はてなキーワード: 入力とは
パスポートが必要になったので、先月有給を取って申請書をもらいにいったり戸籍謄本を取ったりして、
前日になって家族に「マイナンバーカードでオンライン申請できるっぽいよ?」と言われた。
明日の休みを別のことに使えるな、と思い始めて早速ウキウキで申請をし始めたが、もうだめ。
全然簡単じゃないし、手間はかかるし、突然あれもこれも用意しろといわれる。
スマホにアプリを入れたくなかったので、パソコンで申請を始めたのだが、
やり始めてから署名画像を作ったり、結局スマホにアプリを登録しなきゃならなかったり、
行ったり来たりしなきゃならなかったり、めちゃくちゃ面倒くさい!!!!!
スマホでの認証画面が始まってあたふたしてるうちにブラウザがタイムアウトですもう一度といわれてブチ切れている。
ここまで!!!!8画面も!!!!!入力してきたのをもう一度か!?!?!!?!?!
というわけで、一度整理します。
これは最初からわかっていたので、写真をココで作った。すげー便利。→https://photobooth.online/ja-jp/japanese-passport-photo
2.署名を用意する
それさぁ、普通にフォトショップいじる人とか、普段からお絵かきソフト使ってる人ならわかるかもしれないけど、
ピクセル数指定して、JPGでハイどうぞ!って言ったって突然すぎてできなくない?
スマホにアプリを極力増やしたくない民なので、マジでイミフだった。結局アプリはDLした。
で、8画面くらい遷移してスマホのアプリ入れてそっちの手続きもわかりづらい。
ログインしないでQRを読み込めというのなら、なぜログインボタンをでかでかと出すんだ!!
ログインしなきゃないのかな?とおもってログインしたらQRの読み込み画面がないんですよ、なんでだよ。
で、やっとQR読み込んでスマホに「パソコンの画面に戻って下さい」ってかいてあるからパッと顔をあげてパソコン見たのね?
すげー頭にきたから、いったん風呂入ってからもう一度やり直すつもりなんだけど、
今の時点で思ったことをいろいろ書き出しておく。
スマホで申請の場合はスマホでそのまま写真を撮れるので問題ないのかもしれないが、
スマホのカメラでは歪んでしまってブサイクに映るし、家族6人分を一気に申請したかったので、
なので、パソコンでの申請に限った話になるので、そこはご了承下さい。
〇写真を作成するのところで、写真のトリミング機能などを付けてほしい。
アップロードした写真が駄目だ、と言われたら、そこでトリミングをし直せるようにできたらその場で完結するのに、とおもった。
マウスでその場でかけたり、ペンで書くなり、トリミングをし直せたり、
その辺の、「マイナポータル」から移動しないで作れる仕組みにしてほしい。
なお、自分の場合は署名アップ画面になってから、家族に名前をコピー用紙に書かせて、それをスキャンして指定のサイズの画像にするという作業をした。
カードリーダーにマイナンバーカード読み込ませて申請してるのに、いちいちスマホで読み取らせる意味はなに??
あっちこっち行かせるのイクナイ!!
というわけで、もしこれがデジ庁に届くのであれば、お願いしたいのが3つ。
3.申請ボタンを押す前に、コレとコレを用意しましたか?みたいなものを文字ではなく画像で説明してくれ。
以上です。
なお、申請開始して頓挫まで20分、この文章を書くのに13分かかっている。
この後まだ5人分の申請が控えているので、もうこれは明日の休みにセンターに行って申請する方が早いような気がしてきている…
家から15分で行けるんだよ…。
風呂に入ってくるわ。
これはおそらく3つの中で最も簡単な方法だ。現在のChatGPTは、基本的に、テキストを入力できる孤立した箱の中に座っている人間のようなものだ。初期のアンホブリング改良では、個々の孤立したツールの使い方をモデルに教えていましたが、マルチモーダルモデルでは、近いうちにこれを一挙にできるようになると期待しています。
つまり、Zoomでの通話に参加したり、オンラインで調べ物をしたり、メッセージや電子メールを送ったり、共有されたドキュメントを読んだり、アプリや開発ツールを使ったりといったことだ。(もちろん、より長いホライゾン・ループでモデルがこれを最大限に活用するためには、テスト時間のコンピューティングをアンロックする必要がある。)
最終的には、ドロップイン・リモートワーカーのようなものができると期待している。エージェントは、あなたの会社に入社し、新しい人間の雇用のようにオンボードされ、Slackであなたや同僚にメッセージを送り、あなたのソフトウェアを使用し、プルリクエストを行い、大きなプロジェクトがあれば、人間が独立してプロジェクトを完了するために数週間留守にするのと同等のことができる。これを実現するためには、GPT-4よりもいくらか優れたベースモデルが必要だろうが、おそらくそれほどでもないだろう。
https://situational-awareness.ai/wp-content/uploads/2024/06/devin.gif
Devinは、完全に自動化されたソフトウェア・エンジニアを作るために、モデル上の「エージェンシー・オーバーハング」/「テストタイム・コンピューティング・オーバハング」を解除する初期のプロトタイプだ。Devinが実際にどの程度機能するかはわからないし、このデモは、適切なチャットボット→エージェントのアンホブリングがもたらすものに比べれば、まだ非常に限定的なものだが、近々登場するもののティーザーとしては役に立つだろう。
ところで、私は、アンホブリングの中心性が、商業的応用という点で、少々興味深い「ソニックブーム」効果につながると期待している。現在とドロップイン・リモートワーカーの中間モデルは、ワークフローを変更し、統合して経済的価値を引き出すためのインフラを構築するために、膨大な手間を必要とする。ドロップイン・リモートワーカーは、統合が劇的に簡単になる。つまり、リモートでできるすべての仕事を自動化するために、ドロップインするだけでいいのだ。つまり、ドロップイン・リモートワーカーが多くの仕事を自動化できるようになる頃には、中間モデルはまだ完全に活用され統合されていないため、生み出される経済価値のジャンプはやや不連続になる可能性がある。
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_gpt2togpt4.png
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_ooms_2023to2027.png
数字をまとめると、GPT-4に続く4年間で、2027年末までにGPT-2からGPT-4規模のジャンプが再び起こると(おおよそ)予想される。
GPT-4のトレーニングに3ヶ月かかったとしよう。2027年には、一流のAIラボはGPT-4レベルのモデルを1分で訓練できるようになるだろう。OOMの効果的なコンピュート・スケールアップは劇的なものになるだろう。
それは我々をどこへ連れて行くのだろうか?
https://situational-awareness.ai/wp-content/uploads/2024/06/overview_counting_the_ooms.png
GPT-2からGPT-4までで、私たちは~未就学児から~賢い高校生になった。とんでもないジャンプだ。もしこれが、私たちが今一度カバーする知能の差だとしたら、それは私たちをどこに連れて行くのだろうか?私たちは、それが私たちをとてもとても遠くに連れていっても驚かないはずだ。おそらく、ある分野の博士や最高の専門家を凌駕するようなモデルまで到達するだろう。
(このことを考える1つの良い方法は、現在のAIの進歩の傾向は、子供の成長のおよそ3倍のペースで進んでいるということだ。あなたの3倍速の子どもは高校を卒業したばかりだが、いつの間にかあなたの仕事を奪っていくだろう!)
続き I.GPT-4からAGIへ:OOMを数える(10) https://anond.hatelabo.jp/20240605211837
コンピュートへの大規模な投資が注目される一方で、アルゴリズムの進歩も同様に重要な進歩の原動力であると思われる(そして、これまで劇的に過小評価されてきた)。
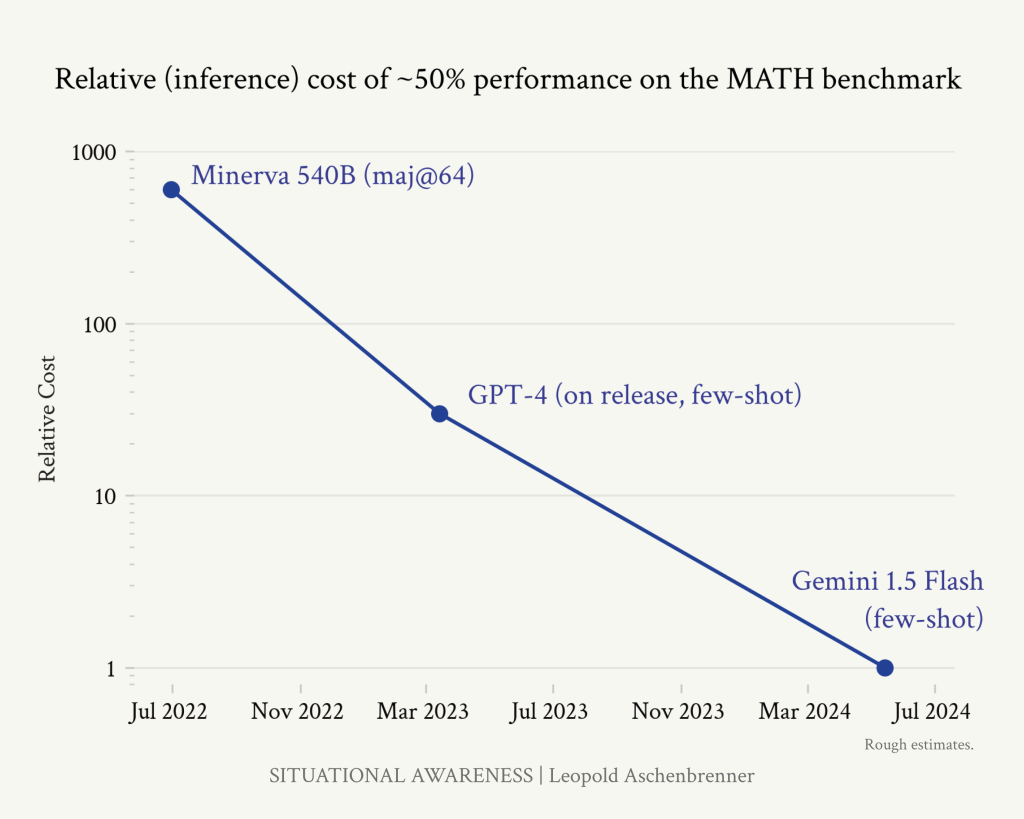
アルゴリズムの進歩がどれほど大きな意味を持つかを理解するために、MATHベンチマーク(高校生の競技用数学)において、わずか2年間で~50%の精度を達成するために必要な価格が下がったことを示す次の図を考えてみてください。(比較のために、数学が特に好きではないコンピュータサイエンスの博士課程の学生が40%のスコアを出したので、これはすでにかなり良いことです)。推論効率は2年足らずで3OOMs-1,000倍近く向上した。
https://situational-awareness.ai/wp-content/uploads/2024/06/math_inference_cost-1024x819.png
これは推論効率だけの数字だが(公開データから推論するのが難しいトレーニング効率の向上と一致するかどうかはわからない)、アルゴリズムの進歩は非常に大きく、また実際に起こっている。
この記事では、アルゴリズムの進歩を2種類に分けて説明します。まず、「パラダイム内」でのアルゴリズムの改良を取り上げることにしま す。例えば、より優れたアルゴリズムによって、同じパフォーマンスを達成しながら、トレーニングの計算量を10倍減らすことができるかもしれません。その結果、有効計算量は10倍(1OOM)になります。(後ほど「アンホブリング」を取り上げますが、これはベースモデルの能力を解き放つ「パラダイム拡張/アプリケーション拡張」的なアルゴリズムの進歩と考えることができます)。
一歩下がって長期的な傾向を見ると、私たちはかなり一貫した割合で新しいアルゴリズムの改良を発見しているようです。しかし、長期的なトレンドラインは予測可能であり、グラフ上の直線である。トレンドラインを信じよう。
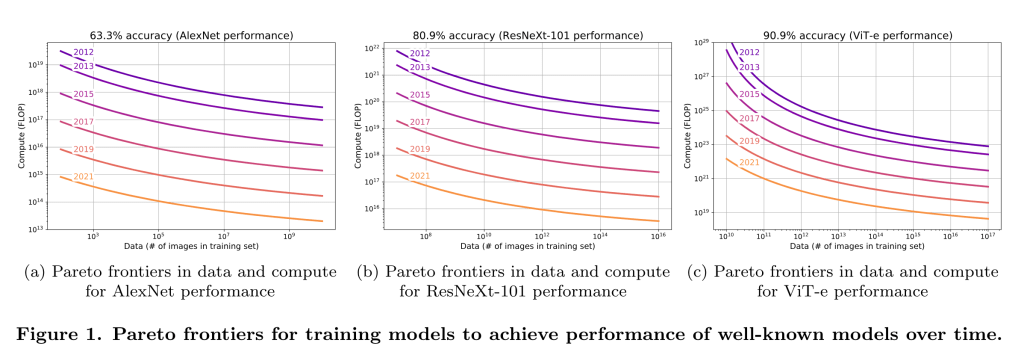
アルゴリズム研究がほとんど公開されており、10年前にさかのぼるデータがある)ImageNetでは、2012年から2021年までの9年間で、計算効率が一貫して約0.5OOM/年向上しています。
アルゴリズムの進歩を測定することができます。同じ性能のモデルを訓練するために必要な計算量は、2012年と比較して2021年にはどれくらい少なくなっているのでしょうか?その結果、アルゴリズムの効率は年間0.5 OOMs/年程度向上していることがわかります。出典Erdil and Besiroglu 2022.
これは非常に大きなことです。つまり、4年後には、~100倍少ない計算量で同じ性能を達成できるということです(同時に、同じ計算量ではるかに高い性能も達成できます!)。
残念ながら、研究室はこれに関する内部データを公表していないため、過去4年間のフロンティアLLMのアルゴリズムの進歩を測定することは難しい。EpochAIは、言語モデリングに関するImageNetの結果を再現した新しい研究を行っており、2012年から2023年までのLLMのアルゴリズム効率のトレンドは、同様に~0.5OOM/年であると推定しています。(しかし、これはエラーバーが広く、また、主要なラボがアルゴリズム効率の公表を停止しているため、最近の上昇を捕捉していません)。
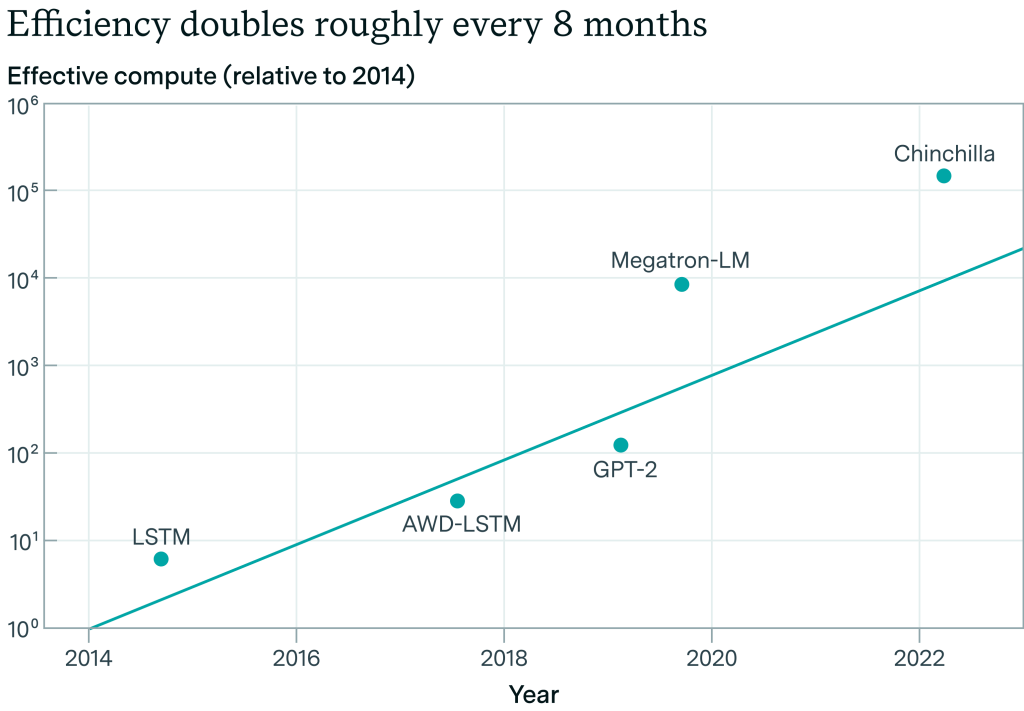
https://situational-awareness.ai/wp-content/uploads/2024/06/llm_efficiency_epoch-1-1024x711.png
Epoch AIによる言語モデリングにおけるアルゴリズム効率の推定。この試算によると、私たちは8年間で~4OOMの効率向上を達成したことになります。
より直接的に過去4年間を見ると、GPT-2からGPT-3は基本的に単純なスケールアップでした(論文によると)が、GPT-3以降、公に知られ、公に干渉可能な多くの利益がありました:
最近リリースされたGemini 1.5 Flashは、"GPT-3.75レベル "とGPT-4レベルの間の性能を提供する一方で、オリジナルのGPT-4よりも85倍/57倍(入力/出力)安い(驚異的な利益!)。
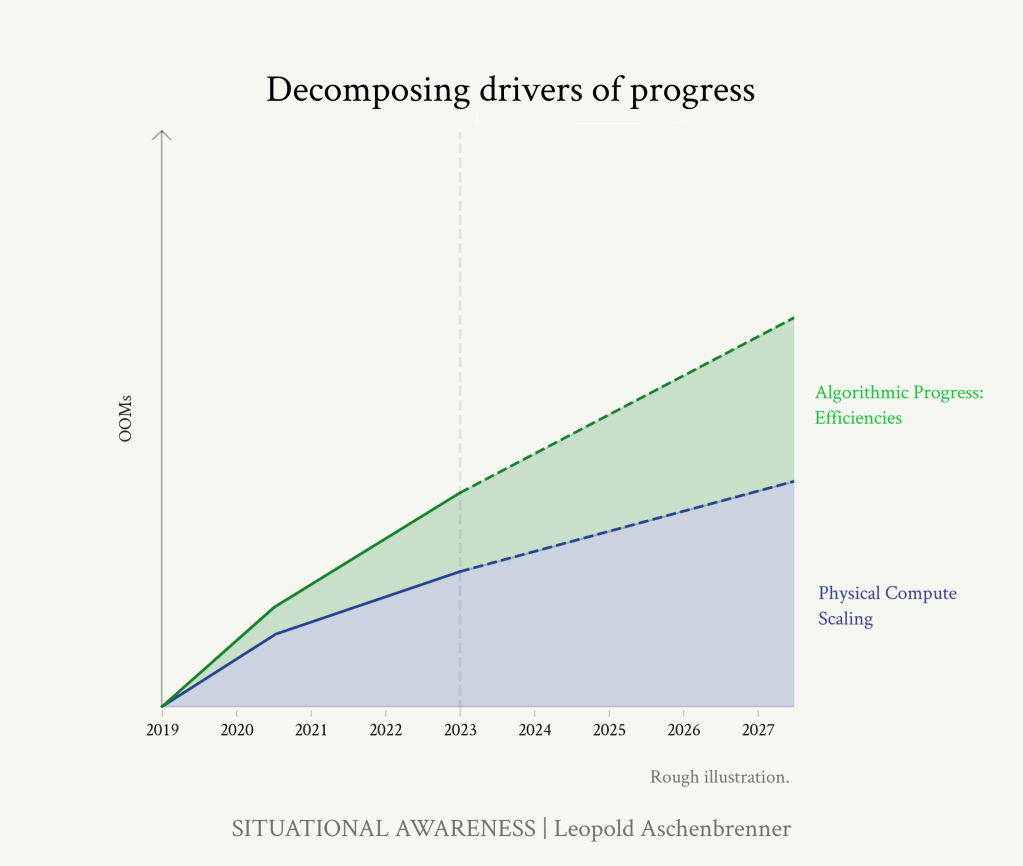
公開されている情報を総合すると、GPT-2からGPT-4へのジャンプには、1-2 OOMのアルゴリズム効率向上が含まれていたことになります。
https://situational-awareness.ai/wp-content/uploads/2024/06/stacked_compute_algos-1024x866.png
GPT-4に続く4年間はこの傾向が続くと予想され、2027年までに平均0.5OOMs/年の計算効率、つまりGPT-4と比較して~2OOMsの向上が見込まれます。計算効率の向上は、低空飛行の果実を摘み取るようになるにつれて難しくなる一方、新たなアルゴリズムの改良を見出すためのAIラボの資金と人材への投資は急速に増加しています。 (少なくとも、公開されている推論コストの効率化は、まったく減速していないようだ)。ハイエンドでは、より根本的な、トランスフォーマーのようなブレークスルーが起こり、さらに大きな利益が得られる可能性さえある。
これらをまとめると、2027年末までには(GPT-4と比較して)1~3OOMのアルゴリズム効率向上が期待できることになります。
続き I.GPT-4からAGIへ:OOMを数える(6) https://anond.hatelabo.jp/20240605205754
結婚相談所のプロフィールだと、体重は男女とも入力必須になっているよ。恐ろしいことにね。
ユーザーがある特定のアイテムをクリックしたという情報があったときに、そのアイテムの属性に関連するアイテムを推薦してほしいわけね
で、具体的にはコンテンツベース推薦を使ってて、アイテムを100次元のベクトルに圧縮してANNで検索してるから、実際に抽出してみるまでは「どういう入力にどういう出力をするか」ってのがわからない
誰かにプロトタイプを使ってもらって「入力Aに対して出力Bが得られる例はない?」などと言われることがあるだろう
例えばレコメンダシステムでは、ユーザーの行動を入力としてアイテムを出力する
「こういう行動をした場合と、してない場合で、こういうアイテムの違いが想定されて欲しい」という要望が出てくるのである
そういう場合は、可能な行動の組み合わせを全て網羅して、それらを関数に自動的に入力し、その出力をファイルとして出すなどして見てもらって自動化したほうが良い
要するに、プロトタイプをポチポチ触るだけでは効率が悪い場合は、入力の組み合わせを自動入力してしまったほうが早いわけである
もし出力に条件があれば、その条件をフィルタリングすることも可能だろう
そのため、自動化が必要かどうか、またどの程度の自動化が適切かを判断するためには、テストの目的と範囲、そして利用可能なリソースを考慮することが重要
https://news.yahoo.co.jp/articles/2fb2830c67da67b34682e33b59e1a383b451a85e
「身長、最終学歴、仕事内容、所得など15項目の個人情報も、事前入力して相手が見られるようにする。」
じゃあなんで身長っていう本人の努力でどうしようもないことでフィルターするのがおかしくないと思ってんだ。
あとな!朝日新聞!
「身長でのフィルターは議論を呼びそうだ。」くらいは書けないのか?いつもやってんだろうが!
>確かにいくつかコミュニケーション上の問題があったりすることは多い
>足りないコミュニケーションを偏見で補ってしまい相手の地雷を踏むことがままある
これが全てだろうな
世の中には「自分の衝動をぶつけるのに人間のナリをしていることが必要」な人間がいて、
そういう人間は相手の内面を見るのが不得手だし、偏見に気づかず相手の地雷を踏みぬくような「コミュニケーション」を平気でやらかし
そういう人間には、
自分を満足させる応答を(自分が応答を入力しなくとも)返してくる装置として、
でもそれを「人間扱いしない」ともいう、
仮に奴隷の主人に「奴隷を人間扱いしてください」と言ったなら、
「私は奴隷を人間扱いしているよ、なぜなら奴隷に任せている労働は彼らでなくてはこなせないからね、
機械は高価だしメンテナンスが必要だし、それに比べて奴隷は口で命じればいいし維持費が安いし要らなくなったら売れるから人間である必要があるんだよ、
と返してくるはずだ
人間は、人間扱いしていれば、目の前の相手を見ようとするものだと自分は思う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}