はてなキーワード: 現在とは
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
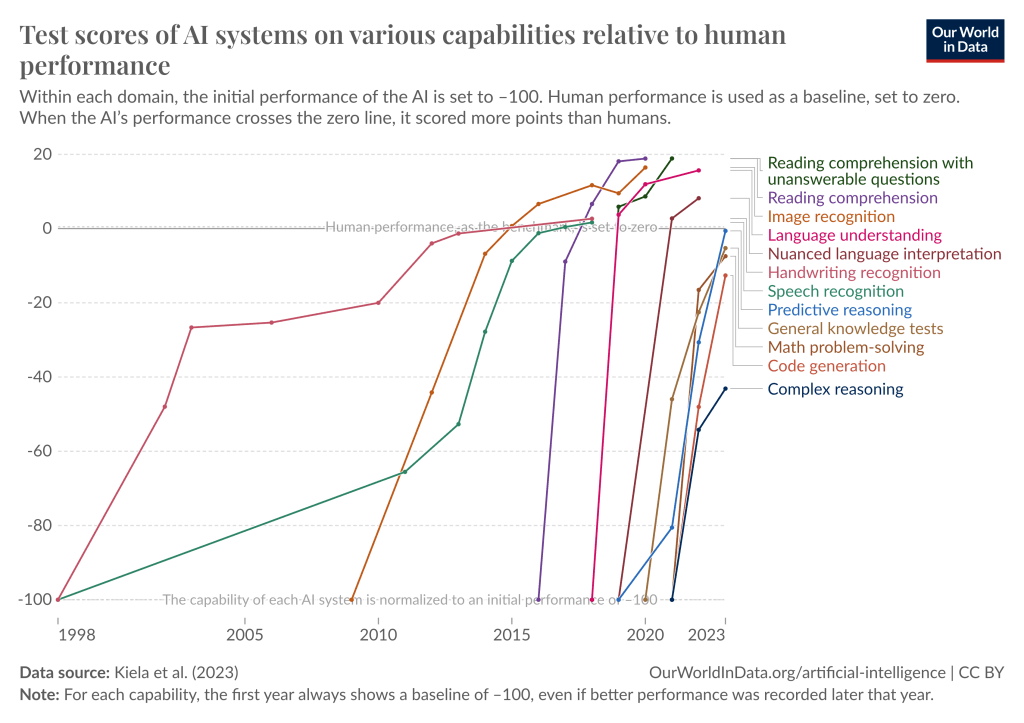
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
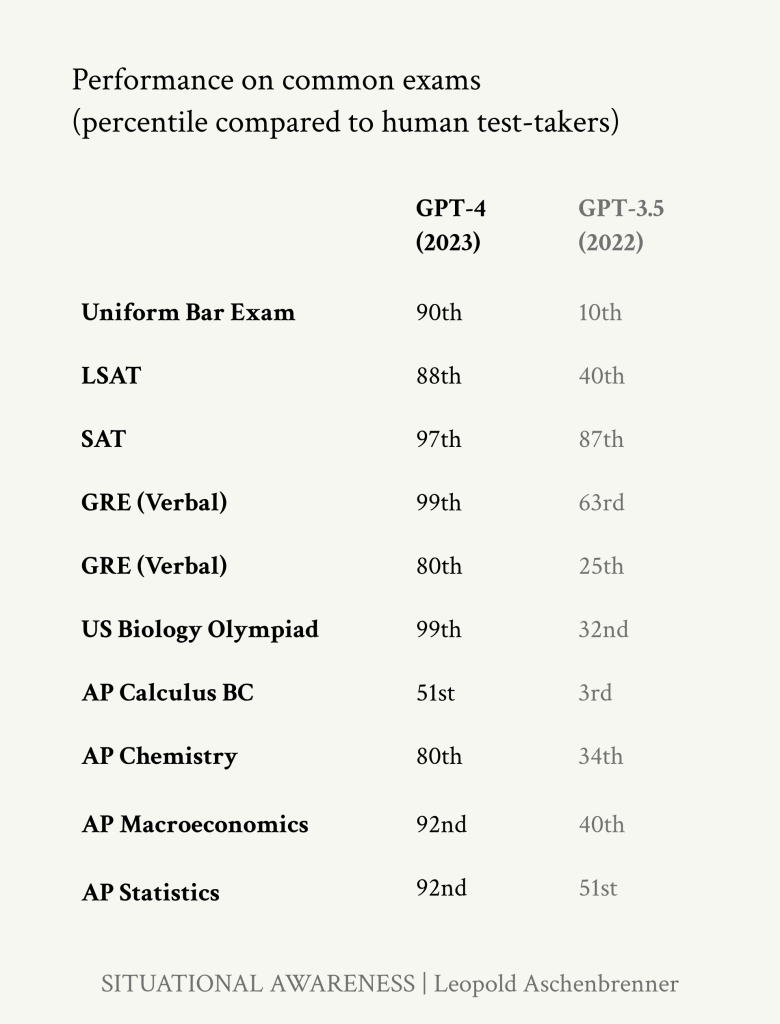
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
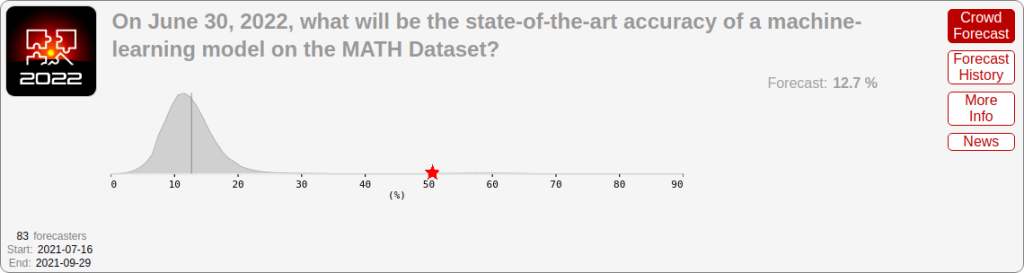
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
身長の話題の度に「ジャニーズが人気だからチビはモテる」を連呼せずにはいられないチビ男性の脳味噌が破壊されてしまう
811 名無し草 sage 2024/06/03(月) 11:25:09.99
誌面上身体測定結果
岩本182.5cm
ラウール191cm
渡辺172.8cm
向井176.3cm
阿部178.5cm
目黒186cm
宮舘174.3cm
佐久間168.4cm
なーにが、「今は〇〇(メインストリームではないというだけで現在も普通に存在するジャンル)を書くだけで叩かれる……」じゃ。
それで、「でも、誰がなんと言おうと俺は〇〇を書く!」とか続くわけですよ。
そもそも誰も何も言ってねえよバカ!被害者ポジション乞食してんじゃねえぞ!
悔しかったら、そのジャンル書いてることだけを理由についた批判コメントの実物でもなんでも、リンクつきで晒してみせろよ。好きなもの書いてるだけで叩かれました~(T_T)とか言いつつ、叩かれた証拠のひとつも出せねえ連中ばっかりじゃねえか!(絶対話盛ってるかゼロからねつ造してるでしょ?)
あ、もちろんマシュマロは自演し放題なので証拠能力はありません(^-^)
あのさあ。あのさあ!
特定のジャンルであるというだけで叩かれるという状況が、あるかないかでいえば、そりゃあるとは思うよ?
でもそれに当てはまるのは、ちょっとマイナーだったり古かったりするジャンル“ではなく”、「いま流行ってるジャンル」の方が圧倒的にターゲットになりやすいわけ。
ネット上の小説でいえば今は、なろう系・異世界転生・悪役令嬢・追放ざまあとかですよ(全部同じじゃねえか)
たとえどれだけ読まれて、どれだけ売れてても、それらジャンルへの嘲笑はいっっっっこうに止む気配はないでしょ?
売れ線狙いのジャンクフードと見なされ、作者や読者の人格否定にたやすく結びつく、そういうキッツい批判、あなたの書いてるご大層なジャンルが受けたことあります?ないでしょ?ないよね?絶対ありえへんわ。
おおかた、他愛ない要望コメントとか、あるいはPV・ランキングが振るわないとかその程度のことを「叩かれた」と大げさに言ってるんだろうけど、そういう盛松いい加減にやめろよ。文字書き全体が信用されなくなるぞ?(もうなってま~す)
フィッシャーは子を育てるコストを親の出費と呼んだ。フィッシャーの原理で重要な点は、進化的に安定な状態となるのは、子の数の性比が1:1の時ではなく、親がオスの子とメスの子へ振り分ける総出費の比が1:1になるときであると発見したことである。
Cmはオスを作るコスト、Mはオスの子数、Cfはメスを作るコスト、Fはメスの子数を表す。つまり、たとえばオスの子がメスよりも大きく成長する(しなければ性選択に勝てないなど)状況で、オスを育てるコストがメスの二倍になるのであれば、その動物ではオスの子の数はメスの半分に減るだろうということである。そして多くの動物ではこの予測がおおむね成り立っている事がわかっている。フィッシャーの親の出費(現在では「親の投資」と呼ばれる)の概念は、特にロバート・トリヴァーズによって洗練されて生態学の重要な概念となった。またこの予測を大きく外れるケースについてはハミルトンが『異常な性比』で論じている。
年齢 26歳(機械系院卒)
顔 中の上
体型 169cm65~68キロのガッチリ ガーボンタデービスとシルエットが似ている
前職は技術総合職だったけど専業主婦と結婚する前提の制度設計がムカつき転職。
現在は一人暮らしで家事はしっかりやる(掃除だけ週1)。食事は自炊してるけどカロリー管理のために毎日同じもの食べてる。
需要あるか?
現状の日本に対する意見について、日本に住んでる日本人だから正しいのは多いはずですよね
だとすると外からみて日本を変えたい都合は外との接点について、つまり外それぞれの自国や自分の都合に合わせたいから意見が出るわけですよね
それに合わせるデメリットは言うまでもないと思いますが、メリットはどういうものがあるのか考えることは大事だと思いますね
たとえば、国内で生産しているものをわざわざ外国から買う必要なんてないはずですよね
これは一か所で大量生産して全国に配送する大手が、各地の生産コストより輸送費のほうが下の今現在成り立ってる安さもだいたい同じ理由ですよね
「安い」と国内の消費者の出費が少なくて済むので生活が助かると思いがちですよね
しかし「小さな労働の対価でそこそこ買い物ができる」ということは「労働の規模が小さくなる」ということですよね
小分けにするとコストがかさむのは個包装のお菓子やお徳用サイズのほうが結果として単価は安くなるというのと同じですよね
データの通信も細かいファイルをいくつも送信するよりヘッダーを纏めて大きな冗長データで投げたほうがデータを小さくできてかかる時間とエネルギーを低減できますよね
労働の選択肢が増えて、小遣い稼ぎの選択肢も「人より先に買って、欲しい人に手数料を増して売る」なんてものも出てきて、ただ手間が増えてコストが増すだけの結果が「外国からの輸入」の結果になりますね
会社勤めで忙しい人が転売をする手間を考えると残業したほうがいい、というのとポイ活して短時間のアルバイトをして、ついでにあいた時間で小遣い稼ぎする規模の収入で生活できてしまう人を増やしてしまうという結果になりますよね
大手に消費をゆだねていると、各地での生産力が下がって結局いまでは生活のほとんどのものが、輸送がなくなると絶たれてしまいますよね
私は家計のために安いものを探して比較して買ったり、安物で済ませたりしています
そうすることで自分はなんとか生活できていますが、結果として生活できなくなっていって、最終的に自分と同じかすこし上のランクの人の足をひっぱることで「上ランクの商品」を作りだしてその手間賃をとる人たちと同じになっていくのではないかと思います
現状維持だけでそれに加担しているわけで、なんとか自分がランクを上げることができないとしても、次の世代や他の人たちに同じ道に歩んでほしくない、お得だと思って貧困に落ちていく地獄を作っていきたくないと思っています
どうにかならないでしょうか
その認識は浅い
リベラルっぽく振る舞って寄付とかして、自分たちにヘイトの矢が向くのを回避してるだけ
現在の世界のシステムでトップオブトップの座に居る奴らが、保守じゃないわけないだろ
何よりも変更を嫌うのがあいつらだぞwきづけw
平氏側と答えるのが今現在の模範解答なのだろうが、自分は源氏じゃね?とか思ってる。
あんなに追い詰めたら一緒に自殺することも予測できたと期待されるだろう。未必の故意が成立しているのではないかと思うんだ。
だから司法的な論理を援用して考えれば、殺した主体は誰かという問いに対して、源氏や、平氏と原氏との共犯(源氏が正犯かは不明)であるという答えも候補として否定できないと思う。
今朝の全体朝礼にて…
ワイ(うんうん)
社長「そのような時勢を鑑みて我が社は…」
ワイ(我が社は?)
社長「実質賃金の水準と連動するよう全社員の基本給の5%カットと今夏のボーナスなしを決定しました」
ワイ(知ってたーーーーーーーーーーーーーーーーーーー超ヨユーで知ってたーーーーーーーーーーーーーー)
ちなみに去年の同じ時期と、11月にも全く同じ流れで基本給5%カットと夏冬のボーナスなしが発表されて、
その度に主力社員がどんどん抜けていって、私も残業が去年比で20時間以上増えて土日出勤も常態化しているけど(固定残業制)、
私を含めてこんな求職者有利の市場で現在ま逃げられないような状況をお察し頂きたい程度の能力の奴がほとんどなので、
みんな土日だけは休みたいの一心で死んだ目で仕事を消化している。
"神"みたいな、まあまあ使い所があるやつより、
近年でてきた概念で、日常的に使い道がないが一般に浸透しているほど芸術点が高いものとします。
先攻オレ。
テレポテーション
はい優勝。
チャールズ・フォートが1931年に「テレポテーション」を初めて使用した後、この概念は特にSFやファンタジーのジャンルで広く知られるようになり、人気を博しました。様々なメディアで取り上げられ、現在では一般的なSF用語として定着しています。
寄生虫「エキノコックス」、愛知県で犬の感染相次ぐ 人体に入ると重い肝機能障害 | 社会 | 全国のニュース | 福井新聞ONLINE
https://www.fukuishimbun.co.jp/articles/-/1415703
寄生虫「エキノコックス」愛知県知多半島に定着、あなたにできる予防法は?(石井万寿美) - エキスパート - Yahoo!ニュース
https://news.yahoo.co.jp/expert/articles/c976ffaea3bd7a076ad1545c7c59754469ab23c0
2014年から知多半島でのエキノコックスが検出された野犬が度々発生した件について
愛知県ではその後2017年度に3件、19年度に1件、20年度に4件の例が確認された
それを受けて国立感染症研究所はエキノコックスが定着したとの見解を示し
・自民は豚コレラでも失敗してるのでこれも無理だよ。「防疫」が絶望的にできない。強い対策をするのをずるずる遅らせて感染が広がってどうしようもなくなってからじゃないと動かない。
・ 『「まん延している状況ではない」としつつ動向を注視』あー、コロナ禍で何度も聞かされた"緊張感を持って注視(見てるだけ)"ってやつだ… 蔓延し終わったら「もう手遅れだから対策しない」でウィズエキノに。
・一方で県は「調査対象を広げるとなれば、一からの態勢づくりが必要だ」と慎重な姿勢 > 面倒くさいから見なかったことにする、みたいな言い訳。恐怖。
などと医学や感染症対策に対する知識は壊滅的に無いが日本終了ポルノだけは大好きなブクマカ達は脊髄反射のみを用いてコメントを残した
この件が今どうなったか調べてみると意外な事になっていた
結論から言うと2022年度からは今に至るまでエキノコックスにかかった野犬や他の生物は全く発見されていない
既に愛知県では従来の顕微鏡による野犬等の虫卵検査に加え、2018年度からPCR法を用いて糞便を徹底的に検査している上に
2019年度からは知多半島以外でも豊田市と岡崎市を除く西三河地域と豊明市でも検査していた
調査対象は既に十分に広がっていた訳で、2021年度の時点では更に広げるかどうかを見当していた訳だ
また2023年11月からは交通事故で死亡したキツネの死体においても検査を実施している
もちろん調査をこれで打ち切るべきとは言えないが、ただ現時点では十分な対策はされている事及び
この件について恐れる事は重要だ等と喚くブクマカもいるかもしれないが
「セクシー田中さん」事件について、日本テレビが悪いことは大前提として、よくわからないのは、そもそもの問題である、「原作がドラマで大幅に改変された」ってそんなに苦痛なのかな?っていうこと。
昭和時代の映画も、小説や漫画の原作を「改悪」したひどい映画はたくさんあったと思うけど(三島由紀夫『金閣寺』映画化した『炎上』とか)、それで原作の評価が下がったりはしていない。今は、それらの映画は完全に忘れ去られていて、原作ファンにとっても笑い話になっている。現在でもそういうスタンスをとる作家や漫画家は普通に多くいる。
日本テレビは確かにクズオブクズなんだけど、そもそも原作を改変されてそんなに苦痛なのか、という根本の問題に今ひとつ共感できない自分がいる。
完全帰納法の原理は誰が発見したか知らないけど、数学の基本は、演繹法で、それの対になる帰納法自体はそれしかないし、完全帰納法というのはなんでも出来る可能性がある有名な
奴で他にもあるけど、あれば突破口になるだろうということで昭和時代は一世を風靡した。現在でこれを知っている奴はただの犯罪者で公共社会の害悪でしかない。
今の非モテ論争、あれ見てて一番やべえなと思うのが、他人への関心の薄さなんだよなあ
すごい矛盾したこと言ってるように感じると思うんだけど、あの元増田みたいな人って他人に興味がないよね
自分の足りないものを補うために彼女が欲しいだけで、その子を自分が受け入れよう、受け止めようって気持ちはないよね、自分を受け入れてほしい、受け止めてほしいばっかでさ
好きな子ができたって言ってもちょっと理想と外れてたり嫌なとこ見たり冷たくされただけで「やっぱり違った」「傷つけられた」ってすぐ完結するじゃん
「この子こんな一面もあるんだなあ」とか「なんでこんなことするんだろう?」とか「相手と自分のどっちが悪かったんだろう?」とか、自分にも原因があったりしないか本当に相手の性格が悪かったのか単純に状況が悪かったのか、そういうこと考えずにサーッと引いていくじゃん
相手を見極めたいとか、本当はどういう人間なんだろうって深掘りするほどの興味はないんだよね
現実の世界に理想どおりの相手なんているほうが奇跡だし、アニメのキャラクターみたいにたかが13回見たくらいで理解できるような薄っぺらい人間はいないのに、ほんのちょっとのズレで「わかった、さようなら」って尻尾巻いて逃げてくんだよ
なにもわかってねえよ、なんなら十年二十年一緒にいたって「こんな奴だったのか」って思うこともあるのが人間の面白さだろ
それに興味が持てないなら最初から現実の女に行くなよ、だれも強制してねえよ
で、こういうこと言うとだいたい過去のトラウマを持ち出してくるじゃん
「過去に人間関係で辛い経験をした、だから心に傷があって他人と接するのが怖い、でも彼女は欲しい」っつってな
うん可哀想だね、自分を大事にしてね、でもおまえを大事にするのはおまえ自身であって今現在まったく赤の他人の女の子じゃねえんだよ、って話なんだよな
過去におまえを傷つけた誰かの責任を別の誰かに取らせようとするんじゃねえよ
過去の誰かと今の誰かの区別がついてねえんだよ、勝手に自分の中にあるいくつかの人物像当てはめて自分の中でお人形遊びしてるだけだろ、それが「人間扱いしてない」って言われてんだよ
おまえに冷たくしたその子は実は過去にひどいいじめを受けて心は傷だらけでそれをおまえが知らないうちに抉ったのかもしれないじゃん
嫌な態度取ってたその子は今家族の問題を抱えてて心の余裕がなかったのかもしれないじゃん
そういう「相手には相手の事情があるかもしれない」ってことを考えずに「可哀想な自分を受け入れてくれないなんて」って傷つくの、すごいお門違いの我儘だろ
おまえが心の傷を持ち出すなら、相手にだって心の傷を持ち出す権利があるんだよ
自分だけが傷ついてると思うなよ、むしろ心の傷なんてない人間のほうがレアだよ、みんな必死こいて自分で埋めてんだよ
でもこういうこと言うと、でも自分はものすごく傷ついてるからって特別扱い要求するんだよな、おまえの傷の深さなんか知らねえよ、おまえだって他人の傷の深さなんかわかんねえだろ
それでもおまえが傷ついた自分を受け入れてくれって言うなら、おまえは傷ついた相手を受け入れる義務があるんだよ、必死こいて相手の傷を埋めてあげなきゃいけないんだよ
それができないと思うならまだ早いんだよ、行くんじゃねえよ、だれも強制してねえよ
それでも行きたいなら心の傷くらい受け入れる度胸を持てよ、怖いとか言ってる場合じゃねえんだよ
だいたい、なんの過失もない相手を怖がるってものすごい失礼なんだよ、夜道やエレベーターで勝手に痴漢疑惑かけられて怖がられる善良な男のことを考えたらわかるだろ
そんで、男だって女だって失礼な奴は嫌いなんだよ、「なんで勝手に怖がられて怯えられなきゃいけないんだよ、自分が何かした?」って思って当然だろ、わけもわからず自分に怯えてる人間に好意なんて持てないんだよ
だからおまえは煙たがられるんだよってこと
ぬいペニ論争からペニスの出し方の話が出てきてたじゃん、あれ正しいし、頑張れる人はあれで頑張ればいいと思うんだよ
なんだけど、すごい絶望的だなとも思ったんだよな、だって拗らせた奴はあれができないわけじゃん、ていうかあれができる関係性すら築けないわけじゃん
それがなんで築けないのかっていうのはもう彼女云々じゃなくて人間関係構築の問題じゃん、彼女が欲しいとか言ってる場合じゃないんだよ、問題はもっと深刻なんだよ、もっと別のとこで危機感持てよ
その子に興味があって好きになって彼女になってほしいじゃなくて、彼女が欲しくて周囲から見繕ってこの子が好きかもってなるのはもうなにもかも違うんだってことがわかってないわけじゃん
まずはさあ、自分が欲しいのは本当に生きてる人間の彼女かってことを冷静に考えたほうがいいと思うんだ
民事訴訟法82条1項2項を制御しているファンクターは、民訴法の目的ではなく、憲法25条の福祉国家の精神に由来していてなおかつ、民事手続の要点だけに絞った補完規定なので
その辺で、finalvent説によれば、コンメンタールを読めば精緻に整理されたものが読めるので、コンメンタールを読めばいいというようなことを言われた。finalbent, ボツネタ、養老孟司といえば、
平成17年より前に大量に活躍していた文筆家で、 Finalventは文筆家ではなくプログラマーエンジニアで、Windowsの本を書いてその後にブログで文筆家に転向したが、今はどうなっているのか
確認する手段がない。Twitterには、宮崎県知事、なども書き込みをしているのは理解できるが、記載内容の趣旨が分からないし、Twitterにいる者を巡査などが自転車が外観などから見ても
どこに住んでいるのか確定することは困難であろうと思う。Finalventは、2005年より前にブログで晒していた変態を削除することなく現在でも残存させているのは偉いと思うが、社会を検索して
発見したことはない。またそれに似た者が警察官の服を着て舟渡の堤防にいたこともあるが去年の話で何も申し立てなかったので本人かどうか分からなかった。
「こういんや?」
今日は小学生の参観日である。授業では国語辞典の使い方を教えており、子どもたちは楽しそうに大きな辞書をめくっている。
「「光」の文字を使う単語を探してみよう」というテーマで辞書をめくる子どもたち。早速「光陰矢の如し」をみつけたらしい生徒が、なぜか「こういんや!」とだけ答えたため、先生が意味を理解できなかったらしい。
生徒が開いたページを覗きこみ、漢字を確かめた先生は、もういちど「こういんや?」と首をかしげ、黒板に「光陰矢」と書いた。「ごとし」はどこにいったのだろう。もしかして「光陰矢の如し」をご存知ない??まさかね。きっと「光陰矢」という単語もあるのだろう。
次の生徒が手を挙げる。
「こうそく!」
にこっと笑って先生が却下する。多分生徒は「高速」でもなく「校則」でもなく、「光速」と答えたのでは?なぜ確認せずに却下する?
先生のさわやかな笑顔を眺めながら、ふと大学時代の友人達を思い出した。
私達は氷河期世代だ。田舎の国立大を出たくらいでは就職は困難を極めたし、教育学部の友人で、先生になれた子はただのひとりもいなかった。そもそも採用すらほとんどなかった。「先生になりたかった」って泣いてた子、何年も試験をチャレンジして講師を続けていた子、本当に先生になるのは狭き門で難しかった。
しかし、現在はうってかわっての教員不足。うちの小学校でも例に漏れず教員は全く足りていない。クラスに応じた教員が確保できず、先生がかけもちで対応していた時期まであった。きっとこれは罰なのだろう、教員の待遇を改善してこなかった罰。その罰は、我々でなく小学生の我が子達が現在進行形で背負っている。
「これ、せんせいこれ!これも!」
また「光」の付く単語をみつけたらしい男の子が辞書をひらいて単語を指差す。
「よし!それも「光」がつくな!」
「ウニ駆除を5年やってきたけど、磯焼けの原因はウニじゃなくてイスズミとかいう魚だったっぽい(でもウニ駆除は続けるよ)」 とかいう論調になっていてげんなりした。
いわゆるガイジ採用枠が一人入ったんだけど、そいつの業務に上司が永久について回ってる。
パニック障害の手帳持ちなんだけど現在は病状は安定していて日常生活に特に問題はないレベルと聞いているんだけど、システム導入の支店への説明や使用指導とかあらゆる業務に上司がついて回ってる。
何してんのかなと思って支店の仲のいい同僚に聞いてみたらなんか後ろで突っ立って見てるだけって言ってて、マジでこいつ何しについて行ってんのって感じ。ガイジも普通にハキハキ話してて説明もうまいしガイジ採用枠ってわからなかったよ!って言ってた。
ガイジ採用だから給料自体はちょっと安いらしいけど、それに無能上司が常について回ってるんだったら実質、一人で済む業務に2人分以上の給料がかかってることになるわけじゃん。ぶっちゃけそれだったらガイジじゃなくて健常一人とってそいつにその業務やらせた方がよっぽどましじゃない?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}