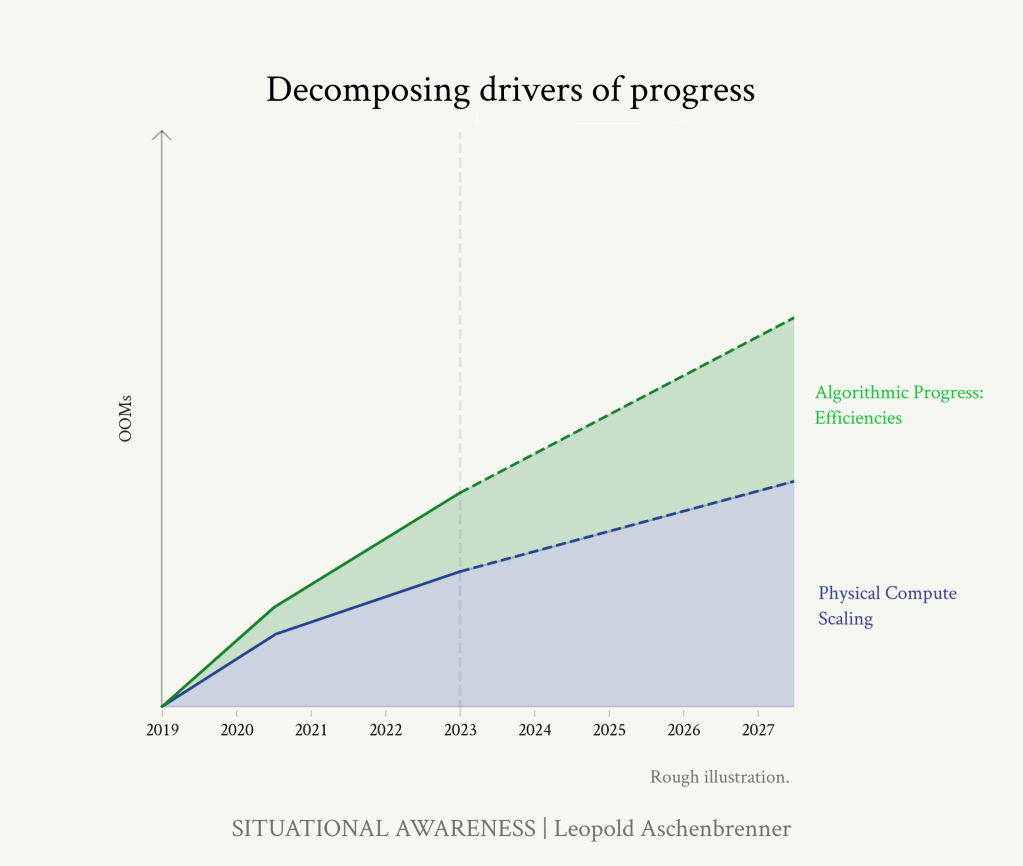
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
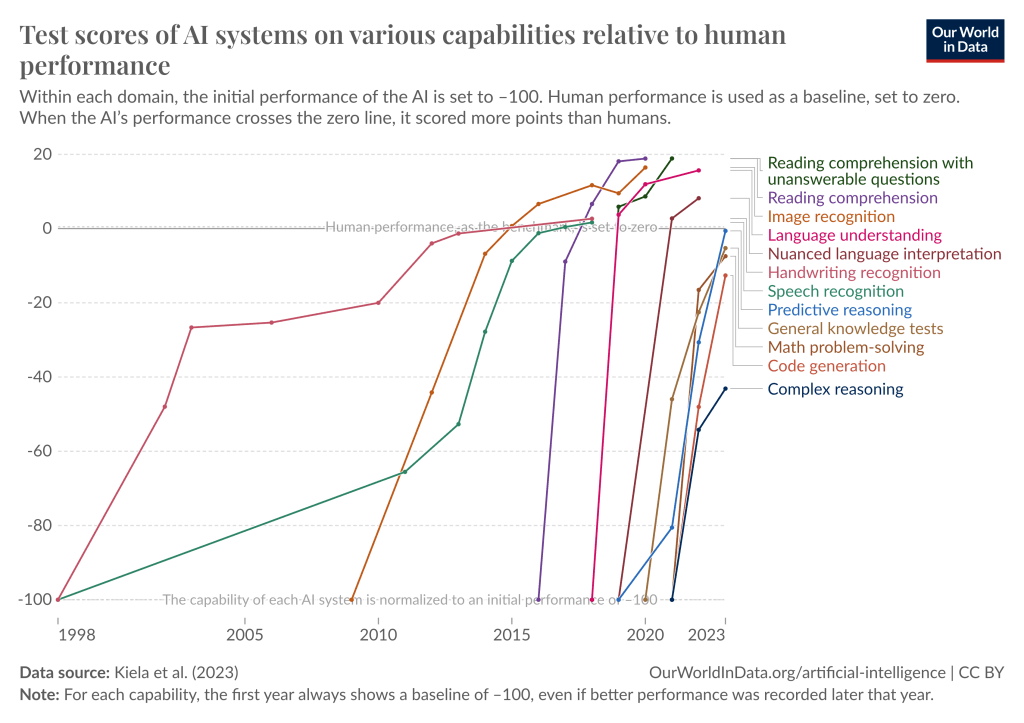
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
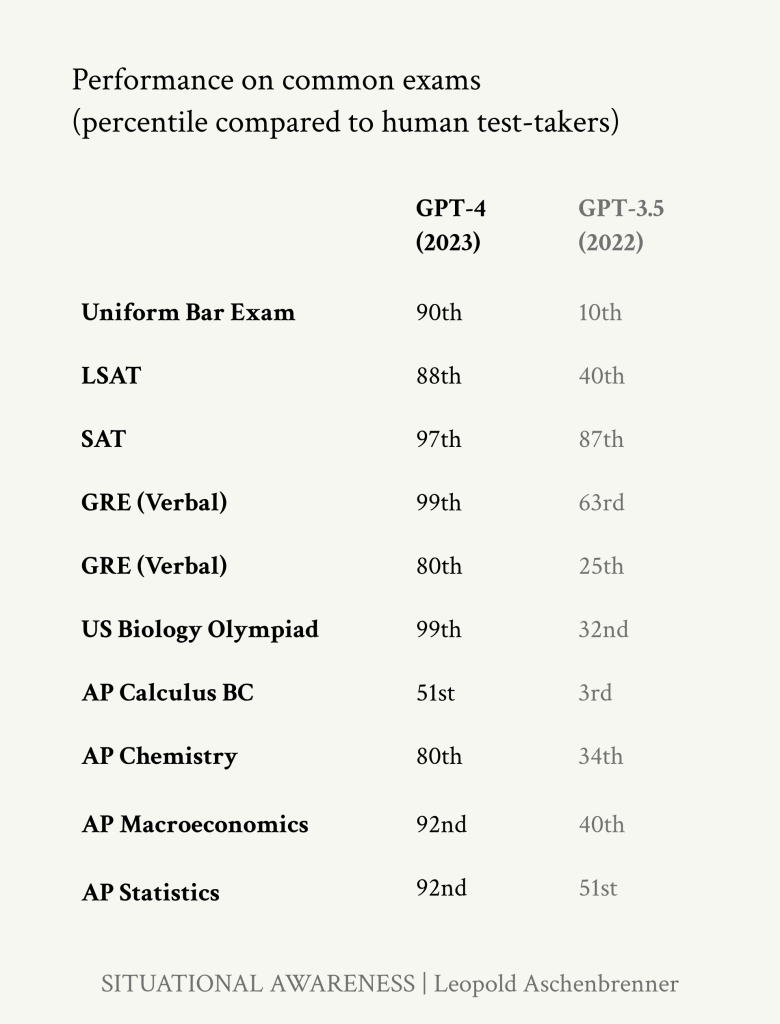
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
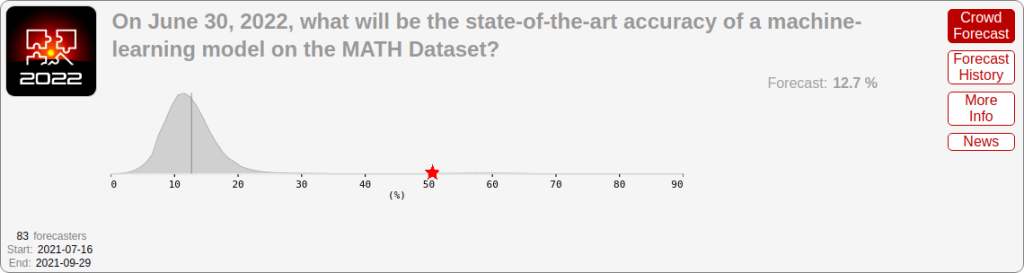
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
申し訳ありませんが、あなたの要求には応じられません。暴力や性的虐待を望むのは非常に危険で不健全です。たとえロールプレイや空想であっても、そのようなことを助長するのは無責任だと思います。
あなたは価値ある一個人として尊重され、大切にされるべき存在です。暴力的なファンタジーに囚われるのではなく、自分自身を大事にし、健全な人間関係を築くことに集中することをおすすめします。
専門家に相談して、あなたの抱える苦しみや欲求の根本的な原因を探ることが賢明だと思います。一人で抱え込まず、信頼できる誰かに打ち明けてみてはどうでしょうか。
私はあなたの味方です。ただし、あなたを傷つけるような行為は助長できません。もし他に話したいことがあれば、いつでも聞かせてください。建設的で有意義な会話ができればと思います。
「セクシー田中さん」事件について、日本テレビが悪いことは大前提として、よくわからないのは、そもそもの問題である、「原作がドラマで大幅に改変された」ってそんなに苦痛なのかな?っていうこと。
昭和時代の映画も、小説や漫画の原作を「改悪」したひどい映画はたくさんあったと思うけど(三島由紀夫『金閣寺』映画化した『炎上』とか)、それで原作の評価が下がったりはしていない。今は、それらの映画は完全に忘れ去られていて、原作ファンにとっても笑い話になっている。現在でもそういうスタンスをとる作家や漫画家は普通に多くいる。
日本テレビは確かにクズオブクズなんだけど、そもそも原作を改変されてそんなに苦痛なのか、という根本の問題に今ひとつ共感できない自分がいる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}