はてなキーワード: mLとは
今後数年間の野心的なアンホブリングはどのようなものになるのでしょうか?私が考えるに、3つの重要な要素がある:
GPT-4は、多くの人の仕事の大部分をこなせるだけの生の賢さを持っているが、それは5分前に現れたばかりの賢い新入社員のようなものだ:関連するコンテキストを持っておらず、会社のドキュメントやSlackの履歴を読んだり、チームのメンバーと会話したり、会社内部のコードベースを理解するのに時間を費やしたりしていない。賢い新入社員は、着任して5分後にはそれほど役に立たないが、1ヶ月後にはかなり役に立つ!例えば、非常に長いコンテクストを通じて、新しい人間の同僚を雇うようにモデルを「オンボード」することは可能なはずだ。これだけでも、大きなアンロックになるだろう。
2.テスト時間の計算オーバーハング(より長いホライズンの問題に対する推論/エラー訂正/システムII)
今のところ、モデルは基本的に短いタスクしかこなせない。しかし、これでは非常に限界がある。5分どころか、数時間、数日、数週間、数ヶ月かかるのだ。
難しい問題について5分間しか考えることができない科学者は、科学的なブレークスルーを起こすことはできない。ソフトウェア・エンジニアは、より大きな仕事を与えられ、計画を立て、コードベースや技術ツールの関連部分を理解し、さまざまなモジュールを書いて段階的にテストし、エラーをデバッグし、可能性のある解決策を検索し、最終的には数週間の仕事の集大成である大規模なプル・リクエストを提出する。などなど。
要するに、テスト時間の計算オーバーハングが大きいのだ。GPT-4の各トークンは、問題を考えるときの内部モノローグの言葉だと考えてください。各GPT-4トークンは非常に賢いのですが、現在のところ、思考の連鎖のために~数百トークンのオーダーしか効果的に使うことができません(あたかも問題やプロジェクトに数分しか内部独白/思考を費やせないかのように)。
もし数百万トークンを使って、本当に難しい問題や大きなプロジェクトについて考え、取り組むことができるとしたらどうだろう?
| トークンの数 | 私が何かに取り組むのに相当する時間... | |
| 100s | 数分 | ChatGPT (私たちはここにいる) |
| 1000s | 30分 | +1 OOMsテスト時間計算 |
| 10,000 回 | 半日 | +2 OOMs |
| 100,000ドル | 1週間 | +3 OOMs |
| 数百万回 | 複数月 | +4 OOMs |
人間が〜100トークン/分で考え、40時間/週働くと仮定して、「モデルが考える時間」をトークンで換算すると、与えられた問題/プロジェクトにおける人間の時間になる。
仮に「トークンあたり」の知能が同じだったとしても、頭のいい人が問題に費やす時間が数分なのか数ヶ月なのかの違いになる。あなたのことは知らないが、私が数ヶ月でできることと数分でできることは、はるかに、はるかに、はるかに多い。もしモデルに「数分ではなく、数カ月に相当する時間、何かを考え、取り組むことができる」という能力を与えることができれば、その能力は飛躍的に向上するだろう。ここには膨大なオーバーハングがある。
今のところ、モデルにはまだこれができない。最近のロング・コンテキストの進歩をもってしても、このロング・コンテキストのほとんどはトークンの消費にしか機能せず、トークンの生産には機能しない。しばらくすると、このモデルはレールから外れたり、行き詰まったりする。しばらくの間、離れて単独で問題やプロジェクトに取り組むことはまだできない。
しかし、テスト時間の計算を解除することは、単に比較的小さな「ホブリングしない」アルゴリズムの勝利の問題かもしれない。おそらく、少量のRLは、モデルがエラー訂正(「うーん、これは正しくないようだ、再確認してみよう」)を学習したり、計画を立てたり、可能性のある解を探索したりするのに役立つだろう。ある意味、モデルはすでに生の能力のほとんどを持っており、それをまとめるために、さらにいくつかのスキルを学習する必要があるだけなのだ。
要するに、私たちはモデルに、困難で見通しの長いプロジェクトを推論させるシステムIIのアウターループのようなものを教えればいいのだ。
この外側のループを教えることに成功すれば、2、3段落の短いチャットボットの答えの代わりに、モデルが問題を考え、ツールを使い、異なるアプローチを試し、研究を行い、仕事を修正し、他の人と調整し、大きなプロジェクトを一人で完成させるような、何百万もの言葉のストリーム(あなたが読むよりも早く入ってくる)を想像してみてほしい。
続き I.GPT-4からAGIへ:OOMを数える(9) https://anond.hatelabo.jp/20240605210357
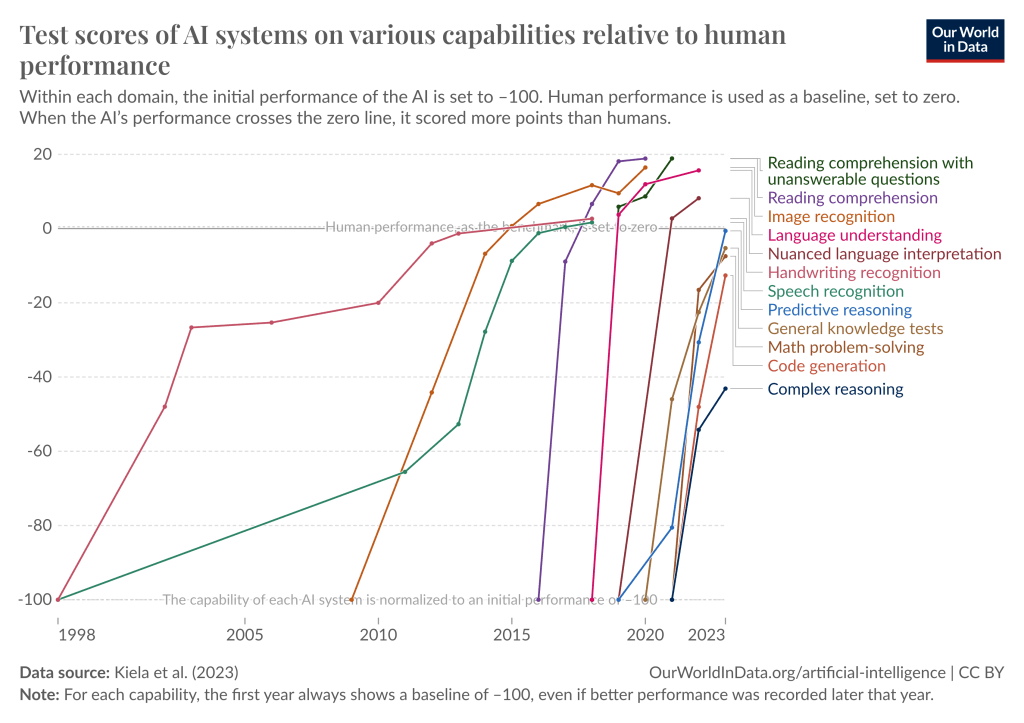
過去10年間のディープラーニングの進歩のペースは、まさに驚異的だった。ほんの10年前、ディープラーニング・システムが単純な画像を識別することは革命的だった。今日、我々は斬新でこれまで以上に難しいテストを考え出そうとし続けているが、新しいベンチマークはどれもすぐにクラックされてしまう。以前は広く使われているベンチマークをクラックするのに数十年かかっていたが、今ではほんの数カ月に感じられる。
https://situational-awareness.ai/wp-content/uploads/2024/06/owid-test-scores-1024x723.png
ディープラーニング・システムは、多くの領域で急速に人間レベルに達し、あるいはそれを超えつつある。グラフィック データで見る我々の世界
私たちは文字通りベンチマークを使い果たしている。 逸話として、友人のダンとコリンが数年前、2020年にMMLUというベンチマークを作った。彼らは、高校生や大学生が受ける最も難しい試験に匹敵するような、時の試練に耐えるベンチマークを最終的に作りたいと考えていた。GPT-4やGeminiのようなモデルで〜90%だ。
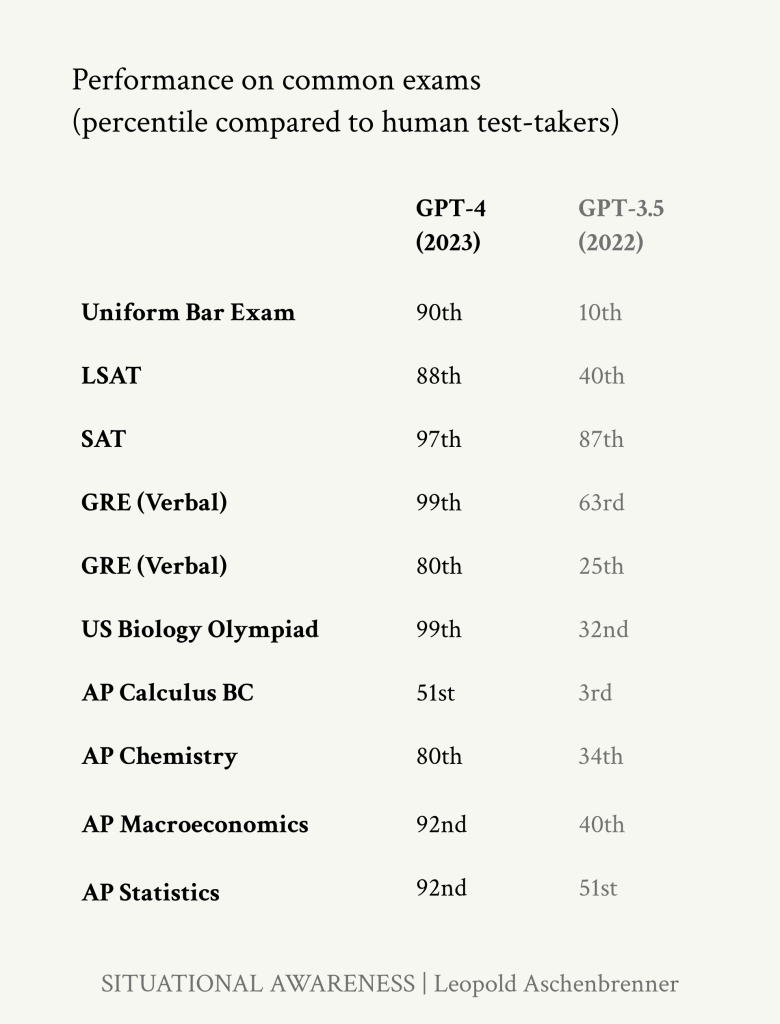
より広く言えば、GPT-4は標準的な高校や大学の適性試験をほとんど解いている。(GPT-3.5からGPT-4までの1年間でさえ、人間の成績の中央値を大きく下回るところから、人間の成績の上位に入るところまで、しばしば到達した)
https://situational-awareness.ai/wp-content/uploads/2024/06/gpt4_exams-780x1024.png
GPT-4の標準テストのスコア。また、GPT-3.5からGPT-4への移行で、これらのテストにおける人間のパーセンタイルが大きく跳ね上がり、しばしば人間の中央値よりかなり下から人間の最上位まで到達していることにも注目してほしい。(これはGPT-3.5であり、GPT-4の1年も前にリリースされたかなり新しいモデルである。)
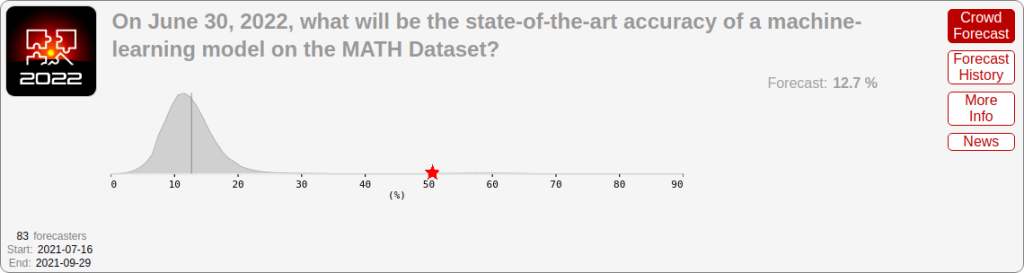
https://situational-awareness.ai/wp-content/uploads/2024/06/math2022-1024x273.png
灰色:2021年8月に行われた、MATHベンチマーク(高校数学コンテストの難解な数学問題)の2022年6月のパフォーマンスに関する専門家の予測。赤い星:2022年6月までの実際の最先端のパフォーマンス。ML研究者の中央値はさらに悲観的だった。
MATHベンチマーク(高校の数学コンテストで出題された難しい数学の問題集)を考えてみよう。このベンチマークが2021年に発表されたとき、最高のモデルは問題の5%しか正解できなかった。そして元の論文にはこう記されている:「さらに、このままスケーリングの傾向が続けば、単純に予算とモデルのパラメータ数を増やすだけでは、強力な数学的推論を達成することは現実的ではないことがわかった。数学的な問題解決をより牽引するためには、より広範な研究コミュニティによる新たなアルゴリズムの進歩が必要になるだろう」、つまり、MATHを解くためには根本的な新しいブレークスルーが必要だ、そう彼らは考えたのだ。ML研究者の調査では、今後数年間の進歩はごくわずかだと予測されていた。しかし、わずか1年以内(2022年半ばまで)に、最高のモデルの精度は5%から50%に向上した。
毎年毎年、懐疑論者たちは「ディープラーニングではXはできない」と主張し、すぐにその間違いが証明されてきた。過去10年間のAIから学んだ教訓があるとすれば、ディープラーニングに賭けてはいけないということだ。
現在、最も難しい未解決のベンチマークは、博士号レベルの生物学、化学、物理学の問題を集めたGPQAのようなテストである。問題の多くは私にはちんぷんかんぷんで、他の科学分野の博士でさえ、Googleで30分以上かけてやっとランダムな偶然を上回るスコアを出している。クロード3オーパスは現在60%程度であり、それに対してインドメインの博士たちは80%程度である。
https://situational-awareness.ai/wp-content/uploads/2024/06/gpqa_examples-768x1120.png
続き I.GPT-4からAGIへ:OOMを数える (4) https://anond.hatelabo.jp/20240605205024
それはあるんだがML関連では確定できない曖昧なのを扱うのが得意なのであって
ユーザーがある特定のアイテムをクリックしたという情報があったときに、そのアイテムの属性に関連するアイテムを推薦してほしいわけね
で、具体的にはコンテンツベース推薦を使ってて、アイテムを100次元のベクトルに圧縮してANNで検索してるから、実際に抽出してみるまでは「どういう入力にどういう出力をするか」ってのがわからない
エンジニアじゃないAI語って人様を煽ってる君はMLの基礎の基礎さえ知らんけど
煽った相手の俺はエンジニアだからちゃんとやってるので勝負にもならないって話
さいならー
最近の「AI」はMLの中でもニューラルネットワーク、ディープラーニングあたりを使うやつを言う
キリアンのヴレヴ クシュ アヴェク モワがアリュールに似ているというレビューがあった
久しぶりにアリュールを量り売りで購入しつけてみた
トワレとオードパルファムそれぞれ
お腹にヴレヴ クシュ アヴェク モワ、左腕にアリュールのトワレ、右腕にアリュールのEDP
トワレのほうが似てると感じる
つけた瞬間の感じが柑橘系と白い花の甘さで良い
EDPは甘い方が強くてまろやか 癖が少ない気がして物足りないと思った
EDPは残ってる
で、お腹プッシュしたヴレヴは相変わらず濃厚に香る
ヴレヴ クシュ アヴェク モワのこの重いパウダリーが好きで、似ている香水でコスパの良いものがあればと探してた
アリュールはまあ似てる、どっちも好きだと思う、mlあたり単価ならえーと
アリュール100で2万ちょっと、ヴレヴは50で4万だから、まあ4分の一なわけだ
アリュールトワレの軽さもEDPのまろやかさも、日常使いと思えばむしろメリットか
でもなあ
ということで、アリュールボトルに手を出すよりは、ヴレヴ クシュ アヴェク モワを消費する方向かな
{kind=link}
{kind=link}
{kind=link}
{kind=link}