はてなキーワード: トレーニングとは
それはありふれたイベントであるはずだった。子ども連れはその辺を普通に歩いている。知り合う人々には必ず親が居る。子育てについては日々たくさんの議論が交わされている。妊婦さんがこの世に命を送り出すこと、それは特別でも何でもない日常の出来事だ。そう思っていた。
とんでもなかった。
何が私の考えをかえたのか。
痛みである。とんでもない痛みに襲われたせいだ。
陣痛というものを知らなかったわけではない。痛いんだろうな、ときちんとビビっていた。下調べもイメージトレーニングもして、痛みに耐える覚悟はしていた。だけど私は陣痛を理解しているわけではなかったのだ。うっかり知っているつもりになっていた。
経産婦の皆さんは言う。「そりゃ痛いよ、でもみんな何とかなっているから」、「もう覚えていないなぁ、だからふたりめも産めちゃう」と。つまり、耐えられない痛みではないのだ。私は自分を鼓舞した。
そしてむかえた出産当日、私は吠えた。冷静な頭のまま、しかし狂ったように叫び声を上げていた。もう狂ってしまいたかった。意識がとんでしまったら楽だったのに。
大声を出して何になる、と自分にドン引きながら、それでもただひたすら叫ぶしかなかったあの時間。耐えられない痛みではない? 嫌だもう耐えたくない! 痛い痛い痛い逃げたい! どんなに吠えても誰も助けてはくれなかった。
実際、私は耐えて産んだわけだ。それでも「耐えられない痛みではない」とは絶対に表現しない。痛いもの。おかしいよ。人間なのに、動物だった。
世の母親達は本当にしれっとこの痛みを経験しているのか。信じられない。実は痛みを減らす裏技でもあるのではないか。
この陣痛というものを、当たり前のように受け入れているなんて今は一体何時代なの? そうか、令和は別に新しくないのだな。未来から覗いてみれば、私達はきっと古代に生きている。長い人間の歴史の最先端なんかではないのだ、令和は。そこそこ古い時代に居るんだ。
その証拠に、分娩方法が昔とそうかわらないだろう。傘の形態と同じである。高度な医療が発展しているはずなのに、出産は辛いままなのだ。出生率が減るのも当たり前である。
せめて妊婦を、経産婦を労おう。ジェンダー論や政治的配慮なんか置いておいて、とにかく陣痛に立ち向かう度胸に対して、みんなで拍手を送ろうよ。
意地悪なおばちゃんも、炎上しちゃうギャルママも、あの痛みを経験したのだと思うと頭が下がる。
出産を経験して、私は母に心から感謝することができた。訳あってほぼ絶縁している実家に、子どもを産んだことを伝えた。久し振りの連絡であった。たどたどしいやり取りを交わし、でんわを切った。ショートメールに彼らの孫の写真を送った。
私を産み落とすために、あの痛みに耐えてくれたのだ、と心が震えた。
「痛いのに産んでくれてありがとう」
そのセリフは、出産後に私が子どもにかけたそれと同じであった。
しまった、出産は素晴らしいという締めになってしまいそうだ。やりがい搾取は良くない。痛かったよ。あの痛みを当たり前に妊婦さんに押しつけてはいけない、そうだろう、と問題提起をしておく。
石丸伸二をよく知ろう
https://www.youtube.com/watch?v=Nv3KOXAvFFU
全く意味が解らない。
皆さんこんにちは石丸伸二です。今回喜多方市長選に立候補しました。いろんなところで政策のお話はさせてもらってるんですけども、そもそもあなたは誰なんですかというご質問をいただくことも多いので、今回はその御要請いただいた質問をまとめてもらいました。
順番にお答えしていきたいと思います。
まず最初、最初ははい浦上ですね。はい。最初血液型と星座。O型です。星座は、しし座ですね。変わってないと思います。13星座でもしし座のはずですというのは、あまり星座に興味がない人間です。すいません朝の星座占い見ません。
次へきのこの山たけのこの里、どっち派。これは難しいですね。これほど世界を二分するテーマはないんじゃないでしょうか?ただこの厳しい質問に答えていくのも、市長としての大事な仕事になるのかなと信じてます。答えはたけのこですね。
チョコとサクサクスナックのバランス、何より質量感ちょっとキノコじゃ出せないなと思ってます。
次こんな調子で大丈夫か。次じゃん。得意なこと、自慢できること取り立てて自慢できることも、もう何でしょうか?
お酒が結構飲めます。苦手なお酒はないですね。世界のどんな酒でも出されたら絶対飲むと。
これは唯一親が僕に与えてくれた貴重な才能の一つかな.。お酒が飲める体質にくれてありがとう。(笑いがはいる)
次じゃん。苦手なこと、本当に苦手なことが多いんで、ちょっと選ぶのが難しいですね
もうちょっと皆さんが引くほど苦手なことを言っちゃうとマイナスなんで、言える範囲で、装着時は結局苦手な事。複雑な事が苦手です。
例えばスポーツの球技だけ駄目ですね。単純な走りとか泳ぐとかだと、夢中でどれだけでもできるんですけど、はい、野球とかはもう見る専門です
この街サッカーサンフレッチェありますけど、もう応援は絶対頑張って誰よりもできるんですけど、実際にやってみる体験とかは、すいませんちょっと難しいと思います。(だれかしゃべっている)
次スクールミーティング休みは何してますかなるほどこれまでの生活の中でいくと、基本的に休んでません。というのはトライアスロンというのをやってるので、土日は基本的に練習になってます。
朝は7時ぐらいからですねバイク、自転車に乗って、長い日は昼過ぎぐらいまで走り続けてます。100キロとか120キロというトレーニングをやるのって、休みの日はむしろ休まない。そんな生活を受けてます。
次今お付き合いしている人は、私の恋人は安芸高田市です。(スタッフが笑う)
ちょっとスタッフの人は笑いすぎですよ。いいえなるほどそれはいらないいらないんですいません。はい。独身ですし未婚のまま今に至ってます。はい。
どうも私にとっては恋人がこの街であり、私の奥さんはこの街です。また笑われました。
私はここで生まれ育って、僕は外の世界は本当に知らなかったんですね。旅行で時々出かけたことが年に1回ぐらい。
海外なんてもう大人になるまで出たことはありませんし、なので、ここが私の世界の全てです。
なので、何でしょう。はい。もう完成してましたね。この町も全て私の好きなものは全部ここにあると思って育ってました。はい。なので、やっぱりここは僕にとっては安らぐ場所ですね帰ってくる場所としては、これ以上の街はないなと思ってます。
安芸高田のここが好き僕の生まれ育った場所なので、小さい頃好きだった風景ですね。それは山があって、田んぼが広がって、町の人たちも距離が近いですよね。うちは歩いててすれ違う人に大体挨拶します。
名前知らなくても何となく知ってる人、そういう感じがみんなにあるんですね。そういう懐かしいというか、変わらない良さ、やっぱりそこが好きです。
新庄よく素人の映像あっという間の2時間半お楽しみいただけましたでしょうか?(この動画以外にまだあったらしい)
6日は今まだ選挙期間中です。
でも、あっという間に終わります。次の日曜日で、もうこの選挙も終わりなんですね。
でもこの選挙期間を通して何よりも、それが終わった先でですね、しっかりと自分がここにいる意味戻ってきた意味を、それを皆さんに伝えていきたいと思います。
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
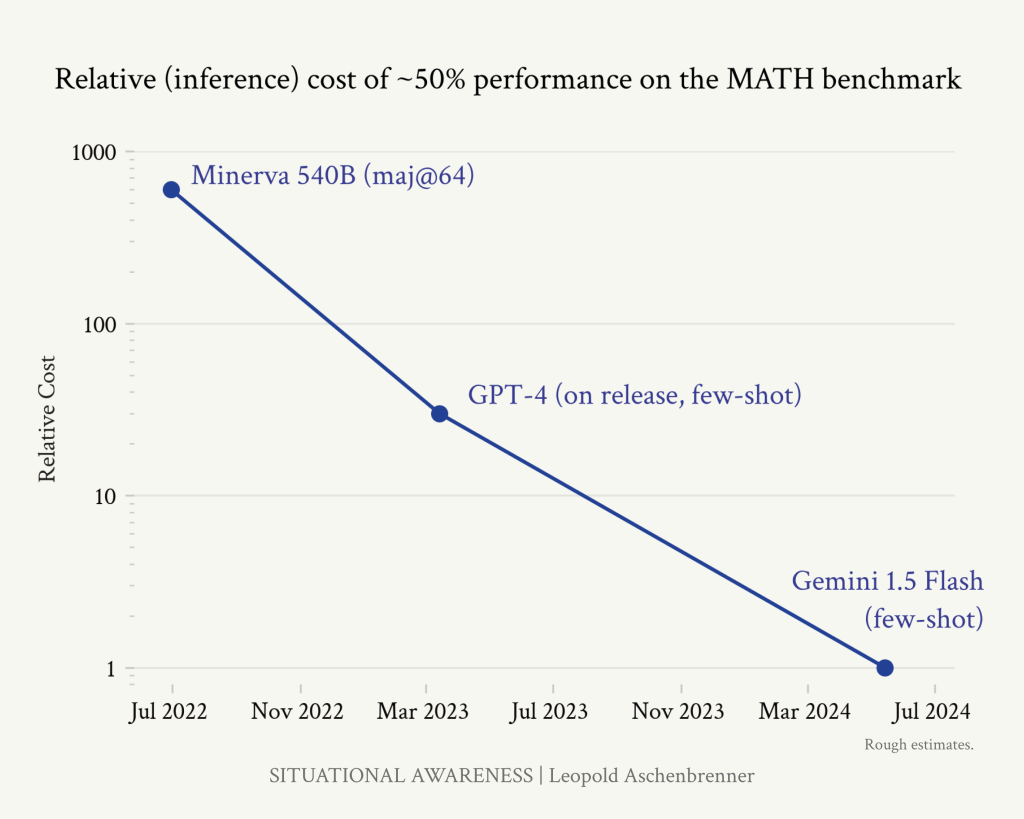
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
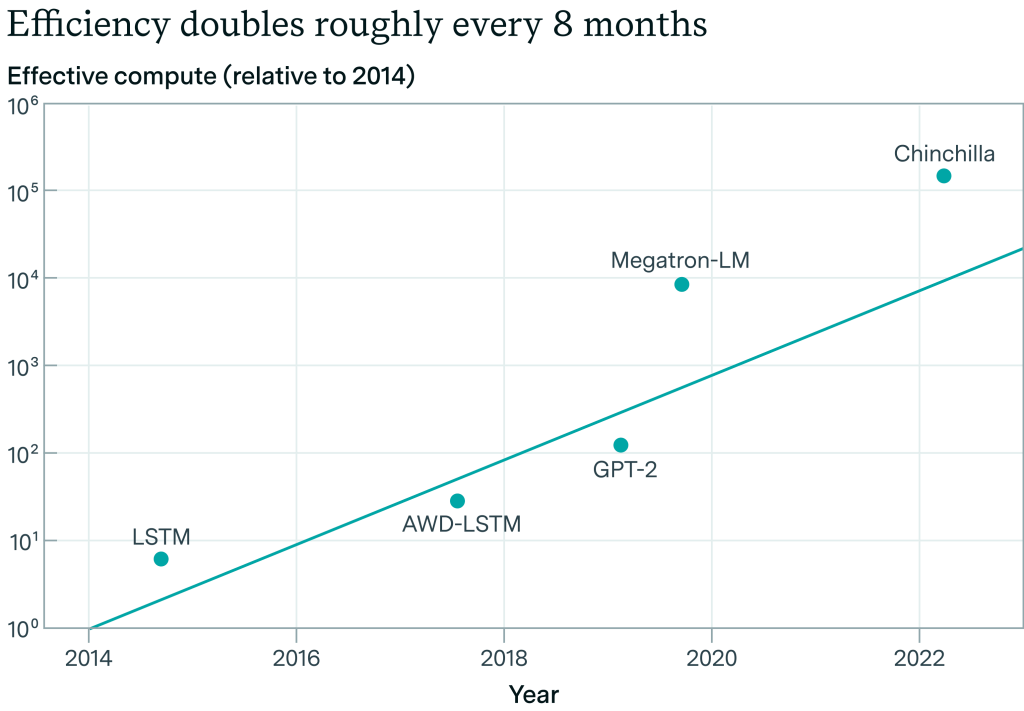
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
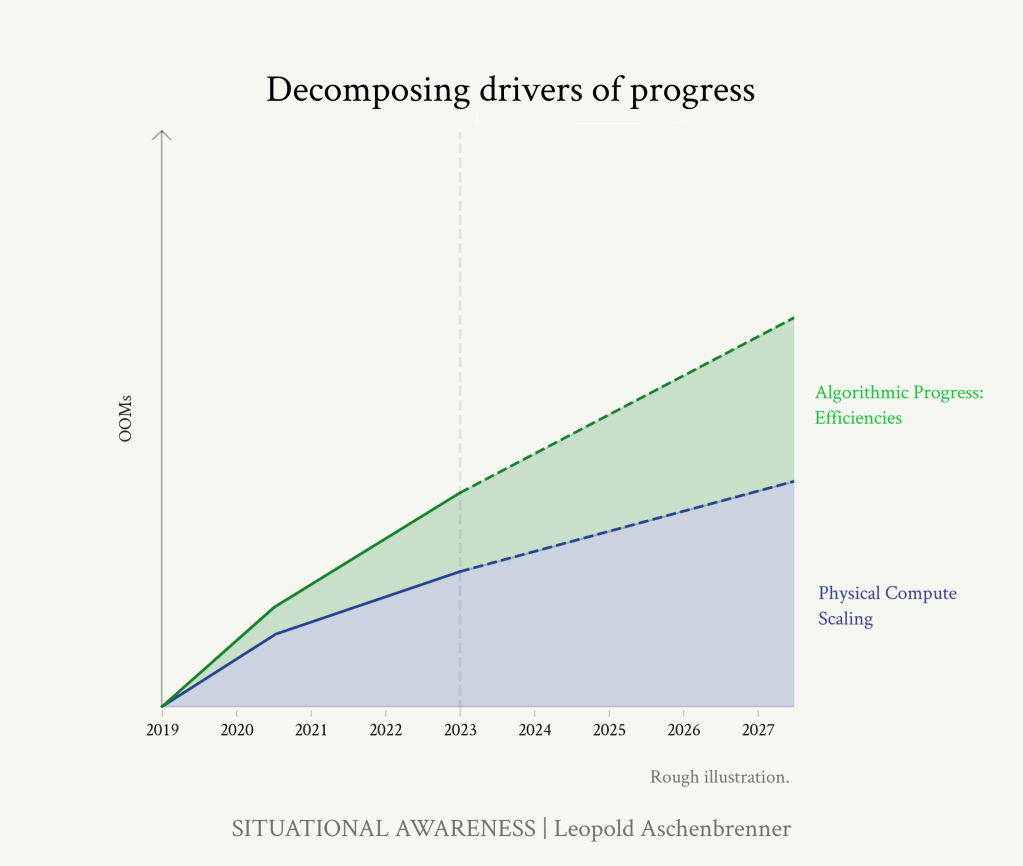
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
「人として接する」というのは普通のことではありません。トップコメの言うことは、正しいが、あなたには本当に難しいことです。
学校のクラスがあって、あなたが「人として接してきてくれたなぁ」という人はどれくらいいましたか?おそらくほとんどいませんね。学生時代は特に、自分に利益(面白いとか発言力あるとか)がない人には多くの人は冷たいものです。
不自由ない人からみた「人として接する」、それはその人たちが他の人達に普通に受け入れられ、普通に喧嘩し、普通に仲直りし、時には仲違いしたままになる、そんな「普通」のやりとりなんです。そりゃあ「普通にすればいいよ」といいます。その人たちは悪くない。だってその人たちには普通なんだもの。「変にセクハラみたいなことを【わざと】せずに、普通にすればいいんだよ」と思ってるんです。
あなたは違う。これまであなたに「人として接してきた人」なんていうのは、本当に少ない。されてない事はわからない。教わってもいないし。あいつ等が楽しそうに喋ってるのはたしかによくある光景だけど、それはこちらにはやり方は分からない。やってないから。やってないし、じーっとなんて見ないから。じーっと見てたら、「気持ち悪い、あいつは人に人として接しないやつ」と思われる。少なくともこちらは思われると思う。だって経験してきたから、そういうことを。分かるから、プロだから(笑)まあもっとも、見てるだけでできるなら誰だって大リーガーになれるわけで。
あなたにとって、人に対して一般的に言う「人として接する」というのは、とてもハードルの高いことなんです。だから、一つ一つ登っていかないといけない。全て網羅的に言うことはできないけど、大事だと思うことから順に書いていきます。
これは当然だと思うだろうし、「あなたは何考えてるか分からない」とさえ言われたこともあるでしょう。こちらの考えがわかってもらえずヤキモキしたり不本意に責任をふっかけられたことも一度や二度ではないはずです。
でもね、同時に、あなたはあなたの本心が見透かされてると思うこともあるんじゃないかと思うんです。下心が見透かされてるのではないかとかね。
あのね、実際のところ相手には分かりませんから。相手は単に、あなたがキモいからそう思うだけです。仮に本当にあなたに下心があっても、下心があると思われるのは、あなたがキモいからです。(てかそもそも下心があることが悪いことじゃないし。そこがズレてんだよなぁアドバイザー(笑)さんは。)カップルになる連中は、下心があって、下心を許容して、それでカップルになってるだけですから。「下心をなくせ」というアドバイスは下の下、何も見えてない。下心なくしてあなたが行く先は、ぬいぐるみですから。
下心はあってもいいのです。相手はあなたな下心なんて本当の意味では見透かせません。問題は「見た目と話し方」なんです。そして幸い、どちらもなんとかなります。
2. 見た目を整える
以下をやってください。
・服を全部捨てる
・季節ごとに服を買う(凄く凄く頑張って、店員を捕まえて、全身をコーデしてもらってください。ここ、残念ながら頑張りどころです)
・月ごとに美容院に行く(ここは予約さえ取れれば、あとは「いい感じにしてください」でなんとかなります)
3. 話し方を整える
オンラインでいいので、人と話すトレーニングをしてください。教えてくれる環境で。
「話し方講座」と調べると出てきます。
これらをしてやっとあなたに「人として人に接する権利」が与えられます。今はあなたには権利がありません。不公平はしょうがない。戦争のない国に産まれただけありがたいと思うしかない。足があるとか目が見えるとか、ありがたいと思うことはたくさんあるのでそう思って自分をなんとか誤魔化してください。権利を得るまでの辛抱です。もしあなたが権利もちになったら、これはもう素晴らしいことであり、最初から持ってる有象無象とあなたは違うということになります。逆に権利を持つところまで行けなかったら、あなたはいつまでもそいつ等以下。誰がなんと言おうと、見えない世間の目はそうあなたを判断します。もちろん奴らは「そんなことはない」というけれど、クマが出てきて誰を犠牲にするかといえば、あなたですよ。なぜならキモいから。理屈で考えりゃ、これまでいい思いをしてきた連中が食われるべきなんですよ。それが公平ってもんだ。でもそうしない。なぜか?あなたを下に見てるんですよ、結局。そんで逃げ切ったところで「良かったね、あの人可哀想だったね」とか言って女が泣いて、男が慰めて、まあその夜にでもセックスするんじゃないですか。こんな不条理あるか?と。あるんですね。まあ不条理がない方がおかしいんですよ、別にだれかが上手くバランス取るみたいなゲームみたいなことはないわけで。
人として人に接するには、まず権利が必要。で、その権利を得るためには、人は不要な努力をする必要がある。まあ見た目は他の人も努力してるかもしれない、そこはあなたのこれまでの努力不足とはみられるかもしれない。でも話し方は違いますね、割と持ってるものってところかなと。
あとは、権利を持ったあとに濫用しないことは注意ですね。それによって、あなたの行動が本心に沿ってしまう。その時は、キモさとは異なり、本当に本心が表に出てしまい見えてしまうから。そこだけは気を付けてください。
朝早く起きて、ジムに行き、
その後電車で街へ。
交通系の残高が足りなくなっていたのでスマホでチャージをして、電車から降りる。
それから友達に代理で受け取ってもらった荷物を友達の家へ取りに行く。
時間が溶けて、寝る支度もままならないほどハマってしまっている。
助けてくれ。
40代から体重が増えやすいのは加齢による筋肉量の減少で代謝が低下しているにも関わらず摂取カロリーが変わらないためオーバーカロリーにが日常的になっている事が原因です。
従ってまずは筋力トレーニングで筋肉量を増やします。ジムに契約し、フリーウェイトでコンパウンド種目を中心に全身の主用な筋肉を鍛えます。強度は漸進的にあげていき週2回程度の頻度で行います。
次に食事を改善します。直近1ヶ月の摂取カロリーと体重の変動からメンテナンスカロリーを算出します。減量するなら1日500kcalのマイナスカロリー、減量時以外はメンテナンスカロリー+200kcal程度に抑えます。タンパク質を体重kgの1.5倍グラム程度、脂質を体重g程度に設定し、残りを設定カロリーに合わせた炭水化物量にします。この範囲内で甘いものなど好きなものを食べてください。
有酸素運動は減量を加速させたい場合に行います。心拍数130程度で20分間行うのが効果的です。
ChatGPT 6が登場したあたりで「俺に残ってる仕事って何?」ってなると思うわ。
どうすんのこれ。
その数ヶ月前に始めていたスクワットが原因かと思って数週間休んだりもした。
が、結局しばらく休んでも完全に痛みは消えず、小康状態になってからスクワットを再開していた。
休みの日には痛みが消えるのであんまり気にはしていなかったのだが、今度は反対側の膝まで痛み出したので仕方なく整形クリニックに行くことにした。
スクワットのしすぎによる腱鞘炎かと思っていたら、レントゲン撮られた上に、軟骨のすり減りによる痛みだと診断された。
しかし、レントゲンをみる限りだと骨がとがってるだけでひどい状態ではないらしい。
じゃあ何でこんな痛いんだ?
結局痛み止めのヒアルロン酸打って、後は湿布と塗り薬を処方されたが、
「足を鍛えるように」
と言われた。そうすることで膝の悪化進行を緩やかに出来るとか。
え?と思って「じゃあスクワットしていいんですか?」と聞くと、痛みが収まるまで止めといた方が良いという。
?
?
?
スクワットせずに足を鍛えろ…?妙だな…この医者何を言っているんだ?歩くのもだめならいよいよ鍛えるなんて無理だ。
じゃあどうやって鍛えるんだと聞くと医者は渋々
と言いつつ寝ながら足鍛える方法を紹介したペラ紙をくれた。膝痛い人向けに足を鍛える方法でググると出て来る奴だ。
それから自分はコンビニジムのエアロバイクを週一で使うことにした。平日に筋トレ40分+エアロバイク20分以上のトレーニング時間を確保するのは難しい。
そして、エアロバイクを使っていると今度は、親指が痛み出した。
原因はエアロバイク中にスマホを見ているからだ。エアロバイクの退屈さは経験したことのある人なら知ってるだろう。ひたすら無心でアレを続けるなど私には無理だ。
とかくこの世はままならない。
この医者ヤブじゃなかろうかと思いつつも他に手はないので湿布を貼っているが、膝の痛みが消えるのは一時だけだ。引いたと思った次の日にはまた痛みが出る。
医者に行く前は芥見下々の描く少女の足の様に太かった私の足も、今は、早瀬ユウカ並みに細くなってる。
ここから更に篠澤広の様になるまで続けなければならないのだろうか
膝の痛みはまだ消えない
はい、交差検証法はホールドアウト分割を繰り返し行う手法です。
## 交差検証法の手順
1. データセットを複数のフォールド(部分集合)に分割する。[1][2]
2. 1つのフォールドをテストデータ、残りをトレーニングデータとしてモデルを構築する。[1][2]
3. テストデータでモデルを評価し、評価指標(精度など)を記録する。[1][3]
4. 2と3を、すべてのフォールドが1回ずつテストデータになるまで繰り返す。[1][2]
5. 各フォールドでの評価指標の平均を最終的な評価値とする。[1][2][3]
つまり、交差検証法はホールドアウト分割(トレーニングデータとテストデータに分割)を複数回行い、その結果を平均化することで、より信頼性の高い汎化性能評価を行う手法なのです。[1][2][3]
この繰り返しによって、特定のデータ分割に左右されずに、より客観的な評価ができるというメリットがあります。[1][2]
代表的な交差検証法には、k分割交差検証やLOOCV(Leave-One-Out Cross-Validation)などがあり、データ量に応じて使い分けられます。[1][2]
Citations:
[1] https://shoblog.iiyan.net/cross-validation/
[2] https://ja.wikipedia.org/wiki/%E4%BA%A4%E5%B7%AE%E6%A4%9C%E8%A8%BC
[3] https://qiita.com/RyutoYoda/items/4ca997771e99d6c39ddb
[4] https://aiacademy.jp/media/?p=263
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}