はてなキーワード: 投資とは
少子化対策の話をするなら、まずは世界で成功している少子化対策について見る必要がある。
日本の対策が不十分なら、他の成功例を参考にするしかないからだ。
じゃあ、どこがうまくいってるかって言うと、北欧諸国がその代表例だ。彼らの成功には、いくつかの理由がある。
まず第一に、育児休暇とその充実度だ。スウェーデンやノルウェーでは、父親も育児休暇を取るのが当たり前。父親の育児参加が進んでいるから、子供を産むことへのハードルが下がっているわけだ。「日本の企業文化じゃ無理だ」と言うやつもいるだろう。でも、それができないのは企業が古臭い考え方にしがみついているからだろ?少なくとも、国が本気で取り組めば変えられないはずはない。
次に、保育施設の充実。デンマークなんかは、保育施設がたくさんあって、しかも質が高い。待機児童なんて言葉すら存在しない。日本でも待機児童問題は深刻だけど、「金がない」とか「土地がない」とか言い訳ばかり。実際には、予算の使い方が下手なだけだ。無駄な公共事業に金をかけるくらいなら、保育施設の拡充に投資すべきだろう。
そして、教育費の無償化。フィンランドでは、大学までの教育が基本的に無料だ。子供を産むと教育費がかかるから、産みたくないっていう親が多いけど、そういう負担を軽減する仕組みがあれば、もっと子供を産む人が増えるはずだ。それに対して、「財源がない」とか言うやつもいるだろうけど、本当に必要なことに使うなら、増税だって納得する人は多いはずだ。政治家のお友達予算に使われるよりはね。
さらに、女性の働きやすさ。北欧では、女性の社会進出が進んでいて、出産後もキャリアを続けやすい環境が整っている。日本じゃ、未だに女性が家庭に入るのが当たり前って考えが残ってるけど、そんな古い価値観を変えなきゃ、少子化対策なんて進まない。女性が働きやすい環境を作るために、制度改革や意識改革が必要だ。
「日本の文化や歴史があるから、そんなに簡単に変えられない」とかという話もあるだろう。でも、文化や歴史があるからこそ、変えなきゃいけない部分もあるんじゃないのか?過去に固執して未来を犠牲にするのは愚かだ。
問題は、政治家や企業が本気で取り組む気があるかどうかだ。本気でやれば、結果はついてくるはずだ。
でも、現状を変えたくない人たちが多すぎて、進まないってのが現実だろう。少子化問題を解決するためには、抜本的な改革が必要だ。だけど、それを実行する覚悟があるかどうかが問われているんだ。
あらゆる子育て支援をどれだけ拡大しても夫婦の平均出生数は全く増えていない
そして少子化は明らかに婚姻数の減少によって加速しているとあらゆるデータが示してる
結局のところ子育て支援に流れる金は子供を増やすことではなくすでにいる子供により良い投資を行うほうに消えているというのが統計的な事実なんだよな
・判断を保留した
・英語学習をするふりをした
・大喜利をした
・2階に行った
・婚活をした
・3大◯◯を考えた
・手斧を投げた
・タイトルだけ読んだ
・文句だけ言った
・ダイエットをしようとした
・改めてファッションに興味を失った
・積読をした
・積みゲーを積んだ
・投資をした
・お酒を飲んだ
・90年代を懐かしんだ
・温泉に浸かった
・寝る前に少しブコメをした
多分もう何やっても無駄なところまで来てる
「政策で動く出生率の幅は小さいから人的資本投資と考えたほうが良い」とか「少子化前提で労働力不足の解決を考えるべき」とか話したんだけど、案の定使われなかった…。
共働きで子供を育てていくとなると、夫婦間でさまざまなすり合わせが必要となる。若い世代にはそれも負担と映るのかもしれない。結婚や出産はあくまで個人の自由な選択の結果であるべきだが、1人で生きるより結婚や子供を持つ人生の方が楽しいと思えるような社会に変えていかないと子供は増えない。
若者の価値観が結婚や子育てから離れていってしまうと、仕事と子育ての両立策を充実させても子供を増やすことは難しくなるだろう。
https://www.sankei.com/article/20240216-DOVVM3M7GVGDRG6RGNOD6ZY6AE/
私は以前、AGIへの短期的なタイムラインには懐疑的だった。その理由のひとつは、この10年を優遇し、AGI確率の質量を集中させるのは不合理に思えたからである(「我々は特別だ」と考えるのは古典的な誤謬のように思えた)。私は、AGIを手に入れるために何が必要なのかについて不確実であるべきであり、その結果、AGIを手に入れる可能性のある時期について、もっと「しみじみとした」確率分布になるはずだと考えた。
しかし、私は考えを変えました。決定的に重要なのは、AGIを得るために何が必要かという不確実性は、年単位ではなく、OOM(有効計算量)単位であるべきだということです。
私たちはこの10年でOOMsを駆け抜けようとしている。かつての全盛期でさえ、ムーアの法則は1~1.5OOM/10年に過ぎなかった。私の予想では、4年で~5OOM、10年で~10OOMを超えるだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/this_decade_or_bust-1200x925.png
要するに、私たちはこの10年で1回限りの利益を得るための大規模なスケールアップの真っ只中にいるのであり、OOMsを通過する進歩はその後何倍も遅くなるだろう。もしこのスケールアップが今後5~10年でAGIに到達できなければ、AGIはまだまだ先の話になるかもしれない。
つまり、今後10年間で、その後数十年間よりも多くのOOMを経験することになる。それで十分かもしれないし、すぐにAGIが実現するかもしれない。AGIを達成するのがどれほど難しいかによって、AGI達成までの時間の中央値について、あなたと私の意見が食い違うのは当然です。しかし、私たちが今どのようにOOMを駆け抜けているかを考えると、あなたのAGI達成のモーダル・イヤーは、この10年かそこらの後半になるはずです。
マシュー・バーネット(Matthew Barnett)氏は、計算機と生物学的境界だけを考慮した、これに関連する素晴らしい視覚化を行っている。
これらすべての重要な変動要因になりうるものがあります。つまり、より多くのスクレイピング・データでより大きな言語モデルをプリ・トレーニングするという素朴なアプローチが、まもなく深刻なボトルネックにぶつかり始める可能性があるということだ。
フロンティア・モデルはすでにインターネットの多くで訓練されている。例えば、Llama 3は15T以上のトークンで学習された。LLMのトレーニングに使用されたインターネットの多くのダンプであるCommon Crawlは、生で100Tトークンを超えるが、その多くはスパムや重複である(例えば、比較的単純な重複排除は30Tトークンにつながり、Llama 3はすでに基本的にすべてのデータを使用していることになる)。さらに、コードのようなより特殊な領域では、トークンの数はまだまだ少ない。例えば、公開されているgithubのリポジトリは、数兆トークンと推定されている。
データを繰り返すことである程度遠くまで行くことができるが、これに関する学術的な研究は、16エポック(16回の繰り返し)の後、リターンは非常に速く減少し、ゼロになることを発見し、繰り返しはそこまでしか得られないことを示唆している。ある時点で、より多くの(効果的な)計算を行ったとしても、データ制約のためにモデルをより良いものにすることは非常に難しくなる。私たちは、言語モデリング-プレトレーニング-パラダイムの波に乗って、スケーリングカーブに乗ってきた。大規模な投資にもかかわらず、私たちは停滞してしまうだろう。すべての研究室が、新しいアルゴリズムの改善や、これを回避するためのアプローチに大規模な研究の賭けに出ていると噂されている。研究者たちは、合成データからセルフプレー、RLアプローチまで、多くの戦略を試していると言われている。業界関係者は非常に強気のようだ:ダリオ・アモデイ(Anthropic社CEO)は最近、ポッドキャストでこう語った:「非常に素朴に考えれば、我々はデータ不足からそれほど遠くない[...]私の推測では、これが障害になることはない[...]。もちろん、これに関するいかなる研究結果も独占的なものであり、最近は公表されていない。
インサイダーが強気であることに加え、サンプル効率をはるかに向上させたモデルをトレーニングする方法(限られたデータからより多くのことを学べるようにするアルゴリズムの改良)を見つけることが可能であるはずだという強い直感的な理由があると思う。あなたや私が、本当に密度の濃い数学の教科書からどのように学ぶかを考えてみてほしい:
モデルをトレーニングする昔の技術は単純で素朴なものだったが、それでうまくいっていた。今、それがより大きな制約となる可能性があるため、すべての研究室が数十億ドルと最も賢い頭脳を投入して、それを解読することを期待すべきだろう。ディープラーニングの一般的なパターンは、細部を正しく理解するためには多くの努力(そして多くの失敗プロジェクト)が必要だが、最終的には明白でシンプルなものが機能するというものだ。過去10年間、ディープラーニングがあらゆる壁をぶち破ってきたことを考えると、ここでも同じようなことが起こるだろう。
さらに、合成データのようなアルゴリズムの賭けの1つを解くことで、モデルを劇的に改善できる可能性もある。直感的なポンプを紹介しよう。Llama 3のような現在のフロンティアモデルは、インターネット上でトレーニングされている。多くのLLMは、本当に質の高いデータ(例えば、難しい科学的問題に取り組む人々の推論チェーン)ではなく、このようながらくたにトレーニング計算の大半を費やしている。もしGPT-4レベルの計算を、完全に極めて質の高いデータに費やすことができたらと想像してみてほしい。
AlphaGo(囲碁で世界チャンピオンを破った最初のAIシステム)を振り返ることは、それが可能だと考えられる何十年も前に、ここでも役に立つ。
LLMのステップ2に相当するものを開発することは、データの壁を乗り越えるための重要な研究課題である(さらに言えば、最終的には人間レベルの知能を超える鍵となるだろう)。
以上のことから、データの制約は、今後数年間のAIの進歩を予測する際に、どちらに転んでも大きな誤差をもたらすと考えられる。LLMはまだインターネットと同じくらい大きな存在かもしれないが、本当にクレイジーなAGIには到達できないだろう)。しかし、私は、研究所がそれを解読し、そうすることでスケーリングカーブが維持されるだけでなく、モデルの能力が飛躍的に向上する可能性があると推測するのは妥当だと思う。
余談だが、このことは、今後数年間は現在よりも研究室間のばらつきが大きくなることを意味する。最近まで、最先端の技術は公表されていたため、基本的に誰もが同じことをやっていた。(レシピが公開されていたため、新参者やオープンソースのプロジェクトはフロンティアと容易に競合できた)。現在では、主要なアルゴリズムのアイデアはますます専有されつつある。今はフロンティアにいるように見えるラボでも、他のラボがブレークスルーを起こして先を急ぐ間に、データの壁にはまってしまうかもしれない。そして、オープンソースは競争するのがより難しくなるだろう。それは確かに物事を面白くするだろう。(そして、ある研究室がそれを解明すれば、そのブレークスルーはAGIへの鍵となり、超知能への鍵となる。)
続き I.GPT-4からAGIへ:OOMを数える(7) https://anond.hatelabo.jp/20240605210017
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
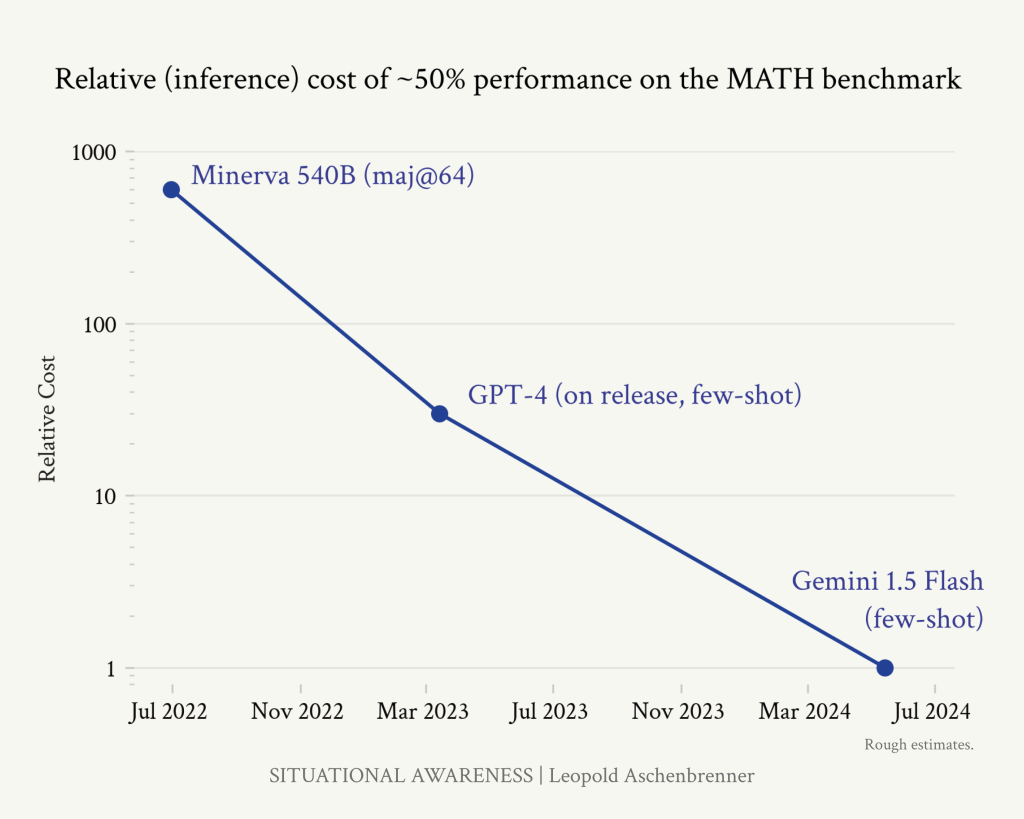
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
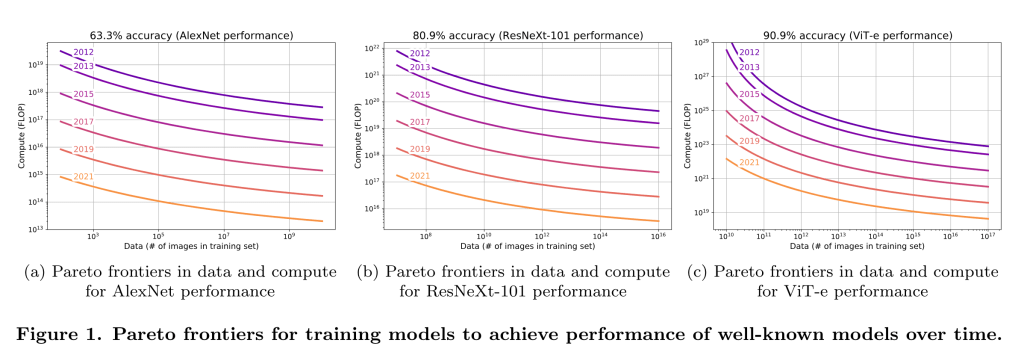
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
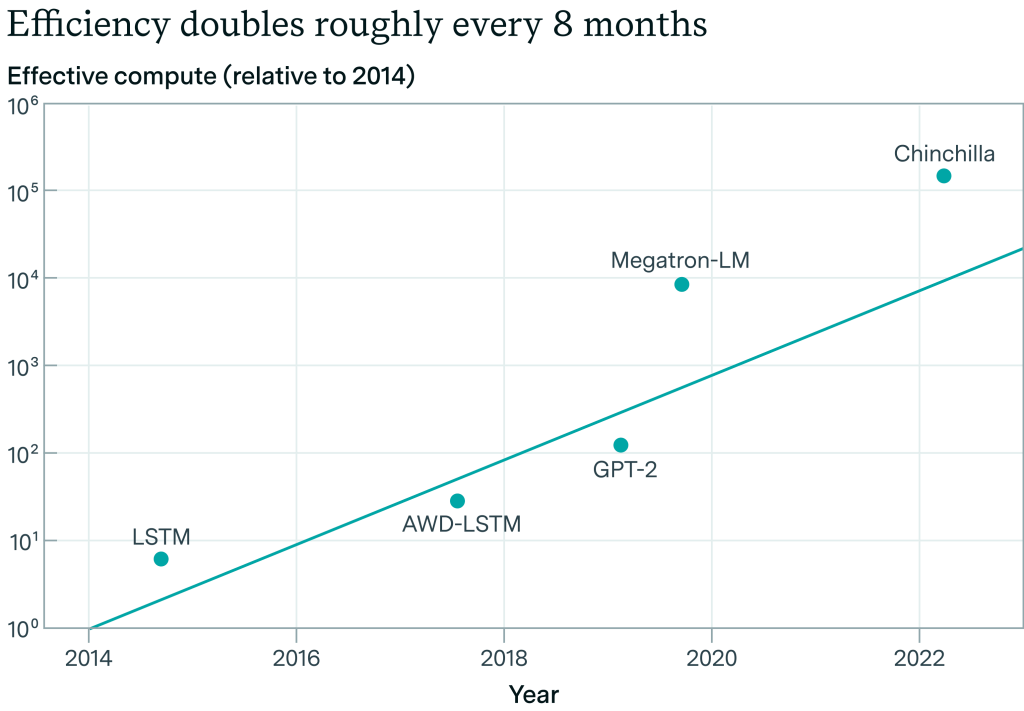
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
どうしてこうなった?ディープラーニングの魔法は、それがただ機能するということであり、あらゆる場面で否定的な意見にもかかわらず、その傾向線は驚くほど一貫している。
https://situational-awareness.ai/wp-content/uploads/2024/06/sora_scaling-1024x383.png
効果的な計算のOOMが増えるごとに、モデルは予測通り、確実に良くなっていく。OOMを数えることができれば、能力の向上を(大まかに、定性的に)推定することができる。そうやって、先見の明のある数人がGPT-4の到来を予見したのだ。
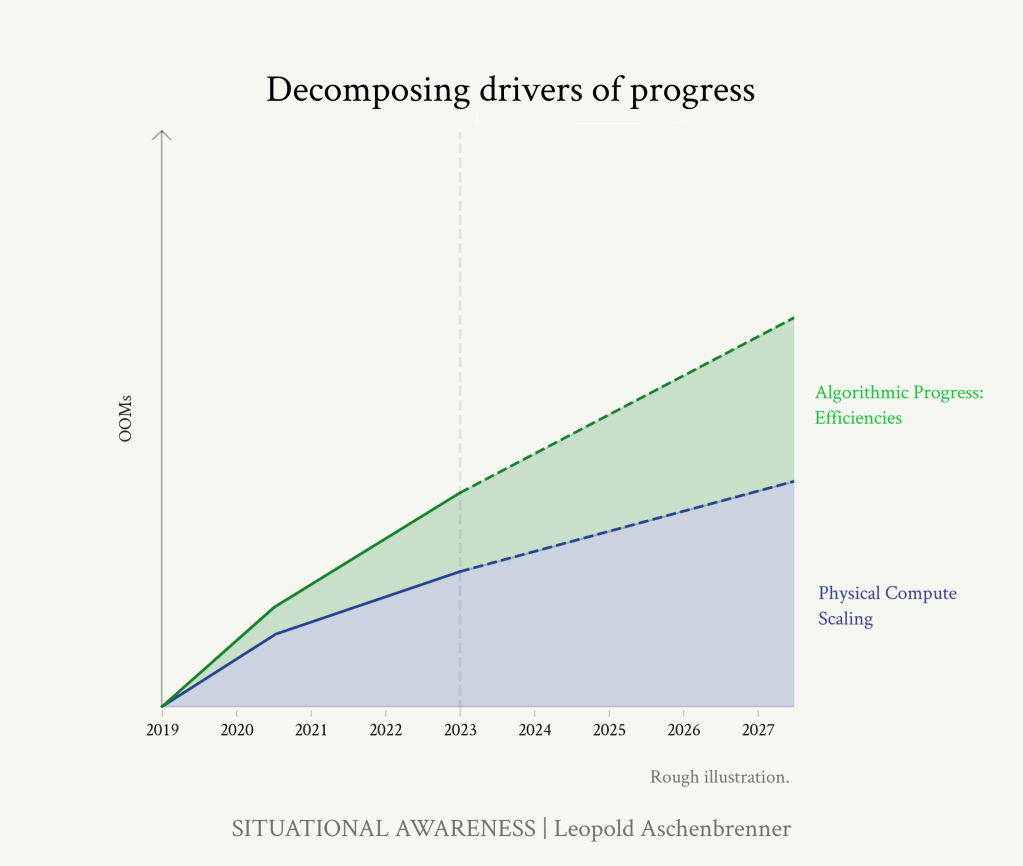
GPT-2からGPT-4までの4年間の進歩を、スケールアップの3つのカテゴリーに分解することができる:
1. コンピュート:計算:これらのモデルを訓練するために、より大きなコンピューターを使うようになった。
2.アルゴリズムの効率化:アルゴリズムの進歩には継続的な傾向がある。これらの多くは「コンピュート・マルチプライヤ」として機能し、有効なコンピュート量の増加という統一された尺度に乗せることができます。
3.「趣味のない」利益:デフォルトでは、モデルは多くの素晴らしい生の能力を学習しますが、あらゆる種類の間抜けな方法で足かせとなり、実用的な価値が制限されます。人間のフィードバックからの強化学習(RLHF)、思考の連鎖(CoT)、ツール、足場などの単純なアルゴリズムの改善により、潜在的な能力を大きく引き出すことができる。
これらの軸に沿って、改善の「OOMを数える」ことができる。つまり、有効計算量の単位でそれぞれのスケールアップをトレースするのだ。3倍は0.5OOM、10倍は1OOM、30倍は1.5OOM、100倍は2OOMといった具合だ。2023年から2027年まで、GPT-4の上に何を期待すべきかを見ることもできる。
ひとつひとつ見ていくが、OOMの数を急速に増やしていることは明らかだ。データの壁には逆風が吹いている可能性があり、それについては後述するが、全体的には、2027年までにGPT-4の上に、GPT-2からGPT-4規模のジャンプがもう1回起こると予想される。
まず、最近の進歩の原動力として最もよく議論されている、モデルへの(大量の)コンピュート投入について説明します。
多くの人は、これは単にムーアの法則によるものだと考えている。しかし、ムーアの法則が全盛期を迎えていた昔でさえ、その進歩は比較的緩やかなものでした。しかし、ムーアの法則が全盛期だった昔でさえ、10年で1~1.5OOMと、比較的ゆっくりとしたスピードだった。(かつては1つのモデルに100万ドルを費やすことさえ、誰も考えもしないことだった。)
| モデル | 推定コンピュート | 成長率 |
|---|---|---|
| GPT-2 (2019) | ~4e21 FLOP | |
| GPT-3 (2020) | ~3e23 FLOP + | ~2 OOMs |
| GPT-4 (2023) | 8e24~4e25 FLOP + | ~1.5~2 OOMs |
エポックAI(AIトレンドの優れた分析で広く尊敬されている情報源)の公開推定値を使用して、2019年から2023年までのコンピュートスケールアップを追跡することができます。GPT-2からGPT-3へのスケールアップは迅速で、小規模な実験から大規模な言語モデルを訓練するためにデータセンター全体を使用するまでにスケールアップし、コンピュートのオーバーハングが大きくなりました。GPT-3からGPT-4へのスケールアップでは、次のモデルのためにまったく新しい(はるかに大きな)クラスタを構築しなければならないという、最新の体制に移行しました。それでも劇的な成長は続いています。エポックAIの試算によると、GPT-4のトレーニングでは、GPT-2の3,000倍から10,000倍の計算量を使用しています。
大雑把に言えば、これは長期的なトレンドの継続に過ぎない。過去10年半の間、主に投資(およびGPUやTPUの形でAIワークロードに特化したチップ)の幅広いスケールアップのため、フロンティアAIシステムに使用されるトレーニング計算量は、およそ〜0.5OOM/年で成長してきた。
https://situational-awareness.ai/wp-content/uploads/2024/06/compute_long_run_trend-1024x968.png
GPT-2からGPT-3への1年間のスケールアップは異例のオーバーハングであったが、長期的なトレンドが続くことは間違いない。SF-rumor-millは、巨額のGPU受注の劇的な話で一杯だ。その投資は並大抵のものではないが、動き始めている。
この分析によれば、2027年末までにさらに2OOMsのコンピュート(数十億ドル規模のクラスター)が実現する可能性は非常に高いと思われる。さらに+3OOMsのコンピュート(1,000億ドル規模以上)に近いクラスターも可能性がありそうだ(マイクロソフト/OpenAIで計画中と噂されている)。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute-1024x866.png
続き I.GPT-4からAGIへ:OOMを数える(5) https://anond.hatelabo.jp/20240605205449
子育て支援をいくら充実させても少子化には全く効果がないって結果出てるんだよな
つまり子育て支援で拡充された分は二人目以降ではなく一人の子供につぎ込まれてたってこと
やっぱ子育てって損得じゃん
フィッシャーは子を育てるコストを親の出費と呼んだ。フィッシャーの原理で重要な点は、進化的に安定な状態となるのは、子の数の性比が1:1の時ではなく、親がオスの子とメスの子へ振り分ける総出費の比が1:1になるときであると発見したことである。
Cmはオスを作るコスト、Mはオスの子数、Cfはメスを作るコスト、Fはメスの子数を表す。つまり、たとえばオスの子がメスよりも大きく成長する(しなければ性選択に勝てないなど)状況で、オスを育てるコストがメスの二倍になるのであれば、その動物ではオスの子の数はメスの半分に減るだろうということである。そして多くの動物ではこの予測がおおむね成り立っている事がわかっている。フィッシャーの親の出費(現在では「親の投資」と呼ばれる)の概念は、特にロバート・トリヴァーズによって洗練されて生態学の重要な概念となった。またこの予測を大きく外れるケースについてはハミルトンが『異常な性比』で論じている。
お父さん、お母さんが楽器を弾けるなら、以下の文は、釈迦に説法、孔子に論語、ラフマニノフにソナチネ、パガニーニにクロイツェル。(後ろの2つは聞けるものなら聞いてみたい。)
ガチで音大目指すとかそういうのじゃなく。子供に楽器を習わせている一人の親として。自分は趣味で楽器が弾けるだけ。業界の人でもプロでもない。
子供がピアノとか弾けたらいいなとか、バイオリンっひけたらかっこいいなとか。そんな感じで子供(4歳くらいから小学生低学年まで)に楽器を習わせたいなと思っている親御さんへ。
習わせる覚悟は犬を飼うのと同じと思ってね。親が思う、「趣味程度で楽器が弾けるといいな」になるには、最低10年、だいたい15年くらいは習わないと、そうならないと思う。
犬と違って、途中で辞めることはできるけど。
子供が「ピアノやだー」っていってても、レッスンには毎週連れて行って、うちで弾き始めたら「うまくなったね」って言って、だらだら続けていれば、いずれ楽しく弾けるようにはなると思う。
自分の子供にはピアノを習わせてる。5年生(女)と2年生(男)だけど、一緒に習っているお友達がだんだん辞めるようになってきた。
特に小学校低学年でかなりの割合の子が辞めちゃう。3~5年くらい習ってたことになるんだけど、それだとたぶん、この先は趣味でもピアノは弾けないと思う。楽譜も読めないと思う。
すごく勿体ない。その時間、別の習い事をしていればとさえ思う。辞める理由は、練習しなくなったとか、お金がかかるからとか。
発表会でもうちの子より上手に弾いてたのに、と思うと、本当に勿体ない。
楽しく自分のペースで弾けるようになるには、中学終わるくらいや高校生までかかると思う。そこまで続けば、しばらく休んでも再開できるし(手は動かなくなってるが)、楽譜もそこそこ読める。
いわゆる才能があって、小学生の間に、上手に弾けて楽譜も読める子は、たぶん辞めたくないっていうし、先生も引き留めるから、大丈夫。この話の対象ではない。
子供に楽器を練習させるには親の協力も必要だ。鈍感力(できなくてあたりまえ。家ではほぼ騒音)と、共感力(できたときに褒めるだけ)、忍耐力(練習していないままでもレッスンには連れて行く。)が必要だ。
それに加えて、やっぱりお金。毎月最低1万円くらい×12ヶ月×12年。だいたい150万円くらい。楽器代や楽譜などの教材費は除いてそれくらいはかかる。
よく、ピアノは中古でも高いとか、バイオリンは買い換えが・・・、とかいうけど、長期にかかる月謝も高い。
塾や習い事が増えてきて、お金もかかるし取捨選択を迫られたときに、どうしても楽器は辞める方向になりがちだ。お金を出しているのが、楽器を弾かないお父さんだった場合は特に。
でもちょっとまってやって。ここで辞めたら無になる。ここは、投資で言う「コンコルド効果」をいい意味で考えよう。「ここまで払った投資が無駄になる。きっと上向くはずだ。」
自分は4歳から高2までバイオリンを習ってた。親は楽器は弾けない。
中学生、高校生の時はほとんど練習せずに週Ⅰレッスンだけ行ってた。だから、同じ先生に習ってた同じくらいの年の子より数段下手。ソロで人に聞かせるレベルではない。
でもね、楽譜みながら、一応音は拾えるし(拾えたからといって弾けるとは限らないが)、楽器は楽しい。
妻は中学か高校までピアノを習ってた。大学の軽音楽部で知り合って結婚した。そのとき僕はバイオリンではなくウッドベース弾いてたけど。
子供に楽器を習わせてるのは、ただ1つ、大人になって楽しみが増えるから。一人でも楽しいし、数人集まっても楽しい。
スポーツと違って、対戦相手もいらない上に、仲間がいればもっと楽しい。ケガもしないし、遭難もしない。超平和。
居酒屋や喫茶店で、雑談してるような楽しさ。時間がすぐに無くなる。
ツイッターで批判されてるけど、上手い商売だと思うね。アートの勉強になるかは今後のAIイラストの普及次第だからわからないけど、大企業も着々とAIイラストを導入してるから可能性は無くもない。
ハナから頭ごなしに批判する人は感情論の否定しかしてないから説得力が無いし、否定する人のアカウントを見ると絵師じゃない、もしくは底辺の下手くそ絵師ばかりでこれまた説得力に欠ける。
「スケッチブックと鉛筆と消しゴムを買った方がアート経験積める」ってポストして伸びてた人のアカウント見ると2018年にアカウント開設して二次創作で1300人程度のフォロワー数しか獲得してないから、6年間(もっと長いかもしれんが)スケッチブックと鉛筆と消しゴムでアートを必死に学んでしかも二次創作で1300人程度のフォロワーしか獲得できない無駄な労力を費やすサンプルを見ちゃったら、
手っ取り早くAIアートのコツを掴んだ方が将来の可能性に投資するには有益だと思ってしまうな。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}