はてなキーワード: x86とは
いやはやまったく、はてブにあがってたので読んでしまったが、久々にあまりにも酷いレビューを読んでしまった。あぁそうそう引用している記事にはアクセスしなくても良い。時間とトラフィックリソースの無駄だ。
記名は編集部となっているが、Business Journal編集部員の質はこの程度なのか?まるで「私たち編集部はWeb検索すらしないで又聞きした情報を記事にしています」と宣言したいがために記事を公開したのかと邪推したくなる。
1つの記事へ膨大な時間を掛けて執筆することは生産性を考慮すると悪手であるのは間違いない。しかし、いくらなんでも"ほど"があるだろうと言わざる得ないのだ。
下記の理由からBusiness Journal編集部は当該記事の編集部員へ二度とゲーム記事は書かせないほうが良いと"ご意見"をよせさせて頂く。
当該記事では太正100年が既存のサクラ大戦シリーズとの歴史的連続性の無さを指摘しつつ、蒸気エネルギーが排除され主要エネルギーが採用されたことへ対して非難の声がよせられていると書いている。
しかし、太正100年は西暦で言えば2011年である。半世紀以上の時間が経過していながらサクラ大戦シリーズはいまだ蒸気エネルギーへ依存し続けなければならないと本気で思っているのだろうか?
そして、歴史的連続性の無さを指摘しているが現在公開されているサクラ革命のシナリオは、チュートリアルと九州編と中国編(そして九州を舞台としたサイドシナリオ特別イベント)のみだ。
サクラ革命は47都道府県を舞台としようとしているのは現状で明確にわかる。つまり素直に受け止めれば45シナリオが残されている。全体のシナリオ進捗は約4.25%であり、この状況ではサクラ革命がサクラ大戦シリーズでどういう立ち位置なのかほぼわかっていないとWeb検索するまでもなく察することが出来るので、なぜこれを"爆死&大炎上"の理由としたのか本気で謎である。
サクラ革命を現状で物凄くやり込んでいるプレイヤーすら何もわかっていないのに、何をわかったつもりで居るのか。
サクラ大戦シリーズにおいて蒸気エネルギーは主要エネルギーとして確かに重要であり、サクラ大戦シリーズを彩るスパイスとして無くてはならない存在であるのは間違いない。
しかし、サクラ大戦シリーズにおいてスチームパンクはスパイスであってメインの素材ではなく、あたかもサクラ大戦シリーズはスチームパンクだからこそ支持されていたかのように描くのは誤解である。
サクラ大戦シリーズファンへはわざわざ説明するまでも無い話だが、申し訳ないけれども知らない読者のためにも付き合って頂きたい。
端的にかつ簡潔に述べるならば、サクラ大戦シリーズは「アイドルマスター」シリーズのご先祖様である。
サクラ大戦シリーズは宝塚歌劇団をパロディした作品であり、その痕跡はキャラクター名や帝国華撃団など各名称に現れており、歌って踊り、企画段階で強くメディアミックスを意識され、当時の声優業界すら巻き込んで現在にもその影響を残しているターニングポイントだった作品だ。
霊子甲冑のデザインを著名なメカデザイナーが手がけているなど日本のSFとして決して軽視できるものではないが、宝塚歌劇団のパロディとしてゲームに落とし込んだという要素に比べればスチームパンク要素は些細と言って過言ではない。
だから「戦うアイマス、アイドルマスター XENOGLOSSIAかよ」と一部のユーザがそう感じてしまうのも仕方ない。ご先祖様なのだから。
ついでに誤解なきよう言及しておくと、蒸気エネルギー要素はディスコンされていない。当該記事の書き方では蒸気エネルギーがディスコンされてしまったものと誤解する読者が出てきそうなので。
これにはサクラ革命プレイヤーとプロジェクトセカイプレイヤーの双方が怒って良い。というか既に怒っているだろう。
どういう神経でプロジェクトセカイを持ってきたのか呆れて果ててしまう。
現代のサブカルシーンでは主題のコンテンツを貶めるため他のコンテンツを持ってくるのは禁じ手とする傾向が強くなってきているのを読み取れていないのか。
作品Aはカワイイ、作品Bもカワイイ。どっちもカワイイ。どちらがカワイイのではないどちらもカワイイ。
これが現代のサブカルシーンであり、当該記事の書き方はまるで10年前のゲームハード戦争真っ直中の素人レビューのようだ。
他のコンテンツを貶める暇が在るなら推しコンテンツを布教しろ。
Business Journalとかいう質が低すぎる文字同人サイトの誤りを指摘したので、次は実際にサクラ革命プレイヤーである筆者がサクラ革命が非難される理由を書こう。
ネタバレになるので詳細は控えるが、サクラ革命で現在配信されている3つのメインシナリオであるチュートリアル、九州編、中国編すべてでお涙頂戴が展開される。
しかもお涙頂戴の起因が3つとも同じだと言って良い。どれだけライターはこのシチュエーションが好きなのか。流石に3連続、というか配信されているすべてのメインシナリオがコレなのはおかしいだろう。
この繰り返される同じお涙頂戴シチュエーションについてはTwitterでちょっと検索するだけで出てくるので当該記事を書いたBusiness Journal編集部員はおそらくWeb検索すらしてないと思われる。
Twitterユーザーの100文字に満たないツイート、例えば「お涙頂戴繰り返すからサクラ革命のシナリオは微妙」みたいなレビューよりも質が低い上に、あれだけの文字量なのだから執筆時間もTwitterユーザーのツイートより掛けているだろうから生産性まで低い。圧倒的な質の低さである。お前Twitterユーザー以下だぞと。
サクラ革命の戦闘シーンで敵ユニットが毎ターンほぼ確定で自ユニットへ弱体化補正(いわゆるデバフ)を決めてくる。
つまり、敵ユニットが自ユニットへ対して攻撃力や防御力、必殺技ゲージの低下を(自ユニットが弱体化耐性を持っていない限り)毎ターンほぼ確定で決めてくるのだ。
ディライトワークスが開発するスマートデバイス向けの別ゲームタイトル「Fate/Grand Order」のプレイヤーならば慣れているゲーム設計と言えるが、ディライトワークス製ゲームを初プレイするプレイヤーに取っては不快なゲーム設計だろう。
サクラ革命はスマートデバイス向けRPGでありがちな、いわゆる「育成周回」が必須のゲーム設計となっている。
そしてサクラ革命には攻略ステージ毎へ親切にも自ユニットの適正レベルが記載されているのだが、どうやらこれは自ユニットの攻略ステージ開始時の初期ステータスを基準にしているらしく、適正レベルへ至っていてもターンが進む毎に敵ユニットから弱体化補正をかけられ続けると攻略が困難になってくるのだ。
当然、非常に高度な立ち回りをすると苦戦しつつも結果的に勝利を収められるが、忘れてはならないのがサクラ革命は「育成周回」が必須のゲーム設計なのである。
「育成周回」しなければならないのにターンを膨大に重ねるのは非効率なので、ここに矛盾が生じて慣れていないプレイヤーはストレスを感じてしまう。
「Fate/Grand Order」プレイヤーはこのゲーム設計に慣れているので即座に「最短ターンで編成を組むのがサクラ革命の最適解」と察して行動を取れたが、ディライトワークス製ゲームを初プレイしたプレイヤーはより一層のストレスを抱えているだろう。
これは完全にディライトワークス製ゲームのプレイヤー間の内輪ネタだが、ディライトワークス製ゲームにとってバグは"お家芸"である。何も笑えないが、ネタにして笑い飛ばすくらいの胆力がないとディライトワークスには付き合っていられない。
「Fate/Grand Order」でもローンチ直後から様々なバグがあり、その伝統は本作にも引き継がれ、大いにプレイヤーを笑わせてくれている。・・・その笑いは失笑かも知れないが。
筆者が笑ってしまったのはローンチ初日、サクラ革命もアプリ初回起動後に追加データダウンロードというゲーム系アプリにはありがちな仕様(初回起動時に追加データダウンロードが発生するのは各アプリストアの仕様上の制限である)で、ダウンロードプログレスバーが表示されている間に、登場キャラクターの簡易プロフィールが読めるという演出になっていた。ダウンロード中にプレイヤーが飽きてしまわないよう配慮された仕様だ。
しかし、この簡易プロフィールのデータがどうやら初回起動後の追加データに含まれていたらしく、1人目以降まったく簡易プロフィールが読めないというバグがあった(現在は修正済み)。ゲームプレイする前からわかりやすいバグが発見できる。これがディライトワークス。
サクラ革命を実際にコーディングしている開発者からすると変な汗が出る初歩的なバグであるのは筆者も情報技術者の末席に連ねる者としてお察し出来るので心身痛み入る、まぁそういうこともあるさという言葉を送りたい。
こうやってディライトワークス製ゲームプレイヤーが開発元ディライトワークスをイジるのが内輪ネタというわけである。
「Fate/Grand Order」のバトルシステムは登場当初スマートデバイスでもバトルっぽいことができると示した素敵なエコシステムだが、サクラ革命のバトルシステムはそのエコシステムのエコさ加減を最大限に活かしつつ、ちょっと戦略性を上げましたというバトルシステムである。
サクラ革命という新しいゲーム開発へ関わったのだから「もうちょっとなんかあったやろ」というツッコミが方々から聞こえてくるが筆者としては1周回って「ディライトワークスだしコレで良いんじゃね?」と思えてきている。
詳細なバトルシステムが気になる人はYoutubeか何かで観たほうが早いだろうし割愛する。所詮はポチポチゲーですよ。
筆者としては歌劇シーンを観ることができると思ってサクラ革命をインストール事前予約してまで期待して待っていた(ディライトワークスなのでバトルシステムは鼻から期待してない)のだが・・・観れないんだなぁ・・・(遠い目)。
いやコチラが勝手に期待したのが悪いっちゃ悪いんだが、3DCGでやるって言うんだもんアイドルマスターみたいな歌劇シーンを期待しちゃうじゃないですか。もしかしたら初代サクラ大戦のメンバーとかもスペシャルゲストとして動いてる様子が観られるとか思っちゃうじゃないですか。
このあたりが怨嗟を生んでる気がするんですけど、ディライトワークスさん1周年イベントで良いんで歌劇シーンやりましょうや。
悪いところばかり挙げるのもアレですし、とりあえずプレイせず様子見している"司令"も居るでしょうから良い点も挙げておく。
初代サクラ大戦のイメージを引っ張っている司令からすると違和感が物凄いけれども、慣れてくるとこれはこれで良いものなのではないかと思えてくる。
ただモーションは固定なので高く期待するほどでも無い。
サクラ革命ではガチャゲーで、アイテムや装備も一緒に排出されるいわゆる"闇鍋ガチャ"であるが、☆5キャラの排出率が恒常ピックアップ☆5キャラが0.375%で「Fate/Grand Order」と比較すると悪くはない(FGOの恒常ピックアップ☆5キャラは0.029%)。
筆者もそうであるが、コレクター的な性質を持つプレイヤーならば出費少なく結構簡単に現行でガチャ実装されているキャラが揃ってしまうので、その辺は気持ちよさがある。
ちなみにガチャで所有キャラが被ると必殺技の性能が向上するという仕様。最大でLV20。
前述したとおり、ガチャで所有キャラが被ると必殺技の性能が向上するという仕様だが、ガチャでなくとも必殺技の性能を挙げるためのアイテムが存在する。
いわゆる"箱推し"でなく"嫁"を愛でる性質を持っているプレイヤーであるのならば自由意志で集中してアイテムリソースを注ぎ込むことが可能だ。
一部の読者からすると途端にマニアックな話になって申し訳ないが、サクラ革命はChrome OSのAndroidエミュレータで動作可能で、Chrome OS上のGoogle Play Storeで普通に配信されている。
これはおそらくAndroidアプリ開発の統合環境Android Studioの仕様で、デフォルト設定だとChrome OSでの動作が許可されているためだ(ちなみに「Fate/Grand Order」も動作する)。
筆者は細かな検証をしていないが、どうやら新しいApple Sillicon M1を採用したMacでは動作しないようなので、この点だけはほんの少し新しいMacbook Airよりも一歩、いや半歩だけ進んでいると言って良い。
ただ、どうやら配信されるバイナリはARMアーキテクチャ向きのものであり、x86(x86_64)アーキテクチャ向きのものではないようで、そのためかレンダリングへ一部不具合を抱えている上に動作が重い。これが半歩の理由。
Chrome OS上でサクラ革命の動作を検証した筆者のChrome OS環境で最大スペックのものはCPUがCore i7-10510U(第10世代)でワーキングメモリ16GB、M.2 SSD 512GB(PCI Express 3.0)であり、それでも「軽快さはないがプレイに全く支障はない」くらいの重さを感じるので、現状でサクラ革命をChrome OSでプレイするならこの程度のスペックは必要になると思われる。
情報技術者としては今後デスクトップおよびラップトップコンピュータでスマートデバイス向きアプリケーションが動作するのが一般的なのは目に見えているので、アプリ開発者はデスクトップおよびラップトップ向きのハードウェアサポートを検討する時代へ突入し始めていると多少の意識を向けたほうが良いのかも知れない。
例えば、各アーキテクチャへ最適化されたバイナリや、スマートデバイスではあまり意識されてこなかったハードウェアキーボードのサポート、シングルタップ時とマルチタップ時のトラックパッドの振る舞いの違い、変動するアスペクト比など挙げればキリはないので頭が痛い話だ。
<
Apple M1の高性能の理由について、ネットはクソみたいな解説記事に溢れている。
技術に明るいはずのはてなーですら某AVライターの間違いだらけの記事に釣られて、300ブクマ超が集まっていて嘆かわしい。
それもこれも後藤センセーがいつまでたっても解説記事を書いてくれないせいではあるが、公開情報が少なすぎるせいでまともなライターほど記事を書けないのも理解できる。
違います。
そもそもM1はDRAMをSoC化/ワンチップ化していません。M1がやっているのはSiP(System in Package、複数チップをワンパッケージに組み込む)であって、eDRAMによるSoCとは全く異なるものです。
SiPとSoCはJavaとJavascriptくらいには違います。
違います。
HBM系のメモリを採用していたらメモリ帯域は大幅に向上しますが、M1は標準DDR系メモリをワンパッケージ化しているだけなので、帯域もレイテンシも変わりません。
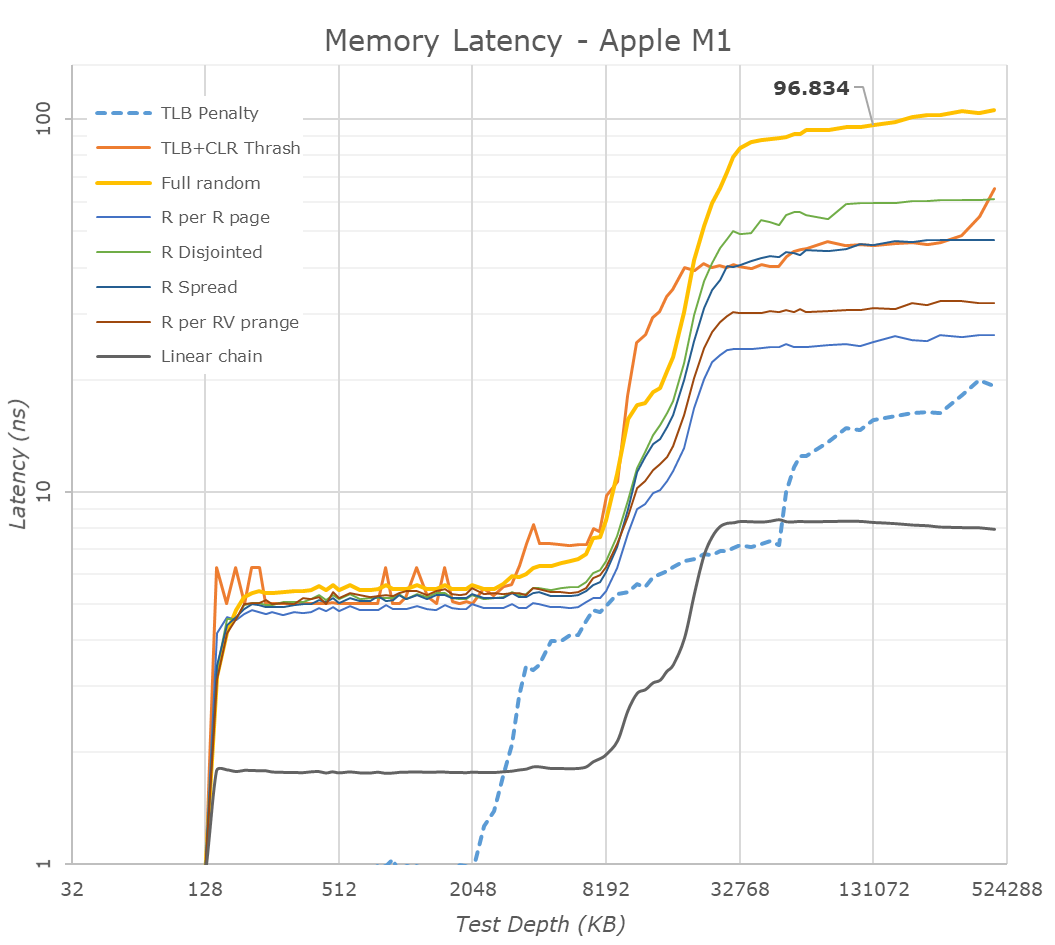
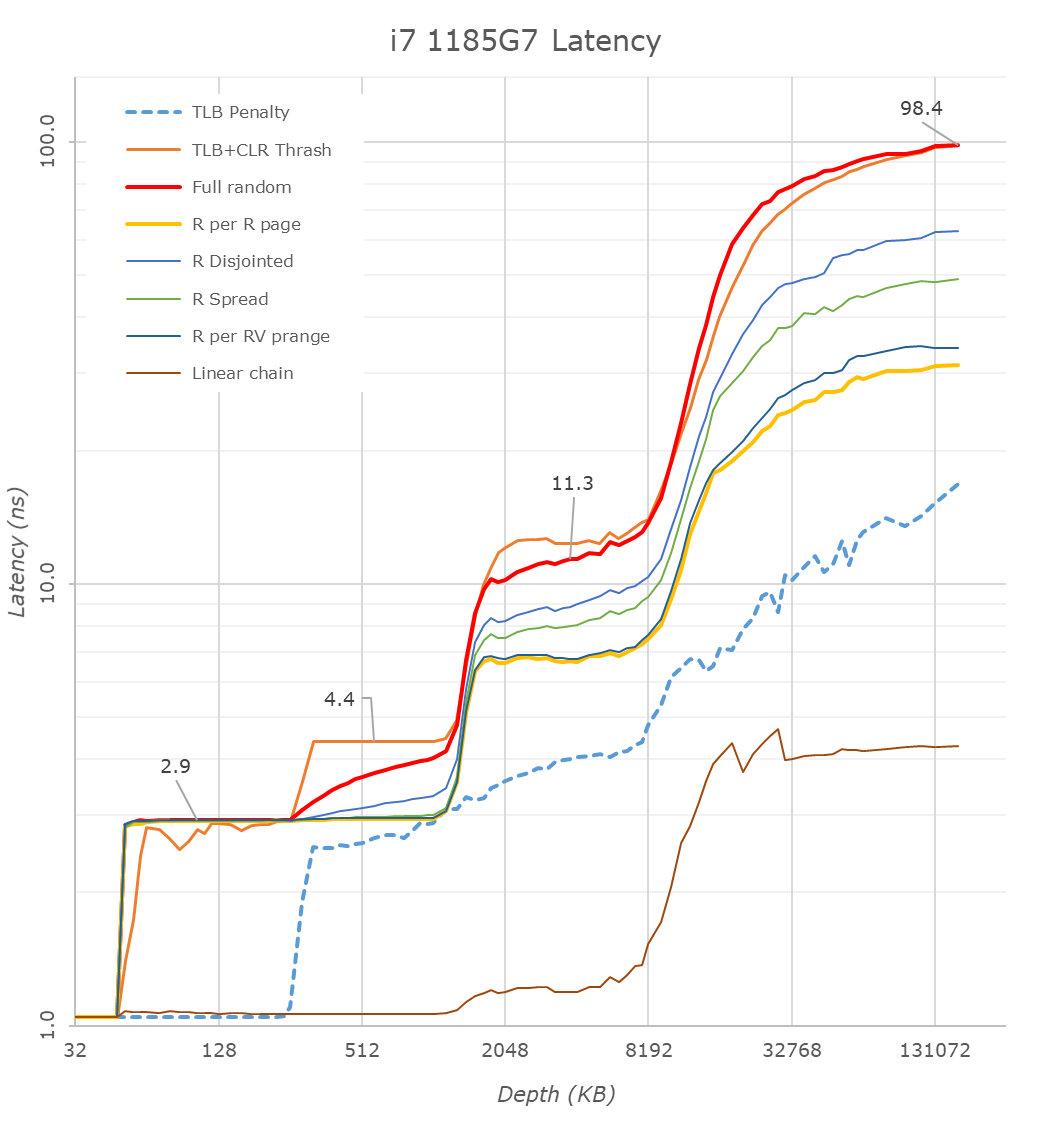
帯域はM1 MBPとIntel MBP(Ice Lake)でチャネル数同じ、前者はLPDDR4X-4266、後者はLPDDR4X-3733なのでメモリ帯域は14%しか向上していません。また、x86/x64最新世代のTiger Lake/ReniorはLPDDR4X-4266に対応しています。レイテンシはM1が96.8ns、Tiger Lakeが98.4nsでほぼ同等です。
Apple M1の実力を最新世代のIntel/AMD CPUと比較。M1が両者を大きく上回る結果ににあるように、SiP化によって消費電力の削減は期待できます。
違います。
SoC-DRAM間がマザーボード上で30cmあったとしても、電気信号の伝送にかかる時間は片道1nsです。仮にSiP化で物理的距離が1/100になったとしてもレイテンシ100usが98.02usになるだけで、CPUにとってDRAMが絶望的に遠いことに変わりありません。
違います。
まず、同一チップ上のCPUとGPUが同一のメモリーコントローラ/DRAMを共有するという意味では、Intelは2011年のSandy Bridge、AMDも2011年のLlanoからUMAです。一歩進んだメモリ空間の共有、コヒーレンシの確保という意味でも、AMDは2014年のKaveriから対応していて、この点においてM1に革新性はありません。
違います。
上記のSandy Bridge、Llanoの世代からかつてのノースブリッジがCPUに取り込まれたため、2011年以降のモバイルPC向け”CPU”のほぼ全てにはGPU/メモリーコントローラが含まれています。
かつてのサウスブリッジはIntelは今でもワンチップ化こそしていませんが、2013年のHaswellからMCMでワンパッケージ内には収められています。AMDは2014年のCarrizoからサウスブリッジ機能もCPUに取り込まれています。
この意味で、x86/x64のモバイルPC向け”CPU”は、かなり以前からSoCです。
違います。
NPUを活かせるアプリケーションは2020年現在では未だ限定的です。もしNPUの有無によってUXが決定的に改善されるなら、NPUありのSnapdargon 8cxを積むSurface Pro Xは同世代のSurface Pro 7よりずっと快適でなければなりませんが、そのような事実はありません。
違います。
CISC/RISCの論争は20年以上前に終わった話です。その後CISCはRISCの美点、RISCはCISCの美点を取り入れたので、現代のCPUはISAがCISCか/RISCかだけで性能が決定されることはありません。
歴史的経緯からx86/x64のデコーダが複雑になりがちなのは事実ですが、5W以下のローパワープロセッサの開発へ向かうIntelにあるように、ISAの差による消費電力増は10~20%のレンジで、さらに性能増によって相殺される分、電力効率の差としてはわずかです。
頑張って最適化してIPC上げたのと、スマホ由来の積極的なDVFS・クロックゲーティング・パワーゲーティングで浮いた消費電力を回しているからです。
気が向いたら書きます。
以下、プログラミングは出来ない俺の認識が間違っている場所があったら教えて下さい。あと、疑問2つを教えて下さい。
【俺の認識】
1. コンピューター(というかCPU)が実行する命令は【機械語】で書かれている。たとえばx86CPUの場合、0x04ならば『imm8をALに加算する』命令、0x90ならば『何もしない』などである。
2. 流石に機械語のままでは人間がプログラムするには不便なので、機械語をそのまま人間にも意味が分かるように1対1対応で書き直した【アセンブラ言語】というのがある。0x04ならば『ADD AL, imm8 』、0x90ならば『NOP』と表記される。
3. アセンブラ言語のように機械語と1対1対応している言語を【低級言語/低水準言語】と言う(この呼び方、4で書く高級言語が出来てから生まれたレトロニムか?)
4. アセンブラのままでプログラムするのも困難である場合が多いので、機械語と1対1対応していないプログラミング言語もある。このような言語を【高級言語/高水準言語】と言う。
5. 高級言語で書かれたものはそのままではコンピューターには実行できないので、【コンパイラ】というソフトによって機械語に変換している。
6. 高級言語で書かれた状態を【ソースコード】と言う。このソースコードをx86用のコンパイラでコンパイルすればx86で動くソフトになり、SPARC向けにコンパイルすればSPARCで、PowerPC向けにコンパイルすればPowerPCで動くソフトになる。
【疑問】
a. 認識6が正しいのであれば、(サポートするファイル形式の問題などを置いておけば)windowsとmacは現時点では同じCPUを使っているのだから、同じコンパイラでコンパイルしたソフトはwindowsでもmacでも動くのではないか?
米中の技術競争に日本はおいていかれているように、いち技術者からは見える。
どうして今のような状況になったのか、考えてみたい。
原因は1つではなく、複合的だろう。
日本で半導体を開発しようとすると設計ソフト(Cadence, Synopsysなど)が必要だが、国産はもうないに等しい。
Webで働いている人からするとオープンソースで開発すれば、と思われるかもしれないが、あるにはあるが、実際の製造には使えない。
機能が全然足りていないのもそうだが、全部の設計工程用のソフトはない。
製造原価やウェーハ代や人件費がかかるでしょと言われるが、ライセンス料金も開発費の中でかなりの割合を占めている。
Web業界だとOracleの値上げに苦しんでいたと思うが、あれと同じような状況だ。
中国はどうかというと、日本と同様に設計ソフトは作れていない。
というよりGithubにそもそもないのでフォークするなど簡単には作れない。
Webやプログラミング関係だと書店にいけばあるが、半導体設計用のソフトに関しての和書はない。
最近のプログラミング関係の和書だと入門編で終わるのが多いが、中国では実際の設計の一連作業まで使い方を解説した書籍が存在する。
勉強しようにも勉強できない日本と、勉強しようとすればなんとかなる中国の差ではないだろうか。
簡単なCPUが作れるだけの書籍がある日本と、x86のクローンを作りかけの中国書との違いといえばいいだろうか。
最初からアメリカ製品を買ってきて作ることが当たり前になっていたので、国内計測機器メーカーにお金が流れが作れなかった。
書籍なども使い方までしかなく、計測機器を分解して中に入っている設計ノウハウについての解説はない。
アメリカだと設備に投資している。土地があるからというのもあるのだろうが設備が充実している。
また型落ちの設備も流通していることもあって、個人で所有している人もいる。
中国はというと、深センでわかるように、分解した部品が売られていたりする。
YES,New generation Optimizer STL/C++ Level Code Optimizer.I think too. you can!
X86以前のコードレベルで自動的にコード最適化をかけた後にX86最適化を行う。このさいに文法的な最適化ではなくX86が最速になるようにCのコードを並び替える。
これはたしかに新時代のオプティマイザーなんだろう。だれが発案したの?
みんなx86で最適化を考えるがCのレベルで等価なコードであれば並び替えたほうが、さらにX86が最適化されるケースはあり得る。
たとえば、ライナーサーチだと判定できたら、さらに最速なアルゴリズムにCを置き換えることは不可能ではない。
コンパイラがアルゴリズムの最適化まで許可された場合 Pythonなどで培われた技術を使ってアルゴリズムコード最適化をしてCのコードをアルゴリズムごと改変してもよく、その後X86最適化を行うことは、次の時代にはふさわしいと私は思う。
例:ライナーサーチをもっとはやいサーチアルゴリズムに、このC言語のコードはライナーサーチだと判別して、コンパイラが自分で関数化した後に、もっとはやいサーチに関数ごと置換する。
その考え方はすごい。
プログラミング言語を印象批評している記事に触発されて、自分も印象批評してみようと思う。
JavaScript以外にもブラウザ上でぐりぐりするのにはJava AppletとかFlashとかSilverlightとかいろいろあったけれど、結局標準化を成し遂げたHTML5に淘汰されちゃった感じがする。LiveScriptからJavaScriptに改名されたり、規格を話すときはECMA Scriptだったりといろんな別名を持つ。一応、プロトタイプベースのオブジェクト指向言語なんだけれど、それを意識してコードを書く人がどれくらいいるかは謎。
Pythonは小さいコードを書くのには楽だけど、これで大きなコードを書くと思わぬ変更で思わぬことが起きるのでつらい。しばらく使うとPythonイヤイヤ病にり患し、goを使うようになるらしいとか、ならないとか。pythonで大規模なコードを万一書こうと思うなら、カバレッジが高いテストを書いてくれと思う。
Javaは初期のころオートボクシング / アンボクシングもなく、ストイックなオブジェクト指向言語だった記憶がある。ただ、staticを多用してオブジェクト指向とは程遠いコードも簡単に書けるので、Javaで書いているからと言ってオブジェクト指向だと思うのは禁物である。
PHPはWebネイティブな言語で、初期のころHTTP POST/GETなどで渡された変数がそのままプログラム中に出てくる機能や初期化していない変数を最初に使うと空文字列あるいは0で初期化するという機能があった。また、文字列と数字を臨機応変に切り替える機能もあり(今もそうかは知らん)、数字と文字の比較を比較演算子(==)でシームレスにできる。パスワードチェックみたいなコードで===ではなく、==を使っているとPHPを知らないバカ扱いされる。
C#はHello Worldくらいしか書いたことないから知らん。monoのような互換環境があるのは知っているけれど、わざわざPC Unix上でmonoを使う気分にはなれなかった。
C++は黎明期に使った感じと、C++11以降に使った感じが驚くほど違う言語。今はかゆいところには大抵STLで手が届くし、autoを使えばイテレーションで腱鞘炎になることもない。PC Unixにも最初から環境がインストールされているか、簡単にインストールできるので毛嫌いせず使うとよいと思う。
Rubyはぎょっとする変更をよくやるというイメージ。これで書かれたプログラムを長年愛用してきたが、ぎょっとした変更を入れられて動かなくなったのでgoで書き直した。その点ではpythonも3でおいていかれたので嫌い。
TypeScriptは書いたことないから知らない。JavaScriptだと大規模コードを書くとつらいのでTypeScriptを使おうという人がいるのは知っている。大規模なコードを書くとしたら、インタフェースに合った呼び出しかコンパイル時にチェックしてくれるような強く片付けされた言語のほうがよくなってくるというのはわかる。
Cは片付けし、構造化したプログラムを書きやすくしたアセンブラ...というイメージだったんだけど、C99くらいから便利機能がいろいろ入ってそうでもない感じになった印象。昔はCのコードを見たら最適化した後のx86アセンブリが見えていたんだけれど、最近は見えなくなってしまった。子供のころ、本屋で秘伝C言語問答 ポインタ編に出会ったのがこの業界に入るきっかけだったのかもしれない。ほかの言語でいろいろ楽に書けるから、カーネルをいじるか、システムコールをたたくかするときくらいしか自分の中では出番がなくなってしまった。
これ以下のランキングのもその気になったら書こうかな。
知らない奴多過ぎて笑えなさすぎる
お前らどんだけゲームに興味ないんだよ
https://game.watch.impress.co.jp/docs/kikaku/1181063.html
マーク・サーニー氏のインタビューから分かることは、大きくわけて次の3つだ。ひとつ目は、PS5のリリースは2019年ではなく、2020年以降になるということだ。2019年内の発売を思わせる情報も飛び交っていたが、どうやらその線はなくなったようだ。
3つ目は、PS4に対する互換性が保たれるということだ。アーキテクチャの大幅な変更が行われたPS2とPS3の間での世代交代では、互換性維持のため、初期のPS3ではPS2を内蔵しているも同然の状態でコスト高になってしまった。また、同様に大幅なアーキテクチャ変更でPS3、PS4間でも互換性が失われることになってしまったが、ほとんどx86互換のPCとアーキテクチャ的な違いがなくなったPS4の延長線上にあるPS5では、互換性が保たれるようだ。
これ昨日じゃないぞ
やっぱり途中で切れたので続きから
違います。
そうです。
はい。Stadia Games and Entertainmentの組織を発表しました。これは我々の1stパーティのスタジオです。
はい。
Googleは開発者に対し全てのツールを支援しています。Stadia向けの開発は彼らにとって別のターゲットにしか過ぎません。Visual Studioを用いる既存のツールや彼らが用いるツールの全てと共に、彼らのワークフローに統合されます。従ってStadia向けの開発はPlayStationやXbox向けの開発と同じくらい簡単です。
我々はUnrealもサポートします。UnityがStadiaをサポートします。予想される多種多用な業界標準のツールとミドルウェアが準備されます。
とても良い質問です。我々はユーザに対し彼等のインフラの中で何が起こっているかをできる限り理解できるよう支援する必要があります。また我々はゲーマーに対し最適な体験を得られるようなチューニングを行うことが可能な情報に対し投資を行うだけでなく、我々自身の技術を用いて最良のパフォーマンスを実現するつもりです。Googleの技術の多くがインターネット網の基盤であることを思い出して下さい。我々はDCからの情報がどのようにユーザに届くかを良く理解しております。できる限りの最適化を行うつもりです。
その通りです。それこそが我々のプラットフォームの根本的な差別化ポイントです。既存のゲームカタログを持つデベロッパにとってStadiaは簡単で親しみ易いものです。我々はできる限り摩擦なくゲームの移植を行えるようにします。なぜならゲーマーは好きなゲームを遊びたいですし、彼らの愛するキャラクター、ストーリー、世界を楽しみたいのです。しかし我々はまた開発者に未来を描く新しいキャンバスをも提供します。ゲームを高速に配布し、プレーヤーと新しい手段で、特にYoutubeにて繋げます。そして開発者が持つアイデアを実現するための前例の無い技術を提供します。
解決されたと同時に緩和されています。まずデータセンターに対しより多くの人々がより良い経験を得られるようにするための投資が行われました。また圧縮アルゴリズムについては我々に抜本的な先進性が存在します。Googleは圧縮アルゴリズム標準仕様の先駆者でありこの点がストリーミングの将来をより確実にします。残念なことですがGoogleでも制御できない点が光の速さです。そのためこの点が常に要因となります。しかし常に理解しなければならないこととして、我々は常にエッジ(終端)にもインフラを構築していることが挙げられます。Googleの中心にある巨大なデータセンタだけではありません。我々はできる限りエンドユーザの側にインフラを構築しています。それによって歴史上の幾つかの問題は回避することが可能です。さらにまだ率直な、あまり洗練されていないProject Streamのストリーマーでも信じられない結果を出しています。さらに我々はサービスリリース時に1080p60を超える品質を実現できるだけの根本的な改善を行いました。我々は8Kに至るでしょう。
圧縮にネットワークです。我々はGoogleがインフラに投入した数々の改善点に依っています。BBR、QUIC、WebRTCを基盤としてその上に構築がなされました。だからIPパケットの低レイテンシでの配信だけでなく、送信元へのフィードバックも行うことが可能です。ですのであなたが仰るZenimaxが使用した技術なら、彼らはここでも利用することが可能です。彼らは彼らのゲームの最適化を行うことができるでしょう。我々はフレーム毎のレイテンシを予測が可能で彼らにそれに合わせて調整を行わせることができます。
我々は改善を続けます。Streamは最初のバージョンです。我々は性能向上のために調査を行っており、レイテンシに適応していきます。リリース時にはより良くなっているでしょう。
確かにそのとおりです。そしてそれこそがGoogleが何年もかけて開発してきたスキルであり、抜本的なスケールする能力です。我々がどうやって実現しているのか、何をしてきたかについては今日は詳細にはお話ししません。しかしGMailやMap、Youtubeが同時に利用可能であるためと同じ基本的な技術のいくつかが我々が依るものです。
我々は競合他社が何をしているかは存じておりません。
我々の第一世代システムに導入されるGPUは10Tflops以上の性能があり、さらにスケールアップします
AMDです。
情報を公開したくない訳ではないのですが、このプラットフォームが進化することのほうがより重要です。そしてこの進化がユーザと開発者の双方に対しシームレスに行われることを確認して頂きたいのです。そして進化は常に継続し、誰もが常に最新で最高の物を手に入れます。
開発者にもこのように考えて欲しいのです。もちろん完全には抽象化されていません。特にゲームの開発者にとっては。しかし我々はそれでもこのプラットフォームが常に進化していると考えて欲しいのです。速さや容量、リソースには制限されていないのだと。
シェーダコンパイラのツールをいくつか開発しました。これらは開発を楽にするでしょう。しかし現在のGPUはとても優れており開発者が既にVulkanに親しんでいれば、例えばid Softwareさんは既に全てVulkanに移行していますが、そのような開発者の方々には既存のゲームをStadiaに移植するのはとても簡単です。Doom Eternalが4K、60フレームで動いでいるのは既にご覧になったと思います。非常に素晴しい状態です。これこそが我々にとって重要な証明ポイントです。FPSはグラフィックとプレイアビリティの双方で要求が高いゲームです。 従ってこれは我々のプラットフォームの強力な証拠であり、idさんにも講演して頂きます。
x86で2.7GHzで動作しています。開発者にとり慣れのあるものです。開発全体を通して、CPUは制約となる要因ではありません。我々は全てのタイトルを動作するに十分なCPUを提供します。
沢山です。
しかしサーバ級のCPUです。Stadiaはこれまでのコンソールと違いパッケージングに制約を受けません。熱対策の問題も異なります。コンソールとはサイズやパッケージングの動機が異なります。データセンタの中でそれはとても汚なく見えるかもしれません。一方でとても帯域幅が高いメモリが使用可能で、とても高速なペタバイト級のローカルストレージも使用可能です。ご家庭のコンシューマデバイスよりも数百倍は速い物です。
パートナーには彼らが話せる時点で彼らの計画を教えてくれるよう伝えています。Stadiaをこの世界で最も偉大なゲームの開発者達に説明することにはとても興奮します。Stadiaは、開発コードではYetiと呼ばれていましたが、Stadiaのビジョンを説明すると、開発者のリアクションは「これは私が期待したものそのものだ。これはまさに我々の次のゲームのためのビジョンそのものだ。elastic computingの考え、次世代レベルのマルチプレーヤー環境、ゲームを観ることと遊ぶことの境をあやふやにし1つの体験にすること」と話されます。
イノベーションの1つの領域として、最初のほうで述べましたが、マルチプレーヤー環境において、単純にパケットを複数のプレーヤーにリダイレクすることから、原子時計レベルでのコンシステンシーを全ての状態遷移において定期的にクライアント間で更新する真のシミュレーションへの移行が挙げられます。これにより開発者はこれまでには不可能だった分散された物理シミュレーションを得ることができます。これだけでもゲーム設計のイノベーションに対し大きく寄与します。このため多くの開発者が、大袈裟でなしに、実際にとても感動的なリアクションを我々のプレゼンに対して返して下さっています。
これこそがゲーム業界の素晴しい点です。技術が常に創造性を刺激し、ゲームに対しより大きな聴衆を作り、そのことがプレーヤーと開発者に対しより大きな機会を作ってきました。エコシステムが進化し、正の方向に回り続けるなら、それはゲームを遊ぶことにとって良いことです。
3台のGPSが一緒に実行されるデモを行っています。私は上限が無いとは申しません。しかし我々は技術上の限界を上げています。そしてStadiaは静的なプラットフォームではありません。このプラットフォームは5年や6年の間、レベルが変わらない訳ではありません。開発者とプレーヤーの要求に従い、成長し、進化するプラットフォームです。なぜならStadiaはデータセンタの中に構築されています。進化させるのは我々にとって簡単なことです。
CPU/GPU/メモリ帯域幅の変更にはいくつかの自然な段階があります。これは家庭の物理な小売の端末よりももっとスムースでより継続的な進化です。しかし、より重要なことは基盤データセンタ網とそれに含まれるネットワーク技術への投資です。この2つが一致して行われることが重要でどちらか1つではダメなのです。
それは我々も既に行っています。Googleが既に20年以上、行っていることです。我々が依って立つまた別の巨人の肩です。
我々はStreamをさらに強化させています。従ってユーザはこの制約が全体のスタックに対する改善と最適化、また特に時間によって緩和されることを期待するでしょう。我々はその期待の上を行きます。
私は具体的な数値についてはコメントしません。しかし当然低くなります。
インターネットの接続環境はStadiaをリリースする市場では全体的に上昇機運が見られます。つまりこのパフォーマンス特性はますます多くのユーザが利用可能になります。
さらに繰り返しになりますが、BBRを初めとする我々の技術があります。さらに覚えておいて頂きたいのは我々のネットワークに対する理解はそのままではありません。それらもまた時と共に改善されていきます。Youtubeはマクロと
Eurogamerにより独占配信されたStadia開発者二人に対するインタビュー記事。
---
タイミングの問題です。20年間の蓄積によりGoogleにはデータセンタ内のパフォーマンスに優位性が存在します。Googleはデータセンタ内ではHWメーカーです。我々はデータセンタ内で何年もの間、高い性能で端末間を接続する基盤を構築してきました。Youtubeでの経験からプレーヤーサイドの観点からだけでなくデータセンタ内部からの技術的観点からの技術統合を行ってきました。他社でもその視点は存在していますがGoogleにはその点に固有のアドバンテージが存在します。
その通りです。我々にはレガシーがありません。全てが21世紀のために設計されています。開発者は制限の無い計算資源が利用でき、何よりもマルチプレーヤーをサポートできます。これまでのマルチプレーヤー環境は一番遅い通信に影響を受け開発者は最も遅い接続に対し最適化が必要でした。我々のプラットフォームではクライアントもサーバも同じアーキテクチャの下にあります。これまではクライアントとサーバの間のpingに支配されていましたが我々の環境なら最速でマイクロ秒で済みます。だからプレーヤーの数は単一のインスタンスにて動的にスケールアップが可能です。バトルロイヤルなら数百から数千、数万のプレーヤーが集まることも可能です。それが実際に楽しいかどうかは置いておくとしても、新聞のヘッドラインを飾ることが可能な技術です。
両方です。
ユーザが我々のプライベートLANからはみ出さないだけでもその効果は大きいものです。Googleは45万kmに及ぶ光ケーブルにより世界中のデータセンタ間を接続しています。米国の西海岸から東海岸まででも20ms、フランクフルトからマドリッドでも20ms。これにより開発者は最も極端な場合においてもレイテンシが予測可能でそれに従い設計を行うことができます。
StadiaはYoutubeの技術と深く結びついていますが、実際には一歩引いています。今日のゲーム業界を考えてみて下さい。2つの世界が共存しています。1つはゲームをプレイする人々で、もう1つはゲームを見る人達です。2億人の人々がYoutubeでゲームを毎日見ています。2018年には述べで500億時間がゲームを視聴するのに費されています。時間と人口の双方で信じられない程の視聴が存在します。我々のビジョンはこの2つの世界を1つにすることでゲームを見ることができ、かつ、プレイもできる、双方向に楽しめることです。
つまり重要なのはゲームシステムでもなくコンソールでもありません。噂とは異なり我々はコンソールビジネスには参入しません。我々のプラットフォームの要点はコンソールでは無いことで、皆が集まる場所を作ることです。我々は箱でなく場所を作る。今までと異なる体験を得られる場所です。ゲームを見るなり、遊ぶなり、参加する場所であり、かつユーザが楽しむ場所であり、ユーザが他人を楽しませる場所です。
だから我々のブランドはStadiaといいます。これはスタジアムの複数形です。スタジアムはスポーツを行う場所ですが同時に誰もがエンターテイメントを楽しむ場所でもあります。だから我々はそれをブランドにしたかったのです。皆が遊んで、観て、参加して、さらにはゲームをする場所。一歩下がって見ることもできる場所。常にどのボタンを押したかを意識しないでも良い場所。他のアーキテクチャでは実現できない場所です。
その通りです。そして単純に技術的に深い点を求めて、我々は第一世代でも4K60fps、HDRとサラウンドをサポートしました。さらに開発者が必要なインフラに従ってスケールします。それだけでなく、同時にYoutubeに常に4K60fpsHDRで画像を送信することが可能です。だからあなたのゲーム体験の思い出は常に最高の状態になります。
プレーヤー次第です。Googleは全てを記録はしません。もしプレーヤーが望むならGoogleは4Kでストリームします
共有が友達だけか、世界中に公開かも自由に選択可能です。Googleはユーザに制御を明け渡します。もしユーザがYoutubeで公開すれば誰でもリンクをクリックすることでそのゲームを遊ぶことができます。
そう。そしてこれはマルチプレーヤーゲームのロビーの新しい形となります。Youtubeのクリエイターなら誰でもがファンやチャンネルのsubscriberを自分のゲームへと誘うことができます。生主として、Youtubeのクリエイターとして私は視聴者を私のゲームに瞬間的に招待できます。それが私と10人の友達でも、(訳注: セレブの)Matpatと彼の数百万の購読者でも、技術は同じです。
Googleアカウントの一部です。従ってGMailアカウントがStadiaへのログインに利用できます。他の基盤についても説明させて下さい。最初のサービス立ち上げから全ての画面への対応を行います。TV、PC、ラップトップ、タブレットに携帯です。我々のプラットフォームの基本は画面に依存しないことです。これまで40年間、ゲーム開発は端末依存でした。開発者として私は制約の範囲内で、私の創造性を開発対象の端末に合わせてスケールダウンする必要がありました。
我々はStadiaでそれを逆にしたいのです。我々は開発者に対し彼らの考えをスケールさせ、どの端末の縛りからも解放したいのです。パフォーマンスに優れ、リンクをクリックすればゲームは5秒以内に開始されます。ダウンロードもなく、パッチもなく、インストールも必要なく、アップデートもありません。多くの場合、専用のHWも必要がありません。従って古いラップトップでChromeブラウザを使用する場合にでも皆さんが既に持っているだろうHID仕様に準ずるUSBコントローラが動作します。そして、もちろん、我々自身のコントローラも開発中です。
コントローラを自作する理由にはいくつかあります。1つはTVへの接続です。我々はChromecastをストリーミング技術に採用します。Stadiaコントローラの最も優れた機能の1つはそれがWiFi接続でDC内のゲームに直接接続することです。ローカルのデバイスとは接続しません。
その通りです。これこそが我々のブランドの実現であり、具現化です。そして独自コントローラにより最高のパフォーマンスが実現します。ゲームに直接接続するためにプレーヤーは画面を移動することが可能です。プレーヤーはどの画面でも自由に遊び、停止し、他の画面でゲームに復帰することが可能です。
そしてコントローラには2つの追加されたボタンがあります。1つはGoogle Assistantの技術とマイクを用います。ユーザの選択により、ユーザはプラットフォームとゲームの双方に対し、自然言語を用いて会話が可能です。例えば「Hey, Google。MadjとPatrickと一緒にGame Xをやりたいな」と言えばStadiaがマルチプレーヤーゲームを指定した友人と共に直ぐに開始します。
我々はゲーマーを可能な限り素早くゲームに辿り着かせるよう考えています。数多くの研究を行いましたが、多くのゲーマーがゲームを起動したら直ぐに友人とゲームを開始したいと考えています。ゲーマーはUIに時間を費したくは無いのです。
誰かが言ったことですが、現在のコンソールは起動した時にまるで仕事のように感じると言うのです。ゲーム機自体の更新や、ゲームの更新があります。我々はそれらを完全に取り除きたいと考えています。もう1つのボタンは、ちょっと趣が異なるのですが、Youtubeにシェアできます。
Youtubeが観られるならどこでもStadiaは動きます。
Chromecastはスマホからストリームを受取はしません。Chromecastはスマホから命令のみ受けます。画像はNetflixやYoutubeから直接受け取ります。Stadiaの場合、StadiaコントローラからChromecastへとこのゲームのインスタンスへと接続せよと命令がなされ、Chromecastはゲームインスタンスから動画のストリームを受け取ります。クライアントはとてもシンプルです。行うのはネットワーク接続、ビデオと音声のデコードのみです。Chromecastは入力を処理しません。全て入力はコントローラが扱います。ビデオと音声とネットワーク接続はChromecastの基本動作で全て既に組込まれています。
そうです。とても良く出来ています。WiFiに繋ぐだけです。コントローラにはWiFiのIDとPWを入れるだけです。それだけです。ホームボタンを押すと勝手にChromecastを探し直ぐにChromecast上でクライアントを起動します。UIが表示され直ぐにゲームを遊ぶことができます。デジタルパッドでUIを操作することも可能です。これが重い処理を全てクラウドへと移行する点の美しさです。Chromecastのような低消費電力の端末で説得力のある体験ができます。Chromecastは5W位下です。Micro-USBで給電可能です。典型的なコンソールは100から150Wもします。またこれまで説明しませんでしたが、例えスマホでも行うことは動画の再生だけです。従ってAssassin's CreedやDoomや他の重いゲームがあなたのスマホの上でモバイルゲームよりも低消費電力で動作します。だからスマホで10時間でも遊べます。
今の所、我々はChromecastのみに集中しています。でも技術的、機能的な観点からはYoutubeがある場所ならどこでも動きます。我々はまだStadiaをどのようにユーザに届けるかは検討中です。
サービス開始時から提供されるサードパーティによる解決手段をサポートしています。他にもアイデアがあります。しかし今は話せません。
良い質問です。私がこのプロジェクトに参加する前からチームは既に何社かと提携しここ何年かの間に技術を提供していました。StadiaはLinuxベースです。グラフィックAPIはVulkanです。開発企業はクラウドにインスタンスを作成しますので、開発キットも今ではクラウドにあります。しかしクラウドだけでなく、開発社のプライベートなDCでも、机上のPCでも可能です。
もしそうしたいなら。でも我々は今後のトレンドが開発でも配布でもますますクラウドへと移行していくと考えています。従って今後数年で開発者にとってクラウド中心、クラウドネイティブがゲーム開発での標準となるでしょう。
デベロッパーやパブリッシャーはとても賢くクラウドネイティブとなる新しいゲーム体験を達成するために必要なツールや技術について考えていると思います。しかしそれは世界中で何千ものアクセスポイントを持つデータセンターを運営することや、それらの運営に必要な莫大な投資資本とは異なるものです。Googleは今年単年でも$13Bの資本を投下しています。
米国では全ての必要な場所に展開が終わっています。Project Streamの試験に必要な環境は2018年末には整いました。我々はGoogle社内で、Google社員を対象に2017年の始めから2年間の間、プライベートなテストを行ってきました。2019年には米、加、西欧、英にて Permalink | 記事への反応(1) | 06:10
Green500と経済性は何の関係もないし、なんでそこで経済性を持ち出すのが訳がわからない。
ケーザイセーなるものは今のどの指標でも測ることはできないし、それを問題視するならケーザイセーとやらを評価するランキングを作れ。
アーキテクチャを変更したらソフトウェア更新コストがかかるなんてのは当たり前のことだし、そもそもお前の大好きなx86ですら世代を経るごとにコードを書き換えないと性能が出ない。
いい加減見苦しいぞ乞食。そろそろ黙れ。
そもそもパソコンの世界がx86による統一が図られたあとだから、ほぼすべての端末で艦これが動くのであって、HPCの世界にあっては、なにかを動かすためにはアーキテクチャごとに書き換える必要があるというのは、少し考えれば分かることだろうに…
おっと、いちいち書き換えるなんてコストが高すぎるとかその手の批判は過去数十年繰り返されてきたし、今更そんなものに答えたくないからやめてくれ。
そもそもお前の最初の論点は「Green500は意味なんかないランキングじゃん」だったはずだが、なに論点逸らしてんだテメー
せっかくだから真面目に答えてやろう。
まずHPLなりTop500なりでググれ。
四則演算レベルのベンチマークとか意味不明。そんなんあらゆる計算は四則演算で表せるに決まってんだろ。舐めてんのか
あとな、そもそも今日においてRISCだのCISCだのの分類に意味はない。CISCの代表格のx86が命令をマイクロオペレーションに分解して実行している以上、x86だってRISCだ。
それにな、アーキテクチャが混ざった環境下であっても、その性能を一定の指標のもと、正しく測ることが可能と大多数の人間に考えられているから、HPLは問題があると言われつつも40年間ベンチマークとして成立してんだよ。お前のようなニワカがギャーギャー言ってるようなことはとうの昔に語り尽くされているわけ。
もちろん、HPLに問題がないかといえばそういうわけでもない。様々な批判はある。代替するためにHPCGをはじめとしたベンチマークが提案されている。
ううーん。ワイpezyについて詳しいわけじゃないんだけど、増田がそういう切り返ししてくるってことはそもそも増田も詳しいわけじゃなさそうだな。
くだんのスパコンに積まれているPezy-sc2っていうCPUについては調べてみた?
んで、その下の3位くらいに並んでいるスパコンに積まれているXeon Gold 6148っていうCPUについては調べてみた? NVidiaのTeslaってプロセッサは何者か知ってる?
それらをいろいろ含めて考えると、このランキングにおいての登場人物がアンドレアノフ・ガーランドから渋川剛殻まで多彩過ぎて逆になんかおかしくねえ? って話になるわけだが。
逆に聞くけどRISC山ほど積んだマシンとガリガリのSPARKとか積んだスパコンやX86サーバーのすっごいのと比べててそれでええのか思わんか?
| DGX-1 | DGX-2 | DGX-1比 | 参考DGX-1*3 | ||
|---|---|---|---|---|---|
| 価格 | $149K | $399K | 268% | $447K | |
| 消費電力 | 3.2kw | 10kw | 313% | 9.6kw | |
| CPU | Xeon E5-2698(20core)*2 | XeonPlatinum(28core?)*2 | 140%? | Xeon(20core)*6 | |
| Memory | 512GB | 1.5TB | 300% | 1.5TB | |
| GPU | Volta*8 | Volta*16 | 200% | Volta*24 | |
| GPU-Memory | 128GB(16GB*8) | 512GB(32GB*16) | 400% | 384GB(16GB*24) | |
| SSD | 1.92T*4 | 30TB | 375% | 23TB(1.92*12) |
値段2.5倍、消費電力3倍をどうみるか。
用途によってはDGX-2(Volta*16)よりDGX-1を3台(Volta*24)とかのほうが・・・。
消費電力高そう。
上記の比較でCPU数同じ、GPU倍、で多分増えてるPCIeスイッチ増加分にSSDやメモリ増量を含めても消費電力3倍以上というのは・・・。
上記の表から単純に考えて NVSwitch12個の消費電力+(PCIeスイッチ*X) = Xeon*4 + Volta*8 - HBM2 128GB分 - SSD7TB分。NVSwitch1つで数十Wはありそう、100w超えるかも。
18Portある。
GPU-Switch間は各GPUから6Switchに1Portづつ接続。Switchの8Portを使用。ここまでは確実だと思う、これ以外の接続思いつかない。図みたらそうっぽい。
問題はSwitch間がどうつながるか、6基づつで1クラスタ、クラスタ内はSwitch間接続不要、クラスタ間は別クラスタの1SwitchにGPU接続数と同じ8Port使用とか?(合計16Port使用)
全然違った。クラスタ間は別クラスタ6Switchに1Portづつだった。
消費電力は1つ100w。12個Switchで1.2Kwだと。GPU間そんなつかわないならSwitch減らしてGPU増やしたいところ。
https://news.mynavi.jp/article/20180404-611133/
いや、クラスタ間は予想通りだった。そしてSwitch減らしたいというのは同意。
https://news.mynavi.jp/article/20180418-617343/
X86系ではGPU間接続優先でCPU-GPU間は重視しない方向性にし、
http://itpro.nikkeibp.co.jp/atcl/column/14/346926/101101158/
Q1.役所の仕事なんて全国でほぼ一緒なのに、なんで自治体ごとに別のシステムを作るの?
A1.地方自治体の事務や財務について法律で決まっているのは大枠だけだよ。
それを実務≒内部規定に落とし込むのは各役所ごとなので大枠は似てても実務プロセスは全然各役所で違うよ。例えば同じ業務でも独自の語彙があったり、下手すると同じ語で市町村ごとに意味が違ったりするよ。
Q2.なんで新規で作らないの?
A2.80年代ぐらいにやったよ。その結果が政令市クラスに残ってて今回京都市が更新しようとしてるような、メインフレーム上のシステムだよ。
A3.みんなが使ってるWindowsとかLinuxとかのOSがなかった時代のコンピュータだよ。IBMとかがベンダーごとに作っていてOSもベンダー謹製だよ。性能はいいけどメチャ高いよ。
システム内でクローズして専用線以外では他とつながってなかったから、汎用機からPCサーバへの移行を「オープン化」と言うよ。
オープンソースソフトウェアとは全然関係ないよ。
Q3.使いまわしってどうやってやるの?
A3.80年代とかに作ったシステムで動いてるCOBOLとかPL/IとかをLinuxとかUnixとかWindows上で動く言語にコンバートしてリコンパイルするよ。
DBのデータも階層型データモデルからリレーショナルDB用にコンバートして移行するよ。こういう開発形態を「マイグレーション」と呼ぶよ。
あと、バッチジョブ制御もJCLという汎用機用の言語で動いているよ。これもそのままでは動かないのでコンバートするよ。
コンバート先はperlだったり、シェルスクリプトだったり、ベンダごとの独自スクリプトだったりするよ。
COBOLとかの実行プログラム移行も大変だけど、帳票の大量印刷はたいていバッチジョブでこなしてるので、JCLの移行もめちゃ厄介で大抵もめるよ。
Q4.80年代のものを使いまわすとか。新規で作ればいいじゃん
A4.お金が無限にあればできるよ。今の時代にお金があった時代のシステムをフルスクラッチで再開発するととんでもない予算になって市役所内の決裁が通らないよ。
しかも汎用機時代の納品は割といいかげんだったのか、仕様書が残ってなかったりするから、費用はさらにかさむよ。
Q5.そんなんでよく運用できてたな
A5.当時はSEが汎用機の付属品みたいについてって、困ったらオペレーターとして介入して動かしていたみたいだよ。
そうやって現場感覚バリバリでやっているので、オペレーターしか知らないプロセスがあったりするよ。
マイグレーション開発では総合テスト中にそういう隠しプロセスが「発見」されたりするよ。こわいね。
上記の通り仕様書がないことも多いうえ、システム課に限らず市役所の人員は基本ローテーションするよ。
導入当初の担当者が残っていることは珍しいし、30年も前に導入した汎用機のことなんてここ10年に入った職員にはわからないよ。
Q7.なんで入札にしたの? 現行ベンダに指名してやらせたほうが良くない?
A7.金額がでかいから、たぶんどこの市役所でも入札案件だよ。
随意契約(随契)は無理だし、入札業者を発注者が指定する指名競争入札は談合の温床になってたから最近はあんまりやらないよ。
(裏技としてRFPを指名したいベンダーに書かせて公募型指名入札にしたり、RFPの段階でハードを全部特定ベンダで型番まで指定するというのがあるけど、公になると多分問題になるよ。こわいね)
Q8.じゃあ役所は悪くないの?
Q8.悪いよ。
入札案件はRFPで書かれた各項目をどれだけ満たすかの技術点と、価格点で決まるよ。点が高ければだいたい自動的にそのベンダーに決まるよ。
なので、技術点の項目に現行システムの調査にかかる項目を入れるとかして、現行機の開発・保守ベンダが高得点を取れるようにしておけば価格勝負してくるベンダーをはじけた可能性はあるよ。
もちろん現行の会社に嫌われて逃げられたとか、役所が現行の会社をめっちゃ嫌いになって声をかけなかったとかもあるかもしれないけれど、可能性は低いと思うよ。
A9.ここまで述べたようにこの手のマイグレーションは火薬庫だよ。火を噴いても爆発しなければラッキーぐらいなので、強いて言うなら入札したことが悪いよ。
A10.前にマイグレーションをやったことがあるSEだよ。もうやりたくないよ。今は転職してSIerじゃなくなったからやらなくてよくなったよ。うれしいね。
しょぼいSEだからここに書いたことは個人の体験に基づく参照情報だよ。一般的じゃないことを言ってたり、間違ってたら教えてもらえると助かるよ。
(2017.10.13 追記)
Q3がかぶっていたよ。恥ずかしくてなきそうだけどブコメに番号で言及してくれている人がいるから忍んでそのままにするよ。
あと、「オープン化」の定義が違くない?という指摘があったよ。確かに増田が間違っていたので、記事の主旨から外れるけど補記するよ。
メインフレームは本文で述べたようにOSからハードまでメーカー謹製なので独自仕様のカタマリだよ。
これに対しPCサーバは標準規格で作られているよ。こういう標準規格に基づくサーバをオープン系と呼ぶよ。
独自規格でクローズしたコンピュータから、そうでないオープン系に移行するからオープン化なのであって、専用線とかは関係なかったよ。半可通な知識で語ってしまったよ、ごめんね。
京都市で火中にいるシステムズさんのサイトの解説がこの増田よりも分かりやすくて正確だから気になる人は見てほしいよ
http://www.migration.jp/column/column01.html
完全に余談だけどオープン系のx86サーバに移行しても、システムはそんなにオープンにならなかったりするよ。
H系に頼むとDBが拝承DBになったり、Fに頼むとシステム管理が全部SystemWalkerになったり、要するにベンダ独自のミドルに入ってがっつりロックインされたりするよ。
{kind=link}
{kind=link}