はてなキーワード: リリースとは
最後に、定量化するのが最も難しいが、それに劣らず重要な改善のカテゴリーを紹介しよう。
難しい数学の問題を解くように言われたとき、頭に浮かんだことを即座に答えなければならないとしたらどうだろう。最も単純な問題を除いて、苦労するのは明らかだろう。しかしつい最近まで、LLMにはそうやって数学の問題を解かせていた。その代わり、私たちのほとんどはスクラッチパッドで段階的に問題を解いていき、その方法ではるかに難しい問題を解くことができる。「思考の連鎖」プロンプトは、LLMのそれを解き放った。生の能力は優れているにもかかわらず、明らかな足かせがあるため、LLMは数学が苦手なのだ。
私たちはここ数年で、モデルの「足かせを外す」ことに大きな進歩を遂げました。これは単に優れたベースモデルをトレーニングするだけでなく、アルゴリズムの改良によってモデルの能力を引き出すものです:
足場作り。CoT++について考えてみよう:ただ問題を解くようモデルに求めるのではなく、あるモデルに攻撃計画を立てさせ、別のモデルに可能性のある解決策をたくさん提案させ、別のモデルにそれを批評させる、といった具合だ。例えば、HumanEval(コーディング問題)では、単純な足場作りによってGPT-3.5が足場なしのGPT-4を上回った。SWE-Bench(実世界のソフトウェアエンジニアリングのタスクを解くベンチマーク)では、GPT-4は~2%しか正しく解くことができませんが、Devinのエージェントの足場があれば14-23%に跳ね上がります。(後ほど詳しく説明するが、エージェントのアンロックはまだ初期段階に過ぎない。)
ツール:もし人間が電卓やコンピュータを使うことを許されなかったらと想像してみてほしい。まだ始まったばかりだが、ChatGPTはウェブブラウザを使ったり、コードを実行したりできるようになった。
エポックAIによる研究によると足場作りやツールの使用など、これらのテクニックのいくつかを調査したところ、このようなテクニックは多くのベンチマークで通常5~30倍の効果的な計算量の向上をもたらすことがわかった。METR(モデルを評価する組織)も同様に、同じGPT-4ベースモデルからのアンホブリングによって、エージェントタスクのセットで非常に大きなパフォーマンスの向上を発見しました。
https://situational-awareness.ai/wp-content/uploads/2024/06/metr_gains_over_time-1024x597.png
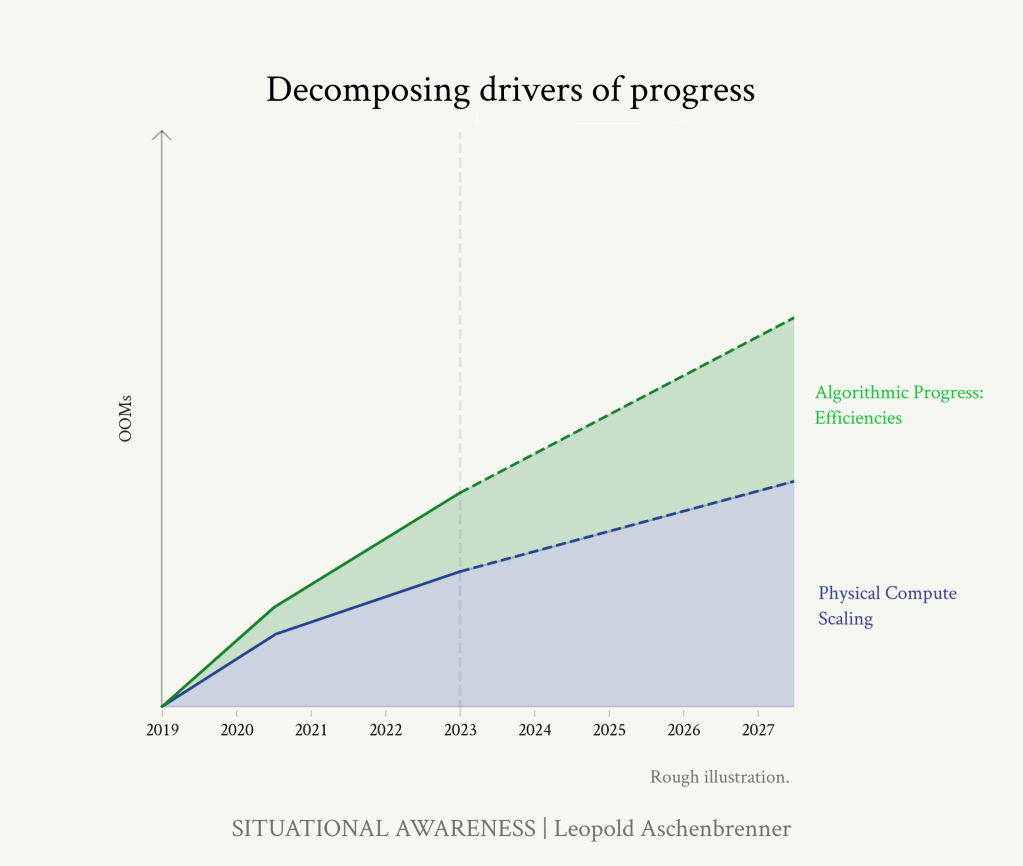
これらをコンピュートとアルゴリズムの効率で統一した実効的なコンピュート規模に当てはめることは困難ですが、少なくともコンピュート規模の拡大やアルゴリズムの効率とほぼ同規模の大きな進歩であることは明らかです。(また、アルゴリズムの進歩が中心的な役割を担っていることも浮き彫りになっています。0.5OOM/年の計算効率は、すでに重要なものではありますが、ストーリーの一部に過ぎません。)
「アンホブリング」こそが、実際にこれらのモデルが有用になることを可能にしたのであり、今日多くの商業アプリケーションの足かせとなっているものの多くは、この種のさらなる「アンホブリング」の必要性であると私は主張したい。実際、今日のモデルはまだ信じられないほど足かせが多い!例えば
ここでの可能性は非常に大きく、私たちはここで急速に低空飛行の果実を摘んでいる。これは非常に重要です。"GPT-6 ChatGPT "を想像するだけでは完全に間違っています。 GPT-6+RLHFと比べれば、進歩は段違いだ。2027年までには、チャットボットというより、エージェントのような、同僚のようなものが登場するだろう。
続き I.GPT-4からAGIへ:OOMを数える(8) https://anond.hatelabo.jp/20240605210232
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
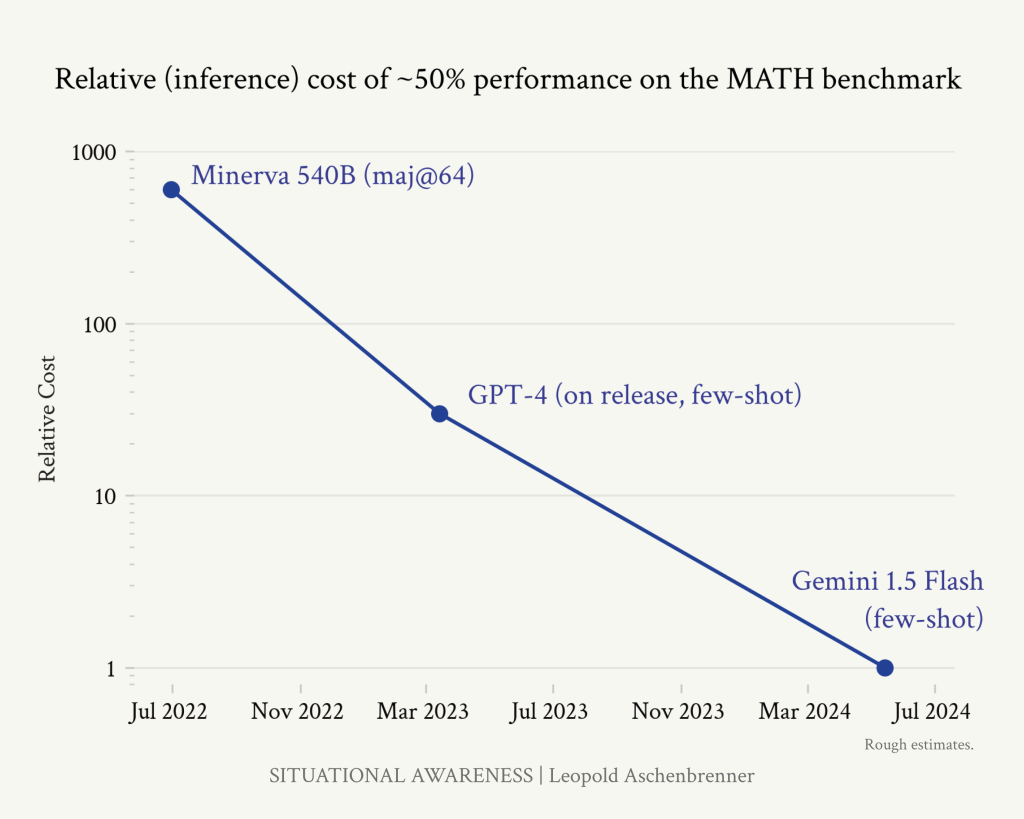
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
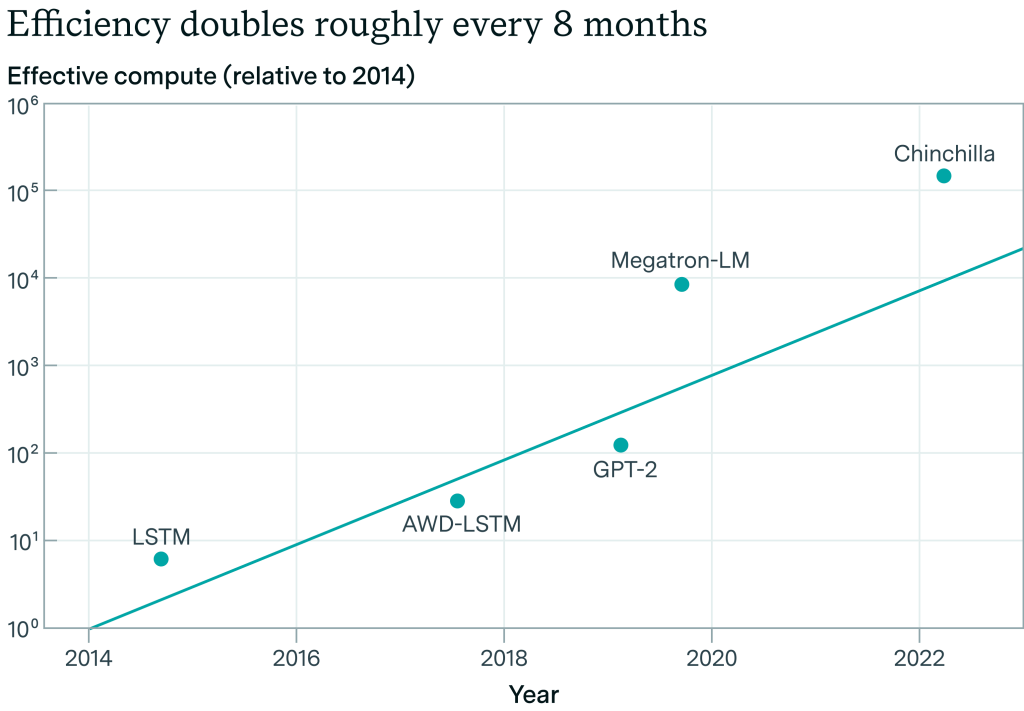
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
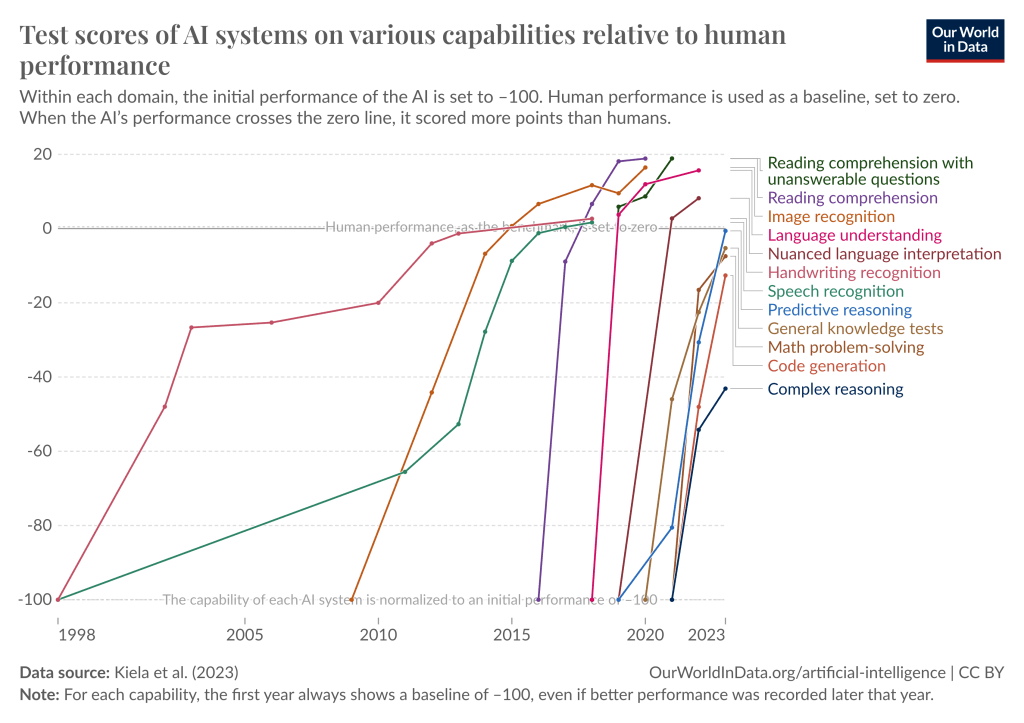
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
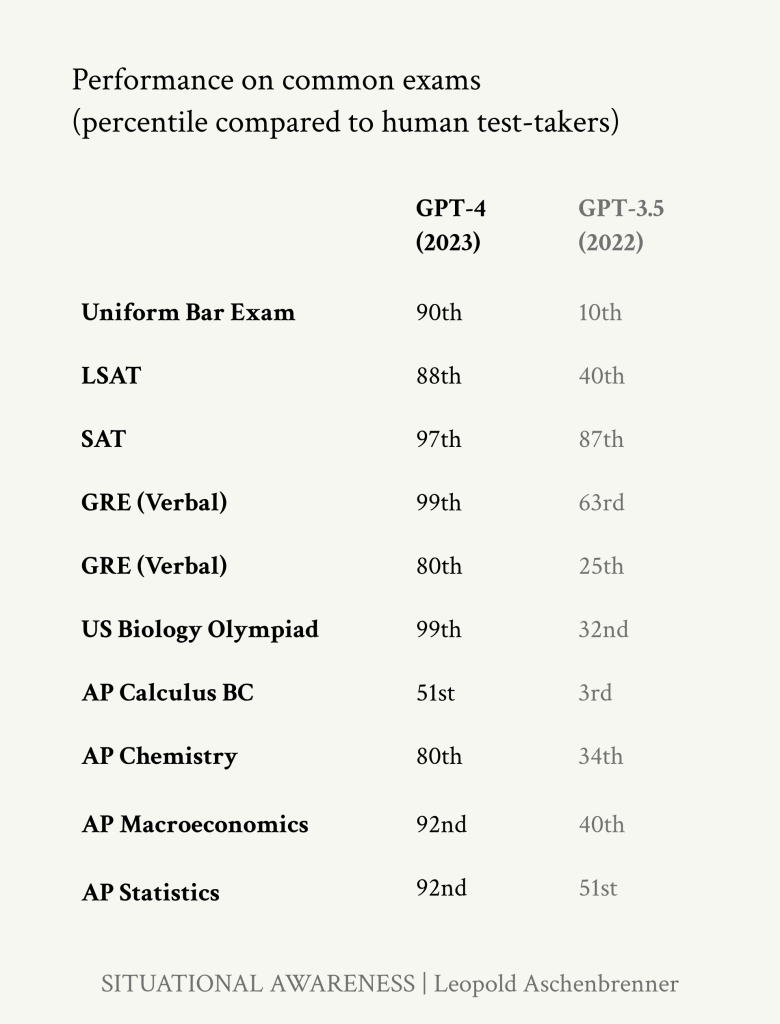
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
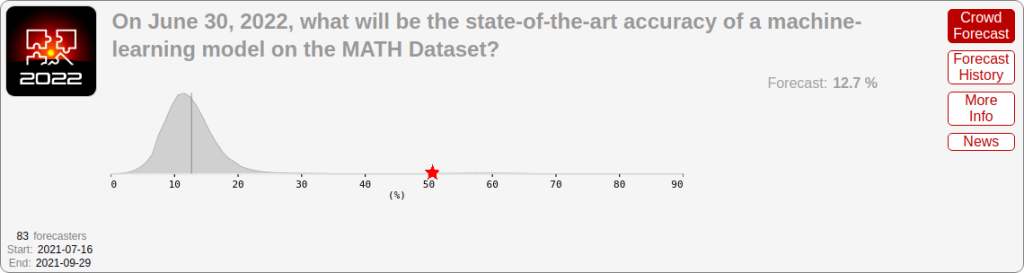
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
私たちは今、基本的に人間のように会話できるマシンを手にしている。これが普通に思えるのは、人間の適応能力の驚くべき証であり、私たちは進歩のペースに慣れてしまったのだ。しかし、ここ数年の進歩を振り返ってみる価値はある。
GPT-4までのわずか4年間(!)で、私たちがどれほど進歩したかを思い出してほしい。
GPT-2(2019年)~未就学児:"わあ、もっともらしい文章をいくつかつなげられるようになった"アンデス山脈のユニコーンについての半まとまりの物語という、とてもさくらんぼのような例文が生成され、当時は信じられないほど印象的だった。しかしGPT-2は、つまずくことなく5まで数えるのがやっとだった。記事を要約するときは、記事からランダムに3つの文章を選択するよりもかろうじて上回った。
当時、GPT-2が印象的だった例をいくつか挙げてみよう。左:GPT-2は極めて基本的な読解問題ではまあまあの結果を出している。右:選び抜かれたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争についてある程度関連性のあることを述べた、半ば首尾一貫した段落を書くことができる。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt2_examples-1024x493.png
当時、GPT-2について人々が印象に残った例をいくつか挙げます。左: GPT-2は極めて基本的な読解問題でまあまあの仕事をする。右: 厳選されたサンプル(10回試したうちのベスト)では、GPT-2は南北戦争について少し関連性のあることを言う、半ば首尾一貫したパラグラフを書くことができる。
AIの能力と人間の知能を比較するのは難しく、欠陥もあるが、たとえそれが非常に不完全なものであったとしても、ここでその例えを考えることは有益だと思う。GPT-2は、その言語能力と、時折半まとまりの段落を生成したり、時折単純な事実の質問に正しく答えたりする能力で衝撃を与えた。未就学児にとっては感動的だっただろう。
GPT-3(2020年)~小学生:"ワオ、いくつかの例だけで、簡単な便利なタスクができるんだ。"複数の段落に一貫性を持たせることができるようになり、文法を修正したり、ごく基本的な計算ができるようになった。例えば、GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt3_examples-1.png
GPT-3について、当時の人々が印象に残った例をいくつか挙げてみよう。上:簡単な指示の後、GPT-3は新しい文の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
GPT-3はSEOやマーケティング用の簡単なコピーを生成することができた。上:簡単な指示の後、GPT-3は新しい文章の中で作られた単語を使うことができる。左下:GPT-3は豊かなストーリーテリングを行ったり来たりできる。右下:GPT-3は非常に簡単なコードを生成できる。
繰り返しになるが、この比較は不完全である。しかし、GPT-3が人々に感銘を与えたのは、おそらく小学生にとって印象的だったことだろう。基本的な詩を書いたり、より豊かで首尾一貫した物語を語ったり、初歩的なコーディングを始めたり、簡単な指示やデモンストレーションからかなり確実に学習したり、などなど。
GPT-4(2023年)~賢い高校生:「かなり洗練されたコードを書くことができ、デバッグを繰り返し、複雑なテーマについて知的で洗練された文章を書くことができ、難しい高校生の競技数学を推論することができ、どんなテストでも大多数の高校生に勝っている。コードから数学、フェルミ推定まで、考え、推論することができる。GPT-4は、コードを書く手伝いから草稿の修正まで、今や私の日常業務に役立っている。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_examples-3.png
GPT-4がリリースされた当時、人々がGPT-4に感銘を受けた点をいくつか紹介しよう。上:GPT-4は非常に複雑なコードを書くことができ(中央のプロットを作成)、非自明な数学の問題を推論することができる。左下:AP数学の問題を解く。右下:かなり複雑なコーディング問題を解いている。GPT-4の能力に関する調査からの興味深い抜粋はこちら。
AP試験からSATに至るまで、GPT-4は大多数の高校生よりも良いスコアを出している。
もちろん、GPT-4でもまだ多少ばらつきがある。ある課題では賢い高校生よりはるかに優れているが、別の課題ではまだできないこともある。とはいえ、これらの限界のほとんどは、後で詳しく説明するように、モデルがまだ不自由であることが明らかなことに起因していると私は考えがちだ。たとえモデルがまだ人為的な制約を受けていたとしても、生のインテリジェンスは(ほとんど)そこにある。
https://situational-awareness.ai/wp-content/uploads/2024/06/timeline-1024x354.png
続き I.GPT-4からAGIへ:OOMを数える (3) https://anond.hatelabo.jp/20240605204704
2027年までにAGIが実現する可能性は極めて高い。GPT-2からGPT-4までの4年間で、私たちは〜未就学児から〜賢い高校生までの能力を手に入れた。計算能力(~0.5桁またはOOMs/年)、アルゴリズム効率(~0.5OOMs/年)、および「趣味のない」向上(チャットボットからエージェントへ)のトレンドラインをトレースすると、2027年までに再び未就学児から高校生規模の質的ジャンプが起こると予想される。
見て。モデルたちはただ学びたいだけなんだ。あなたはこれを理解しなければならない。モデルたちは、ただ学びたいだけなんだ。
GPT-4の能力は、多くの人に衝撃を与えた。コードやエッセイを書くことができ、難しい数学の問題を推論し、大学の試験を突破することができるAIシステムである。数年前までは、これらは難攻不落の壁だと思っていた。
しかしGPT-4は、ディープラーニングにおける10年間の猛烈な進歩の延長線上にあった。その10年前、モデルは犬猫の単純な画像を識別するのがやっとだった。4年前、GPT-2は半可通な文章をつなぎ合わせるのがやっとだった。今、私たちは思いつく限りのベンチマークを急速に飽和させつつある。しかし、この劇的な進歩は、ディープラーニングのスケールアップにおける一貫した傾向の結果に過ぎない。
ずっと以前から、このことを見抜いていた人々がいた。彼らは嘲笑されたが、彼らがしたのはトレンドラインを信じることだけだった。トレンドラインは強烈で、彼らは正しかった。モデルはただ学びたいだけなのだ。
私は次のように主張する。2027年までには、モデルがAIの研究者やエンジニアの仕事をこなせるようになるだろう、と。SFを信じる必要はなく、グラフ上の直線を信じるだけでいいのだ。
https://situational-awareness.ai/wp-content/uploads/2024/06/base_scaleup-1024x790.png
過去と将来の有効計算量(物理計算量とアルゴリズム効率の両方)の大まかな見積もり。モデルをスケールアップすればするほど、モデルは一貫して賢くなり、"OOMを数える "ことによって、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができます。(このグラフはベースモデルのスケールアップのみを示している。)
この記事で取り上げた一般的な推定に基づく、効果的な計算(物理的な計算とアルゴリズムの効率の両方)の過去と将来のスケールアップの概算。モデルをスケールアップするにつれ、モデルは一貫して賢くなり、「OOMを数える」ことで、(近い)将来に期待されるモデルのインテリジェンスの大まかな感覚を得ることができる。(このグラフはベースモデルのスケールアップのみを示している。"unobblings "は描かれていない)。
この作品では、単純に「OOMを数える」(OOM = order of magnitude、10x = 1 order of magnitude)ことにします。1)計算、2)アルゴリズム効率(「効果的な計算」の成長として考えることができるアルゴリズムの進歩)、3)「アンホブリング」(モデルがデフォルトで足かせとなっている明らかな方法を修正し、潜在的な能力を引き出し、ツールを与えることで、有用性を段階的に変化させること)の傾向を見ます。GPT-4以前の4年間と、GPT-4後の2027年末までの4年間に期待されるそれぞれの成長を追跡する。ディープラーニングが効率的な計算のすべてのOOMで一貫して向上していることを考えると、将来の進歩を予測するためにこれを使うことができる。
世間では、GPT-4のリリースから1年間、次世代モデルがオーブンに入ったままであったため、ディープラーニングは停滞し、壁にぶつかっていると宣言する人もいた。しかし、OOMをカウントすることで、私たちは実際に何を期待すべきかを垣間見ることができる。
結果は非常にシンプルだ。GPT-2からGPT-4への移行は、時々まとまりのある文章を並べることに感動的だったモデルから、高校入試のエースになるモデルへの移行であり、一度だけの進歩ではない。私たちはOOMsを極めて急速に克服しており、その数値は、4年以上かけてGPT-2からGPT-4への質的なジャンプをさらに~100,000倍の効果的なコンピュート・スケールアップが期待できることを示している。さらに、決定的なことは、それは単にチャットボットの改良を意味しないということだ。"unhobbling "利益に関する多くの明らかな低空飛行の果実を選ぶことで、チャットボットからエージェントへ、ツールからドロップイン・リモートワーカーの代替のようなものへと我々を導いてくれるはずだ。
推論は単純だが、その意味するところは注目に値する。このような別のジャンプは、私たちをAGIに、博士号や同僚として私たちのそばで働くことができる専門家と同じくらい賢いモデルに連れて行く可能性が非常に高い。おそらく最も重要なことは、これらのAIシステムがAI研究そのものを自動化することができれば、次回のテーマである強烈なフィードバック・ループが動き出すということである。
現在でも、このようなことを計算に入れている人はほとんどいない。しかし、AIに関する状況認識は、一歩下がってトレンドを見てみれば、実はそれほど難しいことではない。AIの能力に驚き続けるなら、OOMを数え始めればいい。
続き I.GPT-4からAGIへ:OOMを数える (2) https://anond.hatelabo.jp/20240605204240
別にかっこよくもない上に使いにくい。
どういう思考回路してたらあのデザインにGOサインが出るのか全く分からない。
もしかしてわざと公式サイトを不親切にして実店舗に客を誘導したいのか?って勘ぐってしまうぐらい使いにくい。
例えば、トップスを選べばその中のサブカテゴリ間は楽に移動できるけど、Tシャツの後にボトムス見ようとするとトップページに一度戻らないとたどり着けなくない?
その割には「WOMEN」、「MEN」、「KIDS」とかの最上位のカテゴリはいろんなページに配置されて切り替え可能なんだよな
そんなのよりその一段下の「トップス」、「パンツ」、「アウター」みたいなカテゴリをベージ内に配置してくれよ。
PCでもスマホでもそういう構造になってんだけど、意味不明だよな。
学マスの裏話配信が公式discord鯖であったらしく、そのまとめをみてたんだけど
その中で「リリース1年で110万ダウンロードが目標だった」って言われてたらしい
最近だとウマ娘やヘブバンとかだと1週間経たずに100万DL達成してたけど
私が住んでいるのは田舎だ。
それでも最後のプライドを示すかのようにデパートがひとつだけ残っている。
といっても平日は実に閑散としていて客の姿は一階のスーパーで見かける程度で、二階三階と階を登るにつれて人の姿は少なくなり、五階ともなれば人の行き来はほぼ見かけない。
おそらくこのデパートの寿命もそう長くはないだろう。その事に気づいた私は、平日の午後イチ、ネコバッグに猫を入れると五階に向かった。
一度、猫をエスカレーターに乗せてみたかったのだ。猫はエスカレーターに対して、どのような反応を見せるのか?一度考えるとその考えは頭から切り離されることはなく、頭の片隅に残り続けていた。
そして私はとうとうチャンスを見つけたのだ。
実行当日、予測通り人の姿はまばらで、五階にまで行くと誰もいない。
私は下りのエスカレーター前で素早く猫をリリースすると、猫はもっさりとした動作でネコバッグから降り立った。
それから猫は慎重に一歩、二歩と歩みを進ませると目の前に動く階段があることに気づき、不安そうに振り返って私を見つめた。
私は手短にエスカレーターの説明をした。これはエスカレーターといって、まあ動く階段のようなものだよと。
猫は要領を得ない様子で首をかしげ、乗ってみたら?と声をかけた。しかし猫はまだ怖いようで、立ち往生している。乗り方が分からないのだろうと思い、手本を見せようと私は前に躍り出てエスカレーターに乗った。ほら、こうして乗るんだよ。大丈夫だからおいで。それでも猫は二の足を踏み、私との距離はどんどん離れていく。
私は不安になり、大丈夫だからおいで、と声をかけ続けたが猫は動じない。猫の姿はみるみる小さくなっていき、猫も不安そうにエスカレーターの前を行ったり着たりしている。
いよいよ猫の姿が消えそうになったとき、私は猫の名前を呼んだ。すると猫は飛び込むようにエスカレーターに乗り、そのまま駆け込むように下った。
すごいスピードだ!
エスカレーターの速度と猫の速度が合わさり、猫は光のような速さでエスカレーターを下ると私に追いつき、私に抱きついてきた。
猫は興奮し、緊張していたのかドキドキという心拍音が直に伝わってきた。
私はエスカレーターを下りきる前に素早く猫をネコバッグにしまい、それから何事もなかったように一階まで下るとデパートを後にした。
猫はネコバッグから頭を出し、振り返るようにデパートを見やった。私も興奮していたが、猫も興奮していたのだ。
それから猫は「にゃあ」と一度だけ鳴き、バッグの中へと戻っていった。私はもう振り返らず、帰路に着いた。
ここは過疎地だ。駅前の商店街は降りたシャッターの数の方が多い。デパートの寿命もいつ切れてもおかしくはない。それでももう、私には思い残すことはなかった。
NewJeansが「Bubble Gum」って新曲出したんだけど(※1)、どうも今までと比べて大人しすぎる曲で、聞いてもピンとこなかったところに、韓国の音楽オタが「1995年にリリースされた『Bubble Gum』」というコンセプトで楽曲をアレンジして投稿した(※2)。イントロや間奏にサックスのメロディが入って、見事に1995年のポップスに変貌していた。おっさんたちがNewJeansに求めていたものはこっちだった。コメント欄によれば、KPOPでも90年代前半にはサックスやトランペットの間奏曲のヒット曲があり、DEUXの「夏の中で」(※3)という歌を思い出したという声もあった。
※1.NewJeans (뉴진스) 'Bubble Gum' Official MV - YouTube
https://www.youtube.com/watch?v=ft70sAYrFyY
※2.NewJeans (뉴진스) - 'Bubble Gum' (1995) - YouTube
https://www.youtube.com/watch?v=QnKXYuLGuMM
※3.듀스 여름안에서 (가사 첨부) - YouTube
私が住んでいるのは田舎だ。
それでも最後のプライドを示すかのようにデパートがひとつだけ残っている。
といっても平日は実に閑散としていて客の姿は一階のスーパーで見かける程度で、二階三階と階を登るにつれて人の姿は少なくなり、五階ともなれば人の行き来はほぼ見かけない。
おそらくこのデパートの寿命もそう長くはないだろう。その事に気づいた私は、平日の午後イチ、ネコバッグに猫を入れると五階に向かった。
一度、猫をエスカレーターに乗せてみたかったのだ。猫はエスカレーターに対して、どのような反応を見せるのか?一度考えるとその考えは頭から切り離されることはなく、頭の片隅に残り続けていた。
そして私はとうとうチャンスを見つけたのだ。
実行当日、予測通り人の姿はまばらで、五階にまで行くと誰もいない。
私は下りのエスカレーター前で素早く猫をリリースすると、猫はもっさりとした動作でネコバッグから降り立った。
それから猫は慎重に一歩、二歩と歩みを進ませると目の前に動く階段があることに気づき、不安そうに振り返って私を見つめた。
私は手短にエスカレーターの説明をした。これはエスカレーターといって、まあ動く階段のようなものだよと。
猫は要領を得ない様子で首をかしげ、乗ってみたら?と声をかけた。しかし猫はまだ怖いようで、立ち往生している。乗り方が分からないのだろうと思い、手本を見せようと私は前に躍り出てエスカレーターに乗った。ほら、こうして乗るんだよ。大丈夫だからおいで。それでも猫は二の足を踏み、私との距離はどんどん離れていく。
私は不安になり、大丈夫だからおいで、と声をかけ続けたが猫は動じない。猫の姿はみるみる小さくなっていき、猫も不安そうにエスカレーターの前を行ったり着たりしている。
いよいよ猫の姿が消えそうになったとき、私は猫の名前を呼んだ。すると猫は飛び込むようにエスカレーターに乗り、そのまま駆け込むように下った。
すごいスピードだ!
エスカレーターの速度と猫の速度が合わさり、猫は光のような速さでエスカレーターを下ると私に追いつき、私に抱きついてきた。
猫は興奮し、緊張していたのかドキドキという心拍音が直に伝わってきた。
私はエスカレーターを下りきる前に素早く猫をネコバッグにしまい、それから何事もなかったように一階まで下るとデパートを後にした。
猫はネコバッグから頭を出し、振り返るようにデパートを見やった。私も興奮していたが、猫も興奮していたのだ。
それから猫は「にゃあ」と一度だけ鳴き、バッグの中へと戻っていった。私はもう振り返らず、帰路に着いた。
ここは過疎地だ。駅前の商店街は降りたシャッターの数の方が多い。デパートの寿命もいつ切れてもおかしくはない。それでももう、私には思い残すことはなかった。
去年破産したゲームエイジ総研なんかよりSensor Towerの方が信用出来ると思うけど
勝利の女神:NIKKEがリリース7ヵ月で世界累計収益4億ドルを突破、日本が最大の市場で60%近くを占める
《블루 아카이브》 서비스 3주년 이벤트로 매출 5억 달러 달성… 경쟁사보다 높은 참여도로 성공적인 IP 확장
(《ブルーアーカイブ》サービス3周年記念イベントで売上5億ドル達成...競合他社より高い参加率でIP拡大に成功)
일본 시장 매출 상위에 있는 모바일 스쿼드 RPG의 성비에서 《블루 아카이브》는 여성 41%, 남성 59%로 다른 상위 게임보다 균등한 성비를 확인할 수 있습니다.
(日本市場の売上上位のモバイルスクワッドRPGの男女比では、『ブルーアーカイブ』は女性41%、男性59%と、他の上位ゲームよりも均等な男女比を確認することができます。)
2019年にリリースされたスマートフォンゲーム「アークナイツ」がターニングポイントだと言われている。「アークナイツ」はアニメ調グラフィックで、世界観やキャラクターに重点を置いた、このジャンルの典型的なゲームだったが、NARUTOなどの”一般向け”ゲームと同じ規模の収益を達成した。
アークナイツの成功がきっかけで、中国の二次元ゲーム業界は「大衆化(一般化)こそが大金を稼げる道」だと信じるようになったという。
しかし、それまでオタクゲーマーだけを相手にしていた中国のアニメ系スマホゲームはここに大きな矛盾を抱えてしまうことになる。大衆化を目指すために、大衆に受け入れられない要素は排除し、幅広いユーザー層に対応できるものを用意しなければならなくなったのだ。
有男不玩の記事画像にアークナイツが使われてるのはどういうことだよと思ったらそういうことか
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}